










【个人主页:玄同765】
大语言模型(LLM)开发工程师|中国传媒大学·数字媒体技术(智能交互与游戏设计)
深耕领域:大语言模型开发 / RAG知识库 / AI Agent落地 / 模型微调
技术栈:Python / LangChain/RAG(Dify+Redis+Milvus)| SQL/NumPy | FastAPI+Docker ️
工程能力:专注模型工程化部署、知识库构建与优化,擅长全流程解决方案
专栏传送门:LLM大模型开发 项目实战指南、Python 从真零基础到纯文本 LLM 全栈实战、从零学 SQL + 大模型应用落地、大模型开发小白专属:从 0 入门 Linux&Shell
「让AI交互更智能,让技术落地更高效」
欢迎技术探讨/项目合作! 关注我,解锁大模型与智能交互的无限可能!
相关 思维导图 下载:
【免费】思维导图:Numpy知识整理.xmind资源-优快云下载
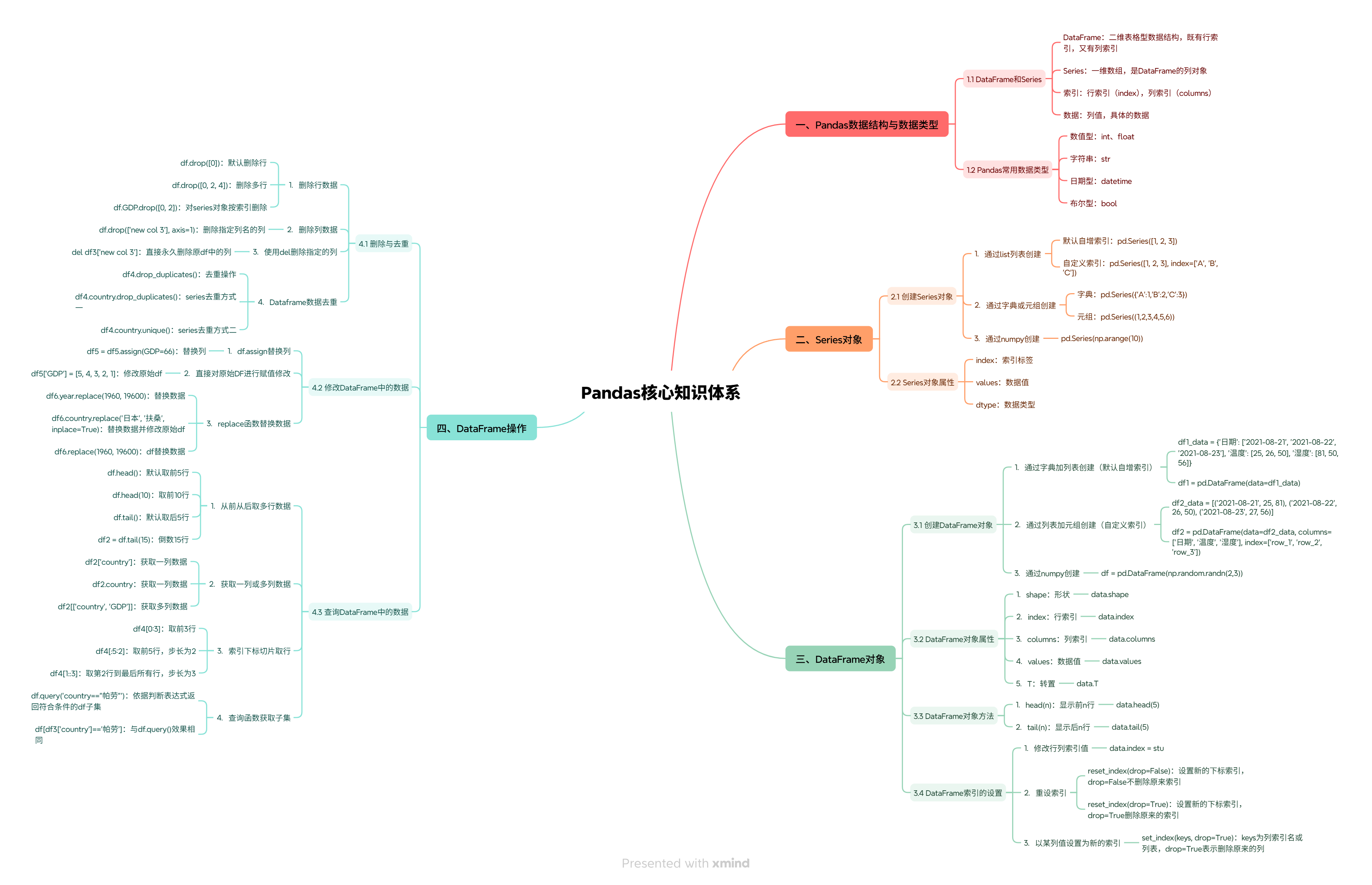
【免费】思维导图:Pandas核心知识体系.xmind资源-优快云下载
【免费】思维导图:Matplotlib数据可视化全攻略.xmind资源-优快云下载
在使用 NumPy 和 Pandas 进行数据分析和处理时,「函数是否有返回值、是否会修改原对象」是一个高频易错点 —— 很多人会因混淆这两类函数导致数据被意外修改、操作无响应或结果不正确。本文将通过功能分类表格和实战代码示例,系统整理 NumPy 与 Pandas 中典型的有无返回值函数,帮助读者避免此类错误。
一、问题引入:一个真实场景的错误
假设你正在处理一份客户购买数据,需要对部分列进行归一化处理:
import pandas as pd
import numpy as np
# 生成模拟数据
data = pd.DataFrame({
'customer_id': [1, 2, 3, 4, 5],
'product_id': [101, 102, 101, 103, 102],
'quantity': [5, 3, 2, 1, 4],
'price': [10.5, 20.0, 10.5, 30.0, 20.0]
})
# 归一化quantity列
# 错误做法:直接调用DataFrame的apply方法,未赋值
data['quantity'].apply(lambda x: (x - np.min(data['quantity'])) / (np.max(data['quantity']) - np.min(data['quantity'])))
# 打印结果,发现quantity列未变化
print(data['quantity'])
错误原因:DataFrame.apply()方法会返回一个新的 Series 对象,不会直接修改原列。正确做法是将返回值赋值给原列或新列。
二、NumPy 中有无返回值函数整理
NumPy 中的函数按是否修改原数组分为两类:返回新数组的函数和直接修改原数组的函数(通常以_结尾,称为「原地操作函数」)。
2.1 NumPy 功能分类表格
| 功能分类 | 函数名 | 功能 | 是否有返回值 | 原数组是否改变 | 代码示例 |
|---|---|---|---|---|---|
| 数组创建 | np.array | 从列表 / 元组创建数组 | 是 | 否 | arr = np.array([1, 2, 3]) |
| np.zeros | 创建全零数组 | 是 | 否 | arr = np.zeros(5) | |
| np.ones | 创建全一数组 | 是 | 否 | arr = np.ones(5) | |
| 形状修改 | arr.reshape | 改变数组形状 | 是 | 否 | new_arr = arr.reshape(2, 3) |
| arr.resize | 改变数组形状(可原地) | 否(无返回) | 是(原地修改) | arr.resize(2, 3) | |
| arr.T | 数组转置 | 是 | 否 | new_arr = arr.T | |
| 数据操作 | np.add | 数组加法(向量化) | 是 | 否 | new_arr = np.add(arr1, arr2) |
| arr1 + arr2 | 数组加法(运算符重载) | 是 | 否 | new_arr = arr1 + arr2 | |
| arr.fill | 数组填充值 | 否(无返回) | 是(原地修改) | arr.fill(0) | |
| np.where | 条件索引 | 是 | 否 | new_arr = np.where(arr > 0, arr, 0) | |
| 统计计算 | np.sum | 数组求和 | 是 | 否 | sum_result = np.sum(arr) |
| np.mean | 数组平均值 | 是 | 否 | mean_result = np.mean(arr) | |
| np.max | 数组最大值 | 是 | 否 | max_result = np.max(arr) | |
| 原地操作 | arr += arr2 | 原地加法 | 否(无返回) | 是(原地修改) | arr += arr2 |
| arr.sort | 原地排序 | 否(无返回) | 是(原地修改) | arr.sort() | |
| arr.flatten | 数组扁平化(返回拷贝) | 是 | 否 | new_arr = arr.flatten() | |
| arr.ravel | 数组扁平化(返回视图) | 是 | 否 | new_arr = arr.ravel() |
2.2 NumPy 实战易错点示例
示例 1:混淆 reshape 与 resize
import numpy as np
# 创建数组
arr = np.array([1, 2, 3, 4, 5, 6])
# reshape:返回新数组,原数组不变
new_arr1 = arr.reshape(2, 3)
print(f"reshape后原数组:{arr}") # [1 2 3 4 5 6](未变化)
print(f"reshape后新数组:\n{new_arr1}")
# resize:原地修改,无返回值
arr.resize(2, 3)
print(f"resize后原数组:\n{arr}") # [[1 2 3] [4 5 6]](已变化)
示例 2:混淆 sort 与 sorted
import numpy as np
# 创建数组
arr = np.array([3, 1, 4, 1, 5, 9, 2, 6])
# sorted:返回新数组,原数组不变
new_arr1 = sorted(arr)
print(f"sorted后原数组:{arr}") # [3 1 4 1 5 9 2 6](未变化)
print(f"sorted后新数组:{new_arr1}")
# arr.sort:原地修改,无返回值
arr.sort()
print(f"arr.sort后原数组:{arr}") # [1 1 2 3 4 5 6 9](已变化)
三、Pandas 中有无返回值函数整理
Pandas 中的函数同样分为返回新对象的函数和直接修改原对象的函数(通常有inplace=True参数)。Pandas 的函数更多,我们按Series 操作和DataFrame 操作分类整理。
3.1 Series 操作分类表格
| 功能分类 | 函数名 | 功能 | 是否有返回值 | 原对象是否改变(默认) | 代码示例 |
|---|---|---|---|---|---|
| 数据操作 | s.apply | 应用自定义函数 | 是 | 否 | new_s = s.apply(lambda x: x*2) |
| s.map | 应用字典 / Series / 函数 | 是 | 否 | new_s = s.map({1: 'A', 2: 'B'}) | |
| s.replace | 替换值 | 是 | 否 | new_s = s.replace(1, 'A') | |
| 数据过滤 | s[s > 0] | 条件过滤 | 是 | 否 | new_s = s[s > 0] |
| 统计计算 | s.sum | 求和 | 是 | 否 | sum_result = s.sum() |
| s.mean | 平均值 | 是 | 否 | mean_result = s.mean() | |
| 原地操作 | s.fillna | 填充缺失值 | 是(默认) | 否(默认) | new_s = s.fillna(0) 或 s.fillna(0, inplace=True) |
| s.dropna | 删除缺失值 | 是(默认) | 否(默认) | new_s = s.dropna() 或 s.dropna(inplace=True) | |
| s.sort_values | 排序 | 是(默认) | 否(默认) | new_s = s.sort_values() 或 s.sort_values(inplace=True) |
3.2 DataFrame 操作分类表格
| 功能分类 | 函数名 | 功能 | 是否有返回值 | 原对象是否改变(默认) | 代码示例 |
|---|---|---|---|---|---|
| 数据操作 | df.apply | 应用自定义函数 | 是 | 否 | new_df = df.apply(lambda x: x*2) |
| df.applymap | 应用自定义函数到每个元素 | 是 | 否 | new_df = df.applymap(lambda x: str(x)) | |
| df.pipe | 链式操作 | 是 | 否 | new_df = df.pipe(lambda x: x[x['quantity'] > 0]) | |
| 形状修改 | df.drop | 删除列 / 行 | 是(默认) | 否(默认) | new_df = df.drop('price', axis=1) 或 df.drop('price', axis=1, inplace=True) |
| df.rename | 重命名列 / 行 | 是(默认) | 否(默认) | new_df = df.rename({'customer_id': 'id'}, axis=1) 或 df.rename({'customer_id': 'id'}, axis=1, inplace=True) | |
| 数据过滤 | df[df['quantity'] > 0] | 条件过滤 | 是 | 否 | new_df = df[df['quantity'] > 0] |
| 合并 / 拼接 | pd.concat | 合并 DataFrame/Series | 是 | 否 | new_df = pd.concat([df1, df2], axis=0) |
| pd.merge | 合并 DataFrame(类似 SQL) | 是 | 否 | new_df = pd.merge(df1, df2, on='customer_id') | |
| 原地操作 | df.fillna | 填充缺失值 | 是(默认) | 否(默认) | new_df = df.fillna(0) 或 df.fillna(0, inplace=True) |
| df.dropna | 删除缺失值 | 是(默认) | 否(默认) | new_df = df.dropna() 或 df.dropna(inplace=True) | |
| df.sort_values | 排序 | 是(默认) | 否(默认) | new_df = df.sort_values('quantity') 或 df.sort_values('quantity', inplace=True) |
3.3 Pandas 实战易错点示例
示例 1:未使用 inplace=True 参数
import pandas as pd
# 创建DataFrame
data = pd.DataFrame({
'customer_id': [1, 2, 3, 4, 5],
'product_id': [101, 102, 101, 103, 102],
'quantity': [5, 3, 2, 1, 4],
'price': [10.5, 20.0, 10.5, 30.0, 20.0]
})
# 错误做法:直接调用drop方法,未赋值或使用inplace=True
data.drop('price', axis=1)
# 打印结果,发现price列未变化
print(data.columns) # Index(['customer_id', 'product_id', 'quantity', 'price'], dtype='object')
# 正确做法1:赋值给新DataFrame
new_data1 = data.drop('price', axis=1)
print(new_data1.columns) # Index(['customer_id', 'product_id', 'quantity'], dtype='object')
# 正确做法2:使用inplace=True参数
data.drop('price', axis=1, inplace=True)
print(data.columns) # Index(['customer_id', 'product_id', 'quantity'], dtype='object')
示例 2:混淆 apply 与 applymap
import pandas as pd
import numpy as np
# 创建DataFrame
data = pd.DataFrame({
'customer_id': [1, 2, 3, 4, 5],
'product_id': [101, 102, 101, 103, 102],
'quantity': [5, 3, 2, 1, 4],
'price': [10.5, 20.0, 10.5, 30.0, 20.0]
})
# apply:应用到列(默认axis=0)或行(axis=1)
total_price = data.apply(lambda x: x['quantity'] * x['price'] if x.name == 'total' else x, axis=0) # 错误用法,apply默认作用于列
total_price = data.apply(lambda x: x['quantity'] * x['price'], axis=1) # 正确用法,作用于行
data['total_price'] = total_price
print(data['total_price'])
# applymap:应用到每个元素
data_str = data.applymap(lambda x: str(x))
print(data_str.dtypes) # 所有列都是object类型
四、总结
通过本文的整理,我们可以看出 NumPy 与 Pandas 中「有无返回值函数」的规律:
- NumPy:大部分函数会返回新数组,不会修改原数组;原地操作函数通常以
_结尾,无返回值,会直接修改原数组。 - Pandas:大部分函数会返回新对象,不会修改原对象;原地操作需要使用
inplace=True参数,使用后无返回值,会直接修改原对象。
在实际开发中,我们应该:
- 优先使用返回新对象的函数,这样可以保留原数据,便于调试和错误恢复。
- 如果需要节省内存或必须修改原对象,可以使用原地操作函数,但要确保操作的正确性。
- 对不熟悉的函数,可以先查看官方文档或进行小范围测试,确认其是否有返回值、是否会修改原对象。


















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









