 使用TensorFlow实现一元线性回归
使用TensorFlow实现一元线性回归





 本文通过实例详细介绍了如何运用TensorFlow进行一元线性回归的实践操作,从构建模型到训练过程,展示了TensorFlow在解决简单回归问题上的应用。
本文通过实例详细介绍了如何运用TensorFlow进行一元线性回归的实践操作,从构建模型到训练过程,展示了TensorFlow在解决简单回归问题上的应用。
import tensorflow as tf
import numpy as np
#定义超参数
learning_rate=0.01
max_train_steps=1000
log_step=17
#输入数据
train_X=np.array([[3.3],[4.4],[5.5],[6.71],[6.93],[4.168],[9.779],[6.182],[7.59],[2.167],[7.042],[10.791],[5.313],[7.997],[5.654],[9.27],[3.1]],dtype=np.float32)
train_Y=np.array([[1.7],[2.76],[2.09],[3.19],[1.694],[1.573],[3.366],[2.596],[2.53],[1.221],[2.827],[3.465],[1.65],[2.904],[2.42],[2.94],[1.3]],dtype=np.float32)
total_samples=train_X.shape[0]
#构建模型
X=tf.placeholder(tf.float32,[None,1])
W=tf.Variable(tf.random_normal([1,1]),name="weight")
b=tf.Variable(tf.zeros([1]),name="bias")
Y=tf.matmul(X,W)+b
#定义损失函数
Y_=tf.placeholder(tf.float32,[None,1])
loss=tf.reduce_sum(tf.pow(Y-Y_,2))/(total_samples)
#创建优化器
optimizer=tf.train.GradientDescentOptimizer(learning_rate)
#定义单步训练操作
train_op=optimizer.minimize(loss)
#创建会话
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
#迭代训练
print("开始训练:")
for step in range(max_train_steps):
sess.run(train_op,feed_dict={X:train_X,Y_:train_Y})
if step % log_step == 0:
c=sess.run(loss,feed_dict={X:train_X,Y_:train_Y})
print("Step:%d,loss==%.4f,W==%.4f,b==%.4f"%(step,c,sess.run(W),sess.run(b)))
final_loss=sess.run(loss,feed_dict={X:train_X,Y_:train_Y})
weight,bias=sess.run([W,b])
print("Step:%d,loss==%.4f,W==%.4f,b==%.4f"%(max_train_steps,final_loss,sess.run(W),sess.run(b)))
print("线性模型是:Y==%.4f*X+%.4f"%(weight,bias))
运行结果:

…
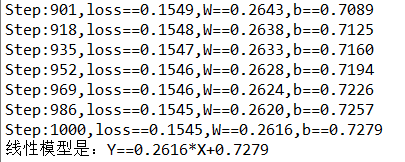

















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









