










序列到序列模型(Sequence-to-Sequence Model, Seq2Seq)是一种用于处理输入和输出序列长度可能不同的任务的深度学习架构,通常用于自然语言处理(NLP)中的机器翻译、对话系统、文本摘要等任务。Seq2Seq 模型由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。
1. Seq2Seq 模型的基本结构
编码器:负责处理输入序列并将其转换为一个上下文向量(context vector),该向量通常是输入序列的固定大小表示。编码器可以是循环神经网络(RNN)、长短时记忆网络(LSTM)或门控循环单元(GRU)。
解码器:负责根据上下文向量生成输出序列,通常也是一个 RNN/LSTM/GRU。解码器可以通过一个结构化的方法(如贪心解码)或注意力机制来生成序列。
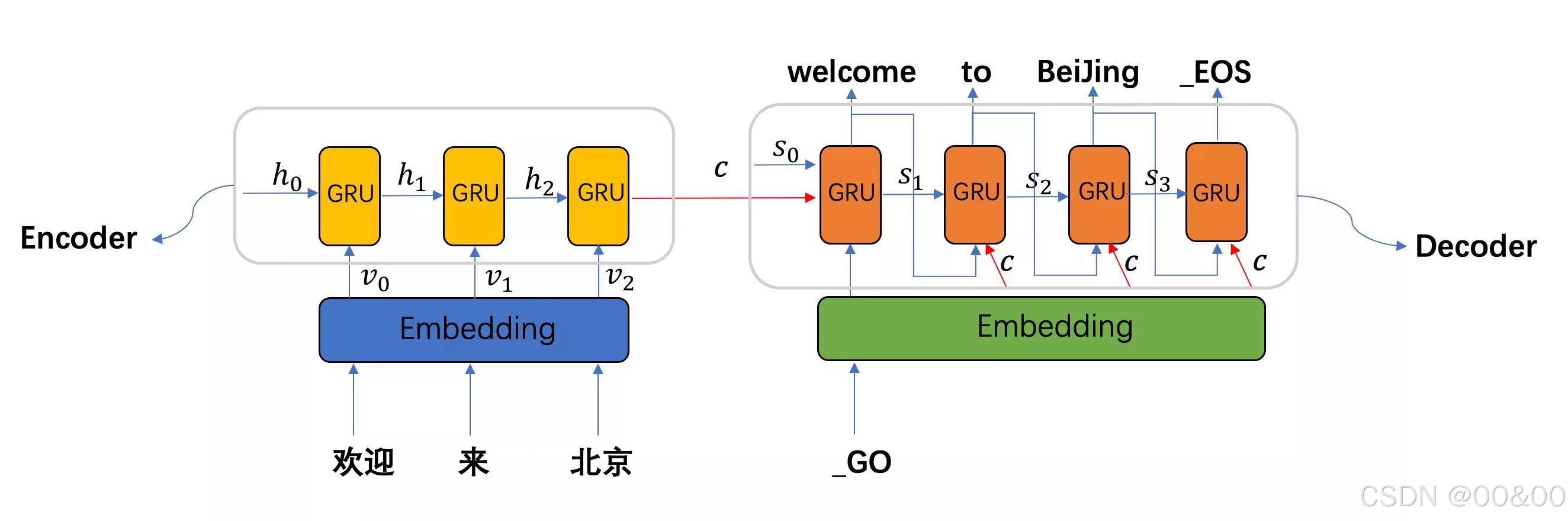
2. Seq2Seq 模型的工作流程
步骤1 输入处理:编码器接收一个输入序列,逐个时间步处理每个输入。
步骤2 上下文向量生成:在处理完输入序列后,编码器生成一个上下文向量,通常是最后一个隐藏层的输出。
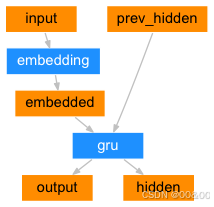
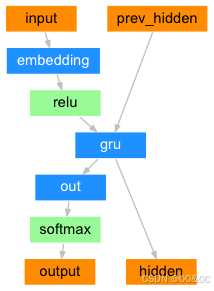
步骤3 输出生成:解码器接收上下文向量并开始生成输出序列。解码器在生成每个单词时,可以使用前一个单词的输出(teacher forcing)或者从生成的输出中取样。
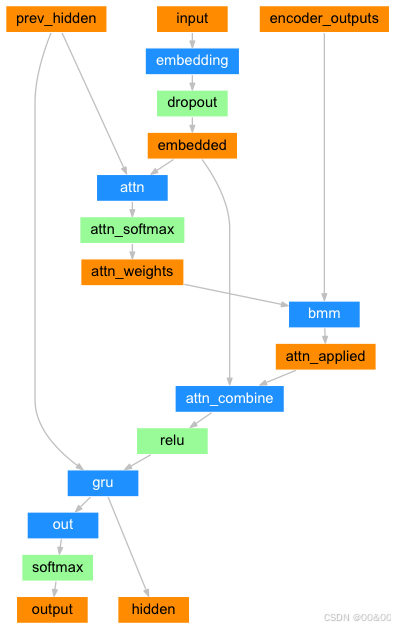
3. Seq2Seq 模型中的注意力机制
为了改善传统 Seq2Seq 模型在处理长序列时的局限性,通常会引入注意力机制,使解码器在生成输出的每一个步骤时可以“关注”输入序列的不同部分。
4. PyTorch 中的 Seq2Seq 模型示例
下面是一个使用 PyTorch 实现的简单 Seq2Seq 模型示例。此示例使用LSTM作为编码器和解码器,并包括注意力机制。
import torch
import torch.nn as nn
import torch.optim as optim
import random
# 定义编码器
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim, n_layers, dropout):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.lstm = nn.LSTM(emb_dim, hidden_dim, n_layers, dropout=dropout, batch_first=True)
def forward(self, src):
embedded = self.embedding(src)
outputs, (hidden, cell) = self.lstm(embedded)
return hidden, cell
# 定义解码器
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hidden_dim, n_layers, dropout):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(output_dim, emb_dim)
self.lstm = nn.LSTM(emb_dim, hidden_dim, n_layers, dropout=dropout, batch_first=True)
self.fc_out = nn.Linear(hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
input = input.unsqueeze(1) # 转换为 (batch_size, 1) 以匹配 LSTM 输入
embedded = self.dropout(self.embedding(input))
output, (hidden, cell) = self.lstm(embedded, (hidden, cell))
prediction = self.fc_out(output.squeeze(1)) # 预测输出
return prediction, hidden, cell
# 定义 Seq2Seq 模型
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, trg, teacher_forcing_ratio=0.5):
batch_size = trg.shape[0]
trg_len = trg.shape[1]
output_dim = self.decoder.fc_out.out_features
outputs = torch.zeros(batch_size, trg_len, output_dim).to(trg.device)
hidden, cell = self.encoder(src)
# 解码器输入是目标序列的开始符(通常是 <sos>)
input = trg[:, 0]
for t in range(1, trg_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[:, t] = output
# 随机选择是否使用
# 教师强迫(teacher forcing):决定是否使用真实的目标作为输入
teacher_force = random.random() < teacher_forcing_ratio
# 如果使用教师强迫,下一步输入为真实目标;否则,用模型的预测输出
input = trg[:, t] if teacher_force else output.argmax(1)
return outputs
# 示例用法
if __name__ == "__main__":
# 参数设置
INPUT_DIM = 1000 # 输入词汇表大小
OUTPUT_DIM = 1000 # 输出词汇表大小
EMB_DIM = 256 # 嵌入维度
HIDDEN_DIM = 512 # 隐层维度
N_LAYERS = 2 # LSTM 层数
DROPOUT = 0.5 # dropout 概率
# 初始化编码器和解码器
encoder = Encoder(INPUT_DIM, EMB_DIM, HIDDEN_DIM, N_LAYERS, DROPOUT)
decoder = Decoder(OUTPUT_DIM, EMB_DIM, HIDDEN_DIM, N_LAYERS, DROPOUT)
# 创建 Seq2Seq 模型
model = Seq2Seq(encoder, decoder)
# 假设输入和目标序列,随机初始化
src = torch.randint(0, INPUT_DIM, (8, 10)) # 输入序列(batch_size x seq_len)
trg = torch.randint(0, OUTPUT_DIM, (8, 12)) # 目标序列(batch_size x trg_len)
# 前向传播
outputs = model(src, trg)
# 输出结果
print("Output shape:", outputs.shape) # 应该是 (batch_size, trg_len, OUTPUT_DIM) 
代码解析
4.1 Encoder 类:
该类初始化一个嵌入层和一个 LSTM 层。
`forward` 方法负责将输入序列嵌入,然后通过 LSTM 生成隐藏状态和细胞状态。
4.2 Decoder 类:
该类同样初始化一个嵌入层和一个 LSTM 层,并且增加了一个全连接层将 LSTM 的输出映射到输出词汇表维度。
`forward` 方法接收输入、隐藏状态和细胞状态,生成输出并返回更新后的状态。
4.3 Seq2Seq 类:
负责整合编码器和解码器。
`forward` 方法接受输入序列和目标序列,初始化输出张量,并使用编码器生成上下文。然后逐步生成目标序列。
在生成时使用教师强迫,控制预测和实际目标之间的选择。
4.4 示例用法**:
给定词汇表大小和其他参数,实例化编码器、解码器及 Seq2Seq 模型。
生成一些随机的源序列 `src` 和目标序列 `trg` 进行前向传播。输出是一个形状为 `(batch_size, trg_len, OUTPUT_DIM)` 的张量,代表模型对目标序列的预测。
5. 训练 Seq2Seq 模型
Seq2Seq 模型的训练过程通常包括以下步骤:
准备数据集:准备源序列和目标序列对。
定义损失函数:常用的损失函数是交叉熵损失(CrossEntropyLoss)。
定义优化器:可以使用 Adam 或 SGD 优化器。
进行训练:在每个 epoch 中,遍历批次并进行前向和反向传播,更新模型参数。
6. 总结
Seq2Seq 模型为处理变长序列提供了一种有效的方式,它通过编码器和解码器的架构,结合注意力机制,进一步提升了多种任务的性能。这种模型在机器翻译和其他序列生成任务中得到了广泛应用。

















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









