




计算机视觉是深度学习中最具应用价值的领域之一,而PyTorch作为当前最流行的深度学习框架,以其简洁的API和动态计算图特性受到了广大研究者和开发者的青睐。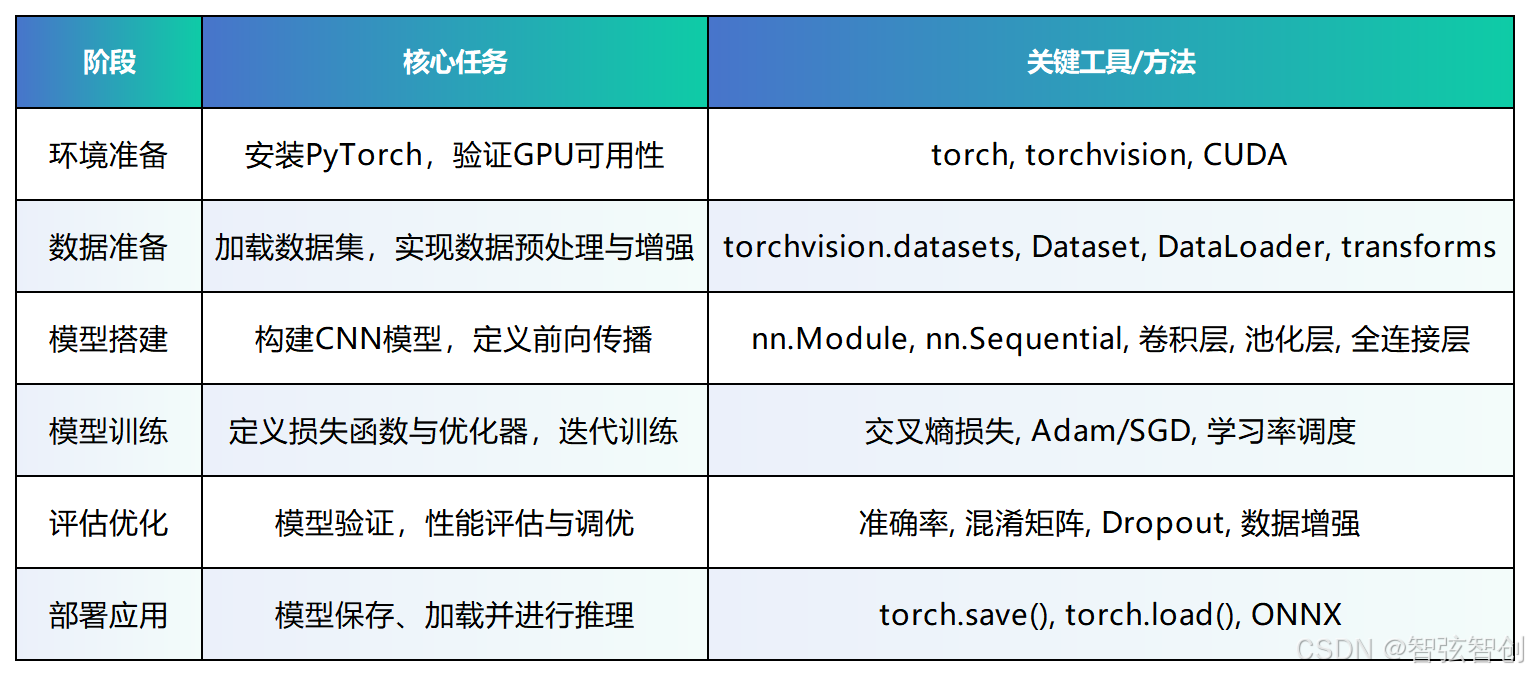
本文将带你完整走一遍使用PyTorch搭建计算机视觉模型的流程,从环境准备到模型部署,为你提供实用的代码示例和关键技术要点。
一、环境配置与验证
在开始之前,我们需要确保正确安装和配置了PyTorch环境。
1.1 安装PyTorch
访问[PyTorch官网](https://pytorch.org/)获取适合你系统的安装命令。例如,对于CUDA 11.x的用户:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu1131.2 验证GPU可用性
安装完成后,通过以下代码验证环境配置:
import torch
print(f"PyTorch版本: {torch.__version__}")
print(f"CUDA是否可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"CUDA版本: {torch.version.cuda}")
print(f"GPU设备: {torch.cuda.get_device_name(0)}")二、数据准备与预处理
高质量的数据处理是模型成功的基础。PyTorch提供了丰富的数据处理工具。
2.1 数据加载与增强
import torch
from torchvision import transforms, datasets
# 定义数据预处理流程
data_transform = transforms.Compose([
transforms.Resize((64, 64)), # 调整图像尺寸
transforms.RandomHorizontalFlip(0.5), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转
transforms.ColorJitter(0.2, 0.2, 0.2), # 颜色抖动
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize( # 标准化
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=data_transform
)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=32,
shuffle=True,
num_workers=4
)2.2 自定义数据集类
对于自己的数据集,需要继承`Dataset`类:
from torch.utils.data import Dataset
from PIL import Image
import os
class CustomDataset(Dataset):
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir
self.transform = transform
self.image_paths = [os.path.join(data_dir, fname)
for fname in os.listdir(data_dir)
if fname.endswith(('.jpg', '.png'))]
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image_path = self.image_paths[idx]
&n 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











