




1.前言
最近一直想用deepseek搞点事情,索性来构建一个RAG吧。构建一个个性化知识库,听起来很高级,实际可能或许有点高级吧。于是,我就用RTX4090在带推理过程的知乎问答数据集上对deepseek-r1的14B蒸馏模型狠狠微调了8个小时,作为RAG的生成模型。
好啦,为了防止有小伙伴不知道为啥要构建RAG,在这里简单说一下。在知识密集型任务中,传统的生成模型往往受限于训练数据的覆盖范围,而RAG(检索增强生成)通过结合检索和生成技术,能够从外部知识库中动态获取信息并生成答案。本文将详细剖析我实现的一个RAG系统,包括(知识库)智能文档处理、混合检索和生成优化三大模块,代码基于LangChain和Sentence-Transformers等常见工具工具。
2.本RAG工作流
2.1工作流程总览
这张图有点大,你忍一下(doge)。
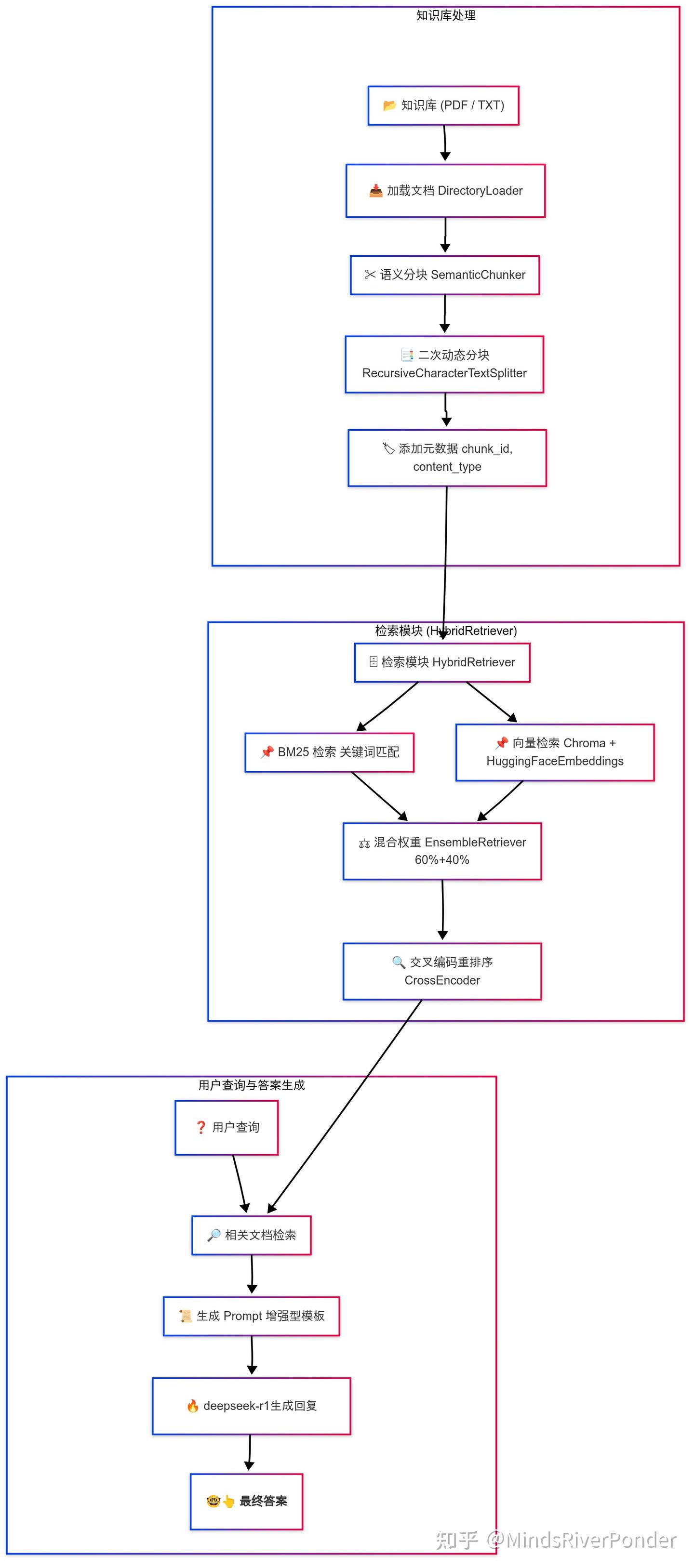
本RAG工作流程
不要担心,这图虽大,但我们细细品尝。 。
2.2第一部分-知识库处理
我们先来讲第一部分,即知识库处理部分。
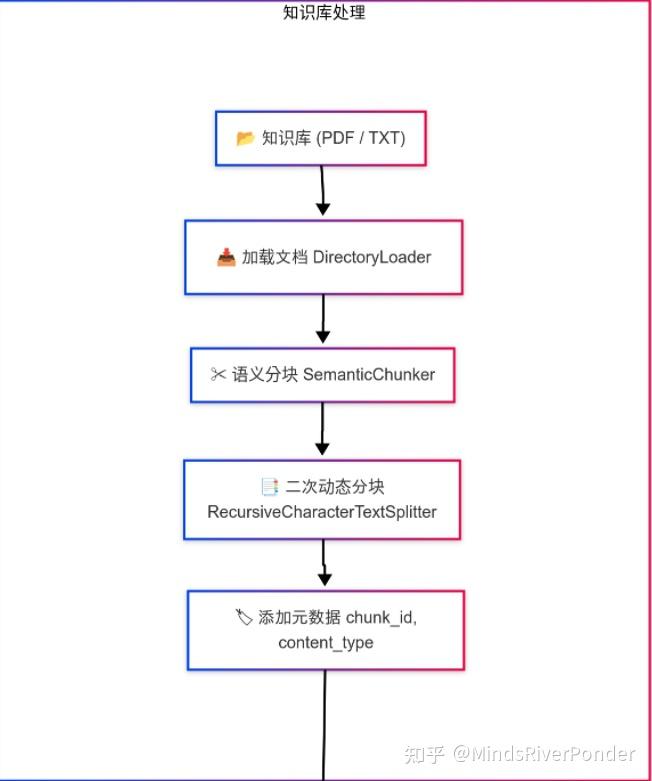
知识只有被吃进脑子里,才叫知识,不然只是一堆字符的堆砌,对于RAG也是如此,我们得把手里的知识变为RAG“爱吃”的知识。
我们得先把知识加载进来,并且根据不同的文件类型对文件进行解析。
待知识加载到计算机后,计算机一看,这些动辄几百页的pdf你叫我一口吞啊!我堂堂计算机只吃细糠,哼 。没办法啦,我们得把知识拆分一下,进行语义分块,根据语义,将原始文档拆分成具有语义完整性的较小单元,具体的工作流程是系统会逐步扫描文档内容,通过比较相邻文本段的语义向量,检测两段之间是否存在显著的语义转变,如果语义转变比较显著(超过了我们设定的阈值),我们就认为在此处存在自然的语义断裂,适合进行分块。
举个例子,如下是一个知识文档:
全世界CS从业者水平下降一万倍,而你不变,此时你是一只正在秋招的鼠鼠,学历一般,实习一般,八股也背得一般。更惨的是,你还选择了JAVA开发这条赛道,奇卷无比。痛定思痛,打开leetcode,已经过了0点,今天的每日一题是买卖股票的最佳时机,你自信打开ide,写完提交,在评论区留下一句,dp秒了,安享完美睡眠,顺便粘贴代码。可是你没有注意到的是,这一题的题解,竟然是光秃秃的0。在你睡后,评论区掀起轩然大波“哪位acm大佬来炸鱼了?”“动态规划,不是图灵奖得出才会的吗?”**( 分割点 )**过年啦,恭喜恭喜你呀,你发现你没有女朋友,又爱干饭,嘴里叼着辣条。
显然,分割点前面是真实发生的,分割点后面突然就过年了,转变了语义,净说假话,这时候,我们根据分割点就把文档分成了两块。当然,一般的文档是很长的,分个几百上千上万块比比皆是。
于是我们得到了文档分块,对这些分块,我们得进行**二次动态分块,**根据分块内容的类型进一步细分,如果是代码片段,采用较小的分块尺寸(256个字符,重叠64个字符)。如果是表格内容:采用适中的分块尺寸(384个字符,重叠96个字符)。如果是普通文本:默认情况,采用较大分块尺寸(512个字符,重叠128个字符)。
于是我们得到了更精细化的分块,对每一个分块添加元数据,这个词很高大上,实际就是给每个分块赋予一个id,并标记内容类型(如代码、表格等)。
通过上述步骤,文档被转化为具有良好语义单元和标注信息的“分块”(chunks),为混合检索模块提供高质量的基础数据。
2.3步骤二,搭建混合检索系统
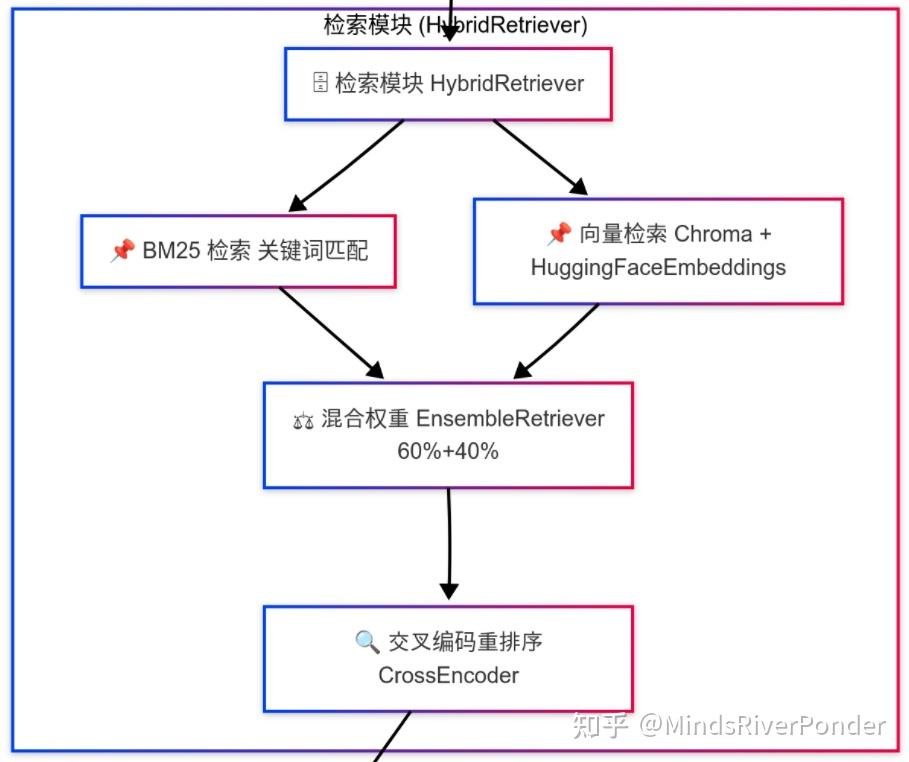
检索模块流程图
到目前为止,我们获得的分块还是活生生的字,我们得把他映射为向量,随后将它存入专门的数据库中-向量数据库,这玩意专门用于存储高维向量(通常由神经网络生成的嵌入),这些向量可以表示文本、图像、音频等非结构化数据的语义信息。并针对相似性搜索进行了优化,能够高效地处理大规模向量数据。为啥不用别的数据库,说白了,就是效率,人家是专门对这类任务优化过的。如果你不注重效率,用Excel当数据库都行(doge)。
把分块映射为向量装入数据库后,我们就可以检索了,我们不采用单一检索方式,而是采用混合检索,一种是向量检索,另一种是BM25关键词检索,简单说说这两种检索方式。
| 检索方式 | 基本原理 | 优势 | 劣势 |
|---|---|---|---|
| 向量检索 | 将文本转换为高维向量,通过余弦相似度等度量文本间的语义相似性。 | 可匹配表达不同但含义相似的文本 | 1.计算开销较大 2.可能召回语义上“相似”但实际不相关的文档 |
| BM25 检索 | 基于词频(TF)和逆文档频率(IDF),利用 BM25 公式对关键词匹配进行加权计算,衡量查询和文档之间的相关性。 | 1.计算速度快 2.精准匹配关键词 | 1.仅依赖关键词,难以捕捉语义信息 2.对同义词、近义词的匹配较差 |
简单来说,向量检索让我们获取语义上相似的内容,而 BM25 检索则确保关键字相关的内容不被遗漏。两者强强联合,对两个检索方式给予不一样的权重来检索文档,这就是混合检索。
但是单靠这两个方法结合起来检索仍有缺陷,我们可能会检索出一些有关键词且语义相似,但不相关的内容,举个例子:
假设用户查询是:
“请讲讲苹果的生态系统”
这个查询可能存在歧义,既可能指代 苹果公司 的产品生态系统,也可能指 苹果果树 周围的自然生态。混合检索(向量检索 + BM25)会尽量召回所有包含“苹果”和“生态系统”关键词的文档,比如:
-
文档 A:
讨论苹果公司的产品整合、操作系统、硬件与软件之间的协同效应,描述了苹果如何构建一个闭环的生态系统。 -
文档 B:
介绍苹果果树园中的生态平衡,如传粉昆虫、土壤养分循环等,详细说明果园中的自然生态。 -
文档 C:
一篇评论文章,既谈论了苹果公司在市场上的生态战略,又顺带提及了一些生物多样性的讨论。查询本身存在歧义时,向量检索可能会捕捉到多个相关的语义方向,从而同时召回多个相关解释的候选文档,而BM25 重视关键词匹配,文档 B 中频繁出现“苹果”、“生态”、“自然”等词,可能被误认为与查询相关,文档B就顺理成章地成为评分最高的文档了;这样就造成了“相似但不相关问题”。
我们得解决一下啊!我们就引入Cross-Encoder 重排序方法,利用联合编码深入理解查询和文档之间的语境关系,对候选文档进行精细排序,将最符合用户隐含语境的文档排在最前面。重排序后文档 A 和可能的文档 C会被排在前列,而文档 B 则会被降到后面。于是,“相似但不相关问题”,就告一段落了。检索系统已经搭建完毕了。
2.4系统集成:RAG!合体!
知识库处理模块组成大脑!检索系统组成躯干!
先将知识库处理模型塞进来,再将检索模块初始化,紧接着我们得将学到的知识讲出来呀。生成模型组成屁股!将知识组织好,拉出来给大伙瞧瞧!(doge)
加载生成模型这一步有一些需要注意的点。在RAG中,我们给模型的Prompt是不一样的,我们会根据检索到的上下文构造最终用于生成回答的 Prompt。
每个检索结果会被格式化为:
[来源:{doc.metadata['source']},类型:{doc.metadata['content_type']}]
{doc.page_content}
将上下文和问题拼接为 Prompt 后,扔给大模型,让大模型生成内容。自此,整个过程就结束了,RAG就搭建好了。注意哦,这个生成模型是随便选的,我选了DeepSeek-R1-Distill-Qwen-14B,使用RTX4090在知乎问答数据集上微调了8小时。
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型! 有需要完整版学习路线,可以微信扫描下方二维码,立即免费领取!

2.5总结
整个系统的工作流程如下:
1.文档预处理:
-
- 加载文档 → 初步语义分块 → 动态二次分块(根据内容类型区分代码、表格与普通文本) → 添加元数据
2.混合检索:
-
- 构建向量与 BM25 检索器 → 混合(Ensemble)检索 → 重排序(CrossEncoder 重评分)
3.生成模块:
-
- 检索相关上下文 → 构造增强 Prompt(含上下文来源、类型等信息) → 利用生成模型输出回答
3.逐段代码讲解
3.1下载并导入相关的库
!pip install langchain unstructured[pdf] chromadb sentence-transformers pypdf langchain_experimental rank_bm25
!pip install --upgrade langchain
from langchain_experimental.text_splitter import SemanticChunker
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.document_loaders import DirectoryLoader,PyPDFLoader,TextLoader
from sentence_transformers import CrossEncoder
from langchain.text_splitter import RecursiveCharacterTextSplitter
from unsloth import FastLanguageModel
import torch
import re
以下是一些主要库的版本,跑不通的话,多半是库版本问题。
langchain :0.3.19
langchain_experimental:0.3.4
sentence_transformers: 3.4.1
chromadb:0.6.3
pypdf:5.3.0
unstructured[pdf]:0.16.23
torch:2.6.0+cu124
3.2配置hugging face镜像站点(可选)
如果你在本地有代理或者在colab上运行,就不用配置镜像站点了(前两行)。注意嗷,记得去hugging face官网申请一个token,用来登录hugging face拉取模型。
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' #可选
from huggingface_hub import login
hf_token = "XXX" #去hugging face官网免费申请一个token
login(hf_token)
3.3智能分块与数据预处理模块
在进行语义分块时,我们使用BAAI/bge-small-zh-v1.5嵌入模型,捕捉句子间的语义。
注意,你需要在当前目录创建名为knowledge_base的文件夹,并把书本扔进去。
# ----------------------
# 1. 智能分块预处理
# ----------------------
class SmartDocumentProcessor:
def __init__(self):
# 初始化嵌入模型,使用HuggingFace的BAAI/bge-small-zh-v1.5模型-这个模型专为RAG而生
self.embed_model = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={"device": "cuda"},
encode_kwargs={"batch_size": 16}
)
def _detect_content_type(self, text):
"""动态内容类型检测"""
# 如果文本包含代码相关模式(如def、import、print或代码示例)标记为代码
if re.search(r'def |import |print\(|代码示例', text):
return "code"
elif re.search(r'\|.+\|', text) and '%' in text: # 如果文本包含表格相关模式(如|和百分比),标记为表格
return "table"
return "normal" # 如果不满足上述条件,标记为普通文本
def process_documents(self):
# 加载文档
# 创建加载器列表,处理知识库中的PDF和文本文件
loaders = [
DirectoryLoader("./knowledge_base", glob="**/*.pdf", loader_cls=PyPDFLoader),
DirectoryLoader("./knowledge_base", glob="**/*.txt", loader_cls=TextLoader)
]
# 初始化空列表,用于存储加载的所有文档
documents = []
# 遍历每个加载器,加载文档并添加到documents列表
for loader in loaders:
documents.extend(loader.load())
# 创建语义分块器,使用嵌入模型进行语义分块
chunker = SemanticChunker(
embeddings=self.embed_model, #使用我们的嵌入模型
breakpoint_threshold_amount=82, # 设置断点阈值
add_start_index=True # 启用添加起始索引功能
)
base_chunks = chunker.split_documents(documents) # 使用语义分块器将文档分割为基本块
# 二次动态分块
# 初始化最终分块列表,用于存储二次分块结果
final_chunks = []
# 遍历每个基本块,进行二次动态分块
for chunk in base_chunks:
content_type = self._detect_content_type(chunk.page_content)
if content_type == "code":
# 如果是代码,设置较小的块大小和重叠,用于保持上下文
splitter = RecursiveCharacterTextSplitter(
chunk_size=256, chunk_overlap=64)
elif content_type == "table":
# 如果是表格,设置中等块大小和重叠
splitter = RecursiveCharacterTextSplitter(
chunk_size=384, chunk_overlap=96)
else:
splitter = RecursiveCharacterTextSplitter(
chunk_size=512, chunk_overlap=128)
# 如果是普通文本,设置较大的块大小和重叠
final_chunks.extend(splitter.split_documents([chunk]))
# 使用适当的分割器将块分割为最终块,并添加到列表
# 遍历最终块列表,为每个块添加元数据
for i, chunk in enumerate(final_chunks):
chunk.metadata.update({
"chunk_id": f"chunk_{i}",
"content_type": self._detect_content_type(chunk.page_content)
}) # 更新块的元数据,添加唯一ID和内容类型
return final_chunks
3.4混合检索模块
在创建向量数据库时,我们使用嵌入模型BAAI/bge-large-zh-v1.5将文档块映射为向量。
# ----------------------
# 2. 混合检索系统
# ----------------------
class HybridRetriever:
def __init__(self, chunks):
# 创建向量数据库,使用Chroma存储文档块,嵌入模型为BAAI/bge-large-zh-v1.5
self.vector_db = Chroma.from_documents(
chunks,
embedding=HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5"),
persist_directory="./vector_db"
)
# 创建BM25检索器,从文档块中初始化,初始检索数量为5
self.bm25_retriever = BM25Retriever.from_documents(
chunks,
k=5 # 初始检索数量多于最终需要
)
# 创建混合检索器,结合向量和BM25检索,权重分别为0.6和0.4
self.ensemble_retriever = EnsembleRetriever(
retrievers=[
self.vector_db.as_retriever(search_kwargs={"k": 5}),
self.bm25_retriever
],
weights=[0.6, 0.4]
)
# 初始化重排序模型,使用BAAI/bge-reranker-large
self.reranker = CrossEncoder(
"BAAI/bge-reranker-large",
device="cuda" if torch.has_cuda else "cpu"
)
def retrieve(self, query, top_k=3):
# 第一阶段:使用混合检索器获取相关文档
docs = self.ensemble_retriever.get_relevant_documents(query)
# 第二阶段:为查询和每个文档创建配对,用于重排序
pairs = [[query, doc.page_content] for doc in docs]
scores = self.reranker.predict(pairs)
# 使用重排序模型预测配对的分数
ranked_docs = sorted(zip(docs, scores), key=lambda x: x[1], reverse=True)
# 返回top_k结果
return [doc for doc, _ in ranked_docs[:top_k]]
3.5RAG系统集成
注意:我将已经微调好的模型保存到了:./fine-tune_by_zihu
本文章的代码不包含微调过程,如果你不想微调,想使用现成的模型,按照以下方法修改
在下面EnhancedRAG类里面,在__init__里面,找到
self.model, self.tokenizer = FastLanguageModel.from_pretrained(
"./fine-tune_by_zihu",
max_seq_length=4096
)
修改为
self.model, self.tokenizer = FastLanguageModel.from_pretrained(
"unsloth/DeepSeek-R1-Distill-Qwen-14B",
max_seq_length=4096
)
RAG系统集成代码
# ----------------------
# 3. RAG系统集成
# ----------------------
class EnhancedRAG:
def __init__(self):
# 文档处理
processor = SmartDocumentProcessor()
chunks = processor.process_documents() #整合检索和生成功能
# 初始化混合检索器,使用处理后的分块
self.retriever = HybridRetriever(chunks)
# 加载微调后的语言模型,用于生成回答
#我使用DeepSeek-R1-Distill-Qwen-14B在知乎推理数据集上进行微调
self.model, self.tokenizer = FastLanguageModel.from_pretrained(
"./fine-tune_by_zihu",
max_seq_length=4096
)
# 设置随机种子
torch.manual_seed(666)
# 将模型设置为推理模式
FastLanguageModel.for_inference(self.model)
def generate_prompt(self, question, contexts):
# 格式化上下文,包含来源和类型信息
context_str = "\n\n".join([
f"[来源:{doc.metadata['source']},类型:{doc.metadata['content_type']}]\n{doc.page_content}"
for doc in contexts
])
# 创建提示模板,要求基于上下文回答问题
return f"""你是一个专业助手,请严格根据以下带来源的上下文:
{context_str}
按步骤思考并回答:{question}
如果上下文信息不足,请明确指出缺失的信息。最后用中文给出结构化答案。"""
def ask(self, question):
# 使用检索器获取与问题相关的上下文
contexts = self.retriever.retrieve(question)
# 根据问题和上下文生成提示
prompt = self.generate_prompt(question, contexts)
inputs = self.tokenizer(prompt, return_tensors="pt").to(self.model.device)
# 使用语言模型生成回答
generated_ids = self.model.generate(
inputs["input_ids"],
max_new_tokens=2048,
temperature=0.3,
top_p=0.9,
do_sample=True
)
generated_text = self.tokenizer.decode(generated_ids[0], skip_special_tokens=True)
response = {'choices': [{'text': generated_text}]}
return response['choices'][0]['text']
3.6 RAG启动!
rag = EnhancedRAG()
3.7提问测试
complex_question = "我现在正在学习卷积神经网络,请你讲讲卷积神经网络的应用"
answer = rag.ask(complex_question)
print(f"问题:{complex_question}")
print("答案:")
print(answer)
注意,在知识库里面我上传了一个txt文件,是有关卷积神经网络的百度百科。
卷积神经网络baike.baidu.com/item/%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/17541100
RAG输出为如下所示,请诸位看看效果
问题:我现在正在学习卷积神经网络,请你讲讲卷积神经网络的应用
答案:
你是一个专业助手,请严格根据以下带来源的上下文:
[来源:knowledge_base/卷积神经网络.txt,类型:normal]
遥感科学
卷积神经网络在遥感科学,尤其是卫星遥感中有得到应用,并被认为在解析遥感图像的几何、纹理和空间分布特征时,有计算效率和分类准确度方面的优势 [125]。依据遥感图像的来源和目的,卷积神经网络被用于下垫面使用和类型改变(land use/land cover change) 研究 [67] [126]以及物理量,例如海冰覆盖率(sea-ice concentration)的遥感反演 [127]。此外卷积神经网络被用于遥感图像的物体识别 [128]和图像语义分割 [129],后两者是直接的计算机视觉问题,这里不再赘述。
大气科学
在大气科学中,卷积神经网络被用于数值模式格点输出的后处理问题,包括统计降尺度(Statistical Downscaling, SD)、预报校准、极端天气检测等。
[来源:knowledge_base/卷积神经网络.txt,类型:normal]
包含卷积神经网络的编程模块
现代主流的机器学习库和界面,包括TensorFlow、Keras、Thenao、Microsoft-CNTK等都可以运行卷积神经网络算法。此外一些商用数值计算软件,例如MATLAB也有卷积神经网络的构建工具可用 [135]。
科研应用
播报
编辑
2024年10月消息,中国科研人员利用一种结合GPU相位折叠和卷积神经网络的深度学习算法,在开普勒太空望远镜的恒星测光数据中发现5颗超短周期行星。 [137]
[来源:knowledge_base/卷积神经网络.txt,类型:normal]
其它
物理学
卷积神经网络在包含大数据问题的物理学研究中有得到关注。在高能物理学中,卷积神经网络被用于粒子对撞机(particle colliders)输出的喷流图(jet image)的分析和特征学习,有关研究包括夸克(quark)/胶子(gluon)分类 [120]、W玻色子(W boson)识别 [119]和中微子相互作用(neutrino interaction)研究 [121]等。卷积神经网络在天体物理学中也有应用,有研究使用卷积神经网络对天文望远镜图像进行星系形态学(galaxy morphology)分析 [122]和提取星系模型(galactic model)参数 [123]。利用迁移学习技术,预训练的卷积神经网络可以对LIGO(Laser Interferometer Gravitational-wave Observatory)数据中的噪声(glitch)进行检测,为数据的预处理提供帮助 [124]。
遥感科学
按步骤思考并回答:我现在正在学习卷积神经网络,请你讲讲卷积神经网络的应用
如果上下文信息不足,请明确指出缺失的信息。最后用中文给出结构化答案。
<think>
好的,我现在需要回答用户关于卷积神经网络(CNN)的应用的问题。用户已经提供了一些资料,我需要仔细分析这些内容,确保覆盖所有提到的应用领域,并且结构清晰。
首先,我需要回顾用户提供的资料,看看有哪些主要的应用领域。资料中提到了遥感科学、大气科学、物理学,以及科研应用中的具体例子。每个领域下还有更细分的应用,比如遥感中的下垫面变化、海冰覆盖率,大气科学中的统计降尺度等。
接下来,我需要将这些信息组织成一个结构化的回答。通常,这样的回答可以分为几个主要部分,每个部分对应一个应用领域,然后在每个领域下列出具体的子应用。此外,用户提到的科研应用中的例子,比如超短周期行星的发现,也应该包含进去。
在整理过程中,要注意每个应用的描述是否准确,是否有重复或遗漏。例如,在遥感科学部分,提到了下垫面变化、海冰覆盖率、物体识别和语义分割,但后两者属于计算机视觉,用户提到不需要赘述,所以可能需要简要提及但不展开。大气科学中的统计降尺度、预报校准、极端天气检测,这些都需要简要说明。
物理学部分包括高能物理中的喷流分析、夸克/胶子分类,天体物理中的星系形态学和模型参数提取,以及LIGO的噪声检测。这些都需要详细说明每个应用的具体内容。
另外,用户提供的资料中有一个科研应用的例子,2024年10月中国科研人员利用CNN发现超短周期行星,这个例子应该放在“科研应用”部分,可能需要单独列出。
在组织结构时,可能需要将资料中的内容分为几个大类:遥感科学、大气科学、物理学,以及科研应用中的其他例子。每个大类下再细分具体应用,并给出对应的参考文献编号,但用户可能不需要具体的文献信息,而是应用的名称和领域。
需要注意的是,用户可能希望了解CNN在不同领域的具体应用场景,而不仅仅是列举名称。因此,在每个应用点下,需要简要说明CNN如何被应用,以及其优势,比如计算效率、分类准确度等。
最后,确保回答逻辑清晰,层次分明,每个部分有明确的标题,并且使用适当的术语,但保持易懂。可能还需要检查是否有遗漏的信息,比如大气科学中的统计降尺度是否需要进一步解释,或者物理学中的迁移学习在LIGO中的应用是否需要强调。
总结来说,回答的结构应该是:
1. 遥感科学
- 下垫面变化
- 海冰覆盖率反演
- 物体识别(简要提及)
- 语义分割(简要提及)
2. 大气科学
- 统计降尺度
- 预报校准
- 极端天气检测
3. 物理学
- 高能物理
- 喷流分析
- 夸克/胶子分类
- W玻色子识别
- 中微子相互作用
- 天体物理
- 星系形态学
- 模型参数提取
- LIGO噪声检测
4. 科研应用
- 开普勒望远镜的超短周期行星发现
每个部分需要简要说明CNN的应用及其优势,可能需要合并或调整部分信息,确保流畅和准确。
</think>
卷积神经网络(CNN)在多个科学领域展现了强大的应用能力,以下是其主要应用场景及优势分析:
---
### **1. 遥感科学**
- **下垫面变化监测**
CNN通过分析遥感图像的几何、纹理和空间分布特征,高效识别土地利用/覆盖变化(如城市扩张、森林砍伐),显著提升分类精度。
- **物理量反演**
用于海冰覆盖率、云层高度等物理量的遥感反演,结合深度学习处理多光谱数据的复杂性。
- **计算机视觉延伸**
- **物体识别**:自动检测卫星图像中的特定地物(如建筑物、车辆)。
- **语义分割**:精细标注图像像素,划分不同地表类型。
---
### **2. 大气科学**
- **统计降尺度(SD)**
将全球气候模型的低分辨率数据转换为局地气候预测,CNN通过时空特征提取优化降尺度精度。
- **极端天气检测**
识别卫星或雷达图像中的台风、冰雹等极端天气特征,辅助灾害预警。
- **数值预报校准**
修正气象模型输出的温度、风速等变量,减少预测偏差。
---
### **3. 物理学**
- **高能物理**
- **喷流分析**:解析粒子对撞机产生的喷流图像,学习夸克/胶子、W玻色子等粒子特征。
- **中微子相互作用**:通过LArTPC探测器的三维图像,识别中微子与原子核的相互作用类型。
- **天体物理**
- **星系形态学**:分类星系形状(螺旋/椭圆),提取旋臂等结构特征。
- **模型参数提取**:从望远镜数据中反演星系质量、旋转速度等参数。
- **LIGO噪声检测**
利用预训练CNN识别引力波探测器中的噪声(glitch),过滤数据噪声,提升信号识别率。
---
### **4. 科研应用实例**
- **开普勒望远镜的超短周期行星发现**
2024年,中国团队结合GPU相位折叠和CNN算法,在开普勒数据中发现5颗超短周期行星,展示了深度学习在天体测光数据分析中的潜力。
---
### **CNN优势总结**
- **特征自动提取**:无需手动设计特征,直接从数据学习有效表征。
- **高效计算**:通过卷积操作减少参数量,适合大规模图像处理。
- **迁移学习**:预训练模型(如ResNet、VGG)可快速应用于新任务。
CNN的应用边界仍在扩展,尤其在多模态数据融合(如遥感+气象)和跨学科问题(如气候变化-生态影响)中展现出独特价值。
整个回答的数据结构是
上下文<think>思考</think>回答
4.总结与展望
本文构建了一个RAG,并对RAG做了3点很普通的优化。
①二次语义分块:动态适配代码、表格和文本,提升分块质量。
②混合检索:向量和BM25互补,重排序确保高相关性。
③生成增强:微调模型+优化提示,回答更专业、更可控。
这只是本项目的初始阶段功能尚未完善,在下一阶段,我可能有以下改进:
1️⃣支持连续对话
2️⃣优化pdf文件解析
2024年,中国团队结合GPU相位折叠和CNN算法,在开普勒数据中发现5颗超短周期行星,展示了深度学习在天体测光数据分析中的潜力。
CNN优势总结
- 特征自动提取:无需手动设计特征,直接从数据学习有效表征。
- 高效计算:通过卷积操作减少参数量,适合大规模图像处理。
- 迁移学习:预训练模型(如ResNet、VGG)可快速应用于新任务。
CNN的应用边界仍在扩展,尤其在多模态数据融合(如遥感+气象)和跨学科问题(如气候变化-生态影响)中展现出独特价值。
整个回答的数据结构是
```text
上下文<think>思考</think>回答
4.总结与展望
本文构建了一个RAG,并对RAG做了3点很普通的优化。
①二次语义分块:动态适配代码、表格和文本,提升分块质量。
②混合检索:向量和BM25互补,重排序确保高相关性。
③生成增强:微调模型+优化提示,回答更专业、更可控。
这只是本项目的初始阶段功能尚未完善,在下一阶段,我可能有以下改进:
1️⃣支持连续对话
2️⃣优化pdf文件解析
3️⃣符合理工男审美的优美前端页面
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **


















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











