






还是一样,老规矩,我们先来看看知识库搭建完的效果。比如,我想了解“如何做抖音运营?”,
那么我可以先去度娘搜索“抖音运营”这个关键词,这个时候会搜出来很多跟抖音运营相关的知识文章。
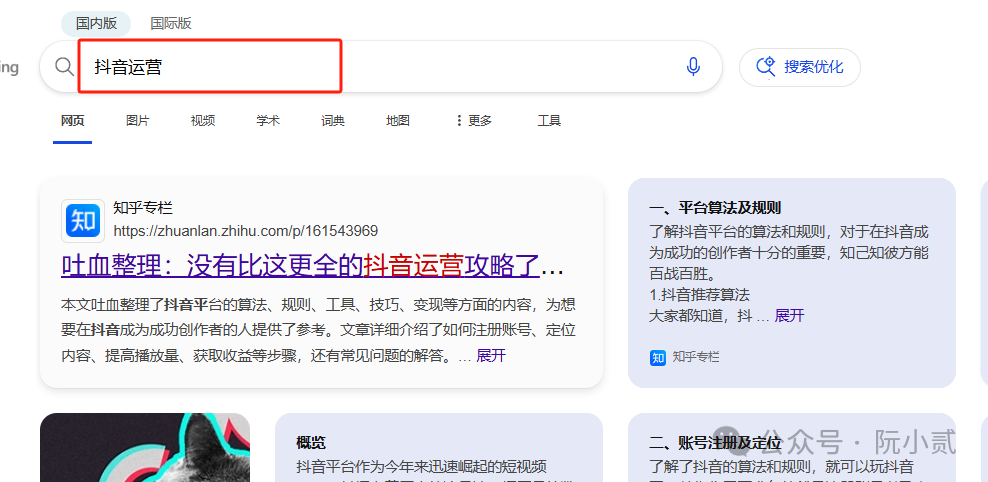
然后,我们找到一些我们认为不错的文章作为我们的知识库来源,
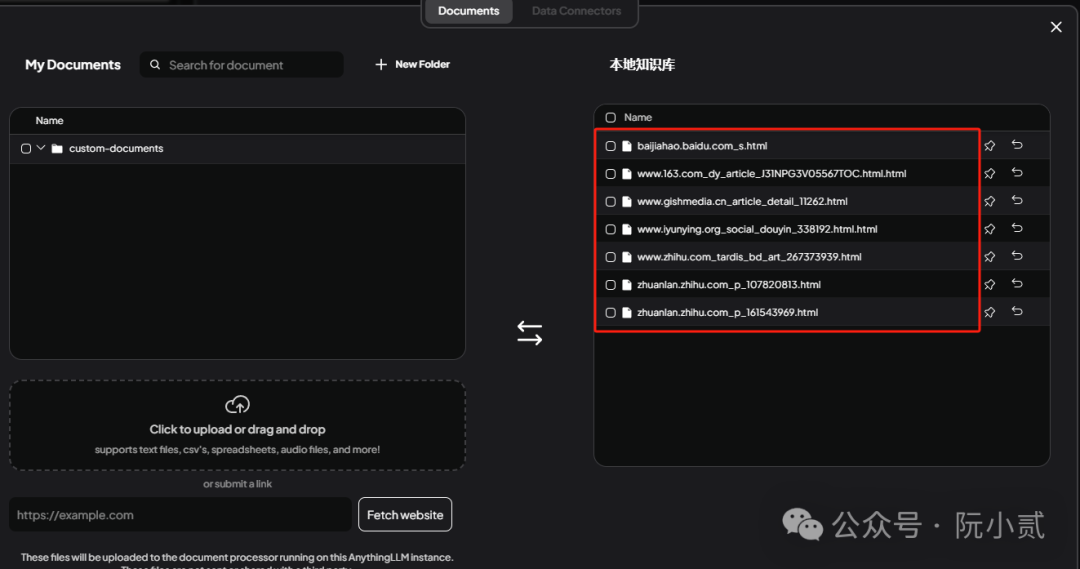
最后,验证知识库即可。
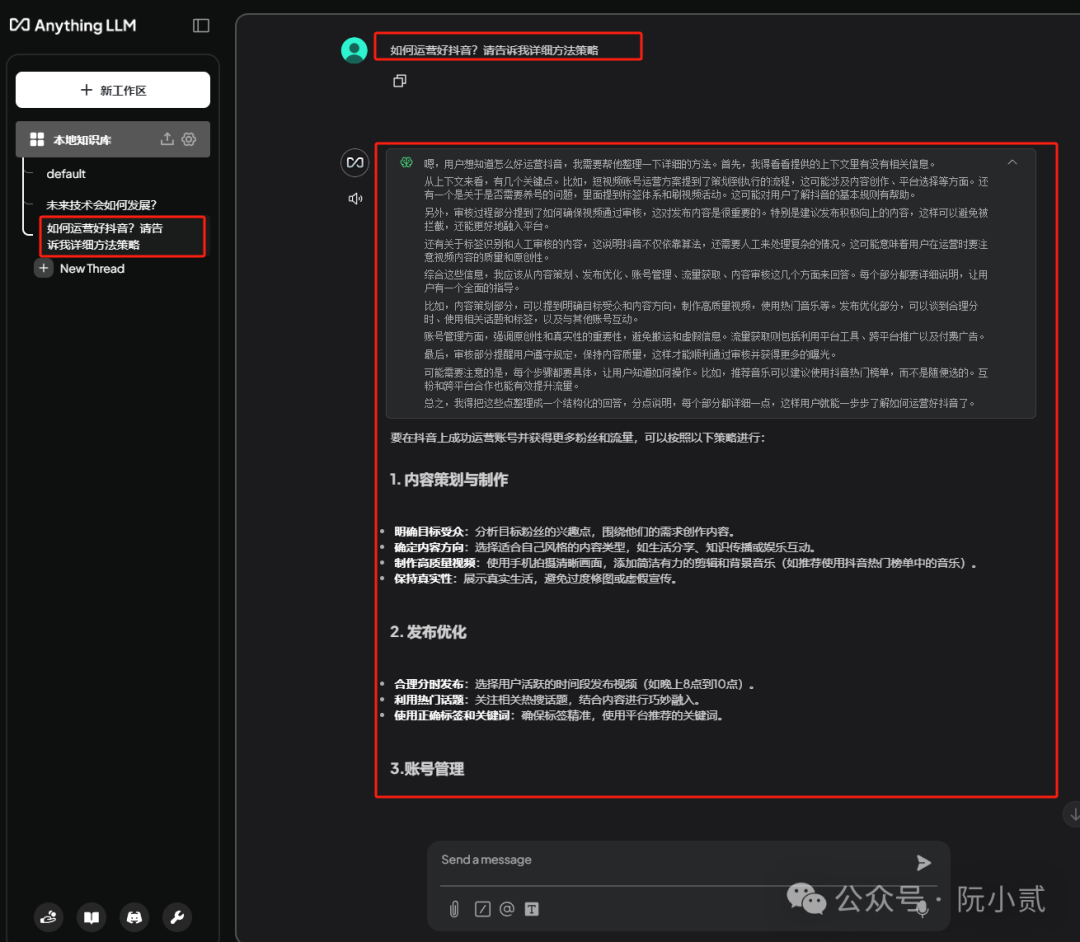
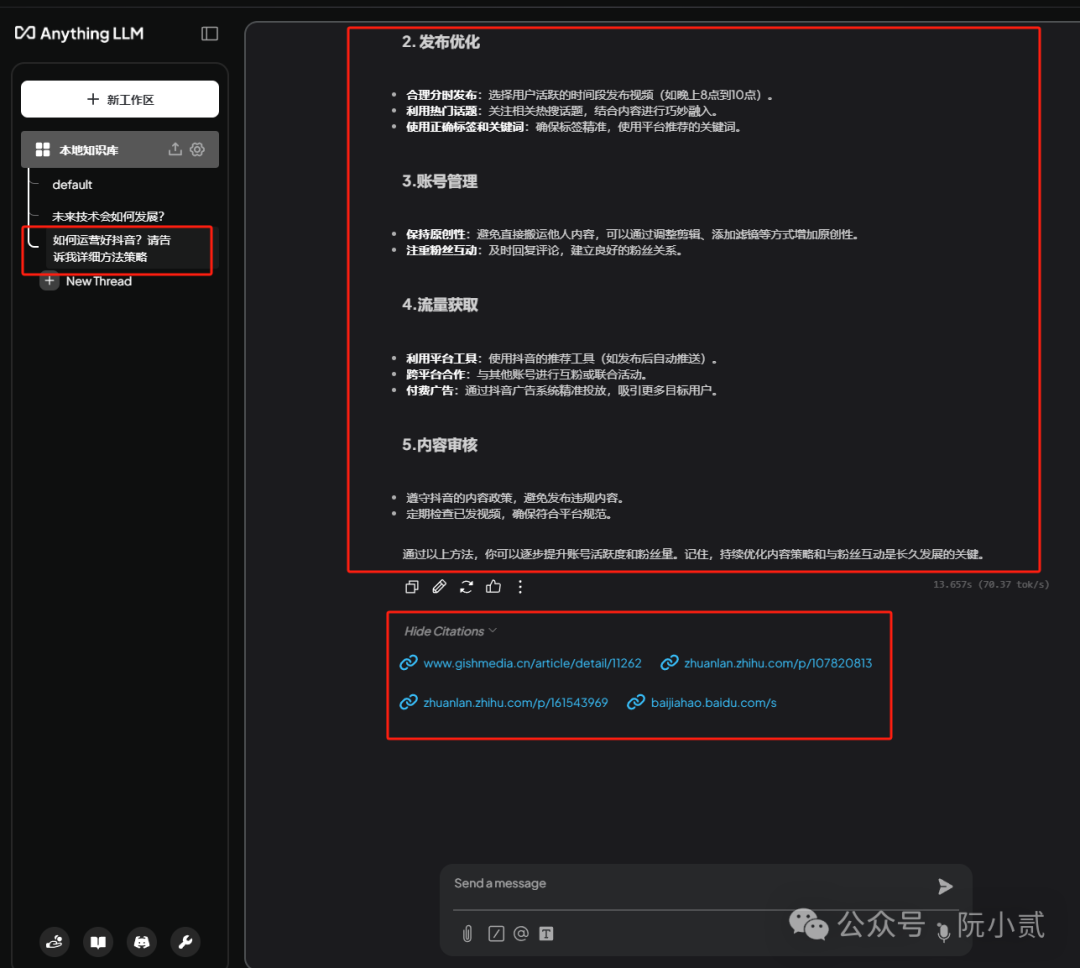
OK,这就是验证后的效果,看起来其实还不错。
一、为什么要搭建知识库?
日常工作中,我们经常需要处理大量文档和资料:
“
产品文档、技术文档散落在各处,查找费时费力
新人入职培训需要反复讲解相同的内容
客户咨询的问题高度重复,但每次都要人工回答
公司内部知识难以沉淀和复用
各类参考资料缺乏统一管理和快速检索的方案
一般传统的文档管理系统只能按目录存储和搜索关键词,而商业AI助手又无法导入私有数据。
那这个时候,一个能将文档智能化并支持对话的系统就显得尤为重要。
而知识库正是为解决这些痛点问题应运而生。
接下来,我以AnythingLLM为例,
重点教一下大家如何使用DeepSeek + AnythingLLM搭建本地私有知识库。
二、什么是AnythingLLM?

简单来说,AnythingLLM 能够把各种文档、资料或者内容转换成一种格式,让LLM(如ChatGPT)在聊天时可以引用这些内容。
然后你就可以用它来和各种文档、内容、资料聊天,支持多个用户同时使用,还可以设置谁能看或改哪些内容。
并且还支持多种LLM、嵌入器和向量数据库。
三、关于AnythingLLM
-
定位: 将本地文档或数据源整合进一个可检索、可对话的知识库,让 AI 助手“懂你”的资料。
-
主要功能:
1. 文档管理: 将 PDF、Markdown、Word 等多格式文件索引进系统。
2. 智能检索: 可基于向量数据库搜索相关文档片段,并在聊天时自动引用。
3. 界面+API: 既提供用户友好的前端管理界面,也能通过 API 与其他系统集成。
-
对接 Ollama 思路:
-
在配置文件或启动脚本中,将“语言模型推理”后端地址指定为 Ollama 的本地服务。
-
当用户发起提问时,AnythingLLM 会先做知识检索,再将检索到的上下文发送给 Ollama 做语言生成。
-
**适用场景: **
-
企业内部文档问答、个人知识管理、高度依赖文本内容的问答场景。
四、AnythingLLM灵活的文档处理能力
AnythingLLM支持处理多种类型的文档和内容:
“
多格式支持:可以导入PDF、Word、TXT等常见文档格式
网页抓取:直接输入URL即可抓取网页内容
智能分割:自动将长文档分割成适合向量化的片段
元数据提取:自动提取文档的标题、作者等信息
增量更新:支持文档的增量更新,无需重新处理全部内容
大规模处理:能高效处理GB级别的文档集合
五、个人AI知识库的搭建方案
使用 AnythingLLM + DeepSeek 是简单且知识检索效果不错的方案
“
AnythingLLM:开源免费的知识库管理前端工具,支持上传知识、向量化数据、检索增强(RAG)等服务。
DeepSeek:(简称DS)幻方量化推出的大模型,性能与Claude 3.5相当,Token价格较低,本次方案使用DS作为推理模型。
为了让大家更好地理解知识库的工作流程,我这边画了一张简易流程图。
大家随便看看就好。
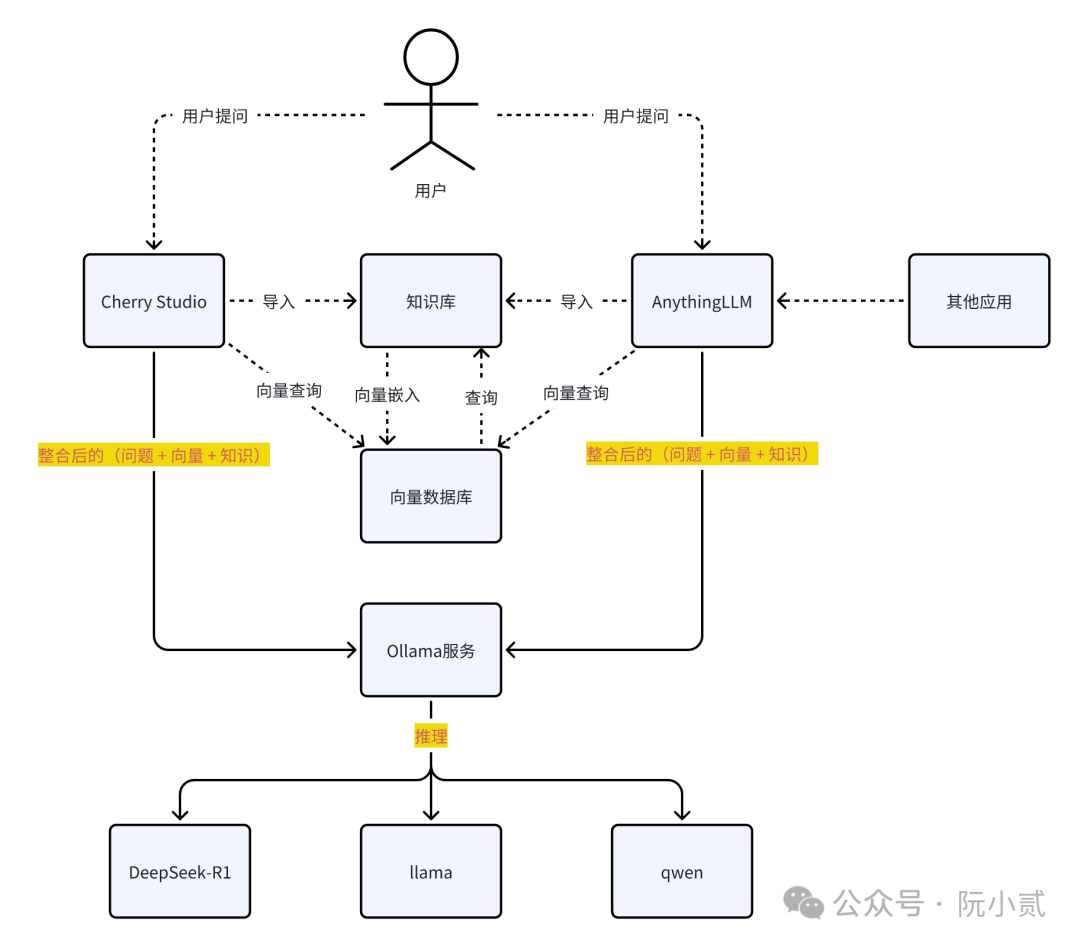
六、AnythingLLM + DeepSeek实战
6.1、本地部署DeepSeek
如果之前已经部署过,这里可以直接跳过忽略。
如果还没有部署或者不知道怎么部署的,可以去看看我之前这篇文章:
6.2、下载AnythingLLM桌面版
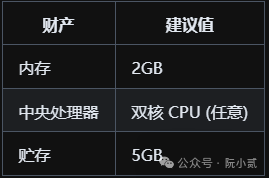
6.2.1、AnythingLLM 的推荐配置
这是运行 AnythingLLM 的最小值。
这足以让您存储一些文档、发送聊天记录并使用 AnythingLLM 功能。
6.2.2、AnythingLLM官网:
https://anythingllm.com/desktop
为了方便大家下载,我专门将所有应用下载到网盘,进入即可保存或者下载
DeepSeek相关安装包——夸克网盘 链接:https://pan.quark.cn/s/fd9135fc7cd9 提取码:8KxZ
6.3、安装AnythingLLM桌面版
下载安装包
双击打开安装包

一般情况下会出现这个提示,
点开【更多信息】
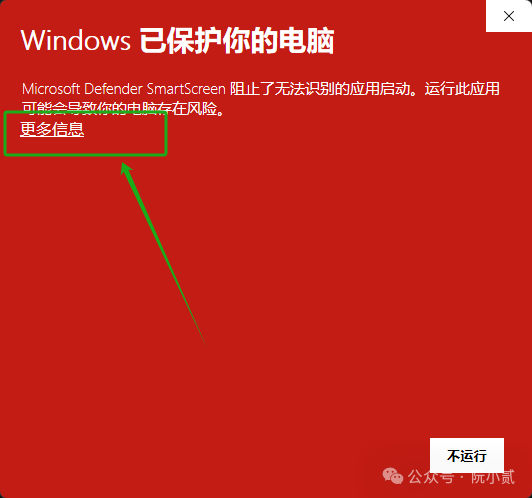
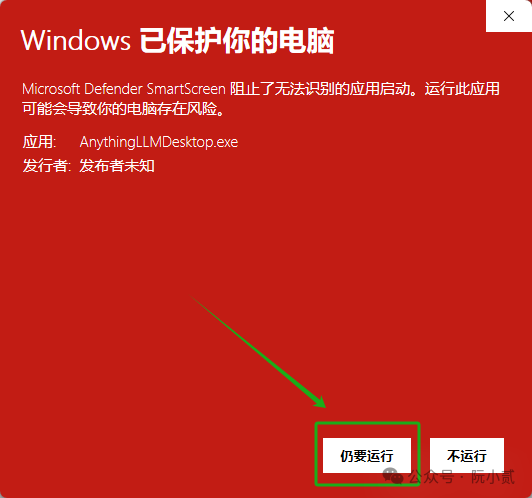
选择【仍要运行】即可
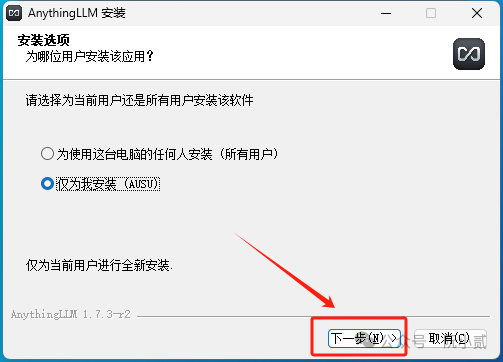
之后,就是正常的下一步了。
这个时候开始安装一些依赖库(为本地LLM做支持用)了。
安装完成
桌面上可以看到AnythingLLM的图标
6.4、AnythingLLM 配置
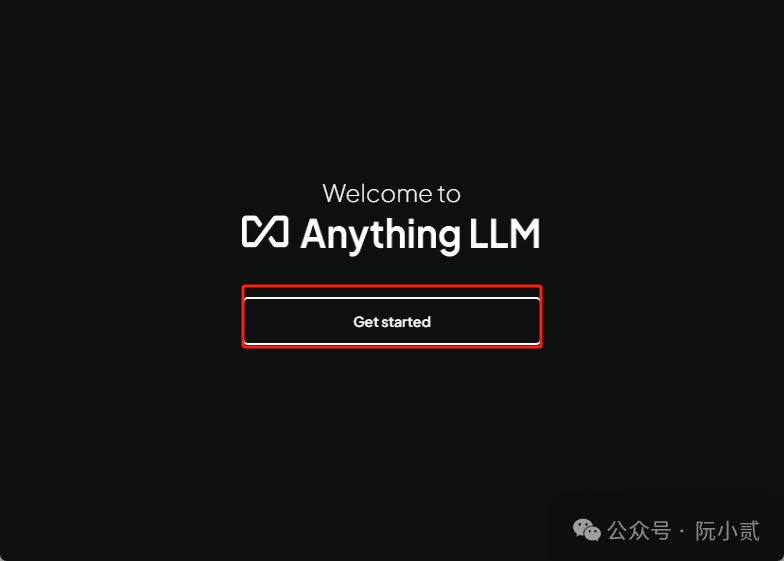
双击桌面AnythingLLM图标打开,首次启动会出现【Get started】,点击即可。
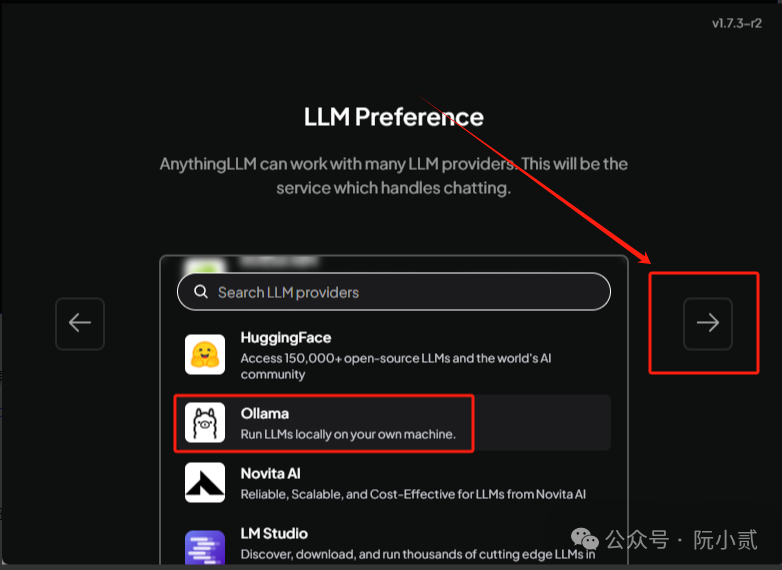
这里可以不做配置,直接点击右侧箭头往右滑。
OK,到这里就算正式进入到工作界面了。
但是,在搭建知识库之前,我们需要给AnythingLLM做一些配置
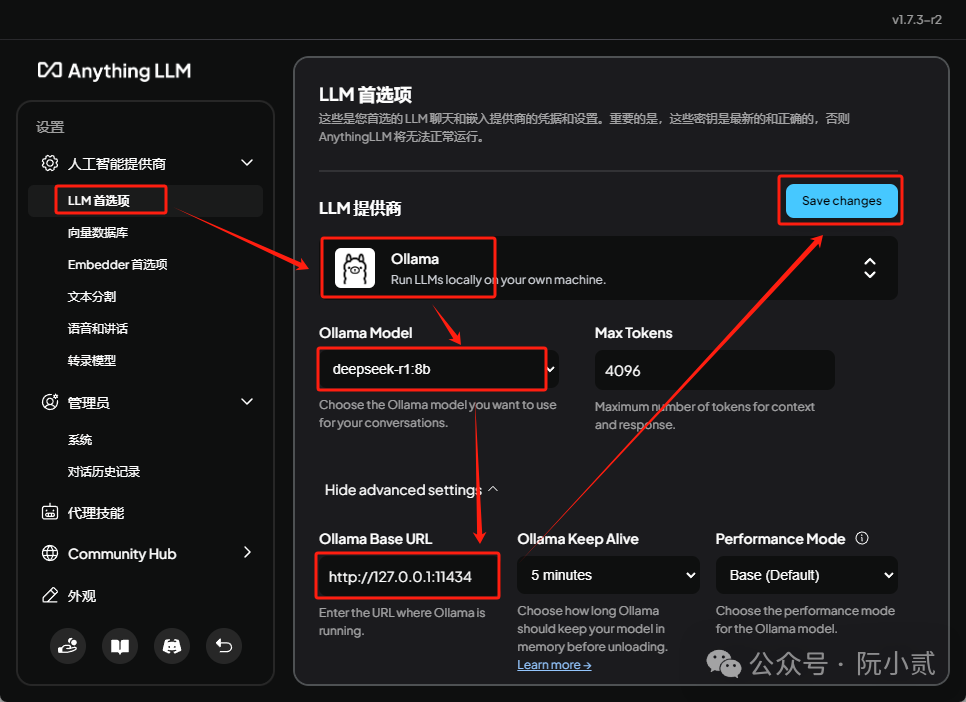
6.4.1、配置LLM首选项
点击左下方【扳手】按钮进入设置界面。
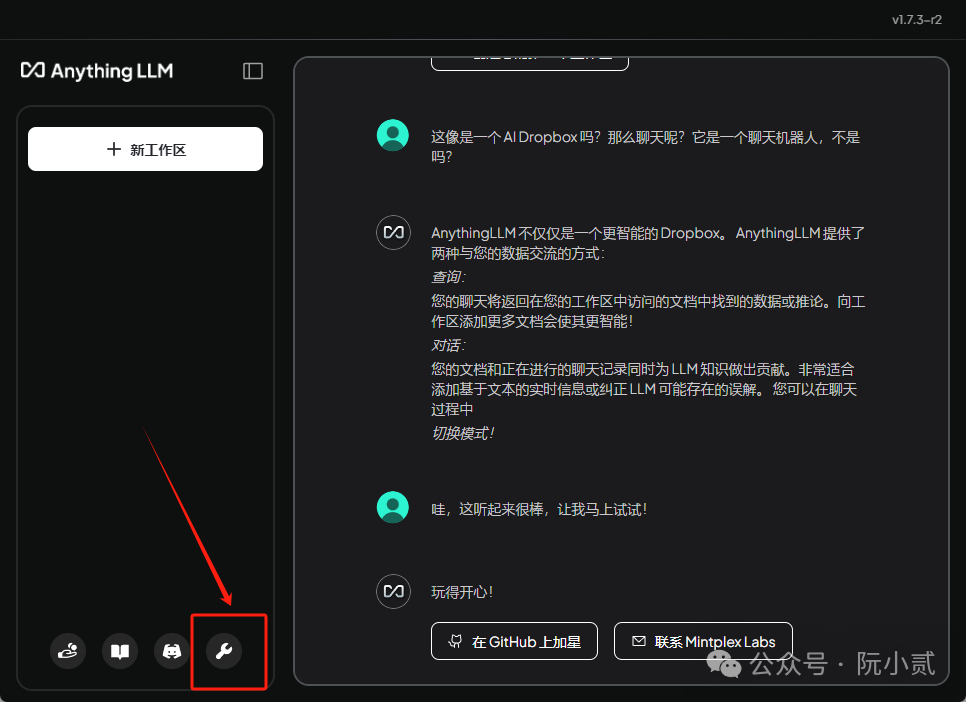
“
点击 LLM首选项
选择ollama作为模型提供商
选择已安装的deepsek 模型
注意下地址
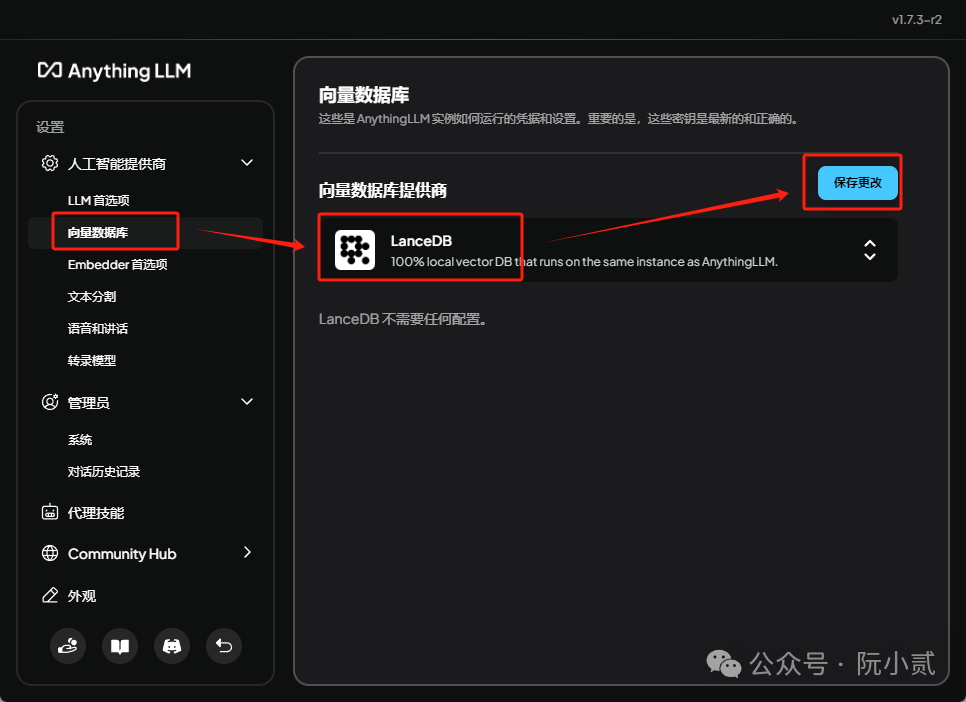
6.4.2、配置向量数据库
向量数据库不用动保持默认即可,使用自带的(ps:如果没有选择安装目录,默认在c盘,如果后续有需要可以挪走)
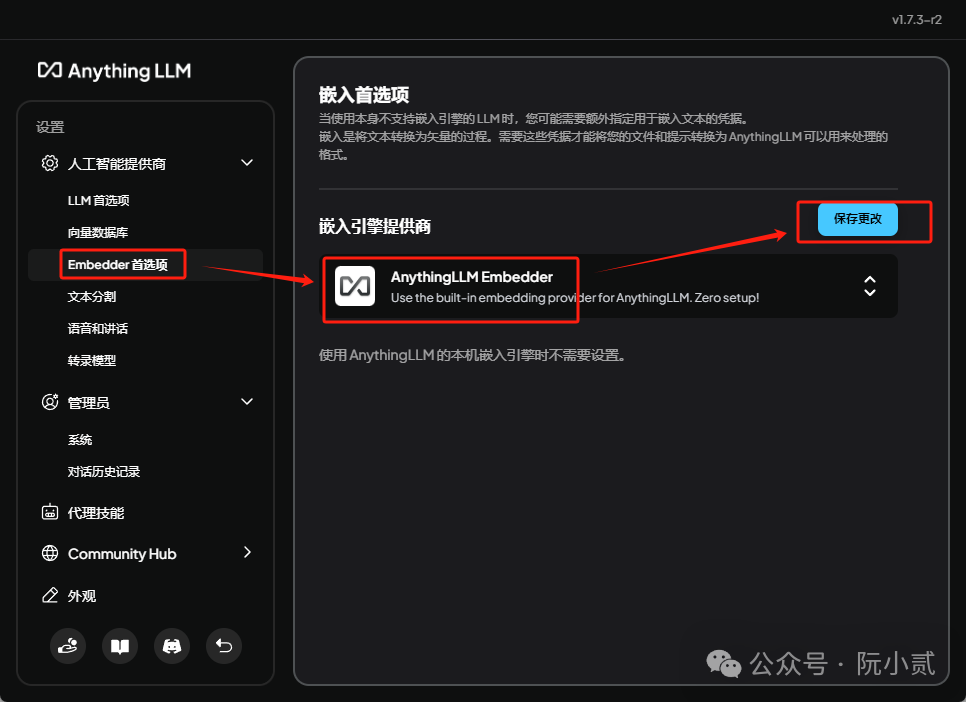
6.4.3、配置嵌入模型
这里的嵌入模型配置,可以使用默认自带的,也可以使用ollama安装好的(如果本地有安装的话)
配置完点击【保存更改】再点击左下角的【返回】即可
6.5、配置工作区
点击【+新工作区】创建一个新的工作区
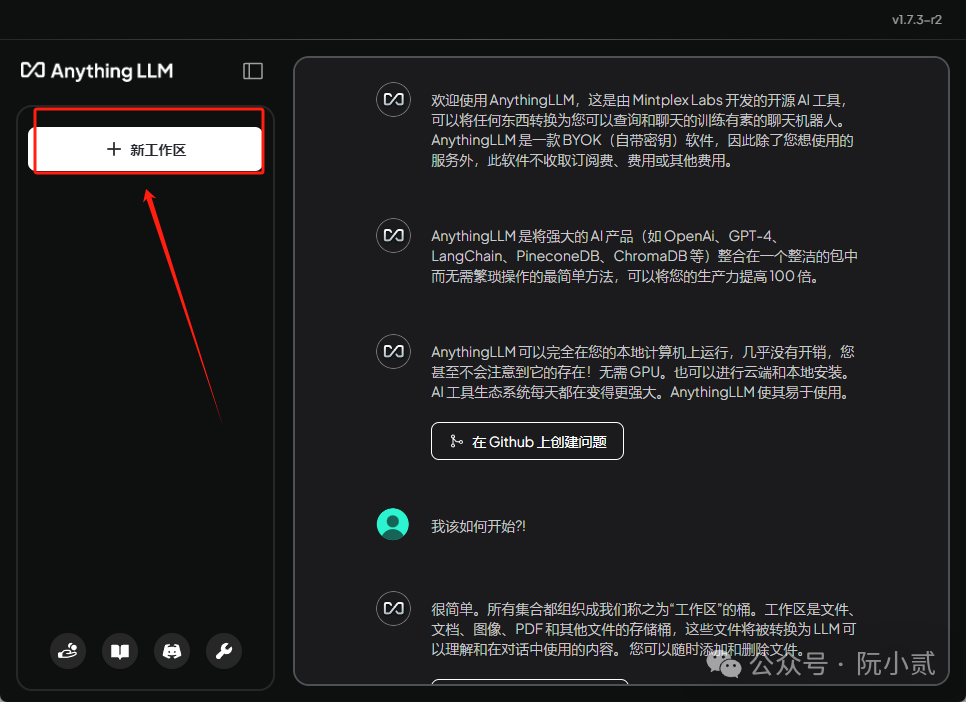
随意起一个工作区名称
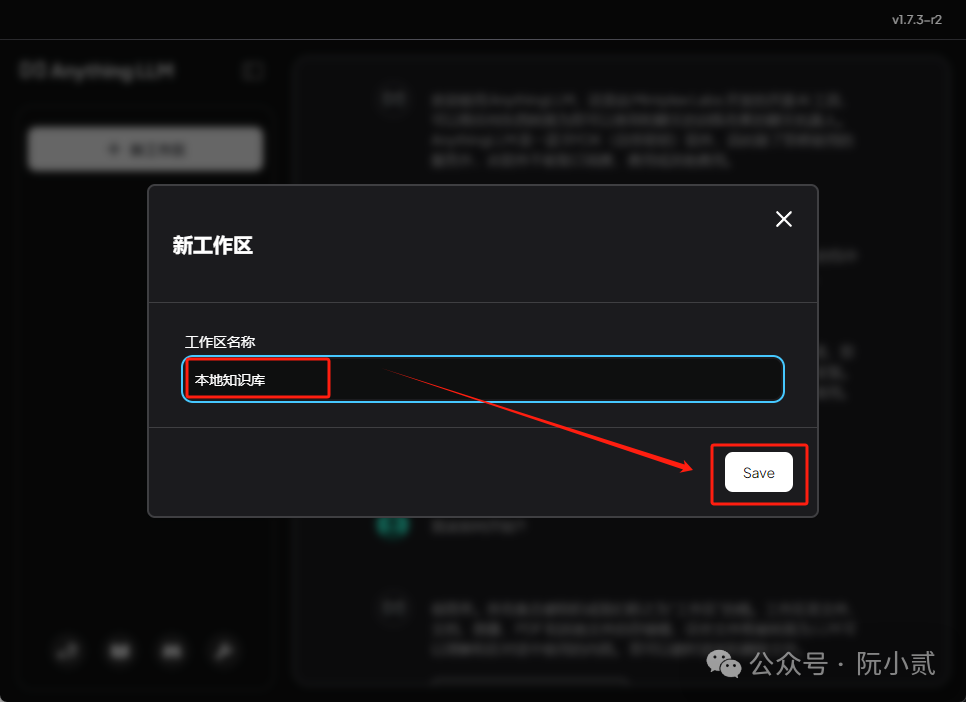
6.6、上传文档
-
上传方式:
-
点击工作空间的上传按钮,支持上传PDF、CSV、音频文件,或者抓取网页内容。
-
上传后,右键点击文件并选择“加入工作空间”即可。
点击【upload a document】上传文件
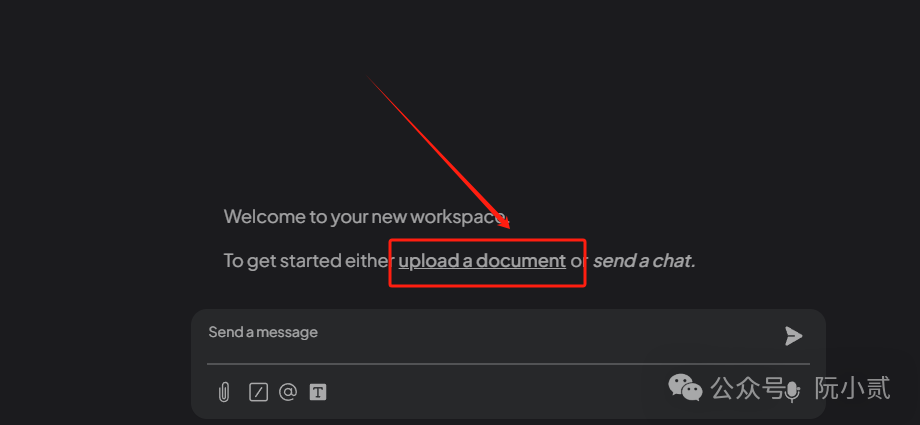
点击按钮开始添加文档
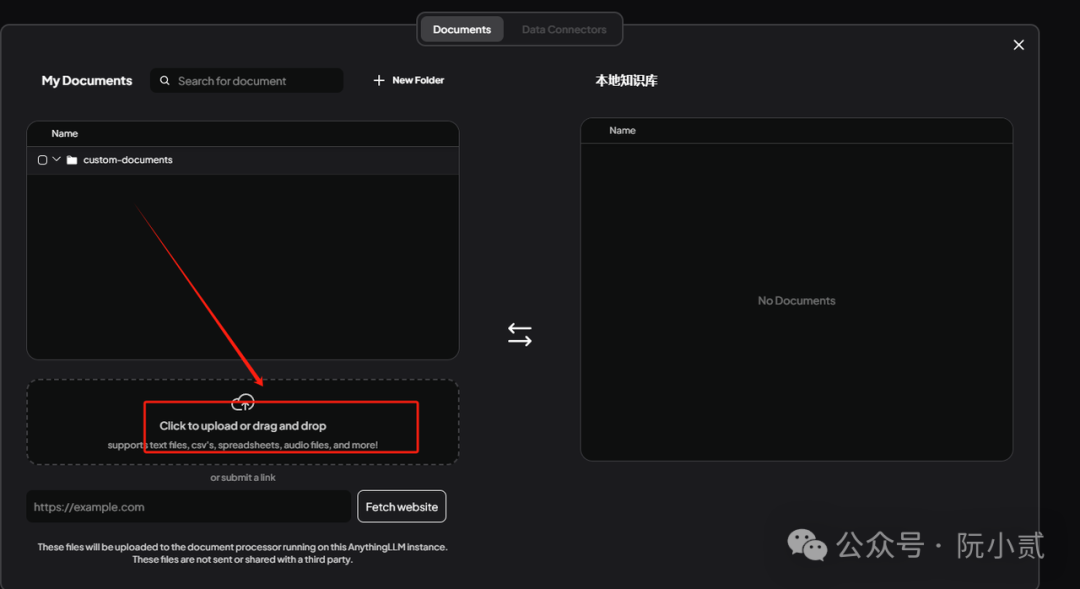
并将文档 Move to Workspace,意思是加载到AnythingLLM的本地知识库中。
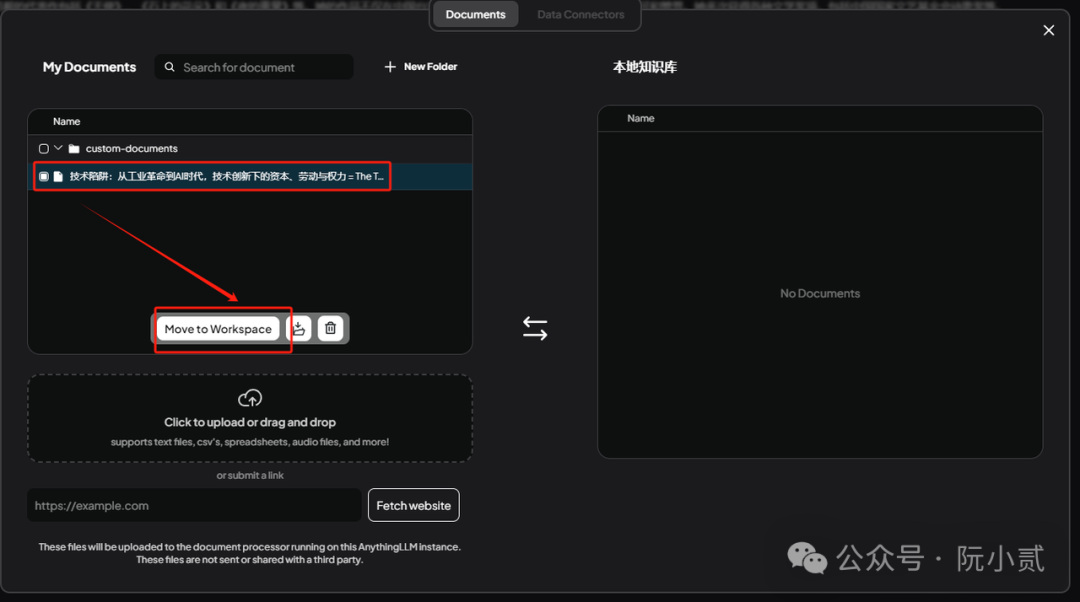
然后点击【Save and Embed】即可。
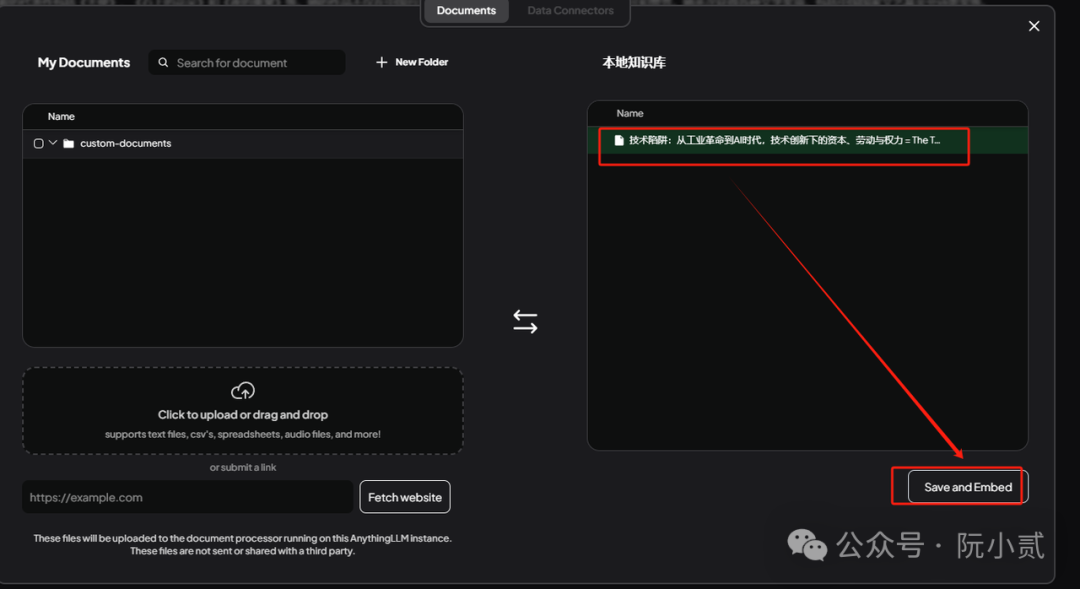
稍微等待一会儿
出现 Workspace updated successfully 就表示知识库配置已经完成。
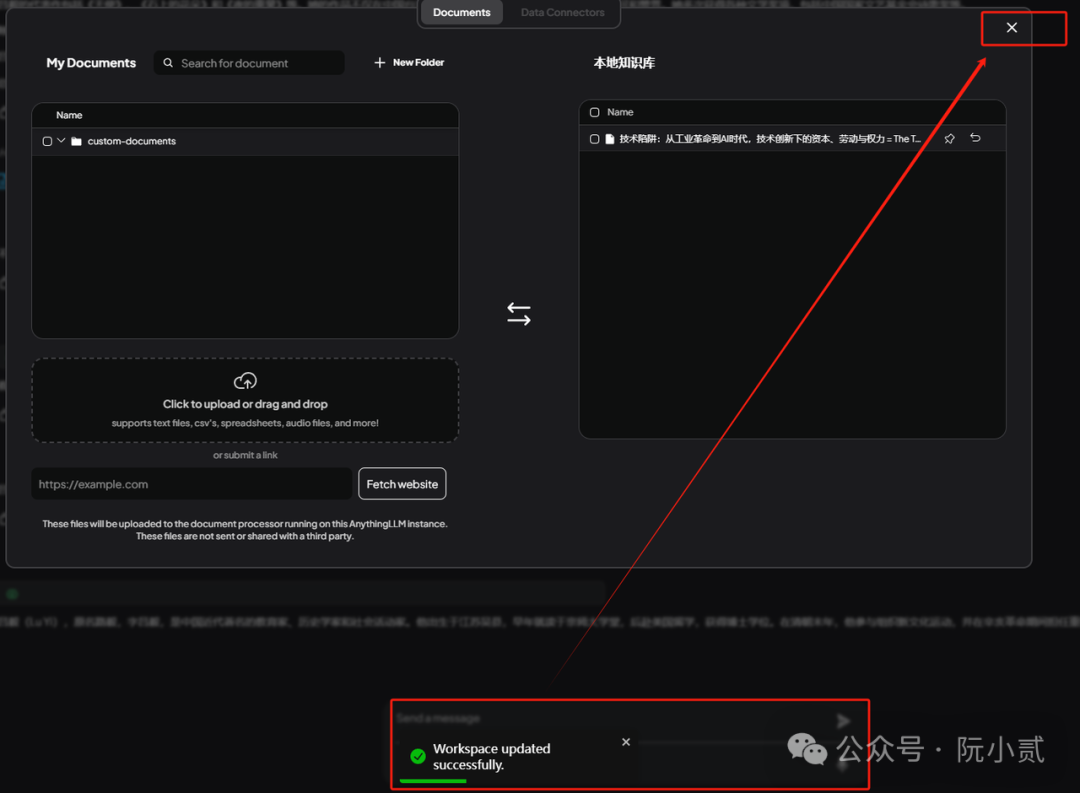
6.7、验证知识库效果
6.7.1、知识检索问答
“
开启对话:
在工作区点击 New Thread 开启新的对话。
提问后,AI会根据知识库中的内容进行回答。
查看引用来源:
如果想确认AI回答的知识来源,可以在回答底部点击 Show Citations 查看引用的知识。
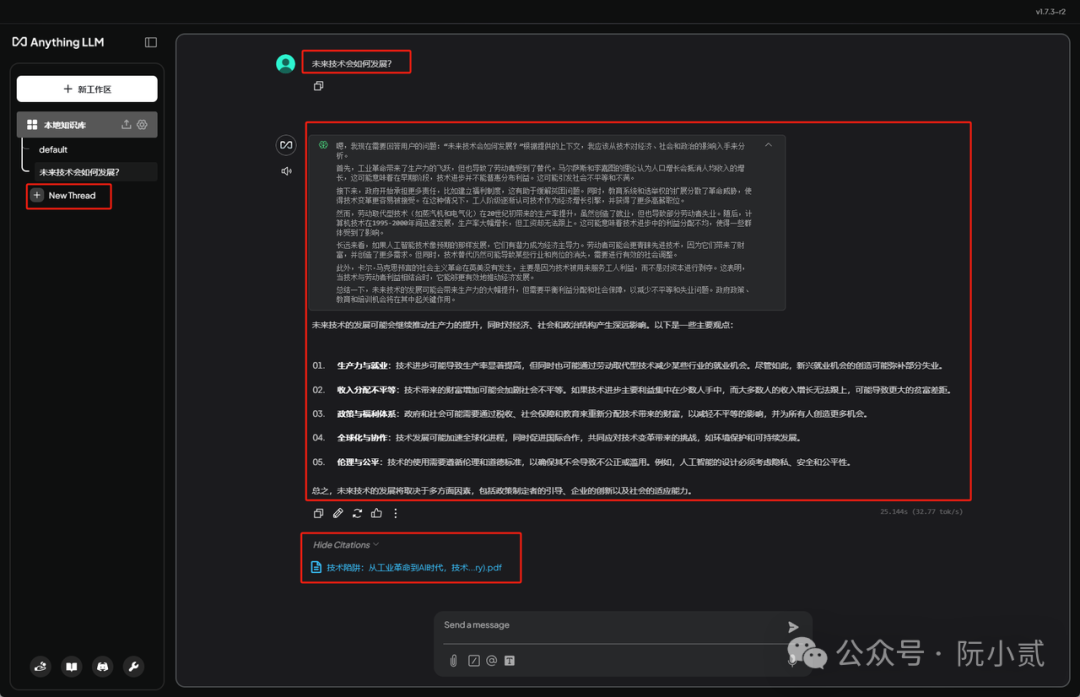
然后我在群里看到不少兄弟安装AnythingLLM的时候经常出现以下报错,
这个时候可以参考官方这篇文章去了解下如何手动安装依赖项:
https://docs.anythingllm.com/installation-desktop/manual-install
OK,到这里关于AnythingLLM的知识库搭建就已经算是基本完成了。
然后,可能有些小伙伴会问,我的知识库数据都保存到哪里去了?
别着急,都在你的电脑里面,数据不会丢。
6.7.2、我的数据位于哪里?
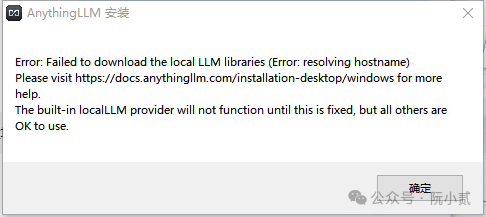
所有与 AnythingLLM Desktop 有关的数据将位于以下位置。请将其替换为您的设备用户名。
在Mac上: /Users/<usr>/Library/Application Support/anythingllm-desktop/storage 在 Linux 上: /Users/<usr>/.config/anythingllm-desktop/storage/ 在 Windows 上: C:\Users\<usr>\AppData\Roaming\anythingllm-desktop\storage
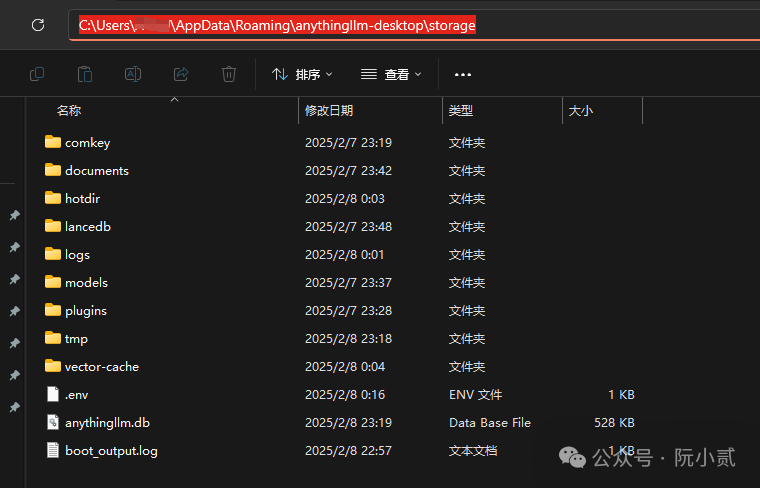
6.7.3、每个文件夹是什么?
“
lancedb:这是存储您的本地矢量数据库及其表的地方。
documents:这是任何上传文件的解析文档内容。
vector-cache:此文件夹是之前上传并嵌入的文件的缓存和嵌入表示。其文件名经过哈希处理。
models:系统使用的任何本地存储的 LLM 或 Embedder 模型都存储在此处。通常是 GGUF 文件。
anythingllm.db:这是 AnythingLLM SQLite 数据库。
plugins:这是存储您的自定义代理技能的文件夹。
好了,可能又有小伙伴说了,我看到网上搭建知识库的工具有很多种,
比如:像AnythingLLM、Dify、MaxKB等都可以搭建本地知识库,
那么问题来了,哪一个最好?
他们之间有什么区别?
我们到底应该要怎么选择?
其实,没有所谓的最好的,
只有适合自己的才是最好的。
七、三大知识库工具大PK?
OK,我带着以上这些问题,去问了一下DeepSeek,来看看他给我的答案。


八、如何选择知识库工具?
1. 选AnythingLLM:
“
需求:数据绝对本地化,避免任何云端传输。
技术能力:有运维团队,能自主管理本地模型(如Llama 3)。
场景:金融、医疗等敏感行业,或内部知识库需严格管控。
2. 选Dify:
“
需求:构建复杂AI应用(如知识库+客服+自动化流程)。
技术能力:具备API集成经验,希望低代码开发。
场景:企业需要灵活扩展功能,整合现有系统(如CRM、ERP)。
3. 选MaxKB:
“
需求:快速搭建轻量级问答系统,无复杂功能需求。
技术能力:非技术人员主导,追求简单配置。
场景:中小企业知识库、教育机构FAQ、个人学习助手。
九、成本与资源考量
“
硬件成本:AnythingLLM需本地GPU运行大模型,成本较高;Dify和MaxKB若使用云端API,按调用量计费。
维护成本:AnythingLLM需技术维护;Dify和MaxKB更易托管。
开源协议:三者均开源,但企业版功能或需付费(如Dify的团队协作功能)。
所以,具体还得根据团队规模、技术能力及场景复杂度权衡选择,必要时可结合工具试用(如Dify的在线Demo、MaxKB的一键安装)进一步验证。
十、写在最后
AnythingLLM为知识管理和智能问答提供了一个开源的整体解决方案。
它不仅能帮助个人和团队更好地管理和利用知识资产,还能大幅提升工作效率。
虽然部署和配置需要一定技术基础,但投入的时间和精力是值得的。
经过一段时间的使用,你会发现它能极大地改善团队的知识管理和信息获取效率。
特别是对于需要经常查阅大量文档的团队来说,AnythingLLM可以成为一个强大的助手。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 1857
1857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









