









引言
机器学习的世界里,决策树(Decision Tree)是一个非常重要且基础的算法。无论你是初学者还是老手,掌握决策树的基本概念与构建方法都是非常有帮助的。决策树不仅直观易懂,还因其较强的可解释性在许多应用场景中表现优异。
今天,我们将一起轻松搞懂决策树。内容不仅会覆盖决策树的基本理论,还会带你一步步搭建一个实际的决策树模型,并附带实战数据与详细代码示例。相信你看完后,能轻松上手。
1. 决策树的构建过程
1.1 什么是决策树?
决策树是一种分类与回归的模型,它通过一系列的决策规则(如“如果A > B,那么选择C”)将数据集划分为多个子集,直到满足某个停止条件为止。树的每个节点代表一个特征(或者属性),每个边代表特征值的划分,而叶子节点则表示最终的分类标签或回归值。
1.2 决策树的构建过程
构建决策树的核心目标是通过选择最优的特征进行划分,使得每个划分后的子集尽可能纯净(即同一类别的数据尽量集中)。决策树的构建通常遵循以下步骤:
1.选择特征:根据一定的准则选择最适合划分数据的特征。
2.划分数据集:根据选择的特征将数据划分成子集。
3.递归构建树:对每个子集继续递归地构建子树,直到满足停止条件(如树的深度达到预设值,或者所有数据点的标签一致)。
1.3 划分准则
决策树选择特征时需要判断哪个特征能最好地分割数据。常见的划分准则有:
- 信息增益(ID3算法):选择可以最大化信息增益的特征。
- 基尼指数(CART算法):选择基尼指数最小的特征。
- 信息增益比(C4.5算法):对信息增益进行归一化处理,选择增益比最高的特征。
1.3.1 信息增益
信息增益基于信息论中的熵(Entropy)概念,熵越小表示数据的纯度越高。信息增益就是划分数据前后的熵差,信息增益越大,划分效果越好。具体计算公式如下:
- 熵公式:
E
n
t
r
o
p
y
(
S
)
=
−
∑
i
=
1
n
P
i
log
2
P
i
Entropy(S) = - \sum{i=1}^{n} Pi \log2 Pi
Entropy(S)=−∑i=1nPilog2Pi
其中,
(
P
i
)
是类别
(
i
)
(P_i) 是类别 (i)
(Pi)是类别(i) 的概率。
- 信息增益:
I
n
f
o
r
m
a
t
i
o
n
G
a
i
n
(
D
,
A
)
=
E
n
t
r
o
p
y
(
D
)
−
∑
v
∈
V
a
l
u
e
s
(
A
)
∣
D
v
∣
∣
D
∣
E
n
t
r
o
p
y
(
D
v
)
Information_Gain(D, A) = Entropy(D) - \sum{v \in Values(A)} \frac{|Dv|}{|D|} Entropy(Dv)
InformationGain(D,A)=Entropy(D)−∑v∈Values(A)∣D∣∣Dv∣Entropy(Dv)
其中,
(
D
v
)
(Dv)
(Dv) 表示划分后的子集。
1.3.2 基尼指数
基尼指数是一种衡量数据不纯度的指标,越小表示纯度越高。计算公式为:
G
i
n
i
(
S
)
=
1
−
∑
i
=
1
n
P
i
2
Gini(S) = 1 - \sum{i=1}^{n} Pi^2
Gini(S)=1−∑i=1nPi2
在决策树的构建过程中,我们选择基尼指数最小的特征进行划分。
1.3.3 信息增益比
为了解决信息增益的偏向问题,C4.5算法提出了信息增益比的概念。信息增益比是在信息增益的基础上加入了一个正则化项,通常是对特征的“分裂值”进行调整。信息增益比的计算公式为:
Gain Ratio
(
D
,
A
)
=
Gain
(
D
,
A
)
Split Information
(
D
,
A
)
\text{Gain Ratio}(D, A) = \frac{\text{Gain}(D, A)}{\text{Split Information}(D, A)}
Gain Ratio(D,A)=Split Information(D,A)Gain(D,A)
其中,
S
p
l
i
t
I
n
f
o
r
m
a
t
i
o
n
Split Information
SplitInformation(分裂信息)是特征A对于数据集D的划分的信息熵,公式如下:
Split Information
(
D
,
A
)
=
−
∑
v
∈
Values
(
A
)
∣
D
v
∣
∣
D
∣
⋅
log
2
(
∣
D
v
∣
∣
D
∣
)
\text{Split Information}(D, A) = - \sum{v \in \text{Values}(A)} \frac{|Dv|}{|D|} \cdot \log2 \left( \frac{|Dv|}{|D|} \right)
Split Information(D,A)=−∑v∈Values(A)∣D∣∣Dv∣⋅log2(∣D∣∣Dv∣)
信息增益比是C4.5算法用来选择特征的标准,它是信息增益的改进版,旨在减少偏向取值多的特征。通过引入分裂信息作为正则项,C4.5能够更合理地选择划分数据的特征,从而构建出更加精确和有效的决策树模型。
1.4 如何选择划分特征?
通过计算每个特征的信息增益或者基尼指数,我们可以选择最佳特征。然后,使用该特征对数据集进行划分。以下是伪代码:
1.计算每个特征的信息增益(或基尼指数)。
2.选择信息增益(或基尼指数)最大的特征。
3.使用选定的特征将数据集划分为不同的子集。
4.对每个子集递归执行上述步骤,直到满足停止条件(如节点纯度达到100%)。
2. 剪枝方法:防止过拟合
决策树的缺点之一是容易过拟合,尤其是在数据复杂时。过拟合意味着模型在训练数据上表现很好,但在新数据上泛化能力差。为了防止过拟合,我们引入了剪枝(Pruning)方法。
2.1 预剪枝(Pre-pruning)
预剪枝是在树的构建过程中通过设置一些限制条件(如最大树深度、最小样本数等)提前停止树的生长。常见的预剪枝策略包括:
- 限制树的最大深度(避免过深)。
- 限制每个叶子节点的最小样本数(避免过小的叶子节点)。
- 当某一特征的划分信息增益(或基尼指数)小于设定阈值时,停止划分。
2.2 后剪枝(Post-pruning)
后剪枝是在树完全构建后,再进行修剪。通过剪掉一些不必要的节点或子树来降低模型的复杂度。后剪枝常用的算法包括CART算法中的最小化错误率剪枝。
2.3 剪枝的作用
剪枝的核心目的是平衡模型复杂度与训练数据拟合度,防止决策树模型对训练数据的过拟合。通过剪枝,我们能够得到一个更为简洁、泛化能力更强的模型。
3. 决策树的可视化与解释性优势
决策树的最大优点之一是可解释性强。它通过树的结构能够清晰地展示如何根据特征做出分类决策,这对于分析模型决策过程非常有帮助。你可以通过可视化工具将决策树“画”出来,进一步理解其内部工作原理。
3.1 如何可视化决策树?
在Python中,我们可以使用sklearn库中的DecisionTreeClassifier进行决策树的训练和可视化。下面是一个简单的例子,演示如何使用Kaggle的Titanic数据集来构建一个决策树模型,并可视化它。
4. 实战:Iris数据集中的决策树
接下来我们将以 “Iris 数据集” 为例,来展示如何使用决策树算法进行分类任务的实战。Iris 数据集是一个经典的机器学习数据集,通常用于演示分类问题,它包含了不同种类的鸢尾花(Iris flower)的特征数据,目标是预测每个花朵的种类。
接下来,我们会对以下内容进行修改:
1.以 Iris 数据集 为例,替换 Titanic 数据集。
2.更新实战代码示例,展示如何使用决策树进行分类。
3.包括数据预处理、模型训练和评估等步骤。
4.1 引入必要的库
首先,我们需要导入 Python 中的相关库,包括数据处理、模型训练和评估所需的工具。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn import tree
4.2 加载和查看数据
Iris 数据集可以通过 sklearn.datasets 直接加载。我们先加载数据,并查看它的基本结构。
# 加载Iris数据集
iris = load_iris()
# 将数据转换为DataFrame格式
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# 添加目标标签
iris_df['species'] = iris.target
# 查看数据集的前几行
print(iris_df.head())
输出的前几行应该是类似以下内容:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) species
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
这里,species 列表示鸢尾花的种类(0、1、2分别代表三种鸢尾花),而其他列是各个花瓣和萼片的尺寸。
4.3 数据预处理和拆分
在训练模型之前,我们需要将数据拆分为训练集和测试集,常见的拆分比例为 80% 用于训练,20% 用于测试。
# 特征和标签
X = iris.data
y = iris.target
# 拆分数据集:80% 用于训练,20% 用于测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("训练集大小:", X_train.shape)
print("测试集大小:", X_test.shape)
4.4 训练决策树模型
接下来,我们将使用决策树模型来对数据进行训练。我们可以通过 DecisionTreeClassifier 来训练模型。
# 创建决策树分类器
clf = DecisionTreeClassifier(random_state=42)
# 使用训练集数据训练模型
clf.fit(X_train, y_train)
4.5 模型评估
训练完模型后,我们可以通过测试集对模型进行评估,检查其预测精度以及其他相关的评估指标。
# 使用测试集数据进行预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.4f}")
# 打印分类报告
print("\n分类报告:")
print(classification_report(y_test, y_pred))
# 打印混淆矩阵
print("\n混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
分类报告会显示每个类别的精确度、召回率和F1分数。混淆矩阵将展示预测结果与实际结果的对比,帮助我们分析模型的表现。
4.6 可视化决策树
为了进一步理解模型的决策过程,我们可以将训练好的决策树可视化。这可以帮助我们了解决策树的分裂方式及其分类标准。
# 可视化决策树
plt.figure(figsize=(15, 10))
tree.plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names, rounded=True)
plt.show()
这将输出一张决策树的图像,展示每一层的分裂特征和阈值,以及各个叶节点的类别预测。可视化后的决策树清晰地展示了模型根据哪些特征做出决策,哪个特征的划分最重要。
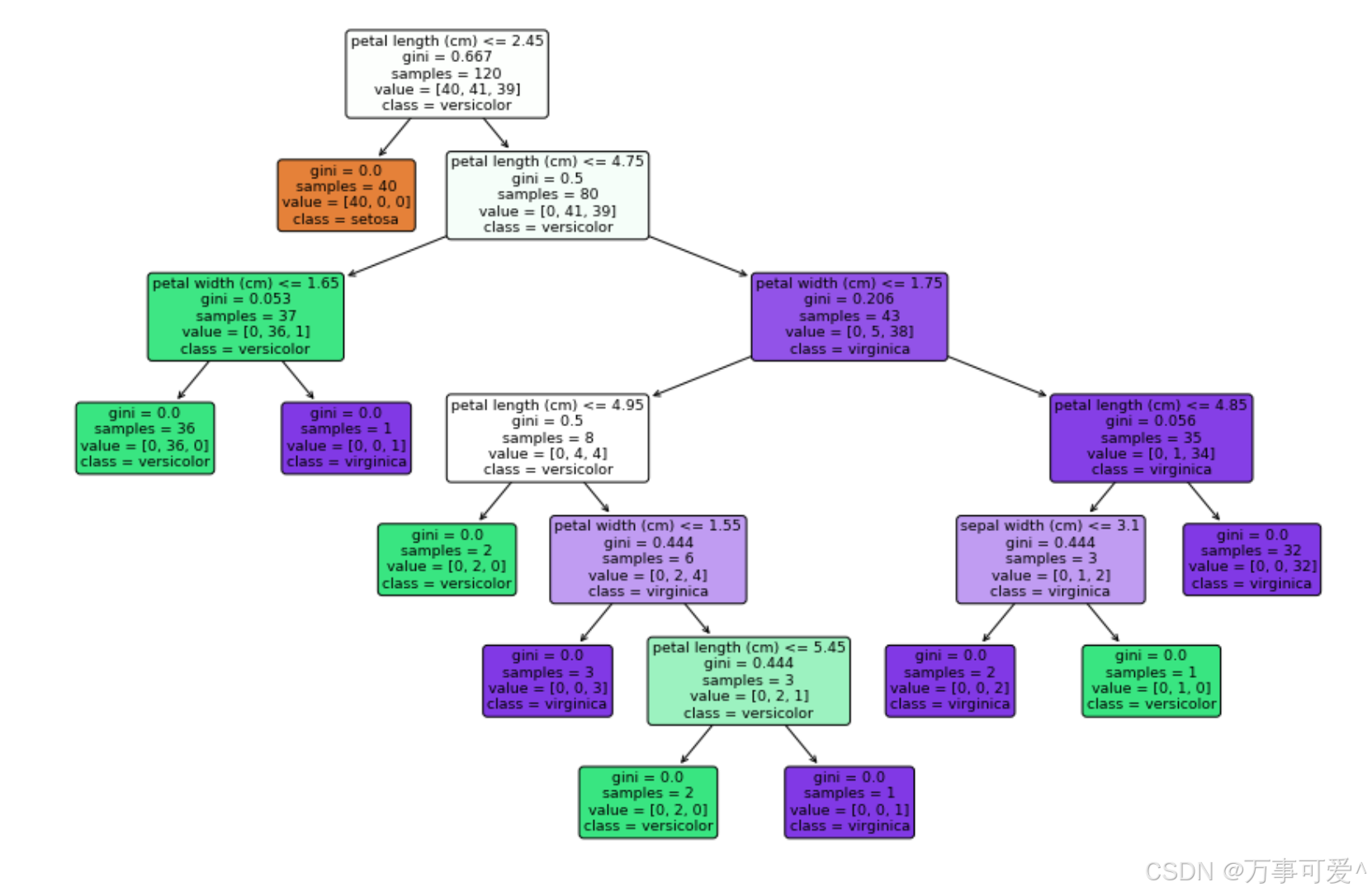
4.7 总结
通过上面的步骤,我们完成了一个简单的决策树分类任务:
- 我们使用 Iris 数据集 来训练和评估决策树模型。
- 我们查看了模型的准确率、分类报告以及混淆矩阵。
- 最后,我们通过可视化决策树的结构,帮助我们理解模型的决策过程。
此案例展示了如何在实际中应用决策树算法进行分类任务,尽管数据集较小,但仍能帮助我们快速理解决策树的基本操作与性能评估。
4.8 代码总结
最终,完整的代码流程如下所示:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn import tree
# 加载Iris数据集
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
iris_df['species'] = iris.target
# 查看数据集
print(iris_df.head())
# 特征和标签
X = iris.data
y = iris.target
# 拆分数据集:80% 用于训练,20% 用于测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("训练集大小:", X_train.shape)
print("测试集大小:", X_test.shape)
# 创建决策树分类器
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 模型评估
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.4f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred))
print("\n混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
# 可视化决策树
plt.figure(figsize=(15, 10))
tree.plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names, rounded=True)
plt.show()
通过这些步骤,您可以快速使用决策树算法来解决分类问题并评估模型的效果。希望这个案例对您理解决策树的应用有所帮助!

















 2417
2417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









