







前言
在之前我写了一篇博客:【detectron2 faster rcnn 训练自己的数据集】
这篇博客是使用自己训练的faster rcnn权重对课堂上的学生进行检测,然后这篇博客要做的就是把检测后的结果裁剪出来,如下图: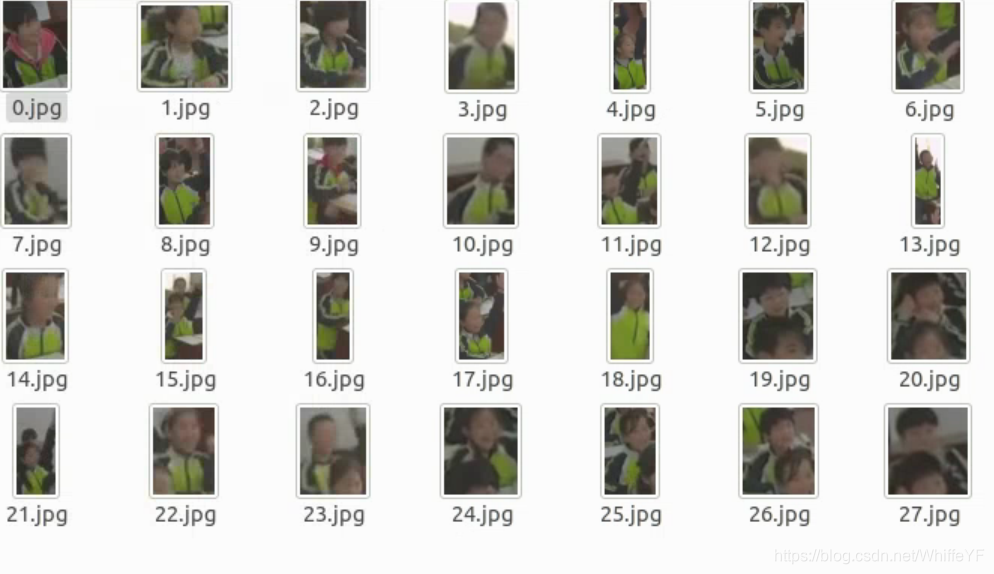
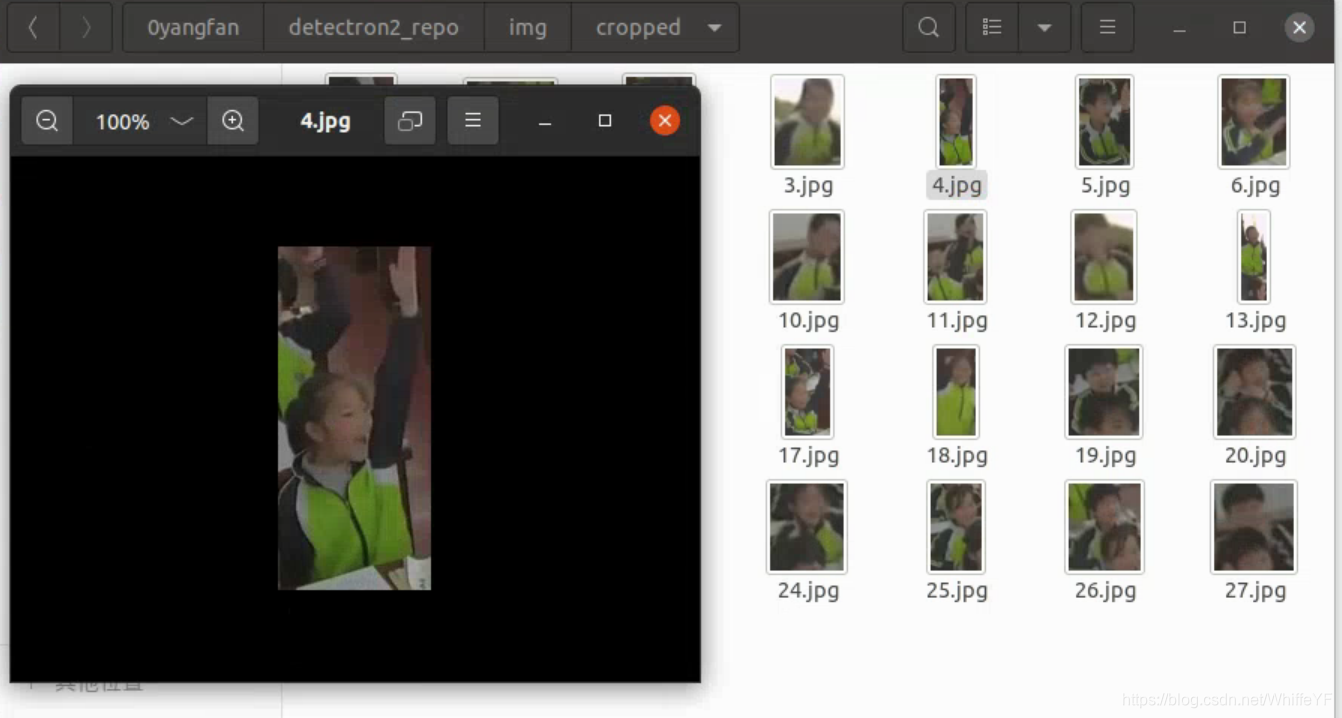
为什么要把这些人单独裁剪出来,原因很简单,要做人的ID匹配,在一个视频当中,比如15s的视频,每一秒取一帧,那么就是15张图片(我用ffmpeg裁出来好像又17张,这就奇怪了),这15张图片处理当中,一个比较重要的就是,确定每个人的ID,比如视频中的张三,从头到尾他的ID都应该是一样的。为了让系统自动给这些人打上ID的标签,那么我们需要把每一帧的图片里的每个人裁剪出来,让算法做匹配(当然,这一篇博客不会写如何匹配,之后的博客会写),匹配每一帧的人和上一帧的人的对应关系。
裁剪代码:
下面的这部分就是把faster rcnn的检测结果裁剪出来
# faster rcnn 检测出来bbox的坐标
bbox_xy_count = 0
for bbox_xy in outputs["instances"].pred_boxes.tensor:
x1 = int(bbox_xy.to("cpu").numpy()[0])
y1 = int(bbox_xy.to("cpu").numpy()[1])
x2 = int(bbox_xy.to("cpu").numpy()[2])
y2 = int(bbox_xy.to("cpu").numpy()[3])
cropped = im[y1:y2,x1:x2] # 裁剪坐标
cv2.imwrite("/home/lxn/0yangfan/detectron2_repo/img/cropped/" + str(bbox_xy_count) + ".jpg", cropped)
bbox_xy_count = bbox_xy_count + 1
下面的是完整代码(这里面的修改【detectron2 faster rcnn 训练自己的数据集】):
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
# import some common libraries
import numpy as np
import cv2
import random
import datetime
import time
import os
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog
from detectron2.data.datasets import register_coco_instances
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.engine import DefaultTrainer
from detectron2.config import get_cfg
from detectron2.utils.visualizer import ColorMode
def Train():
register_coco_instances("custom", {}, "../datasets/coco/annotations/instances_train2014.json", "../datasets/coco/train2014/")
custom_metadata = MetadataCatalog.get("custom")
dataset_dicts = DatasetCatalog.get("custom")
for d in random.sample(dataset_dicts, 3):
img = cv2.imread(d["file_name"])
visualizer = Visualizer(img[:, :, ::-1], metadata=custom_metadata, scale=1)
vis = visualizer.draw_dataset_dict(d)
cv2.imshow('Sample',vis.get_image()[:, :, ::-1])
cv2.waitKey()
cfg = get_cfg()
cfg.merge_from_file(
"../configs/COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml"
)
cfg.DATASETS.TRAIN = ("custom",)
cfg.DATASETS.TEST = ()
cfg.DATALOADER.NUM_WORKERS = 4
cfg.MODEL.WEIGHTS = 'model_final_faster.pkl'
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.02
cfg.SOLVER.MAX_ITER = (
100
)
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = (
128
)
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()
def Predict():
register_coco_instances("custom", {}, "../datasets/coco/annotations/instances_train2014.json", "datasets/coco/train2014")
custom_metadata = MetadataCatalog.get("custom")
DatasetCatalog.get("custom")
im = cv2.imread("class030_000002.jpg")
cfg = get_cfg()
cfg.merge_from_file("../configs/COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml")
cfg.DATASETS.TEST = ("custom", )
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth")
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = (
128
)
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
# faster rcnn 检测出来bbox的坐标
bbox_xy_count = 0
for bbox_xy in outputs["instances"].pred_boxes.tensor:
x1 = int(bbox_xy.to("cpu").numpy()[0])
y1 = int(bbox_xy.to("cpu").numpy()[1])
x2 = int(bbox_xy.to("cpu").numpy()[2])
y2 = int(bbox_xy.to("cpu").numpy()[3])
cropped = im[y1:y2,x1:x2] # 裁剪坐标
cv2.imwrite("/home/lxn/0yangfan/detectron2_repo/img/cropped/" + str(bbox_xy_count) + ".jpg", cropped)
bbox_xy_count = bbox_xy_count + 1
return 0
v = Visualizer(im[:, :, ::-1],
metadata=custom_metadata,
scale=1,
instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels
)
#print(outputs["instances"])
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2.imshow('Result',v.get_image()[:, :, ::-1])
cv2.waitKey()
if __name__ == "__main__":
#Train()
Predict()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











