









【个人主页:玄同765】
大语言模型(LLM)开发工程师|中国传媒大学·数字媒体技术(智能交互与游戏设计)
深耕领域:大语言模型开发 / RAG知识库 / AI Agent落地 / 模型微调
技术栈:Python / LangChain/RAG(Dify+Redis+Milvus)| SQL/NumPy | FastAPI+Docker ️
工程能力:专注模型工程化部署、知识库构建与优化,擅长全流程解决方案
专栏传送门:LLM大模型开发 项目实战指南、Python 从真零基础到纯文本 LLM 全栈实战、从零学 SQL + 大模型应用落地、大模型开发小白专属:从 0 入门 Linux&Shell
「让AI交互更智能,让技术落地更高效」
欢迎技术探讨/项目合作! 关注我,解锁大模型与智能交互的无限可能
相关 思维导图 下载:
【免费】思维导图:Numpy知识整理.xmind资源-优快云下载
【免费】思维导图:Pandas核心知识体系.xmind资源-优快云下载
【免费】思维导图:Matplotlib数据可视化全攻略.xmind资源-优快云下载
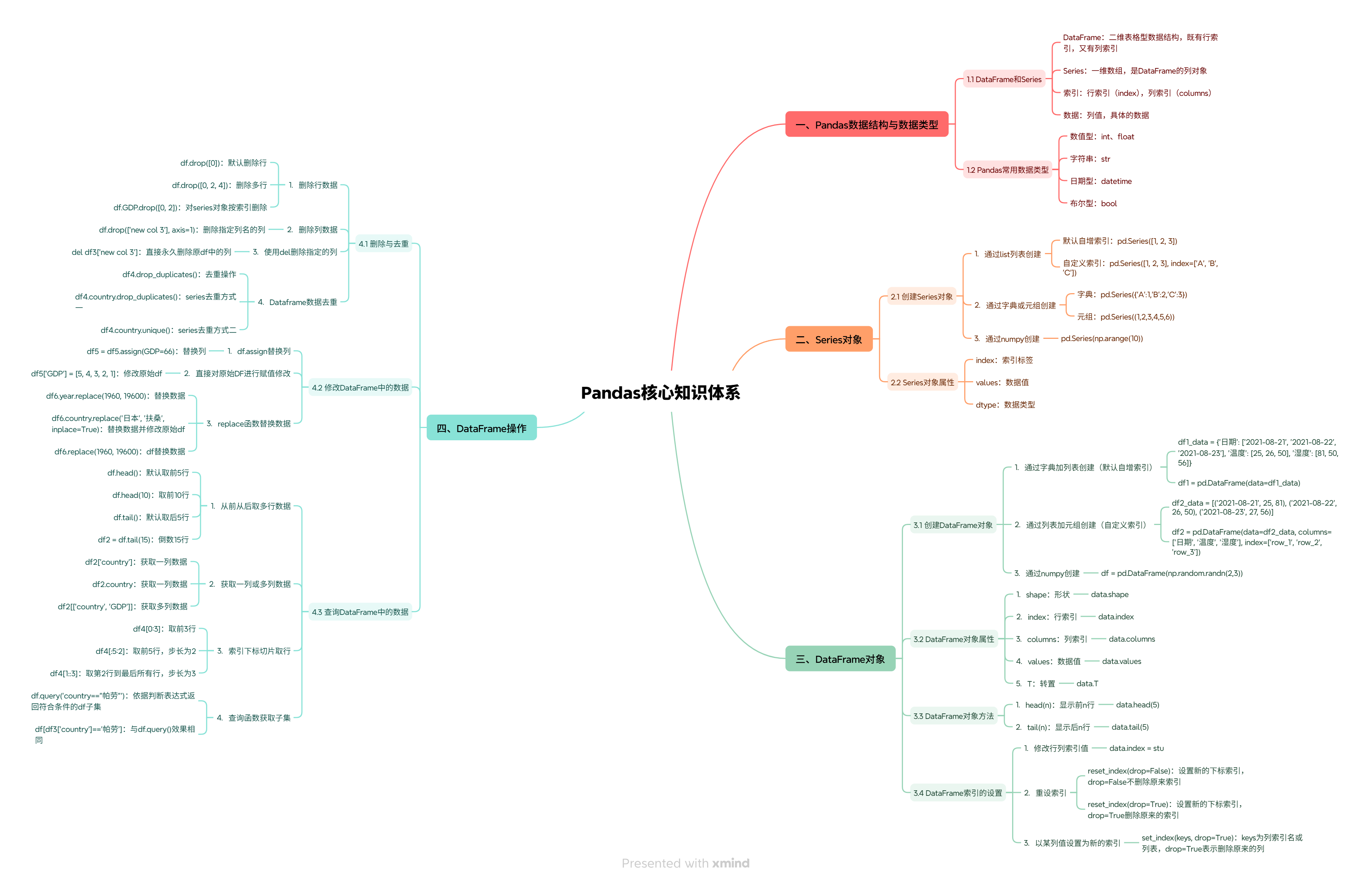 Pandas作为Python生态系统中不可或缺的数据处理工具,为数据分析提供了强大而灵活的解决方案。从初学者的视角来看,Pandas的核心价值在于其能够将复杂的数据操作简化为直观的API调用,让开发者能够专注于分析逻辑而非底层实现。本文将从Pandas的基础概念入手,逐步深入到实际的数据处理和分析场景,并最终探讨Pandas在大型语言模型(LLM)开发中的具体应用,帮助读者构建从入门到实战的完整知识体系。
Pandas作为Python生态系统中不可或缺的数据处理工具,为数据分析提供了强大而灵活的解决方案。从初学者的视角来看,Pandas的核心价值在于其能够将复杂的数据操作简化为直观的API调用,让开发者能够专注于分析逻辑而非底层实现。本文将从Pandas的基础概念入手,逐步深入到实际的数据处理和分析场景,并最终探讨Pandas在大型语言模型(LLM)开发中的具体应用,帮助读者构建从入门到实战的完整知识体系。
一、Pandas基础:安装配置与核心数据结构
Pandas的安装相对简单,主要依赖于Python环境。对于大多数开发者而言,使用pip安装是最直接的方式:
pip install pandas numpy matplotlib
安装完成后,通过导入语句即可在代码中使用Pandas:
import pandas as pd
import numpy as np
Pandas的两个核心数据结构是Series和DataFrame,它们分别对应一维和二维的带标签数据结构 。Series类似于带标签的列表,而DataFrame则类似于表格或Excel电子表,由多个Series组成且共享同一索引。
创建Series的基本方式有两种:从列表或字典创建:
# 从列表创建Series
s1 = pd.Series([10, 20, 30, 40, 50], name='成绩')
print(s1)
# 从字典创建Series
s2 = pd.Series({'张三': 85, '李四': 90, '王五': 78}, name='学生成绩')
print(s2)
输出结果为:
0 10
1 20
2 30
3 40
4 50
Name: 成绩, dtype: int64
张三 85
李四 90
王五 78
dtype: int64
DataFrame的创建方式更加灵活,可以通过多种方式构建:
# 从字典创建DataFrame
data = {
'姓名': ['张三', '李四', '王五'],
'年龄': [25, 30, 28],
'城市': ['北京', '上海', '广州'],
'薪资': [15000, 23000, 18000]
}
df = pd.DataFrame(data)
print(df)
# 从列表创建DataFrame
rows = [
['张三', 25, '北京', 15000],
['李四', 30, '上海', 23000],
['王五', 28, '广州', 18000]
]
df = pd.DataFrame(rows, columns=['姓名', '年龄', '城市', '薪资'])
print(df)
输出结果为:
姓名 年龄 城市 薪资
0 张三 25 北京 15000
1 李四 30 上海 23000
2 王五 28 广州 18000
这两个数据结构构成了Pandas的基础,理解它们的特性和操作方式是掌握Pandas的关键一步。Series适用于单列数据,而DataFrame则更适合处理多列结构化的数据。
二、数据导入导出:连接现实世界的数据源
在数据分析中,数据的获取和保存是首要任务。Pandas提供了丰富的函数来支持各种数据格式的导入导出,包括CSV、Excel、JSON、SQL数据库等 。
CSV文件处理是最常见的数据交换格式。读取CSV文件只需一行代码:
df = pd.read_csv('data.csv')
同样,将DataFrame保存为CSV文件也很简单:
df.to_csv('cleaned_data.csv', index=False)
对于Excel文件,Pandas同样提供了便捷的读写接口:
# 读取Excel文件
df = pd.read_excel('data.xlsx', sheet_name='Sheet1')
# 写入Excel文件
with pd.ExcelWriter('output.xlsx') as writer:
df.to_excel(writer, sheet_name='Data')
summary.to_excel(writer, sheet_name='Summary')
处理多工作表的Excel文件时,可以使用以下方式:
# 加载所有工作表
dfs = pd.read_excel('multi sheets.xlsx', sheet_name=None)
# 或者指定特定工作表
dfs = pd.read_excel('multi sheets.xlsx', sheet_name=['Sheet1', 'Sheet2'])
对于数据库交互,Pandas提供了与SQL数据库的无缝连接:
from sqlalchemy import create_engine
# 创建数据库连接
engine = create_engine('sqlite:///mydatabase.db')
# 从数据库读取数据
df = pd.read_sql('SELECT * FROM employees WHERE department="技术部"', engine)
# 将数据写回数据库
df.to_sql('cleaned_employees', engine, if_exists='replace', index=False)
在LLM开发中,这种数据库交互能力特别有用,例如从用户行为日志表中提取训练数据,或从评估结果表中加载测试数据。通过SQL查询可以灵活地筛选出符合模型训练需求的数据子集。
三、数据清洗:处理现实世界中的"脏数据"
现实世界中的数据往往不完整、不一致或包含错误,数据清洗是确保分析结果可靠性的关键步骤。Pandas提供了多种方法来处理这些问题 。
缺失值处理是数据清洗中最常见的任务之一。Pandas提供了多种函数来检测和处理缺失值:
# 检测缺失值
print("缺失值统计:")
print(df.isnull().sum())
# 删除包含缺失值的行
df_cleaned = df.dropna()
# 用均值填充缺失值
df['薪资'].fillna(df['薪资'].mean(), inplace=True)
重复数据处理同样重要:
# 检测重复数据
print("重复行数量:", df.duplicated().sum())
# 删除重复行
df = df.drop_duplicates()
# 根据特定列删除重复
df = df.drop_duplicates(subset=['姓名', '城市'])
异常值检测可以通过统计方法实现:
# 计算四分位数
Q1 = df['薪资'].quantile(0.25)
Q3 = df['薪资'].quantile(0.75)
IQR = Q3 - Q1
# 检测异常值
outliers = df[(df['薪资'] < (Q1 - 1.5 * IQR)) | (df['薪资'] > (Q3 + 1.5 * IQR))]
print("异常值记录:")
print(outliers)
# 替换异常值
df['薪资'] = df['薪资'].where(
(df['薪资'] >= (Q1 - 1.5 * IQR)) & (df['薪资'] <= (Q3 + 1.5 * IQR)),
df['薪资'].median()
)
数据类型转换对于后续分析至关重要:
# 转换数据类型
df['年龄'] = df['年龄'].astype('int32')
df['薪资'] = df['薪资'].astype('float64')
# 将日期字符串转为datetime类型
df['入职日期'] = pd.to_datetime(df['入职日期'])
在LLM开发中,数据清洗尤为重要,因为模型的性能直接受训练数据质量的影响。例如,清洗用户查询日志中的无效或重复记录,或处理多语言数据集中的编码问题,都需要依赖Pandas的清洗能力。
四、数据转换与重塑:让数据适应分析需求
数据转换是将数据从一种格式转换为另一种格式的过程,目的是使数据更适合特定的分析任务。Pandas提供了多种数据转换工具,包括合并、分组、透视等操作。
数据合并是将多个DataFrame连接成一个的过程:
# 内连接
merged_df = pd.merge(df1, df2, on='key', how='inner')
# 左连接
merged_df = pd.merge(df1, df2, left_on='left_key', right_on='right_key', how='left')
# 拼接
combined_df = pd.concat([df1, df2], axis=0) # 垂直拼接
combined_df = pd.concat([df1, df2], axis=1) # 水平拼接
分组聚合是数据分析的核心操作之一:
# 按城市分组,计算平均薪资
grouped = df.groupby('城市')
mean salaries = grouped['薪资'].mean()
print(mean salaries)
# 按多个字段分组,并应用多种聚合函数
aggregated = df.groupby(['城市', '部门']).agg({
'薪资': ['mean', 'median', 'std'],
'年龄': 'max'
})
print/aggregated)
透视表提供了一种直观的数据重塑方式:
# 创建透视表,统计不同城市和部门的员工数量
pivot_table = df.pivot_table(
index='城市',
columns='部门',
values='薪资',
aggfunc='count',
margins=True, # 添加总计行
margins_name='总计'
)
print/pivot_table)
输出结果为:
部门 技术部 市场部 财务部 总计
城市
北京 3 0 0 3
上海 0 2 1 3
总计 3 2 1 6
数据分箱将连续数据转换为离散区间:
# 创建分箱区间
bins = [0, 25, 30, 35, 40]
labels = ['25岁以下', '25-30岁', '30-35岁', '35岁以上']
# 应用分箱
df['年龄分段'] = pd.cut(df['年龄'], bins=bins, labels=labels, include_lowest=True)
print(df['年龄分段'].value_counts())
输出结果为:
25-30岁 5
30-35岁 3
35岁以上 2
25岁以下 0
Name: 年龄分段, dtype: int64
在LLM开发中,数据转换常用于构建适合模型输入的格式。例如,将用户查询日志中的时间戳转换为统一的时区格式,或将文本数据按长度分箱以适配不同模型的上下文窗口限制。
五、数据探索与可视化:发现数据中的模式
数据探索是了解数据特征、发现潜在模式的过程。Pandas提供了多种方法来快速探索数据:
# 查看数据概览
print(df.head()) # 显示前5行
print(df.tail()) # 显示后5行
print(df.info()) # 显示数据类型和缺失值信息
# 查看统计摘要
print(df.describe()) # 数值列的统计信息
print(df['部门'].value_counts()) # 分类列的频次统计
输出结果为:
姓名 年龄 城市 薪资
0 张三 25 北京 15000
1 李四 30 上海 23000
2 王五 28 广州 18000
3 赵六 35 深圳 25000
4 陈七 27 北京 16000
姓名 年龄 城市 薪资
95 周八 42 上海 32000
96 吴九 38 广州 29000
97 郑十 40 深圳 31000
98 王五 28 广州 18000
99 李四 30 上海 23000
# describe()输出示例
年龄 薪资
count 100.000000 100.000000
mean 32.500000 23500.000000
std 5.809475 6800.000000
min 22.000000 12000.000000
25% 28.000000 18000.000000
50% 32.000000 23000.000000
75% 37.000000 29000.000000
max 45.000000 35000.000000
结合Matplotlib或Seaborn库,可以将数据可视化,更直观地发现模式:
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制薪资分布直方图
plt.figure(figsize=(10, 6))
sns.histplot(df['薪资'], bins=20, kde=True)
plt.title('薪资分布')
plt.xlabel('薪资')
plt.ylabel('频次')
plt.show()
# 绘制城市与薪资的箱线图
plt.figure(figsize=(10, 6))
sns.boxplot(x='城市', y='薪资', data=df)
plt.title('各城市薪资分布')
plt.xlabel('城市')
plt.ylabel('薪资')
plt.show()
# 绘制部门薪资的热力图
plt.figure(figsize=(10, 6))
sns.heatmap(pivot_table, cmap='Blues')
plt.title('部门薪资分布热力图')
plt.xlabel('部门')
plt.ylabel('城市')
plt.show()
这些图表能够直观展示数据分布和关系,是数据分析的重要工具。在LLM开发中,数据探索有助于理解用户查询的分布、评估模型输出的质量,以及发现训练数据中的潜在问题。
六、实战案例:Pandas在LLM开发中的应用
案例一:清洗LLM训练数据
在LLM训练中,数据清洗是确保模型性能的关键步骤。以下是一个清洗对话数据的示例:
# 读取原始对话数据
conversations = pd.read_csv('raw_conversations.csv')
# 清洗步骤
1. 去除空白行
conversations = conversations.dropna()
2. 标准化指令格式
conversations['指令'] = conversations['指令'].str.strip().str.lower()
3. 过滤无效对话
valid_conversations = conversations[
conversations['指令'].str.startswith('问题:') |
conversations['指令'].str.startswith('任务:')
]
4. 处理重复对话
unique_conversations = valid_conversations.drop_duplicates(
subset=['指令', '回答'], keep='first'
)
5. 分割训练验证集
from sklearn.model_selection import train_test_split
train_data, val_data = train_test_split(
unique_conversations, test_size=0.1, random_state=42
)
# 保存清洗后的数据
train_data.to_csv('train_data.csv', index=False)
val_data.to_csv('val_data.csv', index=False)
案例二:分析用户查询日志
用户查询日志是LLM服务的重要数据源,通过分析这些日志可以了解用户行为和需求:
# 读取日志文件
logs = pd.read_csv('query_logs.csv')
# 数据预处理
1. 转换时间戳为datetime类型
logs['时间'] = pd.to_datetime(logs['时间'])
2. 提取时间特征
logs['小时'] = logs['时间'].dt.hour
logs['日期'] = logs['时间'].dt.date
3. 清洗查询文本
logs['查询'] = logs['查询'].str.strip()
logs['查询'] = logs['查询'].str.replace(r'[^\w\s]', '', regex=True) # 去除特殊字符
# 分析用户行为
1. 统计高频查询
top_queries = logs['查询'].value_counts().head(20)
print("TOP 20 高频查询:")
print(top_queries)
2. 分析查询时间分布
hourly_usage = logs.groupby('小时').size()
print("每小时查询量:")
print(hourly_usage)
3. 统计响应时间分布
logs['响应时间'] = logs['响应时间'].astype('float64')
response_time_stats = logs['响应时间'].describe()
print("响应时间统计:")
print(response_time_stats)
输出结果示例:
TOP 20 高频查询:
如何学习编程 456
推荐书籍 321
解释机器学习 287
...
每小时查询量:
小时
0 15
1 23
2 31
...
响应时间统计:
count 10000.000000
mean 2.356789
std 0.897654
min 0.123456
25% 1.567890
50% 2.345678
75% 3.123456
max 5.678901
Name: 响应时间, dtype: float64
案例三:评估LLM模型性能
在LLM模型评估中,Pandas可以用于处理和分析评估数据:
# 读取评估数据
eval_data = pd.read_csv('eval_results.csv')
# 计算ROUGE分数
from rouge_score import rouge_scorer
scorer = RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True)
# 添加ROUGE分数列
eval_data['ROUGE1'] = eval_data.apply(
lambda row: scorer.score(row['参考回答'], row['模型回答'])['rouge1']['f'],
axis=1
)
eval_data['ROUGE2'] = eval_data.apply(
lambda row: scorer.score(row['参考回答'], row['模型回答'])['rouge2']['f'],
axis=1
)
eval_data['ROUGE-L'] = eval_data.apply(
lambda row: scorer.score(row['参考回答'], row['模型回答'])['rougeL']['f'],
axis=1
)
# 统计模型性能
model perform = eval_data.groupby('模型').agg({
'ROUGE1': ['mean', 'std'],
'ROUGE2': ['mean', 'std'],
'ROUGE-L': ['mean', 'std']
})
print("模型性能统计:")
print(model perform)
# 保存评估结果
eval_data.to_csv('eval_data_with_rouge.csv', index=False)
七、高级技巧:提升Pandas数据处理效率
对于大型数据集,处理效率是一个关键问题。Pandas提供了多种方法来提升处理效率。
向量化操作是Pandas的核心性能优化手段:
# 避免使用循环,使用向量化操作
# 低效方式
for index, row in df.iterrows():
if row['薪资'] > 20000:
df.loc[index, '薪资等级'] = '高薪'
else:
df.loc[index, '薪资等级'] = '普通'
# 高效方式
df['薪资等级'] = np.where(df['薪资'] > 20000, '高薪', '普通')
条件表达式可以简洁地筛选数据:
# 筛选高薪且年龄在30岁以下的员工
high_salary年轻 = df[(df['薪资'] > 25000) & (df['年龄'] < 30)]
# 统计不同薪资等级的员工数量
salary_counts = df['薪资等级'].value_counts()
print(salary_counts)
分块处理适用于超大型数据集:
# 分块读取大型CSV文件
chunk_size = 10000
chunks = pd.read_csv('large_data.csv', chunksize=chunk_size)
# 处理每个分块
for chunk in chunks:
# 对分块进行清洗和转换
chunk = chunk.dropna()
chunk['年龄分段'] = pd.cut(chunk['年龄'], bins=[0,25,30,35,40], labels=['25岁以下','25-30岁','30-35岁','35岁以上'])
# 将处理后的分块保存
chunk.to_csv('processed_chunk.csv', mode='a', header=False, index=False)
并行处理可以进一步提升性能:
# 使用Dask进行并行处理
import dask.dataframe as dd
# 创建Dask DataFrame
dask_df = dd.read_csv('large_data.csv')
# 应用转换函数
def transform_data(df):
df['薪资等级'] = np.where(df['薪资'] > 25000, '高薪', '普通')
return df
# 并行处理
processed_dask_df = dask_df.map partitions(transform_data, meta=dask_df)
# 计算结果并保存
processed_dask_df.compute().to_csv('parallel_processed_data.csv', index=False)
这些高级技巧对于处理LLM训练中的大规模数据集尤为重要,可以显著提升数据预处理的效率。
八、Pandas与LLM开发的结合点
1. 数据预处理阶段
在LLM训练前的数据预处理阶段,Pandas可以用于:
- 清洗原始文本数据(去除特殊字符、标准化格式)
- 合并多源数据(如用户表与查询记录表的合并)
- 处理缺失值和异常值
- 分割训练、验证和测试数据集
- 统计文本长度分布,适配模型上下文窗口限制
例如,对于需要训练对话系统的LLM,可以使用Pandas清洗和结构化对话数据:
# 读取原始对话数据
conversations = pd.read_csv('raw_conversations.csv')
# 清洗对话数据
conversations['用户'] = conversations['用户'].str.strip()
conversations['回答'] = conversations['回答'].str.strip()
# 过滤无效对话
valid_conversations = conversations[
(conversations['用户'].notnull()) &
(conversations['回答'].notnull()) &
(conversations['用户'].str.len() > 0) &
(conversations['回答'].str.len() > 0)
]
# 统计对话长度
conversations['用户长度'] = valid_conversations['用户'].str.len()
conversations['回答长度'] = valid_conversations['回答'].str.len()
# 分析长度分布
length_stats = conversations[['用户长度', '回答长度']].describe()
print(length_stats)
2. 特征工程阶段
在特征工程阶段,Pandas可以用于:
- 文本长度统计
- 高频词提取
- 用户行为特征计算
- 多语言数据对齐
- 数据分箱(如按文本长度分段)
例如,提取查询日志中的高频关键词作为特征:
# 分词统计
from sklearn.feature_extraction.text import CountVectorizer
# 提取文本特征
vectorizer = CountVectorizer(max_features=100)
X = vectorizer.fit_transform(logs['查询'])
# 转换为DataFrame
text_features = pd.DataFrame(X.toarray(), columns=vectorizer.get_feature_names_out())
# 合并到原始日志数据
logs = pd.concat([logs, text_features], axis=1)
# 计算用户活跃度
user Activity = logs.groupby('用户ID').size().rename('查询次数').reset_index()
# 合并到用户表
user_data = pd.merge(user_data, user_activity, on='用户ID', how='left')
3. 模型评估阶段
在模型评估阶段,Pandas可以用于:
- 处理评估数据
- 计算评估指标
- 生成评估报告
- 对比不同模型版本性能
- 分析模型在不同数据子集上的表现
例如,分析模型在不同查询类型上的表现:
# 读取评估结果
eval_results = pd.read_csv('model_eval.csv')
# 分析准确率
accuracy_by_type = eval_results.groupby('查询类型')['准确率'].mean().sort_values(ascending=False)
# 可视化结果
plt.figure(figsize=(12, 6))
accuracy_by_type.plot(kind='bar')
plt.title('不同查询类型准确率对比')
plt.xlabel('查询类型')
plt.ylabel('准确率')
plt.xticks(rotation=45)
plt.show()
九、总结与展望
Pandas作为Python数据分析的核心库,为开发者提供了一套强大而灵活的数据处理工具。从基础的数据结构到高级的数据转换和分析,Pandas能够满足从入门到实战的各种需求。
在LLM开发中,Pandas的价值尤为突出。它不仅能够处理大规模的文本数据,还能够整合多源数据、构建评估指标、分析模型性能,为LLM的训练和优化提供坚实的数据基础。
随着LLM技术的不断发展,数据处理的需求也在不断变化。未来的Pandas应用可能包括:
- 更高效的文本处理方法
- 更强大的多模态数据处理能力
- 更智能的数据清洗和预处理工具
- 更深入的与LLM模型的集成
- 更自动化的数据探索和特征工程
掌握Pandas并将其应用于LLM开发,将使开发者能够更高效地处理数据,更准确地评估模型,最终构建出性能更优的大型语言模型。
通过本文的学习,读者应该能够从Pandas的基础知识出发,逐步掌握其在数据分析中的应用,并将这些技能应用于LLM开发的各个阶段,实现从数据到模型的完整闭环。


















 2736
2736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









