



在一些博文中发现一款很适合理工科学生学习日常的软件Simple Tex: ,
,
这款软件可以直接截图识别公式,在安装Math type插件后可直接在word中表示出公式,识别正确率相对较高。
方法如下:
1. 在官方网站下载并注册登录该软件。
2. 打开软件,点击截屏识别
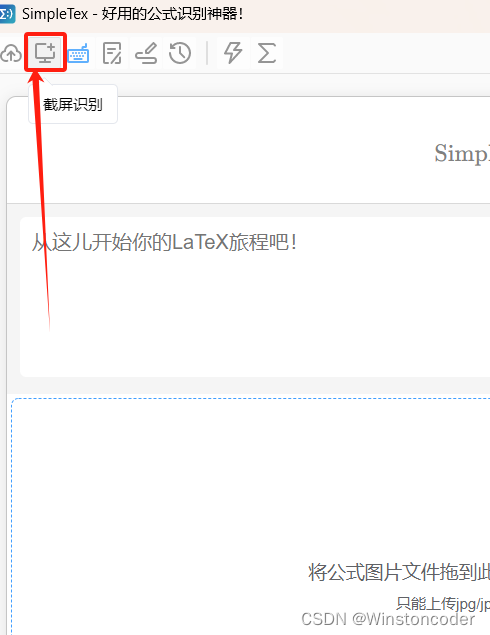
2. 粘贴图片并识别

3. 点击复制Latex
在word中点击mathtype并黏贴复制内容
直接得到公式:
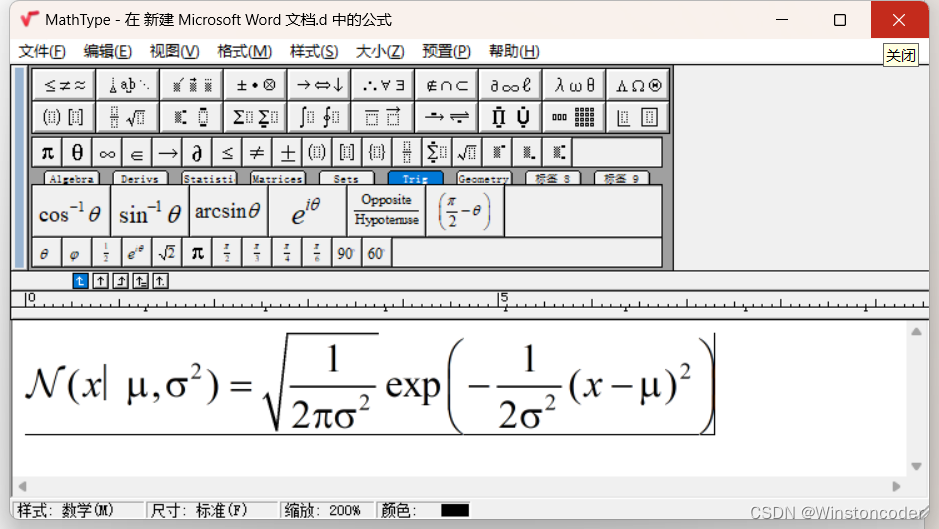
4. 完成
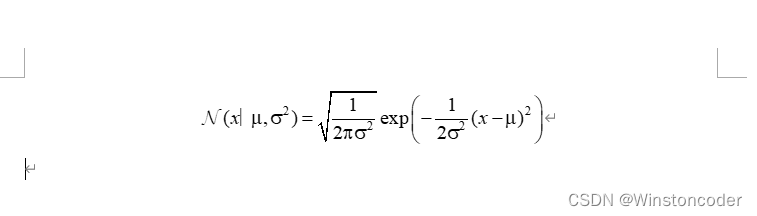
 本文介绍了一款名为SimpleTex的软件,专为理工科学生设计,能通过截图识别公式,并在安装Mathtype插件后无缝整合到Word文档中,提高公式输入效率。只需几步操作即可完成公式转换。
本文介绍了一款名为SimpleTex的软件,专为理工科学生设计,能通过截图识别公式,并在安装Mathtype插件后无缝整合到Word文档中,提高公式输入效率。只需几步操作即可完成公式转换。
在一些博文中发现一款很适合理工科学生学习日常的软件Simple Tex:,
这款软件可以直接截图识别公式,在安装Math type插件后可直接在word中表示出公式,识别正确率相对较高。
方法如下:
1. 在官方网站下载并注册登录该软件。
2. 打开软件,点击截屏识别
2. 粘贴图片并识别
3. 点击复制Latex
在word中点击mathtype并黏贴复制内容
直接得到公式:
4. 完成
 6522
4853
6522
4853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























