










1. 网络工作流程
# 获取VOC数据使⽤
from detection.datasets import pascal_voc
# 绘图
import matplotlib.pyplot as plt
import numpy as np
# 模型构建
from detection.models.detectors import faster_rcnn
import tensorflow as tf
# 图像展示
import visualize1.1 数据加载
# 实例化voc数据集的类,获取送⼊⽹络中的⼀张图⽚
pascal = pascal_voc.pascal_voc("train")
# image:送⼊⽹络中的数据,imagemeta:图像的yuan'x
image,imagemeta,bbox,label = pascal[218] 图像展示
# 图像的均值和标准差
img_mean = (122.7717, 115.9465, 102.9801)
img_std = (1., 1., 1.)
# RGB图像
rgd_image= np.round(image+img_mean).astype(np.uint8)
# 获取原始图像
from detection.datasets.utils import get_original_image
ori_img = get_original_image(image[0],imagemeta[0],img_mean)
# 展示原图像和送⼊⽹络中图像
rgd_image= np.round(image+img_mean).astype(np.uint8)
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(10,8),dpi=100)
axes[0].imshow(ori_img.astype('uint8'))
axes[0].set_title("原图像")
axes[1].imshow(rgd_image[0])
axes[1].set_title("送⼊⽹络中的图像")
plt.show() 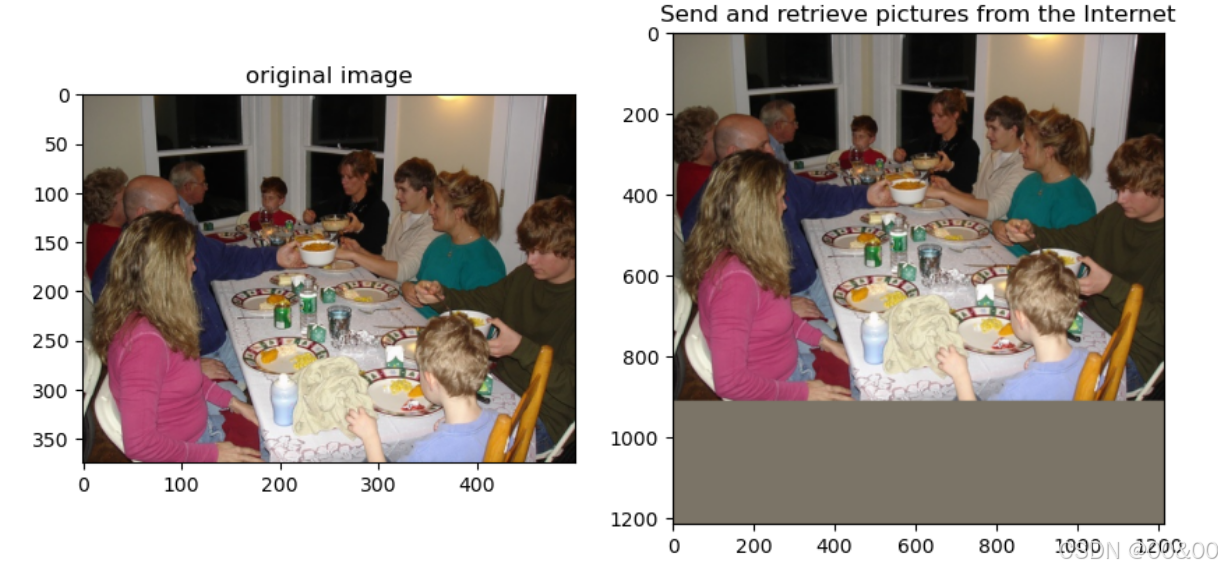
1.2 模型加载
# coco数据集的class,共80个类别:⼈,⾃⾏⻋,⽕⻋,。。。
classes = ['bg','person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra',
'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite',
'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork',
'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut',
'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase',
'scissors',
'teddy bear', 'hair drier', 'toothbrush']
# 实例化模型
model = faster_rcnn.FasterRCNN(num_classes=len(classes))
model((image,imagemeta,bbox,label),training=True)
# 加载训练好的weights
model.load_weights("weights/faster_rcnn.h5")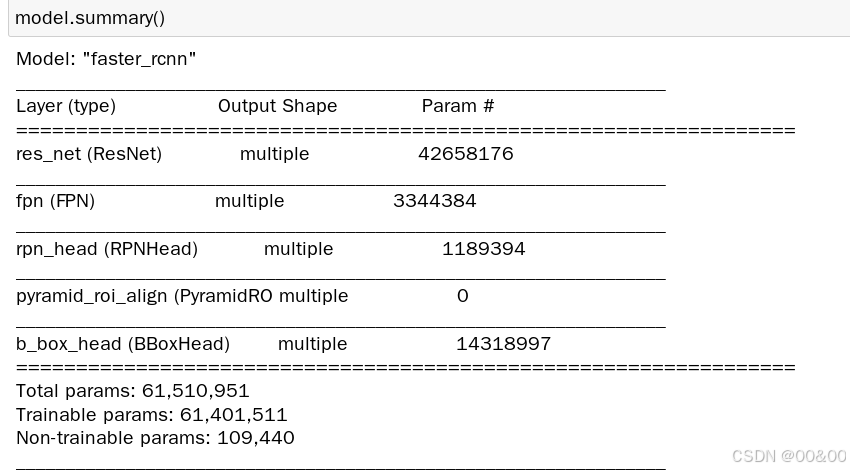
1.3 模型预测过程
1.3.1 RPN获取候选区域
# RPN获取候选区域:输⼊图像和对应的元信息,输出是候选的位置信息
proposals = model.simple_test_rpn(image[0],imagemeta[0]) # 绘制在图像上(将proposal绘制在图像上)
visualize.draw_boxes(rgd_image[0],boxes=proposals[:,:4]*1216)
plt.show() 
1.3.2 FastRCNN进⾏⽬标检测
# rcnn进⾏预测,得到的是原图像的检测结果:
# 输⼊:要检测的送⼊⽹络中的图像,图像的元信息,RPN产⽣的候选区域
# 输出:⽬标检测结果:检测框(相对于原图像),类别,置信度
res = model.simple_test_bboxes(image[0],imagemeta[0],proposals)# 将检测结果绘制在图像上
visualize.display_instances(ori_img,res['rois'],res['class_ids'],classes,res['scores'])
plt.show()  2.模型结构详解
2.模型结构详解
2.1 backbone
2.1.1 resnet特征提取的结果
# 使⽤backbone获取特征图
C2,C3,C4,C5 = model.backbone(image,training=False) 2.1.2 FPN特征融合的结果
# FPN⽹络融合:C2,C3,C4,C5是resnet提取的特征结果
P2,P3,P4,P5,P6 = model.neck([C2,C3,C4,C5],training=False) 2.2 RPN⽹络
2.2.1 anchors
# 产⽣anchor:输⼊图像元信息即可,输出anchor对应于原图的坐标值
anchors,valid_flags = model.rpn_head.generator.generate_pyramid_anchors(imagemeta)# 绘制在图像上(将anchor绘制在图像上)
visualize.draw_boxes(rgd_image[0],boxes=anchors[:10000,:4])
plt.show() 
2.2.3 RPN回归
# RPN⽹络的输⼊:FPN⽹络获取的特征图
rpn_feature_maps = [P2,P3,P4,P5,P6]
# RPN⽹络预测,返回:logits送⼊softmax之前的分数,包含⽬标的概率,对
rpn_class_logits,rpn_probs,rpn_deltas = model.rpn_head(rpn_feature_maps,training=False)# 获取分类结果中包含⽬标的概率值
rpn_probs_tmp = rpn_probs[0,:,1]
# 获取前100个较⾼的anchor
limit = 100
ix = tf.nn.top_k(rpn_probs_tmp,k=limit).indices
anchors_positive = tf.gather(anchors,ix).numpy()
# 获取对应的anchor绘制图像上,那这些anchor就有很⼤概率⽣成候选区域
visualize.draw_boxes(rgd_image[0],anchors_positive) 2.4 Proposal层
2.4 Proposal层
# 获取候选区域
proposals_list = model.rpn_head.get_proposals(rpn_probs,rpn_deltas,imagemeta)# 绘制在图像上(将proposal绘制在图像上)
visualize.draw_boxes(rgd_image[0],boxes=proposals_list[0].numpy()[:,:4]*1216)
plt.show() 
2.3 ROIPooling
# ROI Pooling层实现:输⼊是候选区域,特征图,图像的元信息
pool_region_list = model.roi_align((proposals_list,[P2,P3,P4,P5],imagemeta),training=False)2.4 ⽬标分类与回归
# RCNN⽹络的预测:输⼊是ROIPooling层的特征,输出:类别的score,类别的
rcnn_class_logits,rcnn_class_probs,rcnn_deltas_list = model.bbox_head(pool_region_list,training=False)# 获取预测结果:输⼊:rcnn返回的分类和回归结果,候选区域,图像元信息,
detection_list = model.bbox_head.get_bboxes(rcnn_class_probs,rcnn_deltas_list,proposals_list,imagemeta)# 绘制在图像上
visualize.draw_boxes(rgd_image[0],boxes=detection_list[0][:,:4])
plt.show() 
3 FasterRCNN的训练
3.1 RPN⽹络的训练
# 获取对应的⽬标值:输⼊:要设置正负样本的anchors,anchor在有效区域的
rpn_target_matchs,rpn_target_deltas = model.rpn_head.anchor_target.build_targets(anchors,valid_flags,bbox,label)
# 属于正样本的anchors,与GT交并⽐较⼤的anchor,⽬标值设为1
positive_anchors = tf.gather(anchors,tf.where(tf.equal(rpn_target_matchs,1))[:,1])
# 正样本的个数:⼀共使⽤29个属于正样本的anchor
# TensorShape([29, 4])
# 负样本
negtivate_anchors = tf.gather(anchors,tf.where(tf.equal(rpn_target_matchs,-1))[:,1])
# negtivate_anchors.shape
# TensorShape([227, 4])
# RPN⽹络的损失函数
# 输⼊:rpn的分类结果rpn_class_logits,rpn的回归结果,bbox标注框,
# 输出:分类损失和回归损失
rpn_class_loss, rpn_bbox_loss = model.rpn_head.loss(
rpn_class_logits, rpn_deltas, bbox, label,imagemeta)3.2 FastRCNN⽹络的训练
# fastRCNN的正负样本设置
# 输⼊:RPN⽹络⽣成的候选区域,bbox是标记框,label是⽬标类别
# 输出:参与训练的候选区域rois_list,候选区域分类的⽬标值rcnn_targe
rois_list, rcnn_target_matchs_list, rcnn_target_deltas_list=\
model.bbox_target.build_targets(
proposals_list,bbox, label, imagemeta)
# 获取正样本:
positive_proposal = tf.gather(rois_list[0], tf.where(
tf.not_equal(rcnn_target_matchs_list, 0))[:, 1])
# 显示
visualize.draw_boxes(rgd_image[0],positive_proposal.numpy()*1216)
plt.show() 
# 负样本
negtivate_proposal = tf.gather(rois_list[0], tf.where(
tf.equal(rcnn_target_matchs_list, 0))[:, 1])
# negtivate_proposal.shape
# TensorShape([192, 4])
# 显示
visualize.draw_boxes(rgd_image[0],negtivate_proposal.numpy()*1216)
plt.show() 
# 将参与⽹络训练的候选区域rois_list送⼊到ROIpooling层中进⾏维度固定
pooled_regions_list = model.roi_align(
(rois_list, rpn_feature_maps, imagemeta), training=True)
# 送⼊⽹络中进⾏预测,得到预测结果
rcnn_class_logits_list, rcnn_probs_list, rcnn_deltas_list = \
model.bbox_head(pooled_regions_list, training=True)
# 计算损失函数:分类和回归
# 输⼊:⽹络的预测结果和⽬标值
rcnn_class_loss, rcnn_bbox_loss = model.bbox_head.loss(
rcnn_class_logits_list, rcnn_deltas_list,
rcnn_target_matchs_list, rcnn_target_deltas_list)3.3 端到端训练
# 数据集加载
from detection.datasets import pascal_voc
# 深度学习框架
import tensorflow as tf
import numpy as np
# 绘图
from matplotlib import pyplot as plt
# 要训练的模型
from detection.models.detectors import faster_rcnn
# 加载数据集
train_dataset = pascal_voc.pascal_voc('train')
# 数据的类别: train_dataset.classes
['background',
'person',
'aeroplane',
'bicycle',
'bird',
'boat',
'bottle',
'bus',
'car',
'cat',
'chair',
'cow',
'diningtable',
'dog',
'horse',
'motorbike',
'pottedplant',
'sheep',
'sofa',
'train',
'tvmonitor']
# 数据类别数量:21
num_classes = len(train_dataset.classes)
# 指定数据集中类别个数
model = faster_rcnn.FasterRCNN(num_classes=num_classes)
# 优化器
optimizer = tf.keras.optimizers.SGD(1e-3,momentum=0.1,nesterov=True)
# 损失函数变化列表
loss_his = []
# 使用tf.gradientTape进行训练
# epoch
for epoch in range(2):
# 获取索引
indices = np.arange(train_dataset.num_gtlabels)
# 打乱
np.random.shuffle(indices)
# 迭代次数
iter = np.round(train_dataset.num_gtlabels/train_dataset.batch_size).astype(np.uint8)
for idx in range(iter):
# 获取batch数据索引
idx = indices[idx]
# 获取batch_size
batch_image,batch_metas,batch_bboxes,batch_label = train_dataset[idx]
# 梯度下降
with tf.GradientTape() as tape:
# 计算损失函数
rpn_class_loss,rpn_bbox_loss,rcnn_class_loss,rcnn_bbox_loss = model((batch_image,batch_metas,batch_bboxes,batch_label),training=True)
# 总损失
loss = rpn_class_loss+rpn_bbox_loss+rcnn_class_loss+rcnn_bbox_loss
# 计算梯度
grads = tape.gradient(loss,model.trainable_variables)
# 更新参数值
optimizer.apply_gradients(zip(grads,model.trainable_variables))
print("epoch:%d,batch:%d,loss:%f"%(epoch+1,idx,loss))
loss_his.append(loss)
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









