




 本文介绍了卷积神经网络的基础理论,包括其结构和解决神经网络参数过多、计算资源不足的问题。在实战部分,通过Keras展示了如何实现卷积神经网络和深度可分离卷积,探讨了两者的参数数量和精度差异,并提供了训练建议。深度可分离卷积在网络参数减少的同时,可能导致精度下降,需要更多的训练轮数。
本文介绍了卷积神经网络的基础理论,包括其结构和解决神经网络参数过多、计算资源不足的问题。在实战部分,通过Keras展示了如何实现卷积神经网络和深度可分离卷积,探讨了两者的参数数量和精度差异,并提供了训练建议。深度可分离卷积在网络参数减少的同时,可能导致精度下降,需要更多的训练轮数。
5.2_卷积神经网络
1、理论部分
- 卷积神经网络
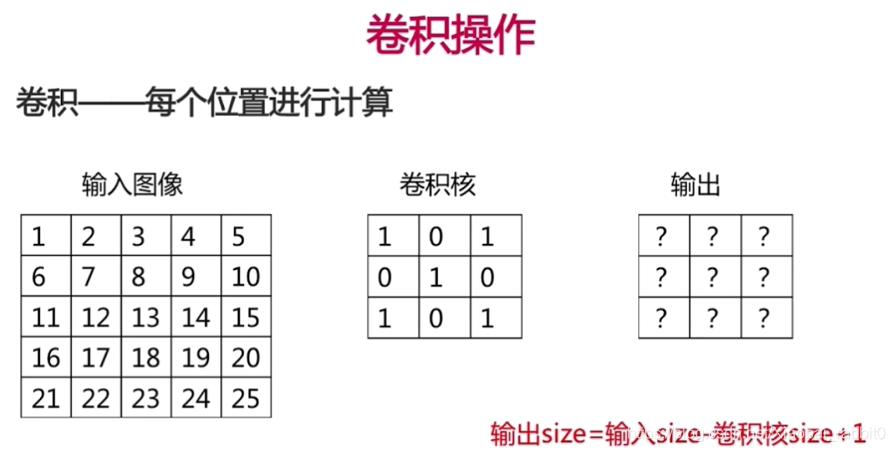
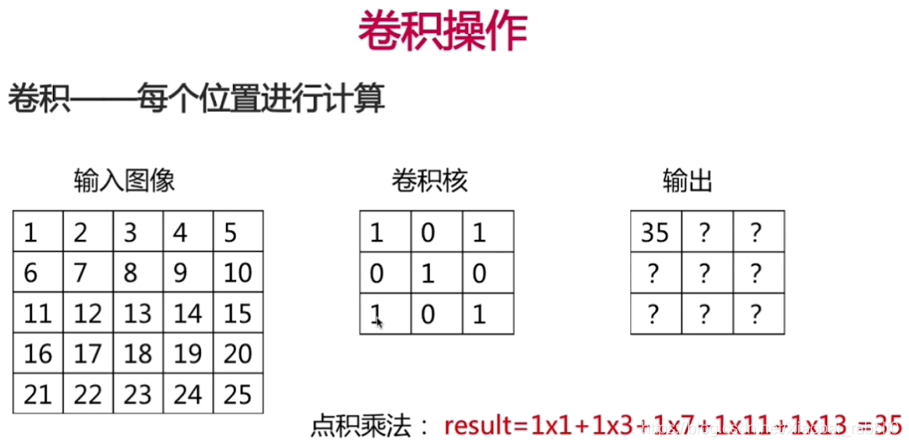
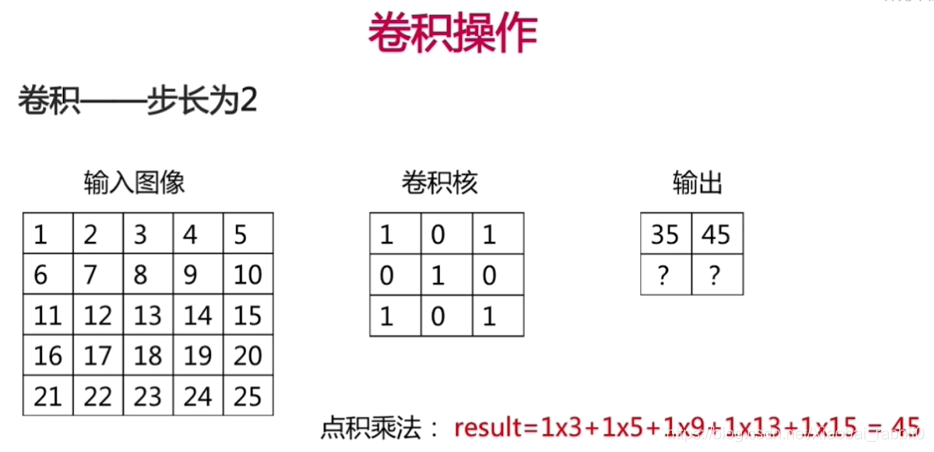
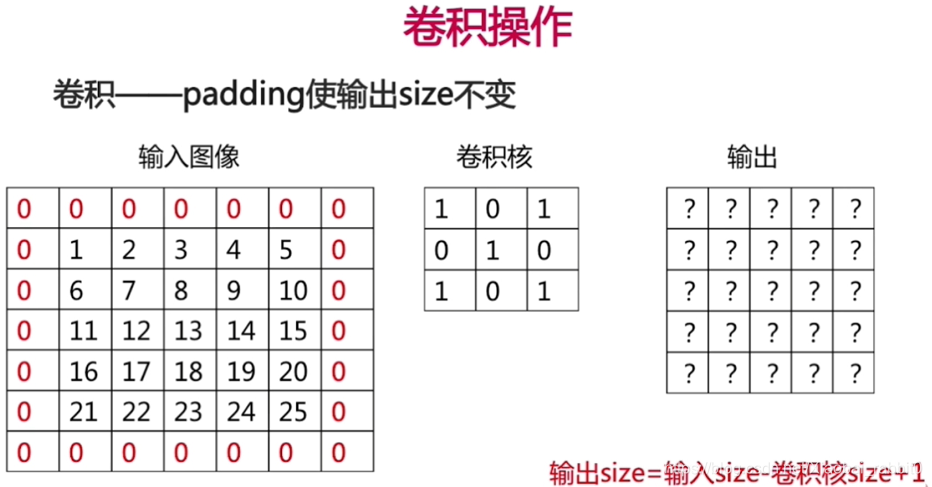
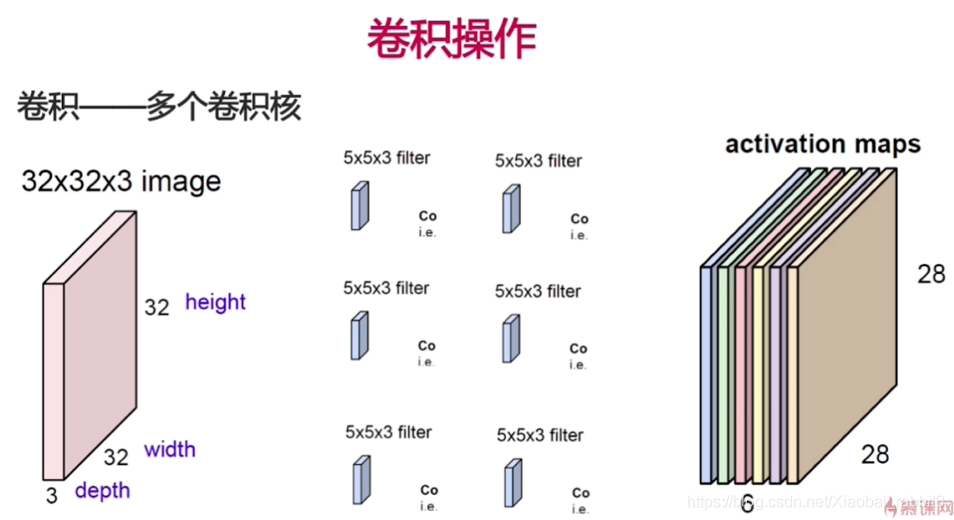
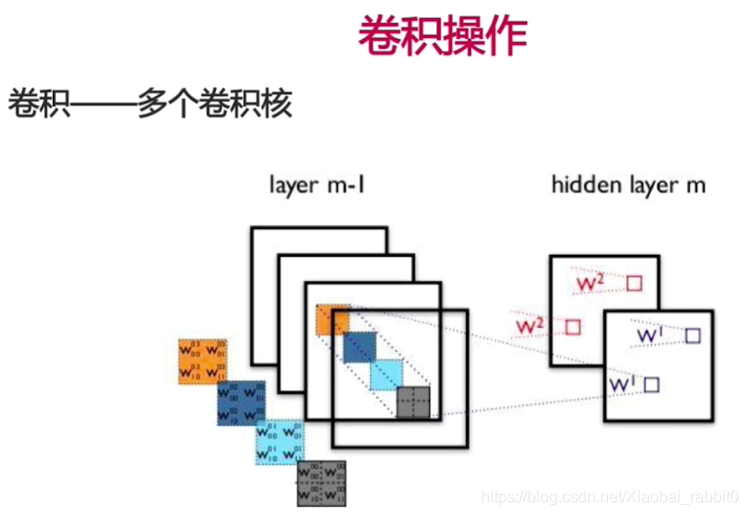
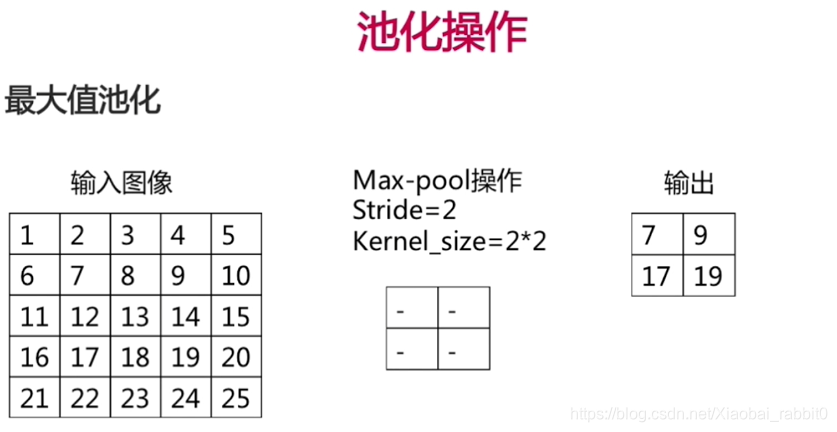
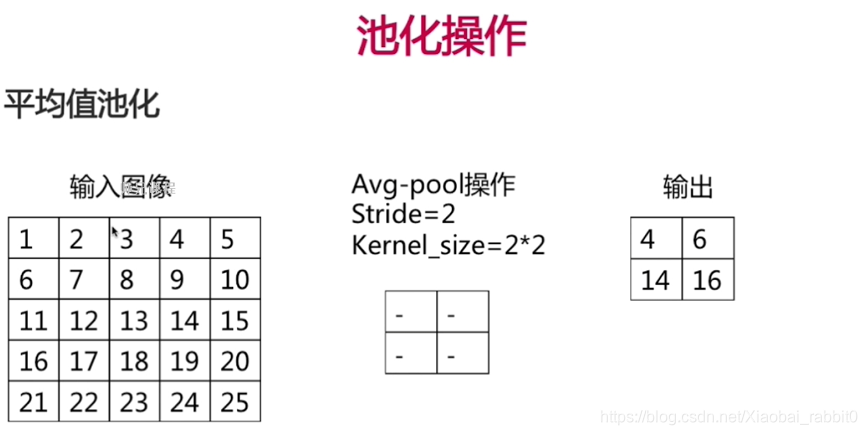
- 卷积操作、池化操作
- 深度可分离卷积
- 数据增强
- 迁移学习
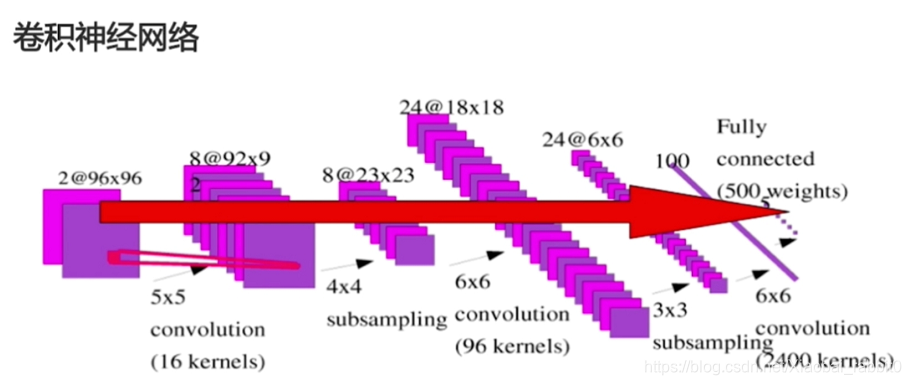
1.1、卷积神经网络
1.1.1 结构
- 卷积神经网络
- (卷积层 + 池化层(可选)) * N + 全连接层 * M ;
(其中,N >= 1,M >= 0,卷积层输入输出均为矩阵,全连接层输入输出均为向量。连接方法就是在卷积的最后一层做一个展平处理。全连接层输出可以是一个值,也可以是一个向量,也就是回归和分类。) - 分类任务、回归任务;
- (卷积层 + 池化层(可选)) * N + 全连接层 * M ;
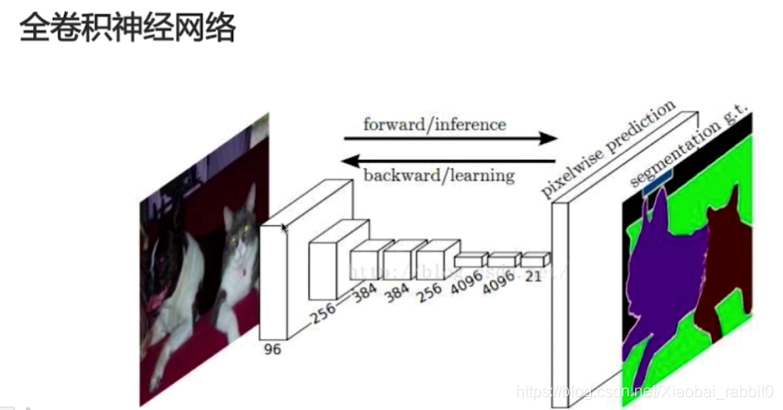
- 全卷积神经网络
- (卷积层 + 池化层(可选)) * N + 反卷积层 * K;
- 物体分割
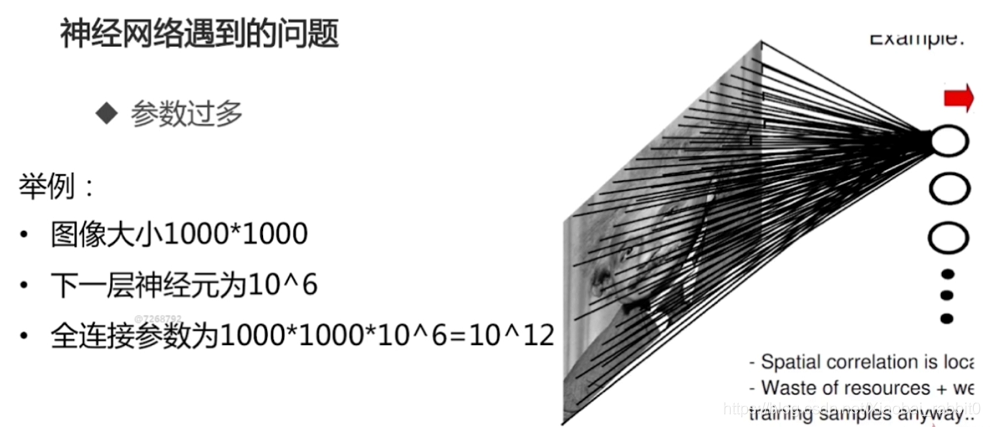
1.1.2 神经网络遇到的问题
- 参数过多
- 计算资源不足
- 容易过拟合,需要更多训练数据
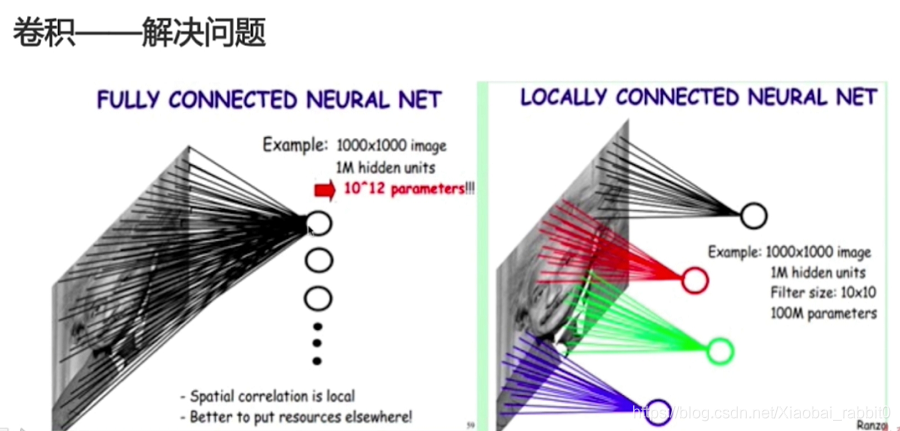
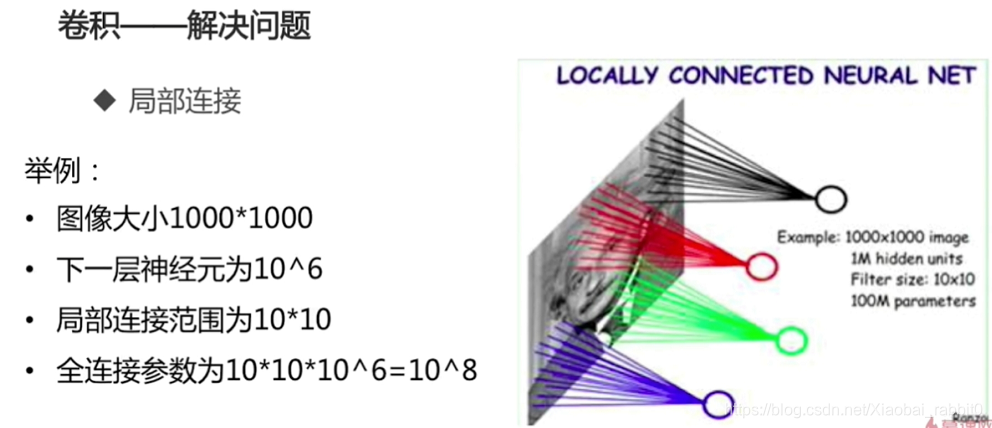


答案:3 * 3 * 3 * 192
完美解答


2、实战部分
- keras实现卷积神经网络
- keras实现深度可分离卷积
- keras实战kaggle
- 10 monkeys和cifar10
- 数据增强与迁移学习
2.1、keras实现卷积神经网络
#深度神经网络
model = keras.models.Sequential()
#定义第一个卷积层
model.add(keras.layers.Conv2D(filters = 32, #32个通道(32个卷积核)
kernel_size=3, #卷积核大小为3
padding='same', #平均值池化
activation='relu', #加padding是否要输入和输出大小一样
input_shape=(28,28,1))) #输入图片大小 28*28*1
model.add(keras.layers.Conv2D(filters = 32, #32个通道(32个卷积核)
kernel_size=3, #卷积核大小为3
padding='same', #加padding是否要输入和输出大小一样
activation='relu')) #不需要加input_shape
#池化层
model.add(keras.layers.MaxPool2D(pool_size=2)) #步长和pool_size相同
model.add(keras.layers.Conv2D(filters = 64, #32个通道(32个卷积核)
kernel_size=3, #卷积核大小为3
padding='same', #平均值池化
activation='relu')) #加padding是否要输入和输出大小一样
model.add(keras.layers.Conv2D(filters = 64, #32个通道(32个卷积核)
kernel_size=3, #卷积核大小为3
padding='same', #加padding是否要输入和输出大小一样
activation='relu')) #不需要加input_shape
#池化层
model.add(keras.layers.MaxPool2D(pool_size=2)) #步长和pool_size相同
model.add(keras.layers.Conv2D(filters = 128, #32个通道(32个卷积核)
kernel_size=3, #卷积核大小为3
padding='same', #平均值池化
activation='relu')) #加padding是否要输入和输出大小一样
model.add(keras.layers.Conv2D(filters = 128, #32个通道(32个卷积核)
kernel_size=3, #卷积核大小为3
padding='same', #加padding是否要输入和输出大小一样
activation='relu')) #不需要加input_shape
#池化层
model.add(keras.layers.MaxPool2D(pool_size=2)) #步长和pool_size相同
#连接全连接层之前,先做一个flatten
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128,activation='relu'))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss = "sparse_categorical_crossentropy", #如果y已经是向量了就用categorical_crossentropy",如果是数字就用sparse_
optimizer = "sgd",
metrics = ["accuracy"])
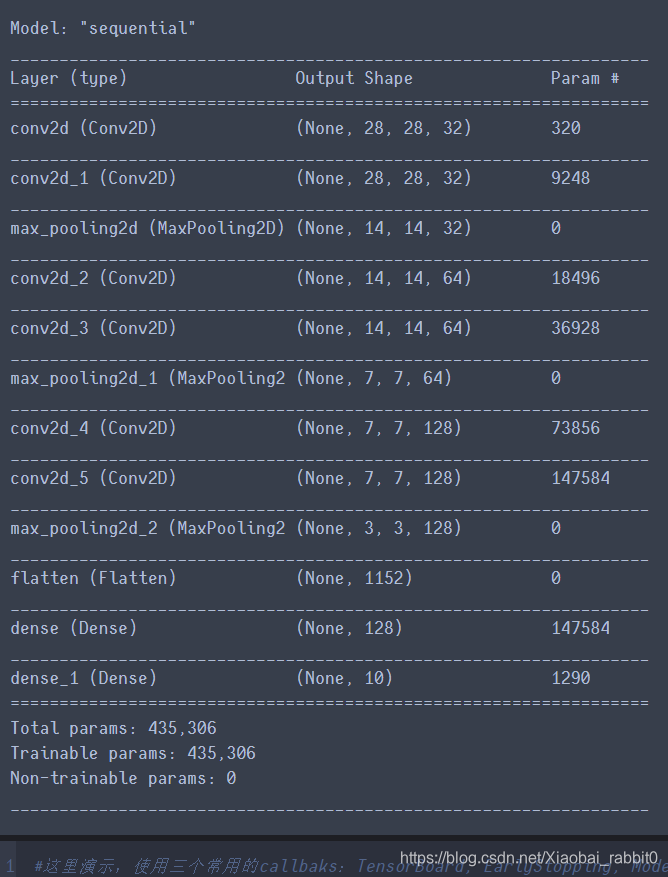
model.summary()
#这里演示,使用三个常用的callbaks:TensorBoard, EarlyStopping, ModelCheckpoint
#对于Tensorboard需要一个文件夹,对于ModelCheckpoint来说需要一个文件名
#定义一个文件夹,和文件名
#logdir = './dnn-callbacks'
logdir = os.path.join("cnn-selu-callbacks")
if not os.path.exists(logdir):
os.mkdir(logdir)
output_model_file = os.path.join(logdir, "fashion_mnist_model.h5")
callbacks = [
keras.callbacks.TensorBoard(logdir),
keras.callbacks.ModelCheckpoint(output_model_file,save_best_only = True),
keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3),
]
#callbacks是在训练过程中做一些监听,所以要添加到fit函数中
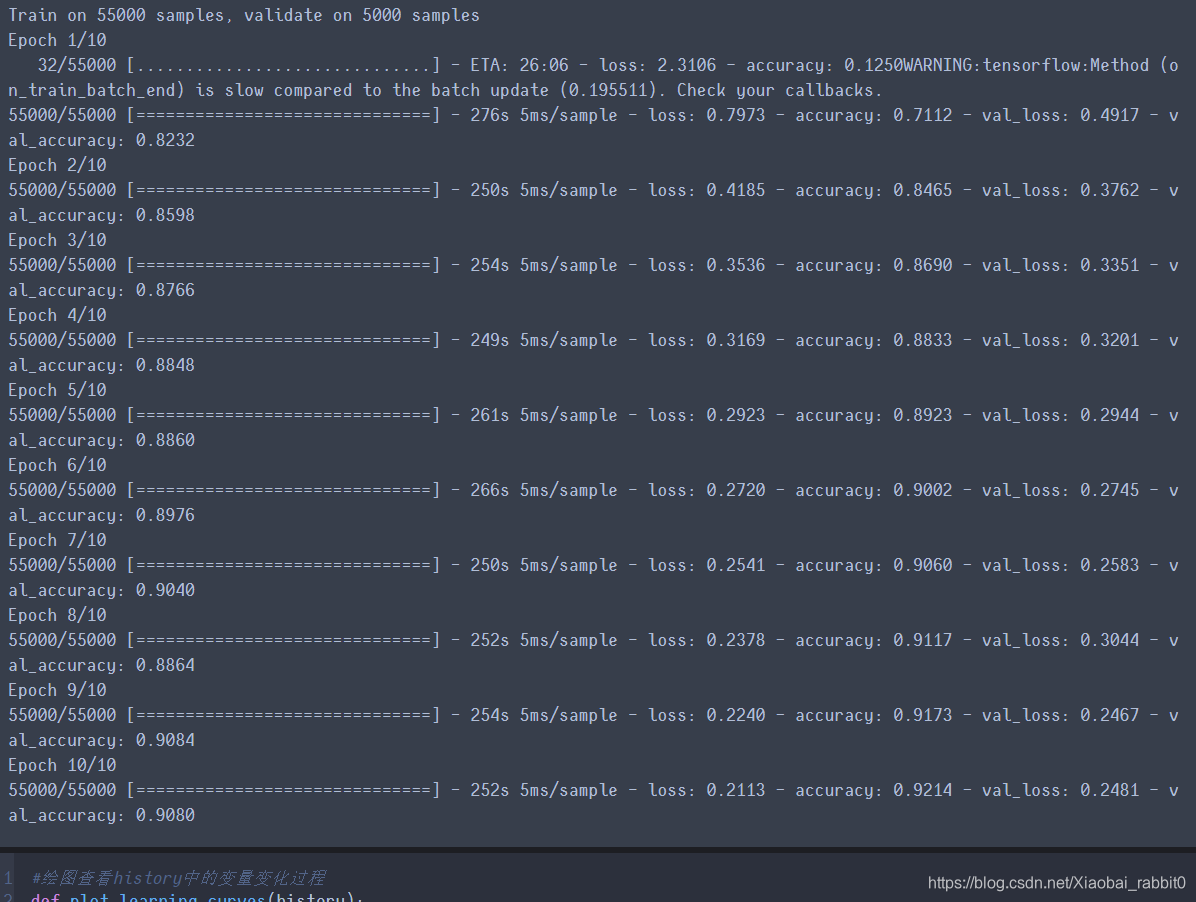
history = model.fit(x_train_scaler, y_train, epochs=10,
validation_data = (x_valid_scaled, y_valid),
callbacks = callbacks)
#绘图查看history中的变量变化过程
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize = (8,5)) #将数据转换成DataFrame,然后调用plot实现
plt.grid(True) #绘制网格
plt.gca().set_ylim(0, 2) #设定y坐标的范围
plt.show()
plot_learning_curves(history)
#在测试集上进行测试
model.evaluate(x_test_scaled, y_test)

注:将网络中所有relu激活函数换成selu后,模型的效果会得到不错的提升。(有时也会变得更糟糕)
- 可以自行尝试
2.2、keras实现深度可分离卷积
2.2.1、理论部分
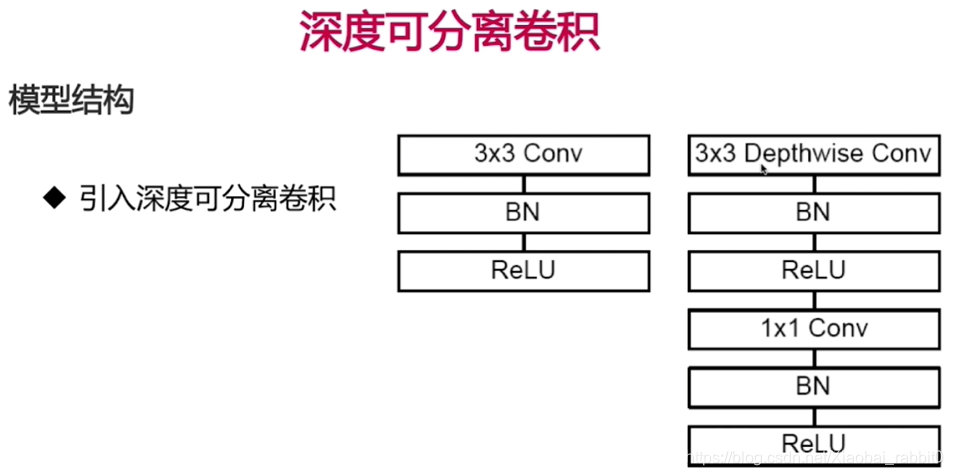
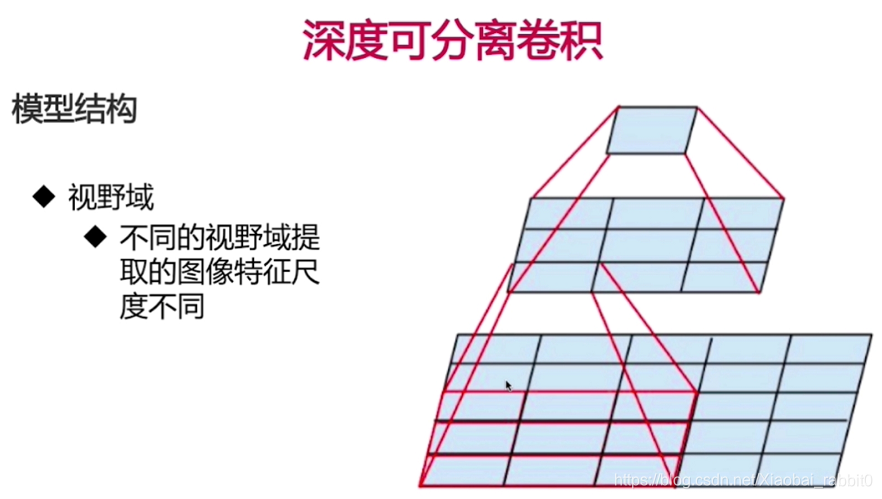

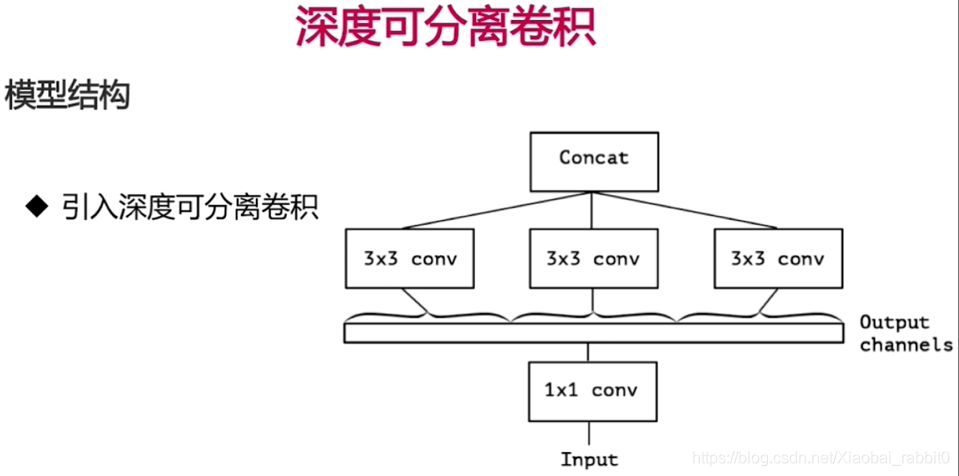

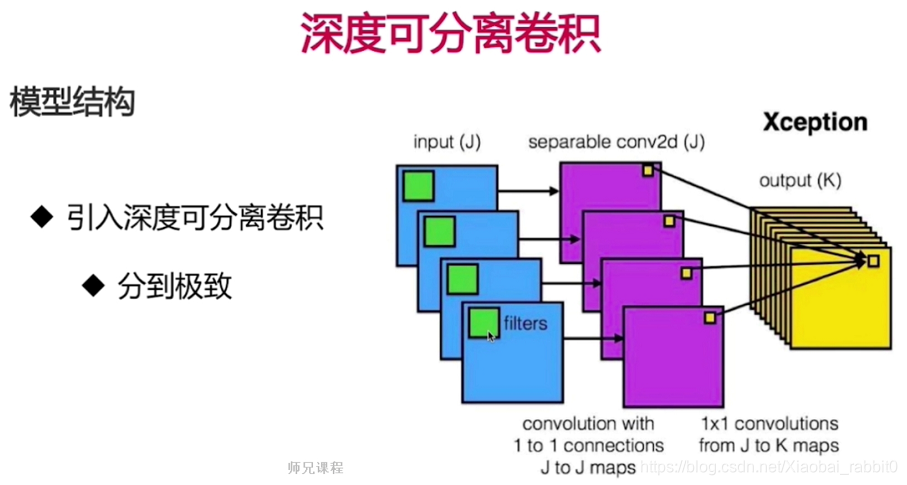
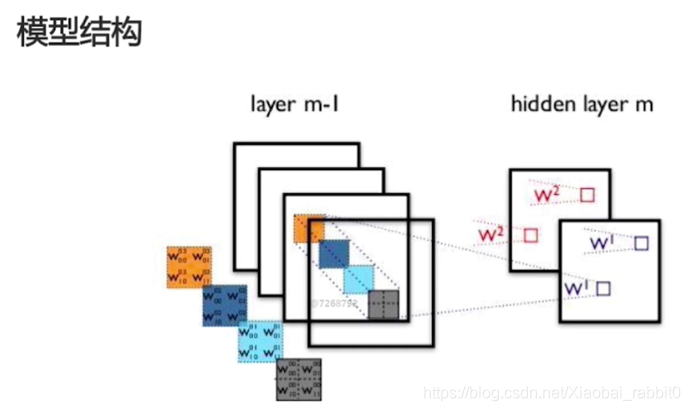


2.2.2、深度可分离卷积网络实战
修改建模部分代码
'''深度可分离卷积-神经网络Conv2D -> SeparableConv2D'''
model = keras.models.Sequential()
#定义第一个卷积层
model.add(keras.layers.Conv2D(filters = 32, #32个通道(32个卷积核)
kernel_size=3, #卷积核大小为3
padding='same', #大小不变
activation='relu', #加padding是否要输入和输出大小一样
input_shape=(28,28,1))) #输入图片大小 28*28*1
model.add(keras.layers.SeparableConv2D(filters = 32, #32个通道(32个卷积核)
kernel_size=3, #卷积核大小为3
padding='same', #加padding是否要输入和输出大小一样
activation='relu')) #不需要加input_shape
#池化层
model.add(keras.layers.MaxPool2D(pool_size=2)) #步长和pool_size相同
model.add(keras.layers.SeparableConv2D(filters = 64, #32个通道(32个卷积核)
kernel_size=3, #卷积核大小为3
padding='same', #大小不变
activation='relu')) #加padding是否要输入和输出大小一样
model.add(keras.layers.SeparableConv2D(filters = 64, #32个通道(32个卷积核)
kernel_size=3, #卷积核大小为3
padding='same', #加padding是否要输入和输出大小一样
activation='relu')) #不需要加input_shape
#池化层
model.add(keras.layers.MaxPool2D(pool_size=2)) #步长和pool_size相同
model.add(keras.layers.SeparableConv2D(filters = 128, #32个通道(32个卷积核)
kernel_size=3, #卷积核大小为3
padding='same', #大小不变
activation='relu')) #加padding是否要输入和输出大小一样
model.add(keras.layers.SeparableConv2D(filters = 128, #32个通道(32个卷积核)
kernel_size=3, #卷积核大小为3
padding='same', #加padding是否要输入和输出大小一样
activation='relu')) #不需要加input_shape
#池化层
model.add(keras.layers.MaxPool2D(pool_size=2)) #步长和pool_size相同
#连接全连接层之前,先做一个flatten
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128,activation='relu'))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss = "sparse_categorical_crossentropy", #如果y已经是向量了就用categorical_crossentropy",如果是数字就用sparse_
optimizer = "sgd",
metrics = ["accuracy"])
model.summary()
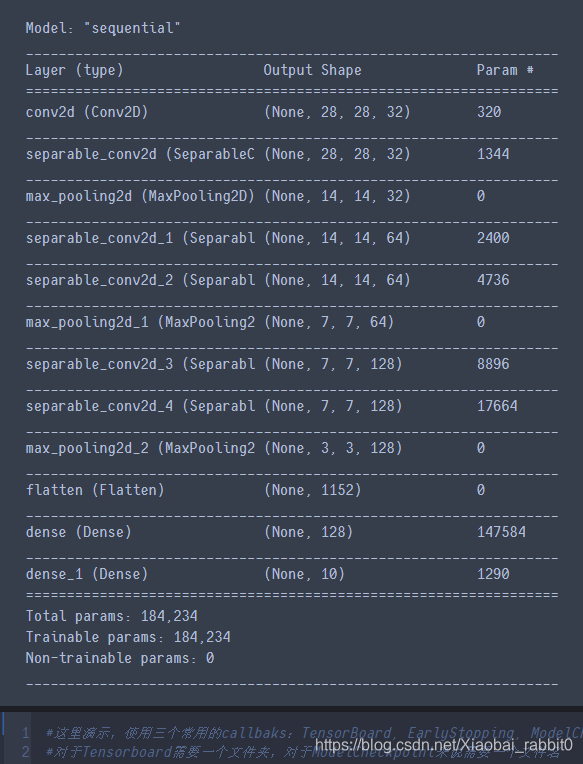
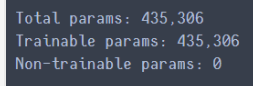
由上面可知cnn的网络参数为443306个参数
使用了深度可分离卷积网络参数变为184234
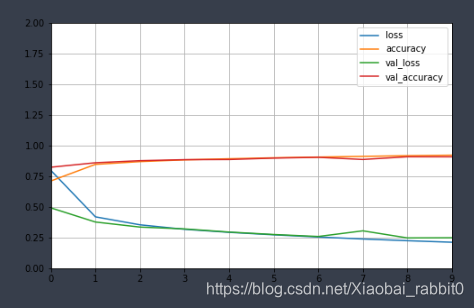
训练结果精度和训练曲线如下图所示:
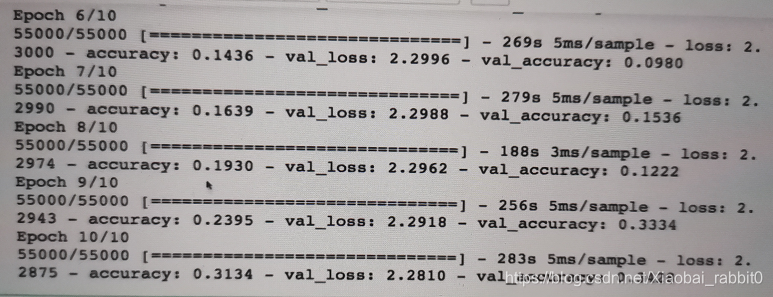
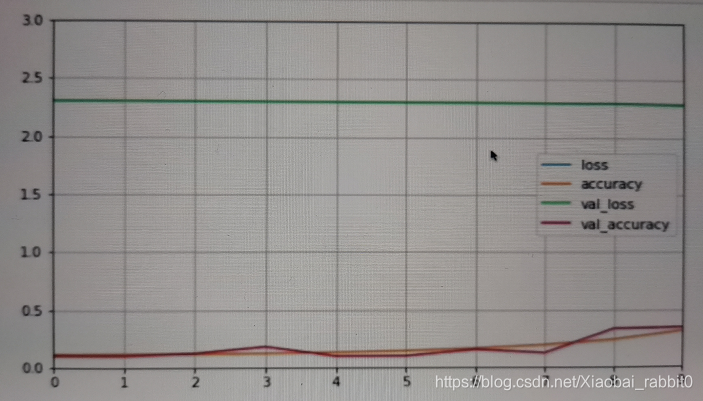
注:上图训练结果非常差,因为训练的轮数太少将epochs由10 -> 100效果会有明显提升,改为300更佳。
结论:
**优点:**训练参数可以大大减少
**缺点:**精度有所下降,训练的时间更长,迭代的轮数也应该变得更多轮。
由上图可以看出,训练的精度在第8-9步才有所的提升,训练曲线也很明显的展现出这个问题。


















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









