




 该博客介绍了使用TensorFlow2.0在Kaggle上进行两个图像识别任务的实战:10-monkey-species和CIFAR-10。通过数据增强提升10-monkey-species的模型性能,300轮训练后准确率可达86%。还探讨了在ResNet50上进行迁移学习微调,发现训练后五层比仅训练最后一层效果更好。对于CIFAR-10数据集,详细讲解了如何下载数据及使用Keras数据生成器进行处理。
该博客介绍了使用TensorFlow2.0在Kaggle上进行两个图像识别任务的实战:10-monkey-species和CIFAR-10。通过数据增强提升10-monkey-species的模型性能,300轮训练后准确率可达86%。还探讨了在ResNet50上进行迁移学习微调,发现训练后五层比仅训练最后一层效果更好。对于CIFAR-10数据集,详细讲解了如何下载数据及使用Keras数据生成器进行处理。
5.2_TensorFlow—kaggle实战
1、kaggle实战_10-monkey-species
利用kaggle进行训练
- 登陆kaggle官网
- 找到10-monkey-species数据集
- 新建notebook编写代码
1.1、使用数据增强
- 加载库
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import sklearn
import sys
import tensorflow as tf
import time
from tensorflow import keras
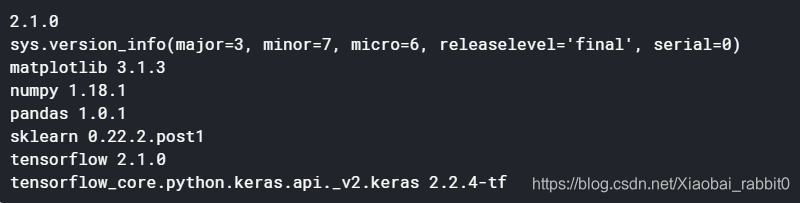
print(tf.__version__)
print(sys.version_info)
for module in mpl,np,pd,sklearn,tf,keras:
print(module.__name__,module.__version__)
- 加载数据
train_dir = "../input/10-monkey-species/training/training"
valid_dir = "../input/10-monkey-species/validation/validation"
label_file = "../input/10-monkey-species/monkey_labels.txt"
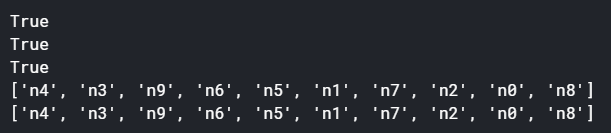
print(os.path.exists(train_dir))
print(os.path.exists(valid_dir))
print(os.path.exists(label_file))
print(os.listdir(train_dir))
print(os.listdir(valid_dir))
#读取数据
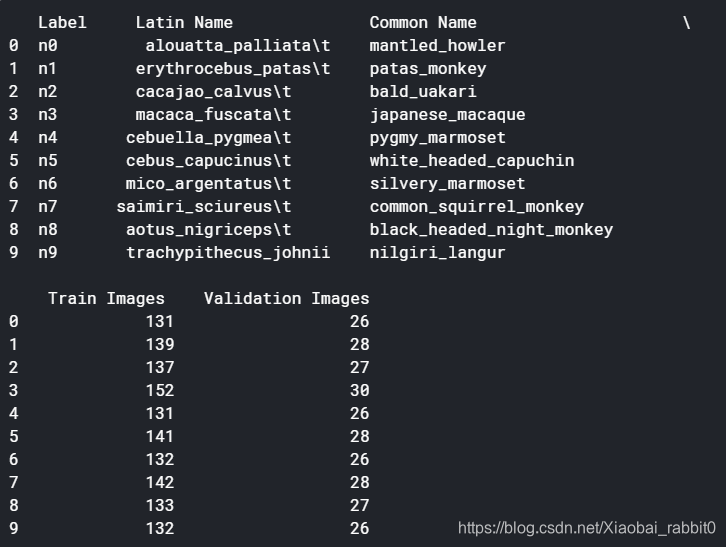
labels = pd.read_csv(label_file,header = 0)
print(labels)
#读取图片
height = 128
width = 128
channels = 3
batch_size = 64
num_classes = 10
#读取数据(keras有一个高层封装:可以读取数据且做数据增强 -> ImageDataGenerator)
train_datagen = keras.preprocessing.image.ImageDataGenerator(
rescale = 1./255, #图像预处理(归一化),输入图片的像素点的值是(0,255)
rotation_range = 40, #图片增强,把图片随机旋转一个角度(-40,40)
width_shift_range = 0.2, #给图片做位移,增加图像位移鲁棒性(池化也可以增加图像位移鲁棒性)
height_shift_range = 0.2, #位移的参数,如果写<1的数,则表示位移比例。>1的值表示移动的像素值(这里并不是平移20%,而是在(0,20%)之间选一个数去平移)
shear_range = 0.2, #表示剪切强度
zoom_range = 0.2, #表示缩放强度
horizontal_flip = True, #表示是否去做随机的水平翻转
fill_mode = 'nearest', #对图片进行处理(放大等)的时候,如果需要填充像素,的填充方式
)
#从文件夹读取图片,并调用上述方法进行预处理
train_generator = train_datagen.flow_from_directory(train_dir,
target_size = (height,width), #将读进来的图片缩放到指定大小
batch_size = batch_size, #生成的图片,多少张为一组
seed = 7, #随机数,做随机的,随便设置一个数即可
shuffle = True, #数据是否需要混排
class_mode = "categorical") #设置label的格式,one-hot编码前()后(categorical)两种格式
#定义验证集的generator
valid_datagen = keras.preprocessing.image.ImageDataGenerator(rescale = 1./255) #验证集也需要做归一化
valid_generator = valid_datagen.flow_from_directory(valid_dir,
target_size = (height,width), #将读进来的图片缩放到指定大小
batch_size = batch_size, #生成的图片,多少张为一组
seed = 7, #随机数,做随机的,随便设置一个数即可
shuffle = False, #验证集不做训练,所以不需要做混排
class_mode = "categorical") #设置label的格式,one-hot编码前()后(categorical)两种格式
'''
class_mode: "categorical", "binary", "sparse"或None之一. 默认为"categorical.
该参数决定了返回的标签数组的形式:
"categorical"会返回2D的one-hot编码标签;
"binary"返回1D的二值标签."sparse"返回1D的整数标签;
如果为None则不返回任何标签, 生成器将仅仅生成batch数据;
这种情况在使用model.predict_generator()和model.evaluate_generator()等函数时会用到.
'''
#查看生成多少张数据
train_num = train_generator.samples
valid_num = valid_generator.samples
print(train_num,valid_num)

#从generator中提取数据
for i in range(2): #遍历两次,取两次数据
x,y = train_generator.next() #在train_generator中读取数据,next方法,获取下一组数据
print(x.shape,y.shape) #x是4维矩阵 -> 大小128 * 128、通道数3、样本数64 y是64个样本数,10个类别
print(y) #x数据太多了,这里就不打印了

#构建模型
model = keras.models.Sequential([
keras.layers.Conv2D(filters=32,kernel_size=3,padding='same',
activation='relu',input_shape=[width,height,channels]),
keras.layers.Conv2D(filters=32,kernel_size=3,padding='same',
activation='relu'),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Conv2D(filters=64,kernel_size=3,padding='same',
activation='relu'),
keras.layers.Conv2D(filters=64,kernel_size=3,padding='same',
activation='relu'),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Conv2D(filters=128,kernel_size=3,padding='same',
activation='relu'),
keras.layers.Conv2D(filters=128,kernel_size=3,padding='same',
activation='relu'),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Flatten 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1498
1498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









