






代码来源:
deep-learning-for-image-processing
部分注释中写的参数以mobilenet为Backbone,Pascal VOC为数据集作举例
注释以特征图size=(34,25)为例,不同大小的图片生成的特征图尺寸不一定相同
模型结构
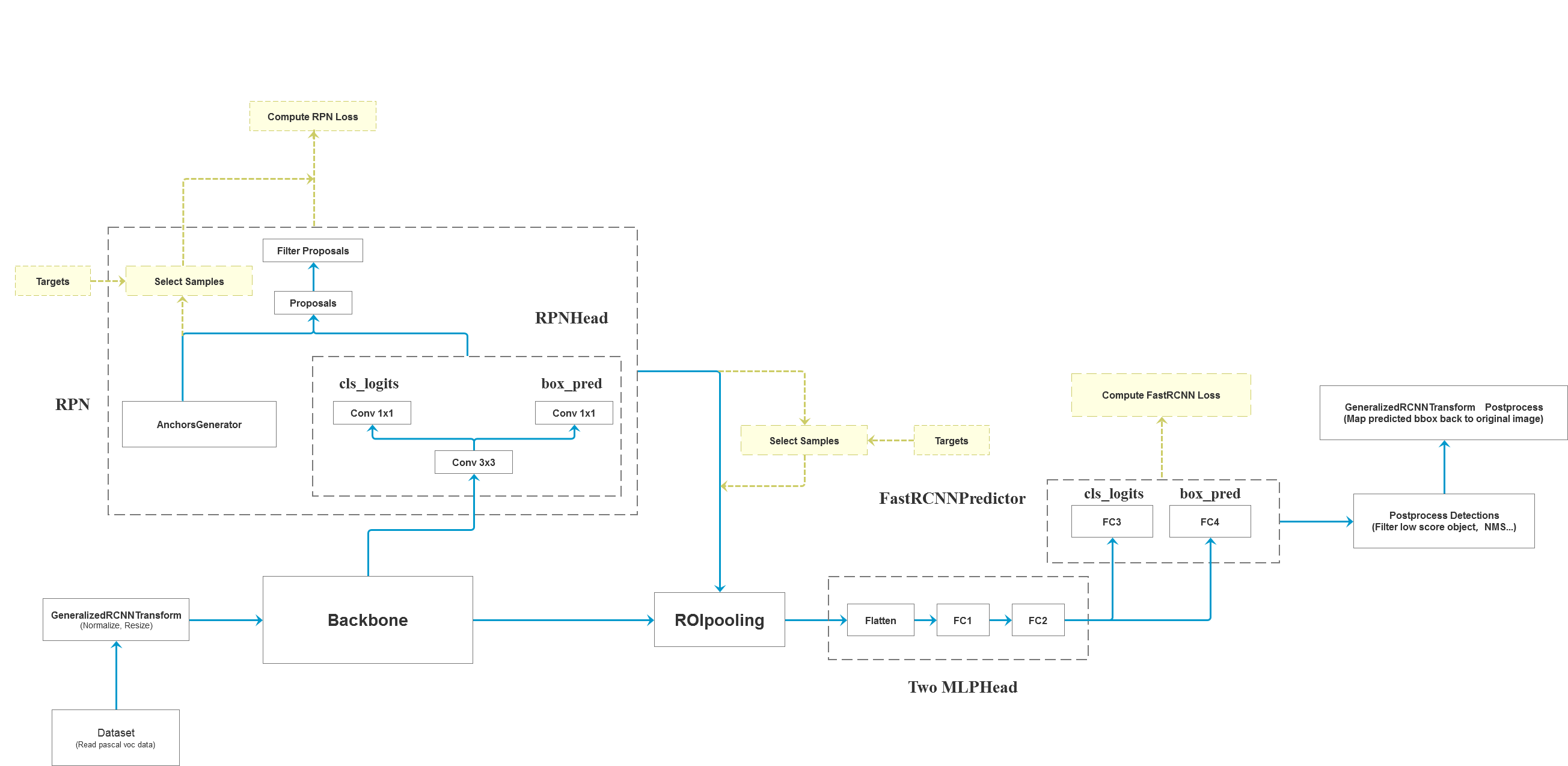
RPN层
RPN层基于BackBone处理生成的特征图生成候选框
rpn_function.py:
--class RPNHead(nn.Module):通过滑动窗口计算预测目标概率与bbox regression参数
--class AnchorsGenerator(nn.Module):生成候选框
----def set_cell_anchors(self, dtype, device):返回基础候选框列表的列表
----def generate_anchors(self, scales, aspect_ratios, dtype=torch.float32, device=torch.device("cpu")):生成基础候选框列表
----def cached_grid_anchors(self, grid_sizes, strides):调用self.grid_anchors将原图对应候选框加入缓存,或者直接从缓存中提取候选框
----def grid_anchors(self, grid_sizes, strides):通过特征图基础候选框和特征图尺寸、映射比例生成原图候选框
----def forward(self, image_list, feature_maps):应用以上函数返回一个batch中每张图片所有候选框的列表
--class RegionProposalNetwork(torch.nn.Module):
class RPN Head
class RPNHead(nn.Module):
def __init__(self, in_channels, num_anchors):
super(RPNHead, self).__init__()
# 3x3 滑动窗口
self.conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1)
# 计算预测的目标分数(这里的目标只是指前景或者背景)
self.cls_logits = nn.Conv2d(in_channels, num_anchors, kernel_size=1, stride=1)
# 计算预测的目标bbox regression参数
self.bbox_pred = nn.Conv2d(in_channels, num_anchors * 4, kernel_size=1, stride=1)
# 初始化
for layer in self.children():
if isinstance(layer, nn.Conv2d):
torch.nn.init.normal_(layer.weight, std=0.01)
torch.nn.init.constant_(layer.bias, 0)
def forward(self, x):
# type: (List[Tensor]) -> Tuple[List[Tensor], List[Tensor]]
logits = []
bbox_reg = []
for i, feature in enumerate(x):
t = F.relu(self.conv(feature))
logits.append(self.cls_logits(t))
bbox_reg.append(self.bbox_pred(t))
return logits, bbox_reg
传入的参数是输入通道和输出通道数,首先特征图通过3x3卷积,再分别进行两个1x1卷积,其中一个输出通道数为num_anchors的一倍,代表每个特征图像素的候选框是否包含物体的概率,另一个输出通道数为num_anchors的四倍,代表每个特征图像素的候选框的四个位置的调整系数。
因为如果Backbone为resnet50会使用FPN金字塔结构,所以传入参数为List[Tensor]的形式,即传入多张特征图。
class AnchorsGenerator
def __ init __:
def __init__(self, sizes=(128, 256, 512), aspect_ratios=(0.5, 1.0, 2.0)):
super(AnchorsGenerator, self).__init__()
# anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),), aspect_ratios=((0.5, 1.0, 2.0),))
# 因此不会进入这两个判断
if not isinstance(sizes[0], (list, tuple)):
# TODO change this
sizes = tuple((s,) for s in sizes)
if not isinstance(aspect_ratios[0], (list, tuple)):
aspect_ratios = (aspect_ratios,) * len(sizes)
# 长度都为1
assert len(sizes) == len(aspect_ratios)
self.sizes = sizes
self.aspect_ratios = aspect_ratios
self.cell_anchors = None
self._cache = {}
传入的参数分别为anchor的基础大小和anchor的变换比例,在这里anchor的种类一共有5x3=15种
def forward:
def forward(self, image_list, feature_maps):
# type: (ImageList, List[Tensor]) -> List[Tensor]
# 获取每个预测特征层的尺寸(height, width)
# grid_sizes == [torch.Size([25, 34])],mobilenet只有一个特征图
grid_sizes = list([feature_map.shape[-2:] for feature_map in feature_maps])
# 获取输入图像的height和width
image_size = image_list.tensors.shape[-2:]
# 获取变量类型和设备类型
dtype, device = feature_maps[0].dtype, feature_maps[0].device
# one step in feature map equate n pixel stride in origin image
# 计算特征层上的一步等于原始图像上的步长
# strides == [[tensor(32, device='cuda:0'), tensor(32, device='cuda:0')]],看来长宽缩放比都是32
strides = [[torch.tensor(image_size[0] // g[0], dtype=torch.int64, device=device),
torch.tensor(image_size[1] // g[1], dtype=torch.int64, device=device)] for g in grid_sizes]
# 根据提供的sizes和aspect_ratios生成anchors模板
self.set_cell_anchors(dtype, device)
# 计算/读取所有anchors的坐标信息(这里的anchors信息是映射到原图上的所有anchors信息,不是anchors模板)
# 得到的是一个list列表,对应每张预测特征图映射回原图的anchors坐标信息,shape为[12750, 4]的那个
anchors_over_all_feature_maps = self.cached_grid_anchors(grid_sizes, strides)
anchors = torch.jit.annotate(List[List[torch.Tensor]], [])
# 遍历一个batch中的每张图像,anchors的元素都一样的,假如batch_size=4,相当于复制4个anchors_over_all_feature_maps组成一个anchors
for i, (image_height, image_width) in enumerate(image_list.image_sizes):
anchors_in_image = []
# 遍历每张预测特征图映射回原图的anchors坐标信息
for anchors_per_feature_map in anchors_over_all_feature_maps:
anchors_in_image.append(anchors_per_feature_map)
anchors.append(anchors_in_image)
# 将每一张图像的所有预测特征层的anchors坐标信息拼接在一起
# anchors是个list,每个元素为一张图像的所有anchors信息,拼接获得tensor(把list变成anchor)
anchors = [torch.cat(anchors_per_image) for anchors_per_image in anchors]
# Clear the cache in case that memory leaks.
self._cache.clear()
return anchors
- grid_sizes,image_size:特征图的四个维度分别为NCHW,因此通过feature_map.shape[-2:]获得特征图尺寸
- strides:为特征图的像素映射原图的比例,用于后续候选框的映射,通过原图高宽除以特征图高宽获得
- self.set_cell_anchors:
- def set_cell_anchors:
将sizes和aspect_ratios等传入self.generate_anchors()函数中获得anchor的模版列表,赋给属性self.cell_anchorsdef set_cell_anchors(self, dtype, device): # type: (torch.dtype, torch.device) -> None if self.cell_anchors is not None: cell_anchors = self.cell_anchors assert cell_anchors is not None # suppose that all anchors have the same device # which is a valid assumption in the current state of the codebase if cell_anchors[0].device == device: return # 根据提供的sizes和aspect_ratios生成anchors模板 anchors模板都是以(0, 0)为中心的anchor zip(self.sizes, # self.aspect_ratios):这里其实只传入了sizes=(32, 64, 128, 256, 512)和aspect_ratios=(0.5, 1.0, 2.0),因为他们长度为1 cell_anchors = [ self.generate_anchors(sizes, aspect_ratios, dtype, device) for sizes, aspect_ratios in zip(self.sizes, self.aspect_ratios) ] self.cell_anchors = cell_anchors
2. def generate_anchors:def generate_anchors(self, scales, aspect_ratios, dtype=torch.float32, device=torch.device("cpu")): # type: (List[int], List[float], torch.dtype, torch.device) -> Tensor """ compute anchor sizes Arguments: scales: sqrt(anchor_area) aspect_ratios: h/w ratios dtype: float32 device: cpu/gpu """ # scales == tensor([ 32, 64, 128, 256, 512]) scales = torch.as_tensor(scales, dtype=dtype, device=device) # aspect_ratios == tensor([0.5000, 1.0000, 2.0000]) aspect_ratios = torch.as_tensor(aspect_ratios, dtype=dtype, device=device) # h_ratios == tensor([0.7071, 1.0000, 1.4142]) h_ratios = torch.sqrt(aspect_ratios) # w_ratios == tensor([1.4142, 1.0000, 0.7071]) w_ratios = 1.0 / h_ratios # [r1, r2, r3]' * [s1, s2, s3] # number of elements is len(ratios)*len(scales) # w_ratios[:, None].shape == torch.Size([1, 3]), scales[None,:].shape == torch.Size([5, 1]) ws = (w_ratios[:, None] * scales[None, :]).view(-1) hs = (h_ratios[:, None] * scales[None, :]).view(-1) # left-top, right-bottom coordinate relative to anchor center(0, 0) # 生成的anchors模板都是以(0, 0)为中心的, shape [len(ratios)*len(scales), 4] # shape为torch.Size([15, 4]),以anchor的中心点为原点 base_anchors = torch.stack([-ws, -hs, ws, hs], dim=1) / 2 return base_anchors.round() # round 四舍五入- scales:anchor的基础尺寸,转变为Tensor变量
- aspect_ratios:anchor的变换比例,转变为Tensor变量
- h_ratios:anchor高的变化系数,为aspect_ratios开方
- w_ratios:anchor宽的变化系数,为h_ratios的倒数(anchor面积不变)
- ws/hs:通过在w_ratios/h_ratios后加维度和scales前加维度,两者相乘触发广播机制,获得5x3的变化后的宽/高具体值,一行里为一种scales的3种变换,一列里为5种尺寸的anchor。通过view(-1)展平
- base_anchor:torch.stack()参数dim=1,按列拼接,以anchor的形心为原点,获得左上角和右下角的坐标[-ws/2,-hs/2,ws/2,hs/2]
- 四舍五入后返回shape为[15,4]的每行为一种anchor的左上右下点坐标的矩阵
- anchors_over_all_feature_maps:
- def cached_grid_anchors:
def cached_grid_anchors(self, grid_sizes, strides): # type: (List[List[int]], List[List[Tensor]]) -> List[Tensor] """将计算得到的所有anchors信息进行缓存""" key = str(grid_sizes) + str(strides) # self._cache是字典类型 if key in self._cache: return self._cache[key] anchors = self.grid_anchors(grid_sizes, strides) self._cache[key] = anchors return anchors- def grid_anchors:
def grid_anchors(self, grid_sizes, strides): # type: (List[List[int]], List[List[Tensor]]) -> List[Tensor] """ anchors position in grid coordinate axis map into origin image 计算预测特征图对应原始图像上的所有anchors的坐标 Args: grid_sizes: 预测特征矩阵的height和width strides: 预测特征矩阵上一步对应原始图像上的步距 """ anchors = [] # cell_anchors为shape为[15,4]的15个预选框的坐标信息(左上坐标和右下坐标) cell_anchors = self.cell_anchors assert cell_anchors is not None # 遍历每个预测特征层的grid_size,strides和cell_anchors # grid_sizes, strides, cell_anchors都做list处理了 # size == [torch.size(25,34)] # stride == [[tensor(32, device='cuda:0'), tensor(32, device='cuda:0')]] # base_anchors.shape == tensor(15,4) for size, stride, base_anchors in zip(grid_sizes, strides, cell_anchors): # grid_height == 25 grid_width == 34 grid_height, grid_width = size # stride_height == tensor(32) stride_width == tensor(32) stride_height, stride_width = stride device = base_anchors.device # For output anchor, compute [x_center, y_center, x_center, y_center] # shape: [grid_width] 对应原图上的x坐标(列) # tensor([ 0, 32, 64, 96, 128, 160, 192, 224, 256, 288, 320, 352, # 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, # 768, 800, 832, 864, 896, 928, 960, 992, 1024, 1056]),tensor(34) shifts_x = torch.arange(0, grid_width, dtype=torch.float32, device=device) * stride_width # shape: [grid_height] 对应原图上的y坐标(行) # tensor([ 0, 32, 64, 96, 128, 160, 192, 224, 256, 288, 320, 352, 384, 416, # 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768]),tensor(25) shifts_y = torch.arange(0, grid_height, dtype=torch.float32, device=device) * stride_height # 计算预测特征矩阵上每个点对应原图上的坐标(anchors模板的坐标偏移量) # torch.meshgrid函数分别传入行坐标和列坐标,生成网格行坐标矩阵和网格列坐标矩阵 # shifts_y按列复制shifts_x的大小(34),shifts_x按行复制shifts_y的大小(25) # shape: [grid_height, grid_width]即tensor(25,34) shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x) shift_x = shift_x.reshape(-1) shift_y = shift_y.reshape(-1) # 计算anchors坐标(xmin, ymin, xmax, ymax)在原图上的坐标偏移量 # shape: [grid_width*grid_height, 4]即tensor(850,4) # tensor([[0,0,0,0],[32,0,32,0],...,[1024,768,1024,768],[1056,768,1056,768]]) shifts = torch.stack([shift_x, shift_y, shift_x, shift_y], dim=1) # For every (base anchor, output anchor) pair, # offset each zero-centered base anchor by the center of the output anchor. # 将anchors模板与原图上的坐标偏移量相加得到原图上所有anchors的坐标信息(shape不同时会使用广播机制) # shifts.view(-1, 1, 4).shape == tensor(850,1,4) # base_anchors.view(1, -1, 4).shape == tensor(1,15,4) # shifts_anchor.shape == tensor(850,15,4),850个映射点的15个anchor的左上和右下的坐标 shifts_anchor = shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4) # shape为tensor(12750,4),生成了12k多个anchors anchors.append(shifts_anchor.reshape(-1, 4)) return anchors # List[Tensor(all_num_anchors, 4)]- shifts_x :通过grid_width * stride_width并通过torch.arrange()生成序列获得特征图像素对应的原图区域的左上x坐标;同理获得
- shifts_y:同上获得对应原图的y坐标
- shift_y/shift_x:torch.meshgrid()生成网络,分别为shifts_y/shifts_x按特征图列/行大小复制,他们的shape都为(25,34),之后进行展平处理
- shifts:shift_y和shift_x按列拼接,一行中为anchor之后需要平移的四个坐距离,一列的数量即为对应原图区域的数量(或者说特征图像素的个数)25*34=850,每一列是按照按照从左到右、从上到下的顺序,从左上到右下的区域。该矩阵shape为(850,4)
- shifts_anchor:先分别在shifts和base_anchors的前后增加维度,之后相加触发广播机制,获得shape为(850,15,4)的包含每个区域的15个候选框的左上右下坐标信息的矩阵。之后将前两个维度合并,获得shape为(12750,4)的所有原始图像的所有anchor的矩阵
- anchors:定义anchors为两层List嵌套的列表,元素为Tensor
- anchors_in_image:遍历一个batch中所有图像,复制anchors_over_all_feature_maps后添加至anchors中
- 将anchor的list元素通过torch.cat变为tensor变量,加入batch_size=4,则为一个长度为4,元素shape为(12750,4)的列表。
以上内容对应了Faster-RCNN结构的这一部分:

class RegionProposalNetwork:
def init:
def __init__(self, anchor_generator, head,
fg_iou_thresh, bg_iou_thresh,
batch_size_per_image, positive_fraction,
pre_nms_top_n, post_nms_top_n, nms_thresh, score_thresh=0.0):
super(RegionProposalNetwork, self).__init__()
# 注册前两个类,分别用作生成基础预选框和得到分类与box分数
self.anchor_generator = anchor_generator
self.head = head
self.box_coder = det_utils.BoxCoder(weights=(1.0, 1.0, 1.0, 1.0))
# use during training
# 计算anchors与真实bbox的iou
self.box_similarity = box_ops.box_iou
self.proposal_matcher = det_utils.Matcher(
fg_iou_thresh, # 当iou大于fg_iou_thresh(0.7)时视为正样本
bg_iou_thresh, # 当iou小于bg_iou_thresh(0.3)时视为负样本
allow_low_quality_matches=True
)
# 每张图抽选的的anchor数量,作为正样本的anchor的比例
self.fg_bg_sampler = det_utils.BalancedPositiveNegativeSampler(
batch_size_per_image, positive_fraction # 256, 0.5
)
# use during testing
self._pre_nms_top_n = pre_nms_top_n # nms处理之前保留的目标个数
self._post_nms_top_n = post_nms_top_n # nms处理之后保留的目标个数
self.nms_thresh = nms_thresh # nms指定阈值
self.score_thresh = score_thresh
self.min_size = 1.
传入参数说明:
- anchor_generator:用于生成基础候选框,数据为一个列表,列表元素为一个batch中一张图片的所有候选框的坐标信息。
- head:用于对特征图进行并列卷积分别获得每个候选框的前景概率和四个坐标参数
- fg_iou_thresh/bg_iou_thresh:如果anchor和gtbox的重叠比例大于fg_iou_thresh设为正样本,小于bg_iou_thresh设为负样本
- batch_size_per_image:rpn在计算损失时采用的正负样本的总个数
- positive_fraction:计算损失时正样本占全部样本的比例
- pre_nms_top_n:nms处理之前针对每个特征层保留的目标个数
- post_nms_top_n:nms处理之后剩余的目标个数(rpn输出的目标个数)
- nms_thresh:nms处理时指定的阈值
其他参数:
- self.box_coder:
- self.box_similarity:可以用来计算传入两个box的IOU值
def forword:
def forward(self,
images, # type: ImageList
features, # type: Dict[str, Tensor]
targets=None # type: Optional[List[Dict[str, Tensor]]]
):
# type: (...) -> Tuple[List[Tensor], Dict[str, Tensor]]
"""
Arguments:
images (ImageList): images for which we want to compute the predictions
features (Dict[Tensor]): features computed from the images that are
used for computing the predictions. Each tensor in the list
correspond to different feature levels
targets (List[Dict[Tensor]): ground-truth boxes present in the image (optional).
If provided, each element in the dict should contain a field `boxes`,
with the locations of the ground-truth boxes.
Returns:
boxes (List[Tensor]): the predicted boxes from the RPN, one Tensor per
image.
losses (Dict[Tensor]): the losses for the model during training. During
testing, it is an empty dict.
"""
# RPN uses all feature maps that are available
# features是所有预测特征层组成的OrderedDict类型变量,对于mobilenet只有一个特征层
features = list(features.values())
# 计算每个预测特征层上的预测目标概率和bboxes regression参数
# objectness和pred_bbox_deltas都是list
# shape分别为(4,15,25,34)和(4,60,25,34),分别代表batchsize、每个特征图像素的anchor的前景概率/边界框回归参数、特征图的高、特征图的宽
objectness, pred_bbox_deltas = self.head(features)
# 生成一个batch的原始图像的所有anchors信息,list(tensor)元素个数等于batch_size
anchors = self.anchor_generator(images, features)
# batch_size = 4
num_images = len(anchors)
# numel() Returns the total number of elements in the input tensor.
# 计算每个预测特征层上的对应的anchors数量
# o[0]的shape的列表,因为只有一个特征层,所以只有一个元素,[15,25,34]
num_anchors_per_level_shape_tensors = [o[0].shape for o in objectness]
# 一张特征图的anchor的总数,和anchors变量的一张图的anchor数量相同 15*25*34=12750
num_anchors_per_level = [s[0] * s[1] * s[2] for s in num_anchors_per_level_shape_tensors]
# 调整内部tensor格式以及shape
objectness, pred_bbox_deltas = concat_box_prediction_layers(objectness,
pred_bbox_deltas)
# apply pred_bbox_deltas to anchors to obtain the decoded proposals
# note that we detach the deltas because Faster R-CNN do not backprop through
# the proposals
# 将预测的bbox regression参数应用到anchors上得到最终预测bbox坐标
proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors)
proposals = proposals.view(num_images, -1, 4)
# 筛除小boxes框,nms处理,根据预测概率获取前post_nms_top_n个目标
boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)
losses = {}
if self.training:
assert targets is not None
# 计算每个anchors最匹配的gt,并将anchors进行分类,前景,背景以及废弃的anchors
labels, matched_gt_boxes = self.assign_targets_to_anchors(anchors, targets)
# 结合anchors以及对应的gt,计算regression参数
regression_targets = self.box_coder.encode(matched_gt_boxes, anchors)
loss_objectness, loss_rpn_box_reg = self.compute_loss(
objectness, pred_bbox_deltas, labels, regression_targets
)
losses = {
"loss_objectness": loss_objectness,
"loss_rpn_box_reg": loss_rpn_box_reg
}
return boxes, losses
传入一个batch的图片和特征图
- objectness, pred_bbox_deltas:分别获得经过rpn head获得的anchors的前景概率和坐标调整参数。
- num_anchors_per_level:为一张图的anchor的总数,和anchors这个list变量的长度相同。
- objectness, pred_bbox_deltas经过concat_box_prediction_layers函数的调整,shape变为[4len(anchors),1]和[4len(anchors),4]
- proposals:通过self.box_coder.decode方法获得最终一个batch中所有图片的调整后bbox坐标信息:
def decode(self, rel_codes, boxes):
# type: (Tensor, List[Tensor]) -> Tensor
"""
Args:
rel_codes: bbox regression parameters
boxes: anchors/proposals
boxes对应anchors,rel_codes对应边界框回归参数
Returns:
"""
assert isinstance(boxes, (list, tuple))
assert isinstance(rel_codes, torch.Tensor)
# boxes_per_image = [15*25*34=12750, 12750, 12750, 12750]
boxes_per_image = [b.size(0) for b in boxes]
# 把一个batch所有图像的框拼接,concat_boxes.size=[12750*4,4]
concat_boxes = torch.cat(boxes, dim=0)
# 脱裤子放屁
box_sum = 0
for val in boxes_per_image:
box_sum += val
# 将预测的bbox回归参数应用到对应anchors上得到预测bbox的坐标
pred_boxes = self.decode_single(
rel_codes, concat_boxes
)
# 防止pred_boxes为空时导致reshape报错
if box_sum > 0:
pred_boxes = pred_boxes.reshape(box_sum, -1, 4)
return pred_boxes
self.decode_single:
def decode_single(self, rel_codes, boxes):
"""
From a set of original boxes and encoded relative box offsets,
get the decoded boxes.
Arguments:
rel_codes (Tensor): encoded boxes (bbox regression parameters)
boxes (Tensor): reference boxes (anchors/proposals)
"""
# 将boxes转化相同的数据类型
boxes = boxes.to(rel_codes.dtype)
# xmin, ymin, xmax, ymax
widths = boxes[:, 2] - boxes[:, 0] # anchor/proposal宽度
heights = boxes[:, 3] - boxes[:, 1] # anchor/proposal高度
ctr_x = boxes[:, 0] + 0.5 * widths # anchor/proposal中心x坐标
ctr_y = boxes[:, 1] + 0.5 * heights # anchor/proposal中心y坐标
wx, wy, ww, wh = self.weights # RPN中为[1,1,1,1], fastrcnn中为[10,10,5,5]
dx = rel_codes[:, 0::4] / wx # 预测anchors/proposals的中心坐标x回归参数
dy = rel_codes[:, 1::4] / wy # 预测anchors/proposals的中心坐标y回归参数
dw = rel_codes[:, 2::4] / ww # 预测anchors/proposals的宽度回归参数
dh = rel_codes[:, 3::4] / wh # 预测anchors/proposals的高度回归参数
# limit max value, prevent sending too large values into torch.exp()
# self.bbox_xform_clip=math.log(1000. / 16) 4.135
dw = torch.clamp(dw, max=self.bbox_xform_clip)
dh = torch.clamp(dh, max=self.bbox_xform_clip)
# 应用偏移量得到框的中心坐标、宽、高
pred_ctr_x = dx * widths[:, None] + ctr_x[:, None]
pred_ctr_y = dy * heights[:, None] + ctr_y[:, None]
pred_w = torch.exp(dw) * widths[:, None]
pred_h = torch.exp(dh) * heights[:, None]
# xmin
pred_boxes1 = pred_ctr_x - torch.tensor(0.5, dtype=pred_ctr_x.dtype, device=pred_w.device) * pred_w
# ymin
pred_boxes2 = pred_ctr_y - torch.tensor(0.5, dtype=pred_ctr_y.dtype, device=pred_h.device) * pred_h
# xmax
pred_boxes3 = pred_ctr_x + torch.tensor(0.5, dtype=pred_ctr_x.dtype, device=pred_w.device) * pred_w
# ymax
pred_boxes4 = pred_ctr_y + torch.tensor(0.5, dtype=pred_ctr_y.dtype, device=pred_h.device) * pred_h
# 再次脱裤子放屁,用torch.cat((x,y,w,h), dim=1)就行了
pred_boxes = torch.stack((pred_boxes1, pred_boxes2, pred_boxes3, pred_boxes4), dim=2).flatten(1)
return pred_boxes
dx = rel_codes[:, 0::4] / wx:使用这种方法采样获得的数据是两个维度的,即[127504, 1]而不是[127504, ]
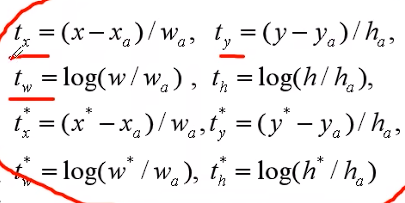
想得到中心x需要ta*wa+xa,即pred_ctr_x = dx * widths[:, None] + ctr_x[:, None]这段代码做的,其他同理
最后将坐标重新转变为左上角坐标和右下角坐标拼接获得pred_boxes
5. 通过view方法将proposals重新变为(4,12750,4)的shape
6. boxes, scores:通过filter_proposals函数筛除小boxes框,nms处理,根据预测概率获取前post_nms_top_n个目标,如果过滤后的预选框没有那么多则保留全部目标,数据类型为list,元素数量为一个batch中的图片数量,元素是一张图片的proposal的坐标信息
def filter_proposals(self, proposals, objectness, image_shapes, num_anchors_per_level):
# type: (Tensor, Tensor, List[Tuple[int, int]], List[int]) -> Tuple[List[Tensor], List[Tensor]]
"""
筛除小boxes框,nms处理,根据预测概率获取前post_nms_top_n个目标
Args:
proposals: 预测的bbox坐标
objectness: 预测的目标概率
image_shapes: batch中每张图片的size信息
num_anchors_per_level: 每个预测特征层上预测anchors的数目
Returns:
"""
num_images = proposals.shape[0]
device = proposals.device
# do not backprop throught objectness
objectness = objectness.detach()
objectness = objectness.reshape(num_images, -1)
# Returns a tensor of size size filled with fill_value
# levels负责记录分隔不同预测特征层上的anchors索引信息
levels = [torch.full((n,), idx, dtype=torch.int64, device=device)
for idx, n in enumerate(num_anchors_per_level)]
levels = torch.cat(levels, 0)
# Expand this tensor to the same size as objectness
levels = levels.reshape(1, -1).expand_as(objectness)
# select top_n boxes independently per level before applying nms
# 获取每张预测特征图上预测概率排前pre_nms_top_n的anchors索引值
top_n_idx = self._get_top_n_idx(objectness, num_anchors_per_level)
image_range = torch.arange(num_images, device=device)
batch_idx = image_range[:, None] # [batch_size, 1]
# 根据每个预测特征层预测概率排前pre_nms_top_n的anchors索引值获取相应概率信息
objectness = objectness[batch_idx, top_n_idx]
levels = levels[batch_idx, top_n_idx]
# 预测概率排前pre_nms_top_n的anchors索引值获取相应bbox坐标信息
proposals = proposals[batch_idx, top_n_idx]
objectness_prob = torch.sigmoid(objectness)
final_boxes = []
final_scores = []
# 遍历每张图像的相关预测信息
for boxes, scores, lvl, img_shape in zip(proposals, objectness_prob, levels, image_shapes):
# 调整预测的boxes信息,将越界的坐标调整到图片边界上
boxes = box_ops.clip_boxes_to_image(boxes, img_shape)
# 返回boxes满足宽,高都大于min_size的索引
keep = box_ops.remove_small_boxes(boxes, self.min_size)
boxes, scores, lvl = boxes[keep], scores[keep], lvl[keep]
# 移除小概率boxes,参考下面这个链接
# https://github.com/pytorch/vision/pull/3205
keep = torch.where(torch.ge(scores, self.score_thresh))[0] # ge: >=
boxes, scores, lvl = boxes[keep], scores[keep], lvl[keep]
# non-maximum suppression, independently done per level
keep = box_ops.batched_nms(boxes, scores, lvl, self.nms_thresh)
# keep only topk scoring predictions
keep = keep[: self.post_nms_top_n()]
boxes, scores = boxes[keep], scores[keep]
final_boxes.append(boxes)
final_scores.append(scores)
return final_boxes, final_scores
以上内容对应模型框架的这一部分:

To be continued

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









