




 本文介绍了一种构建单词查找树的方法,旨在通过优化结构减少节点数量,提高搜索效率。文章详细解释了查找树的特点,并提供了一个示例程序,用于计算给定单词列表对应的查找树节点总数。
本文介绍了一种构建单词查找树的方法,旨在通过优化结构减少节点数量,提高搜索效率。文章详细解释了查找树的特点,并提供了一个示例程序,用于计算给定单词列表对应的查找树节点总数。
【题目描述】
在进行文法分析的时候,通常需要检测一个单词是否在我们的单词列表里。为了提高查找和定位的速度,通常都画出与单词列表所对应的单词查找树,其特点如下:
1.根结点不包含字母,除根结点外每一个结点都仅包含一个大写英文字母;
2.从根结点到某一结点,路径上经过的字母依次连起来所构成的字母序列,称为该结点对应的单词。单词列表中的每个单词,都是该单词查找树某个结点所对应的单词;
3.在满足上述条件下,该单词查找树的结点数最少。
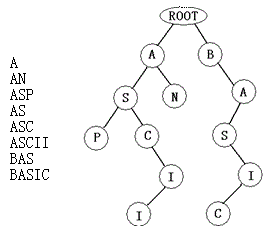
4.例如图3-2左边的单词列表就对应于右边的单词查找树。注意,对一个确定的单词列表,请统计对应的单词查找树的结点数(包含根结点)。
【输入】
为一个单词列表,每一行仅包含一个单词和一个换行/回车符。每个单词仅由大写的英文字母组成,长度不超过63个字母 。文件总长度不超过32K,至少有一行数据。
【输出】
仅包含一个整数,该整数为单词列表对应的单词查找树的结点数。
【输入样例】
A AN ASP AS ASC ASCII BAS BASIC
【输出样例】
13
#include<bits/stdc++.h>
using namespace std;
string a[10000];
string s;
int n;
int main()
{
//
//freopen("int.txt","r",stdin);
while(cin>>a[++n]);
sort(a+1,a+1+n);
int t=a[1].length();//先累加第一个单词的长度
for(int i=2;i<=n;i++){//依次计算每个单词对前一个单词的差
int j=0;
while(a[i][j]==a[i-1][j]&&j<a[i-1].length()) j++;//求俩个单词相等部分的长度
t+=a[i].length()-j;//累加俩个单词差 a[i].length()-j;
}
cout<<t+1<<endl;
return 0;
}

















 640
640



 到【灌水乐园】发言
到【灌水乐园】发言








