









【个人主页:玄同765】
大语言模型(LLM)开发工程师|中国传媒大学·数字媒体技术(智能交互与游戏设计)
深耕领域:大语言模型开发 / RAG知识库 / AI Agent落地 / 模型微调
技术栈:Python / LangChain/RAG(Dify+Redis+Milvus)| SQL/NumPy | FastAPI+Docker ️
工程能力:专注模型工程化部署、知识库构建与优化,擅长全流程解决方案
专栏传送门:LLM大模型开发 项目实战指南、Python 从真零基础到纯文本 LLM 全栈实战、从零学 SQL + 大模型应用落地、大模型开发小白专属:从 0 入门 Linux&Shell
「让AI交互更智能,让技术落地更高效」
欢迎技术探讨/项目合作! 关注我,解锁大模型与智能交互的无限可能!
在使用 NumPy 和 Pandas 进行数据分析时,axis 参数是一个高频出现但极易混淆的概念 —— 很多人会因误解 axis 的维度索引规则和方向含义,导致操作结果与预期不符。本文将结合底层数据结构和折叠 / 聚合逻辑,系统整理 axis 参数的使用方法和常见误区,并提供对比表格和实战示例,帮助读者彻底理解。
一、问题引入:一个真实场景的错误
假设你正在处理一份销售数据,需要计算每个产品的总销量:
import pandas as pd
# 生成模拟数据
data = pd.DataFrame({
'product_id': [101, 102, 101, 103, 102],
'quantity': [5, 3, 2, 1, 4],
'price': [10.5, 20.0, 10.5, 30.0, 20.0]
})
# 错误做法:使用axis=1计算产品总销量
total_sales = data.groupby('product_id')['quantity'].sum(axis=1)
# 打印结果,发现报错
错误原因:groupby后得到的是分组的 Series 对象(1 维),1 维数组的 axis 参数只能是 0,不能是 1。如果是未分组的 DataFrame 计算每行总销量,才会使用 axis=1。
二、NumPy 的 axis 维度索引与方向含义
NumPy 的核心数据结构是N 维数组(ndarray),它是网格状连续存储的同类型数据。axis 参数的编号和方向由数组的维度索引和形状决定。
2.1 ndarray 的维度索引规则
- NumPy 的维度索引从 0 开始,与数组
shape属性的顺序完全一致。 - 对于 N 维数组,
shape属性是一个长度为 N 的元组,shape[i]表示第 i 维的大小。 - 常见的维度索引与形状对应关系:
- 1 维数组:
shape=(n,),第 0 维是唯一的维度,大小为 n - 2 维数组:
shape=(行数,列数),第 0 维是行方向,大小为行数;第 1 维是列方向,大小为列数 - 3 维数组:
shape=(深度,行数,列数),第 0 维是深度方向,大小为深度;第 1 维是行方向,大小为行数;第 2 维是列方向,大小为列数
- 1 维数组:
2.2 “沿着 axis 方向操作” 的底层逻辑
对 ndarray 进行操作时,“沿着 axis=i 方向” 的含义是将数组在第 i 维上的所有元素折叠 / 聚合为一个值,操作后数组的第 i 维会消失,其余维度大小不变。
2.3 NumPy 常见操作的 axis 含义表格
| 操作类型 | 1 维数组(shape=(n,)) | 2 维数组(shape=(m,n))axis=0 | 2 维数组(shape=(m,n))axis=1 | 3 维数组(shape=(d,m,n))axis=0 | 3 维数组(shape=(d,m,n))axis=1 | 3 维数组(shape=(d,m,n))axis=2 |
|---|---|---|---|---|---|---|
| 求和 | sum (axis=0)→标量 | 每行同一列求和→shape=(n,) | 每列同一行求和→shape=(m,) | 每深度同一行同一列求和→shape=(m,n) | 每深度同一列同一行求和→shape=(d,n) | 每深度同一行同一列求和→shape=(d,m) |
| 求平均值 | mean (axis=0)→标量 | 每行同一列求平均值→shape=(n,) | 每列同一行求平均值→shape=(m,) | 每深度同一行同一列求平均值→shape=(m,n) | 每深度同一列同一行求平均值→shape=(d,n) | 每深度同一行同一列求平均值→shape=(d,m) |
| 求最大值 | max (axis=0)→标量 | 每行同一列求最大值→shape=(n,) | 每列同一行求最大值→shape=(m,) | 每深度同一行同一列求最大值→shape=(m,n) | 每深度同一列同一行求最大值→shape=(d,n) | 每深度同一行同一列求最大值→shape=(d,m) |
| 删除 | delete(axis=0,idx)→shape=(n-1,) | delete(axis=0,idx)→shape=(m-1,n) | delete(axis=1,idx)→shape=(m,n-1) | delete(axis=0,idx)→shape=(d-1,m,n) | delete(axis=1,idx)→shape=(d,m-1,n) | delete(axis=2,idx)→shape=(d,m,n-1) |
2.4 NumPy 实战示例
import numpy as np
# 2维数组示例
arr2 = np.array([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
])
print(f"原数组shape:{arr2.shape}") # (3, 3)
# 沿着axis=0方向求和(每行同一列相加)
sum0 = arr2.sum(axis=0)
print(f"axis=0求和结果:{sum0}") # [12 15 18]
print(f"求和后shape:{sum0.shape}") # (3,)(第0维消失)
# 沿着axis=1方向求和(每列同一行相加)
sum1 = arr2.sum(axis=1)
print(f"axis=1求和结果:{sum1}") # [6 15 24]
print(f"求和后shape:{sum1.shape}") # (3,)(第1维消失)
三、Pandas 的 axis 维度索引与方向含义
Pandas 的核心数据结构是Series(1 维)和DataFrame(2 维),其中 DataFrame 内部由多个共享同一 index(行标签)的 Series(列)组成,本质上是基于 NumPy 的 ndarray 构建的。
3.1 Series 与 DataFrame 的结构对应
- Series:对应 NumPy 的 1 维 ndarray,`shape=(行数,),axis 参数只能是 0。
- DataFrame:对应 NumPy 的 2 维 ndarray,`shape=(行数,列数),内部存储结构是列优先的 Series 集合,axis=0 对应行方向,axis=1 对应列方向。
3.2 “沿着 axis 方向操作” 的底层逻辑
Pandas 的 axis 操作逻辑与 NumPy 基本一致,但表述上更贴合表格结构:
- 对于 DataFrame,“沿着 axis=0 方向操作” 表示对每列数据进行操作(行维度折叠),结果通常是一个 Series(列标签作为 index)。
- 对于 DataFrame,“沿着 axis=1 方向操作” 表示对每行数据进行操作(列维度折叠),结果通常是一个 Series(行标签作为 index)。
3.3 Pandas 常见操作的 axis 含义表格
| 操作类型 | Series(1 维) | DataFrame(2 维)axis=0 | DataFrame(2 维)axis=1 |
|---|---|---|---|
| 求和 | sum (axis=0)→标量 | 对每列数据求和→Series(列标签为 index) | 对每行数据求和→Series(行标签为 index) |
| 求平均值 | mean (axis=0)→标量 | 对每列数据求平均值→Series(列标签为 index) | 对每行数据求平均值→Series(行标签为 index) |
| 求最大值 | max (axis=0)→标量 | 对每列数据求最大值→Series(列标签为 index) | 对每行数据求最大值→Series(行标签为 index) |
| 删除 | drop(labels)→Series(shape=(n-1,)) | drop (labels, axis=0)→删除行→DataFrame(shape=(m-1,n)) | drop (labels, axis=1)→删除列→DataFrame(shape=(m,n-1)) |
| 重命名 | rename(index)→Series | rename (index, axis=0)→重命名行标签→DataFrame | rename (columns, axis=1)→重命名列标签→DataFrame |
| 排序 | sort_values(axis=0)→Series | sort_values (by, axis=0)→按列排序→DataFrame | sort_values (by, axis=1)→按行排序→DataFrame |
3.4 Pandas 实战示例
import pandas as pd
# DataFrame示例
data = pd.DataFrame({
'product_id': [101, 102, 101, 103, 102],
'quantity': [5, 3, 2, 1, 4],
'price': [10.5, 20.0, 10.5, 30.0, 20.0]
})
print(f"原DataFrame:\n{data}")
# 沿着axis=0方向求和(对每列数据求和)
sum0 = data.sum(axis=0)
print(f"axis=0求和结果:\n{sum0}")
# 沿着axis=1方向求和(对每行数据求和)
sum1 = data.sum(axis=1)
print(f"axis=1求和结果:\n{sum1}")
四、常见误区与避免方法
4.1 误区 1:混淆 axis=0 和 axis=1 的方向
很多人刚开始使用时会认为 “axis=0 是行,axis=1 是列”,这种表述过于简单且容易混淆。正确的理解方式是:
- 结合数组的
shape属性,axis 的编号与维度索引一致。 - 理解 “沿着 axis 方向操作” 的底层逻辑 —— 折叠 / 聚合该维度,降低一维。
4.2 误区 2:1 维数组使用 axis=1
Series 和 NumPy 的 1 维 ndarray 只有一个维度,axis 参数只能是 0,使用 axis=1 会报错。
4.3 误区 3:groupby 后使用错误的 axis
groupby后如果只选取了一个列,得到的是分组的 Series 对象(1 维),只能使用 axis=0;如果选取了多个列,得到的是分组的 DataFrame 对象(2 维),可以使用 axis=0 或 axis=1。
五、总结
NumPy 和 Pandas 中 axis 参数的维度索引和方向含义总结如下:
| 库名 | 维度索引规则 | 2 维数组 / DataFrame 的 axis 含义 |
|---|---|---|
| NumPy | 从 0 开始,与 shape 属性顺序一致 | axis=0 对应行方向(shape 第 0 维),axis=1 对应列方向(shape 第 1 维) |
| Pandas | 与 NumPy 一致 | axis=0 表示对每列数据进行操作(行维度折叠),axis=1 表示对每行数据进行操作(列维度折叠) |
记忆方法:
- 结合
shape属性,axis 的编号就是维度的索引。 - 对于 2 维数据,“axis=0 是 down(垂直方向,列操作),axis=1 是 across(水平方向,行操作)”。
在实际开发中,对不熟悉的操作,可以先进行小范围测试,观察操作结果的形状和内容,确认 axis 参数的正确性。
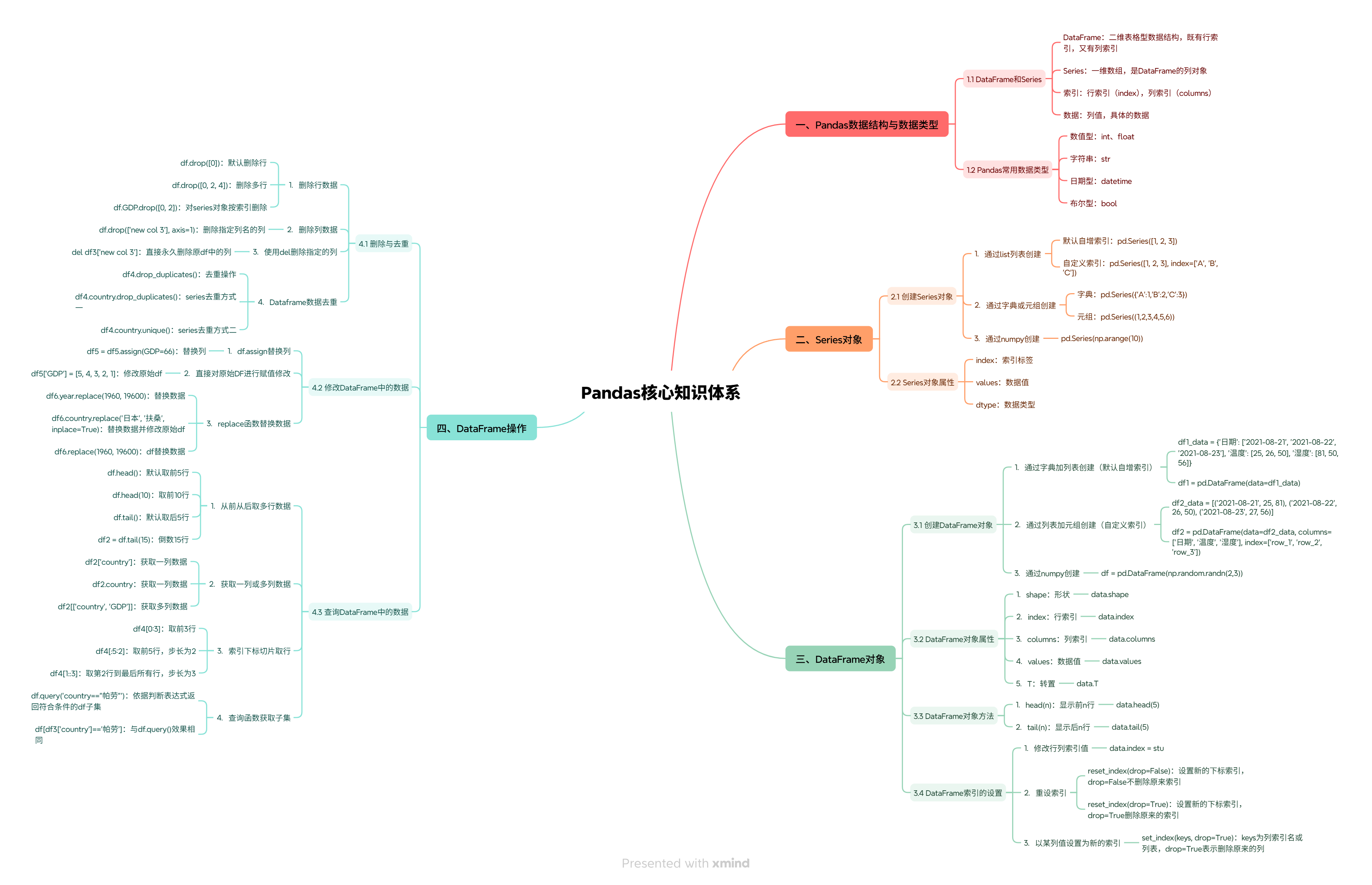
相关 思维导图 下载:
【免费】思维导图:Numpy知识整理.xmind资源-优快云下载
【免费】思维导图:Pandas核心知识体系.xmind资源-优快云下载
【免费】思维导图:Matplotlib数据可视化全攻略.xmind资源-优快云下载


















 4884
4884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









