









【个人主页:玄同765】
大语言模型(LLM)开发工程师|中国传媒大学·数字媒体技术(智能交互与游戏设计)
深耕领域:大语言模型开发 / RAG知识库 / AI Agent落地 / 模型微调
技术栈:Python / LangChain/RAG(Dify+Redis+Milvus)| SQL/NumPy | FastAPI+Docker ️
工程能力:专注模型工程化部署、知识库构建与优化,擅长全流程解决方案
专栏传送门:LLM大模型开发 项目实战指南、Python 从真零基础到纯文本 LLM 全栈实战、从零学 SQL + 大模型应用落地、大模型开发小白专属:从 0 入门 Linux&Shell
「让AI交互更智能,让技术落地更高效」
欢迎技术探讨/项目合作! 关注我,解锁大模型与智能交互的无限可能
相关 思维导图 下载:
【免费】思维导图:Numpy知识整理.xmind资源-优快云下载
【免费】思维导图:Pandas核心知识体系.xmind资源-优快云下载
【免费】思维导图:Matplotlib数据可视化全攻略.xmind资源-优快云下载
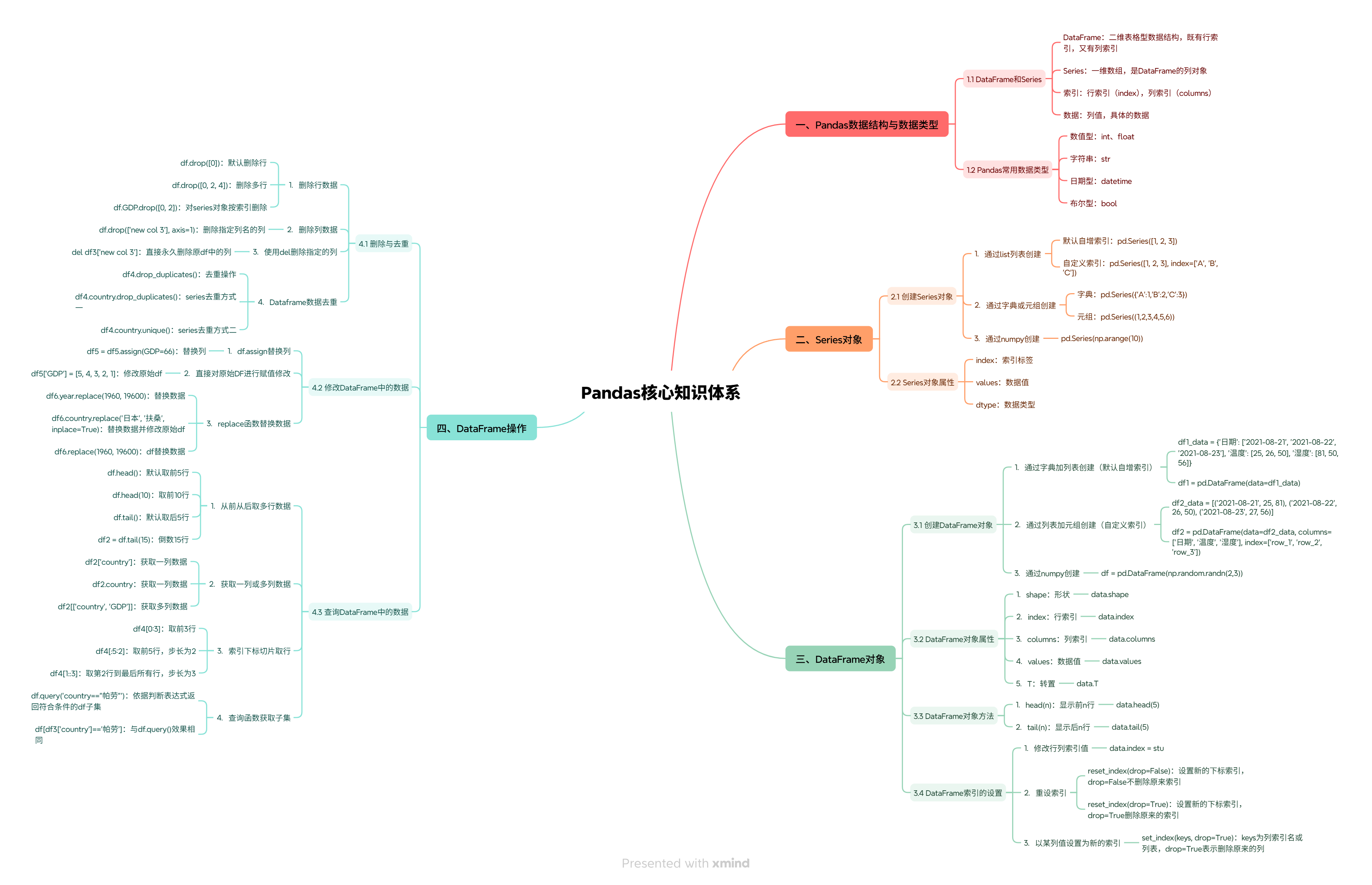
引言
数据是大语言模型(LLM)开发的 “燃料”,从训练数据的收集整理、向量入库前的清洗标准化,到 RAG(检索增强生成)的召回结果处理,再到生成内容的质量评估,每个环节都离不开高效的数据处理工具。Pandas 作为 Python 生态中最强大的数据处理库,凭借其直观的 API、丰富的功能和高性能的处理能力,成为 LLM 开发工程师的首选工具。
本文从零基础开始,系统讲解 Pandas 的核心概念和常用操作,并结合 LLM 开发的实际场景,通过完整的项目案例,展示如何利用 Pandas 解决 LLM 开发中的数据处理问题。
基础篇:Pandas 环境与核心数据结构
1.1 环境搭建
1.1.1 Anaconda 安装
Anaconda 是 Python 的集成开发环境,包含了 Pandas、NumPy、Jupyter Notebook 等 LLM 开发常用的库。
安装步骤:
- 访问Anaconda 官网,下载对应操作系统的安装包;
- 双击安装包,按照提示完成安装;
- 安装完成后,打开 Anaconda Navigator,启动 Jupyter Notebook。
1.1.2 Pandas 安装
如果已经安装了 Anaconda,Pandas 已经默认安装。如果没有安装,可以通过以下命令安装:
pip install pandas
1.1.3 Jupyter Notebook 使用
Jupyter Notebook 是一种交互式笔记本,支持代码、文本、图表的混合编写,非常适合数据处理和分析。
基本操作:
- 启动 Jupyter Notebook 后,会在浏览器中打开一个页面;
- 点击 “New”→“Python 3”,创建一个新的笔记本;
- 在单元格中输入代码,按 Shift+Enter 执行代码。
1.2 核心数据结构
Pandas 有两种核心数据结构:Series 和 DataFrame。
1.2.1 Series
Series 是一种一维数组,类似于 Python 的列表,但可以存储不同类型的数据,并带有标签(索引)。
创建 Series:
import pandas as pd
import numpy as np
# 从列表创建
s1 = pd.Series([1, 2, 3, 4, 5])
print("从列表创建的Series:")
print(s1)
# 从NumPy数组创建
s2 = pd.Series(np.array([10, 20, 30, 40, 50]))
print("\n从NumPy数组创建的Series:")
print(s2)
# 带标签的Series
s3 = pd.Series([1, 2, 3, 4, 5], index=["a", "b", "c", "d", "e"])
print("\n带标签的Series:")
print(s3)
Series 的属性:
| 属性 | 描述 |
|---|---|
values | 返回 Series 的值(NumPy 数组) |
index | 返回 Series 的索引 |
dtype | 返回 Series 的数据类型 |
size | 返回 Series 的长度 |
Series 的常用操作:
# 访问值
print("访问值:")
print(s3["a"]) # 输出1
print(s3[0]) # 输出1
# 切片
print("\n切片:")
print(s3["b":"d"]) # 输出b:2, c:3, d:4
print(s3[1:3]) # 输出b:2, c:3
# 过滤
print("\n过滤:")
print(s3[s3 > 3]) # 输出d:4, e:5
# 运算
print("\n运算:")
print(s3 + 10) # 每个元素加10
print(s3 * 2) # 每个元素乘2
1.2.2 DataFrame
DataFrame 是一种二维表格数据结构,类似于 Excel 的工作表,由行和列组成,每列可以是不同类型的数据。
创建 DataFrame:
# 从字典创建
data = {
"姓名": ["张三", "李四", "王五", "赵六"],
"年龄": [18, 19, 20, 21],
"性别": ["男", "女", "男", "女"],
"成绩": [90, 85, 95, 88]
}
df1 = pd.DataFrame(data)
print("从字典创建的DataFrame:")
print(df1)
# 从CSV文件创建
# df2 = pd.read_csv("data.csv")
# 从Excel文件创建
# df3 = pd.read_excel("data.xlsx")
DataFrame 的结构:
| 行索引 | 姓名 | 年龄 | 性别 | 成绩 |
|---|---|---|---|---|
| 0 | 张三 | 18 | 男 | 90 |
| 1 | 李四 | 19 | 女 | 85 |
| 2 | 王五 | 20 | 男 | 95 |
| 3 | 赵六 | 21 | 女 | 88 |
DataFrame 的属性:
| 属性 | 描述 |
|---|---|
values | 返回 DataFrame 的值(二维 NumPy 数组) |
index | 返回 DataFrame 的行索引 |
columns | 返回 DataFrame 的列索引 |
dtypes | 返回 DataFrame 的数据类型 |
shape | 返回 DataFrame 的形状(行数,列数) |
size | 返回 DataFrame 的总元素数 |
DataFrame 的常用操作:
# 查看数据
print("查看前3行:")
print(df1.head(3))
print("\n查看后2行:")
print(df1.tail(2))
print("\n查看数据信息:")
print(df1.info())
print("\n查看数据统计:")
print(df1.describe())
# 访问列
print("\n访问姓名列:")
print(df1["姓名"]) # 返回Series
print("\n访问姓名和成绩列:")
print(df1[["姓名", "成绩"]]) # 返回DataFrame
# 访问行
print("\n访问第0行:")
print(df1.loc[0]) # 返回Series
print("\n访问第0到1行:")
print(df1.loc[0:1]) # 返回DataFrame
# 访问单元格
print("\n访问第0行第1列:")
print(df1.loc[0, "年龄"]) # 输出18
# 过滤
print("\n过滤成绩大于90的学生:")
print(df1[df1["成绩"] > 90])
# 排序
print("\n按成绩降序排序:")
print(df1.sort_values(by="成绩", ascending=False))
# 添加列
df1["班级"] = ["一年级一班", "一年级二班", "一年级一班", "一年级二班"]
print("\n添加班级列后的DataFrame:")
print(df1)
# 删除列
df1.drop(columns=["班级"], inplace=True)
print("\n删除班级列后的DataFrame:")
print(df1)
进阶篇:LLM 开发中的数据清洗
数据清洗是 LLM 开发的第一步,也是最关键的一步。LLM 训练数据中的重复文本、缺失值、异常值会严重影响模型的训练效果和预测质量。
2.1 重复值处理
重复值是指完全相同的文本或数据。在 LLM 训练中,重复值会导致模型过度拟合,降低模型的泛化能力。
查找重复值:
# 导入数据
data = {
"文本": [
"这是一段重复的文本",
"这是一段重复的文本",
"这是一段唯一的文本1",
"这是一段唯一的文本2",
"这是一段重复的文本"
]
}
df = pd.DataFrame(data)
# 查找重复值
print("重复值:")
print(df[df.duplicated()])
# 统计重复值数量
print("\n重复值数量:")
print(df.duplicated().sum())
删除重复值:
# 删除重复值
df.drop_duplicates(inplace=True)
print("删除重复值后的DataFrame:")
print(df)
2.2 缺失值处理
缺失值是指数据中缺少的部分。在 LLM 训练中,缺失值会导致训练失败或模型预测错误。
查找缺失值:
# 导入数据
data = {
"文本": [
"这是一段完整的文本1",
"这是一段完整的文本2",
None,
"这是一段完整的文本4",
None
]
}
df = pd.DataFrame(data)
# 查找缺失值
print("缺失值:")
print(df[df["文本"].isnull()])
# 统计缺失值数量
print("\n缺失值数量:")
print(df["文本"].isnull().sum())
缺失值可视化:
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制缺失值分布
sns.heatmap(df.isnull(), cbar=False, cmap="viridis")
plt.title("缺失值分布")
plt.xlabel("列")
plt.ylabel("行")
plt.show()
缺失值处理方法:
| 方法 | 描述 | 适用场景 |
|---|---|---|
| 删除 | 删除包含缺失值的行或列 | 缺失值较少,且删除后不影响数据完整性 |
| 填充 | 用固定值、均值、中位数、众数或相邻值填充缺失值 | 缺失值较多,且需要保留数据 |
删除缺失值:
# 删除包含缺失值的行
df.dropna(inplace=True)
print("删除缺失值后的DataFrame:")
print(df)
填充缺失值:
# 用固定值填充
df["文本"].fillna("这是一段默认文本", inplace=True)
print("用固定值填充后的DataFrame:")
print(df)
2.3 异常值处理
异常值是指与其他数据差异较大的数值或文本。在 LLM 训练中,异常值会影响模型的预测结果。
查找异常值:
# 导入数据
data = {
"文本": [
"这是一段正常的文本1",
"这是一段正常的文本2",
"这是一段非常非常非常非常非常非常非常非常长的文本",
"这是一段正常的文本4",
"这是一段正常的文本5"
],
"长度": [15, 16, 100, 17, 18]
}
df = pd.DataFrame(data)
# 绘制箱线图查找异常值
plt.boxplot(df["长度"])
plt.title("文本长度箱线图")
plt.ylabel("长度")
plt.show()
# 查找异常值(大于Q3+1.5*IQR或小于Q1-1.5*IQR)
Q1 = df["长度"].quantile(0.25)
Q3 = df["长度"].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
print("异常值:")
print(df[(df["长度"] < lower_bound) | (df["长度"] > upper_bound)])
异常值处理方法:
| 方法 | 描述 | 适用场景 |
|---|---|---|
| 删除 | 删除包含异常值的行或列 | 异常值较少,且删除后不影响数据完整性 |
| 截断 | 将异常值替换为上下边界值 | 异常值较多,且需要保留数据 |
截断异常值:
df["长度"] = np.where(df["长度"] > upper_bound, upper_bound, df["长度"])
df["长度"] = np.where(df["长度"] < lower_bound, lower_bound, df["长度"])
print("截断异常值后的DataFrame:")
print(df)
LLM 开发关联篇:核心场景的数据处理
3.1 LLM 训练数据的预处理
3.1.1 文本数据的清洗
去噪:
import re
def clean_text(text):
# 去除HTML标签
text = re.sub(r"<[^>]+>", "", text)
# 去除特殊字符
text = re.sub(r"[^a-zA-Z0-9\u4e00-\u9fff\s]", "", text)
# 去除多余空格
text = re.sub(r"\s+", " ", text).strip()
return text
# 导入数据
data = {
"文本": [
"<p>这是一段<em>包含HTML标签</em>的文本</p>",
"这是一段包含特殊字符!@#$%^&*()的文本",
"这是一段 包含多余空格的文本"
]
}
df = pd.DataFrame(data)
# 清洗文本
df["清洗后的文本"] = df["文本"].apply(clean_text)
print("清洗后的DataFrame:")
print(df)
分词:
import jieba
def tokenize(text):
return list(jieba.cut(text))
# 导入数据
data = {
"文本": ["这是一段中文文本", "这是另一段中文文本"]
}
df = pd.DataFrame(data)
# 分词
df["分词后的文本"] = df["文本"].apply(tokenize)
print("分词后的DataFrame:")
print(df)
去停用词:
# 停用词表(示例)
stopwords = ["这是", "一段", "的"]
def remove_stopwords(tokens):
return [token for token in tokens if token not in stopwords]
# 导入数据
data = {
"分词后的文本": [["这是", "一段", "中文", "文本"], ["这是", "另一段", "中文", "文本"]]
}
df = pd.DataFrame(data)
# 去停用词
df["去停用词后的文本"] = df["分词后的文本"].apply(remove_stopwords)
print("去停用词后的DataFrame:")
print(df)
3.1.2 标签的处理
标签的编码:
from sklearn.preprocessing import LabelEncoder
# 导入数据
data = {
"文本": ["这是一段正面情感的文本", "这是一段负面情感的文本", "这是一段中性情感的文本"],
"标签": ["正面", "负面", "中性"]
}
df = pd.DataFrame(data)
# 标签编码
le = LabelEncoder()
df["编码后的标签"] = le.fit_transform(df["标签"])
print("编码后的DataFrame:")
print(df)
# 查看标签和编码的对应关系
print("\n标签和编码的对应关系:")
print(dict(zip(le.classes_, le.transform(le.classes_))))
3.1.3 数据的划分
随机划分:
from sklearn.model_selection import train_test_split
# 导入数据
data = {
"文本": ["文本1", "文本2", "文本3", "文本4", "文本5", "文本6"],
"标签": ["正面", "负面", "中性", "正面", "负面", "中性"]
}
df = pd.DataFrame(data)
# 划分训练集、验证集、测试集
train_df, temp_df = train_test_split(df, test_size=0.4, random_state=42)
val_df, test_df = train_test_split(temp_df, test_size=0.5, random_state=42)
print("训练集:")
print(train_df)
print("\n验证集:")
print(val_df)
print("\n测试集:")
print(test_df)
分层划分:
from sklearn.model_selection import train_test_split
# 导入数据
data = {
"文本": ["文本1", "文本2", "文本3", "文本4", "文本5", "文本6"],
"标签": ["正面", "负面", "中性", "正面", "负面", "中性"]
}
df = pd.DataFrame(data)
# 分层划分(保持标签分布一致)
train_df, temp_df = train_test_split(df, test_size=0.4, random_state=42, stratify=df["标签"])
val_df, test_df = train_test_split(temp_df, test_size=0.5, random_state=42, stratify=temp_df["标签"])
print("训练集标签分布:")
print(train_df["标签"].value_counts())
print("\n验证集标签分布:")
print(val_df["标签"].value_counts())
print("\n测试集标签分布:")
print(test_df["标签"].value_counts())
3.2 向量数据库的前处理
3.2.1 文本的向量化
from sentence_transformers import SentenceTransformer
# 加载预训练模型
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
# 导入数据
data = {
"文本": ["这是一段中文文本", "这是另一段中文文本", "这是一段英文文本", "这是另一段英文文本"]
}
df = pd.DataFrame(data)
# 向量化
df["向量"] = df["文本"].apply(lambda x: model.encode(x).tolist())
print("向量化后的DataFrame:")
print(df)
3.2.2 向量的存储
# 存储到CSV文件
df.to_csv("vector_data.csv", index=False)
# 读取CSV文件
df = pd.read_csv("vector_data.csv")
# 将向量列从字符串转换为列表
import ast
df["向量"] = df["向量"].apply(ast.literal_eval)
print("读取后的DataFrame:")
print(df)
3.3 RAG 的召回结果处理
3.3.1 召回结果的排序
# 导入数据(召回结果)
data = {
"文档ID": [1, 2, 3, 4, 5],
"文本": ["文档1", "文档2", "文档3", "文档4", "文档5"],
"相似度": [0.95, 0.85, 0.90, 0.80, 0.92]
}
df = pd.DataFrame(data)
# 按相似度降序排序
df_sorted = df.sort_values(by="相似度", ascending=False)
print("按相似度排序后的DataFrame:")
print(df_sorted)
3.3.2 召回结果的去重
# 导入数据(包含重复文档)
data = {
"文档ID": [1, 2, 3, 1, 4],
"文本": ["文档1", "文档2", "文档3", "文档1", "文档4"],
"相似度": [0.95, 0.85, 0.90, 0.88, 0.80]
}
df = pd.DataFrame(data)
# 去重(保留相似度最高的文档)
df_deduped = df.sort_values(by="相似度", ascending=False).drop_duplicates(subset=["文档ID"], keep="first")
print("去重后的DataFrame:")
print(df_deduped)
3.3.3 召回结果的格式化
# 导入数据(召回结果)
data = {
"文档ID": [1, 2, 3],
"文本": ["文档1的内容...", "文档2的内容...", "文档3的内容..."],
"相似度": [0.95, 0.90, 0.85]
}
df = pd.DataFrame(data)
# 格式化召回结果
formatted = []
for _, row in df.iterrows():
formatted.append(f"文档ID:{row['文档ID']}\n相似度:{row['相似度']:.2f}\n内容:{row['文本']}")
# 打印格式化后的结果
for doc in formatted:
print(doc)
print("-" * 50)
3.4 LLM 生成结果的分析
3.4.1 生成结果的长度分析
# 导入数据(生成结果)
data = {
"生成结果": [
"这是一个短回答",
"这是一个稍长的回答,包含了更多的内容",
"这是一个非常详细的回答,包含了大量的信息和例子",
"短回答",
"详细回答..."
]
}
df = pd.DataFrame(data)
# 计算长度
df["长度"] = df["生成结果"].apply(len)
print("生成结果长度分析:")
print(df["长度"].describe())
# 绘制长度分布直方图
plt.hist(df["长度"], bins=10)
plt.title("生成结果长度分布")
plt.xlabel("长度")
plt.ylabel("数量")
plt.show()
3.4.2 生成结果的相似度分析
from sentence_transformers import SentenceTransformer, util
# 加载预训练模型
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
# 导入数据(问题和生成结果)
data = {
"问题": ["什么是LLM?", "什么是LLM?", "什么是RAG?", "什么是RAG?"],
"生成结果": [
"LLM是大语言模型的缩写",
"大语言模型是一种基于深度学习的自然语言处理模型",
"RAG是检索增强生成的缩写",
"检索增强生成是一种结合检索和生成的自然语言处理技术"
]
}
df = pd.DataFrame(data)
# 计算相似度
df["问题向量"] = df["问题"].apply(lambda x: model.encode(x))
df["生成结果向量"] = df["生成结果"].apply(lambda x: model.encode(x))
df["相似度"] = df.apply(lambda row: util.cos_sim(row["问题向量"], row["生成结果向量"]).item(), axis=1)
print("生成结果相似度分析:")
print(df[["问题", "生成结果", "相似度"]])
3.4.3 生成结果的质量评估
from datasets import load_metric
# 加载Rouge指标
rouge = load_metric("rouge")
# 导入数据(参考答案和生成结果)
data = {
"参考答案": [
"LLM是大语言模型的缩写,是一种基于深度学习的自然语言处理模型,能够理解和生成人类语言。",
"RAG是检索增强生成的缩写,是一种结合检索和生成的自然语言处理技术,能够从外部知识库中检索相关信息并生成答案。"
],
"生成结果": [
"LLM是大语言模型的缩写,是一种基于深度学习的自然语言处理模型,能够理解和生成人类语言。",
"RAG是检索增强生成的缩写,能够从外部知识库中检索相关信息并生成答案。"
]
}
df = pd.DataFrame(data)
# 计算Rouge得分
results = rouge.compute(predictions=df["生成结果"], references=df["参考答案"])
print("Rouge得分:")
print(f"Rouge-1:{results['rouge1'].mid.fmeasure:.4f}")
print(f"Rouge-2:{results['rouge2'].mid.fmeasure:.4f}")
print(f"Rouge-L:{results['rougeL'].mid.fmeasure:.4f}")
实战篇:基于 RAG 的问答系统数据处理
4.1 项目概述
本项目将利用 Pandas 和 LLM 开发一个基于 RAG 的问答系统。系统的流程如下:
- 数据准备:收集相关文档,清洗和预处理数据;
- 向量入库:将文档向量化,并存储到向量数据库(ChromaDB);
- 检索阶段:用户输入问题,系统从向量数据库中检索相关文档;
- 生成阶段:系统将问题和检索到的文档发送给 LLM,生成答案;
- 结果处理:对 LLM 生成的答案进行格式化和质量评估。
4.2 数据准备
4.2.1 收集文档
本项目使用维基百科的 Python 相关文档作为知识库。
4.2.2 清洗和预处理数据
# 导入数据
data = {
"文档ID": [1, 2, 3, 4, 5],
"标题": ["Python概述", "Python语法", "Python数据类型", "Python函数", "Python模块"],
"内容": [
"Python是一种高级编程语言,由Guido van Rossum于1991年创建。",
"Python的语法简洁易懂,采用缩进式语法。",
"Python支持多种数据类型,包括整数、浮点数、字符串、列表、字典等。",
"函数是Python中的基本构建块,用于封装代码。",
"模块是Python中的代码组织单元,用于重用代码。"
]
}
df = pd.DataFrame(data)
# 清洗和预处理数据
df["清洗后的内容"] = df["内容"].apply(clean_text)
print("清洗后的DataFrame:")
print(df)
4.3 向量入库
4.3.1 安装 ChromaDB
pip install chromadb
4.3.2 将文档向量化并存储到 ChromaDB
import chromadb
from chromadb.utils import embedding_functions
# 初始化ChromaDB
client = chromadb.Client()
# 创建集合
collection = client.create_collection(name="python_knowledge_base", embedding_function=embedding_functions.SentenceTransformerEmbeddingFunction(model_name="paraphrase-multilingual-MiniLM-L12-v2"))
# 向集合中添加文档
collection.add(
documents=df["清洗后的内容"].tolist(),
metadatas=[{"标题": title} for title in df["标题"].tolist()],
ids=[str(doc_id) for doc_id in df["文档ID"].tolist()]
)
# 验证文档是否添加成功
documents = collection.get()
print("添加的文档:")
print(documents)
4.4 检索阶段
# 导入数据(问题)
data = {"问题": ["什么是Python?", "Python支持哪些数据类型?", "什么是Python函数?"]}
df = pd.DataFrame(data)
# 检索相关文档
def retrieve_documents(query, top_k=3):
results = collection.query(query_texts=[query], n_results=top_k)
return results
df["检索结果"] = df["问题"].apply(lambda x: retrieve_documents(x))
print("检索结果:")
print(df)
4.5 生成阶段
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 加载预训练模型和分词器
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
# 生成答案
def generate_answer(query, documents):
prompt = f"问题:{query}\n参考文档:{documents}\n答案:"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_length=1024, temperature=0.7)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answer.split("答案:")[1].strip()
# 格式化检索结果
def format_documents(retrieve_result):
formatted = []
for i, (doc, metadata) in enumerate(zip(retrieve_result["documents"][0], retrieve_result["metadatas"][0])):
formatted.append(f"文档{i+1}:{doc}({metadata['标题']})")
return "\n".join(formatted)
df["格式化后的检索结果"] = df["检索结果"].apply(format_documents)
df["生成结果"] = df.apply(lambda row: generate_answer(row["问题"], row["格式化后的检索结果"]), axis=1)
print("生成结果:")
print(df)
4.6 结果处理
# 生成结果的质量评估
from datasets import load_metric
rouge = load_metric("rouge")
# 参考答案
reference_answers = [
"Python是一种高级编程语言,由Guido van Rossum于1991年创建,语法简洁易懂,采用缩进式语法。",
"Python支持多种数据类型,包括整数、浮点数、字符串、列表、字典等。",
"函数是Python中的基本构建块,用于封装代码。"
]
df["参考答案"] = reference_answers
results = rouge.compute(predictions=df["生成结果"], references=df["参考答案"])
print("Rouge得分:")
print(f"Rouge-1:{results['rouge1'].mid.fmeasure:.4f}")
print(f"Rouge-2:{results['rouge2'].mid.fmeasure:.4f}")
print(f"Rouge-L:{results['rougeL'].mid.fmeasure:.4f}")
总结
Pandas 作为 Python 生态中最强大的数据处理库,在 LLM 开发中扮演着重要角色。本文从零基础开始,系统讲解了 Pandas 的核心概念和常用操作,并结合 LLM 开发的实际场景,通过完整的项目案例,展示了如何利用 Pandas 解决 LLM 开发中的数据处理问题。
在 LLM 开发中,Pandas 的主要应用场景包括:
- LLM 训练数据的预处理,包括文本清洗、标签处理、数据划分等;
- 向量数据库的前处理,包括文本向量化、向量存储等;
- RAG 的召回结果处理,包括排序、去重、格式化等;
- LLM 生成结果的分析,包括长度分析、相似度分析、质量评估等。
通过学习和实践本文的内容,读者可以掌握 Pandas 的核心技能,并在 LLM 开发中有效地处理数据,提高模型的训练效果和预测质量。


















 343
343












 到【灌水乐园】发言
到【灌水乐园】发言







