



- PyTorch基础与异或问题实践
- 激活函数与神经网络优化
- 数据预处理与模型优化:FashionMNIST实验
- 经典CNN架构与PyTorch Lightning实践
- Transformers与多头注意力机制实战
- 深度能量模型与PyTorch实践
- 图神经网络
- 自编码器与神经网络应用
- 深度归一化流图像建模与实践
- 自回归图像建模与像素CNN实现
- Vision Transformers with PyTorch Lightning on昇腾
- ProtoNet与ProtoMAML元学习算法实践
- SimCLR与Logistic回归在自我监督学习中的应用
模型的优化和初始化
学习目标
本次实验主要目的是让学员掌握数据预处理、模型初始化及优化的技巧,并通过可视化工具深入理解模型在训练过程中的行为。具体包括了解FashionMNIST数据集的使用,实现自定义的数据变换,探索不同激活函数对网络性能的影响,以及利用权重、梯度和激活值分布的可视化分析来诊断和改进模型训练过程。
相关知识点
- 模型的优化和初始化
学习内容
1 模型的优化和初始化
1.1 导入包和数据集
%pip install seaborn
%pip install wheel==0.44.0
%pip install --upgrade jupyter ipywidgets
import os
import json
import math
import numpy as np
import copy
import matplotlib.pyplot as plt
from matplotlib import cm
%matplotlib inline
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('svg', 'pdf')
import seaborn as sns
sns.set()
from tqdm.notebook import tqdm
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
import torch.optim as optim
将使用set_seed函数,以及路径变量CHECKPOINT_PATH。如果需要,请调整这些路径。
# 保存文件路径
CHECKPOINT_PATH = "./saved_models/"
# 设置seed的函数
def set_seed(seed):
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
set_seed(42)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# 获取将在整个 notebook 中使用的设备
device = torch.device("cpu") if not torch.cuda.is_available() else torch.device("npu:0")
print("Using device", device)
将使用三种不同的优化器来训练模型,下面将下载Fashion-MNIST数据集。
Fashion-MNIST 是一个包含70,000张28x28像素灰度图像的公开数据集,由Zalando于2017年发布,旨在作为经典MNIST手写数字数据集的一个更具挑战性的现代替代品。 它被设计成与MNIST完全兼容,拥有相同的图像尺寸、数据结构(60,000张训练图像和10,000张测试图像)和10个类别(如T恤、裤子、运动鞋等),因此可以作为“即插即用”的替代方案。 由于其难度适中,既能有效评估现代深度学习模型(基础CNN模型准确率可轻松超过90%),又不像原始MNIST那样容易“饱和”,Fashion-MNIST已成为机器学习教学、研究和模型性能基准测试中广泛使用的标准资源,并被TensorFlow、PyTorch等所有主流深度学习框架原生支持。
#下载所需的预训练模型以及数据集
!wget https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_datasets/c22220f845c011f0943ffa163edcddae/FashionMNIST.zip
!unzip FashionMNIST.zip
1.2 网络构建
在整个笔记本中,将使用一个深层全连接网络,这与之前的实验类似。同样会将这个网络应用于FashionMNIST数据集,以便学员可以将结果与之前进行对比。首先从加载FashionMNIST数据集开始:
from torchvision.datasets import FashionMNIST
from torchvision import transforms
MNIST_PATH = "./"
# 应用于每张图像的变换 => 首先使它们成为张量,然后使用均值 0 和 std 1 对它们进行归一化
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.2861,), (0.3530,))
])
# 加载训练数据集。我们需要将其拆分为训练和验证部分
train_dataset = FashionMNIST(root=MNIST_PATH, train=True, transform=transform, download=True)
train_set, val_set = torch.utils.data.random_split(train_dataset, [50000, 10000])
# 加载测试集
test_set = FashionMNIST(root=MNIST_PATH, train=False, transform=transform, download=True)
#定义了一组数据加载器,以后可以将其用于各种目的。
# 请注意,为了实际训练模型,将使用不同的数据加载器
# 具有较小的批处理大小.
train_loader = data.DataLoader(train_set, batch_size=1024, shuffle=True, drop_last=False)
val_loader = data.DataLoader(val_set, batch_size=1024, shuffle=False, drop_last=False)
test_loader = data.DataLoader(test_set, batch_size=1024, shuffle=False, drop_last=False)
调整了transforms.Normalize的参数。现在的归一化设置旨在使像素的期望均值为0,标准差为1。这对于下面将讨论的初始化问题特别相关,因此在这里进行了修改。需要注意的是,在大多数分类任务中,这两种归一化方法(取值范围在-1到1之间或均值为0且标准差为1)都被证明是有效的。可以通过计算原始图像的均值和标准差来确定归一化的参数:
print("Mean", (train_dataset.data.float() / 255.0).mean().item())
print("Std", (train_dataset.data.float() / 255.0).std().item())
可以通过查看单个批次的统计数据来验证转换是否正确:
imgs, _ = next(iter(train_loader))
print(f"Mean: {imgs.mean().item():5.3f}")
print(f"Standard deviation: {imgs.std().item():5.3f}")
print(f"Maximum: {imgs.max().item():5.3f}")
print(f"Minimum: {imgs.min().item():5.3f}")
请注意,最大值和最小值不再是1和-1,而是向正值偏移。这是因为FashionMNIST包含很多黑色像素(值接近0),类似于MNIST数据集。
接下来,创建一个线性神经网络。将使用与之前实验相同的设置。
class BaseNetwork(nn.Module):
def __init__(self, act_fn, input_size=784, num_classes=10, hidden_sizes=[512, 256, 256, 128]):
"""
Inputs:
act_fn - 在网络中应用作非线性的激活函数的对象。
input_size - 输入图像的大小(以像素为单位)
num_classes - 我们要预测的类数
hidden_sizes - 指定 NN 中隐藏层大小的整数列表
"""
super().__init__()
# 根据指定的隐藏大小创建网络
layers = []
layer_sizes = [input_size] + hidden_sizes
for layer_index in range(1, len(layer_sizes)):
layers += [nn.Linear(layer_sizes[layer_index-1], layer_sizes[layer_index]),
act_fn]
layers += [nn.Linear(layer_sizes[-1], num_classes)]
self.layers = nn.ModuleList(layers) # 模块列表将模块列表注册为子模块(例如,用于参数)
self.config = {"act_fn": act_fn.__class__.__name__, "input_size": input_size, "num_classes": num_classes, "hidden_sizes": hidden_sizes}
def forward(self, x):
x = x.view(x.size(0), -1)
for l in self.layers:
x = l(x)
return x
对于激活函数,使用PyTorch的torch.nn库而不是自己实现。不过,同时也定义了一个恒等(Identity)激活函数。尽管这种激活函数会极大地限制网络的建模能力,但在初始化讨论的初步阶段,将使用它以简化问题。
class Identity(nn.Module):
def forward(self, x):
return x
act_fn_by_name = {
"tanh": nn.Tanh,
"relu": nn.ReLU,
"identity": Identity
}
最后,定义了一些将在讨论中使用的绘图函数。(1)可视化网络内部的权重/参数分布,(2)可视化不同层参数接收到的梯度,以及(3)激活值,即线性层的输出。
##############################################################
def plot_dists(val_dict, color="C0", xlabel=None, stat="count", use_kde=True):
columns = len(val_dict)
fig, ax = plt.subplots(1, columns, figsize=(columns*3, 2.5))
fig_index = 0
for key in sorted(val_dict.keys()):
key_ax = ax[fig_index%columns]
sns.histplot(val_dict[key], ax=key_ax, color=color, bins=50, stat=stat,
kde=use_kde and ((val_dict[key].max()-val_dict[key].min())>1e-8)) # 仅在存在方差时绘制KDE
key_ax.set_title(f"{key} " + (r"(%i $\to$ %i)" % (val_dict[key].shape[1], val_dict[key].shape[0]) if len(val_dict[key].shape)>1 else ""))
if xlabel is not None:
key_ax.set_xlabel(xlabel)
fig_index += 1
fig.subplots_adjust(wspace=0.4)
return fig
##############################################################
def visualize_weight_distribution(model, color="C0"):
weights = {}
for name, param in model.named_parameters():
if name.endswith(".bias"):
continue
key_name = f"Layer {name.split('.')[1]}"
weights[key_name] = param.detach().view(-1).cpu().numpy()
## Plotting
fig = plot_dists(weights, color=color, xlabel="Weight vals")
fig.suptitle("Weight distribution", fontsize=14, y=1.05)
plt.show()
plt.close()
##############################################################
def visualize_gradients(model, color="C0", print_variance=False):
"""
Inputs:
net - 类 BaseNetwork 的对象
color - 可视化直方图的颜色(以便更轻松地分离激活函数)
"""
model.eval()
small_loader = data.DataLoader(train_set, batch_size=1024, shuffle=False)
imgs, labels = next(iter(small_loader))
imgs, labels = imgs.to(device), labels.to(device)
# 通过网络传递一个批次,并计算权重
model.zero_grad()
preds = model(imgs)
loss = F.cross_entropy(preds, labels) # 同样nn.CrossEntropyLoss, 但作为一个函数而不是模块
loss.backward()
# 将可视化限制为权重参数并排除偏差以减少绘图的数量
grads = {name: params.grad.view(-1).cpu().clone().numpy() for name, params in model.named_parameters() if "weight" in name}
model.zero_grad()
## 绘图
fig = plot_dists(grads, color=color, xlabel="")
fig.suptitle("Gradient distribution", fontsize=14, y=1.05)
plt.show()
plt.close()
if print_variance:
for key in sorted(grads.keys()):
print(f"{key} - Variance: {np.var(grads[key])}")
##############################################################
def visualize_activations(model, color="C0", print_variance=False):
model.eval()
small_loader = data.DataLoader(train_set, batch_size=1024, shuffle=False)
imgs, labels = next(iter(small_loader))
imgs, labels = imgs.to(device), labels.to(device)
# 通过网络传递一批,并计算权重的梯度
feats = imgs.view(imgs.shape[0], -1)
activations = {}
with torch.no_grad():
for layer_index, layer in enumerate(model.layers):
feats = layer(feats)
if isinstance(layer, nn.Linear):
activations[f"Layer {layer_index}"] = feats.view(-1).detach().cpu().numpy()
# 绘图
fig = plot_dists(activations, color=color, stat="density", xlabel="Activation vals")
fig.suptitle("Activation distribution", fontsize=14, y=1.05)
plt.show()
plt.close()
if print_variance:
for key in sorted(activations.keys()):
print(f"{key} - Variance: {np.var(activations[key])}")
##############################################################
1.3 初始化
在开始讨论初始化之前,需要注意的是,关于神经网络初始化的主题存在许多非常优秀的博客文章的文章,或者更侧重数学的博客文章。如果在完成本课程后仍有不清楚的地方,建议也浏览一下博客文章。
当初始化一个神经网络时,希望具备以下几个特性:
方差传播:输入的方差应通过模型传播到最后一个层,从而使输出神经元具有相似的标准差。如果方差随着模型深度增加而消失,那么优化模型将变得更加困难,因为下一层的输入基本上会变成一个单一的常数值。同样地,如果方差增大,则很可能随着模型设计得越深,方差会趋向于无穷大(即爆炸)。
梯度分布:希望每一层的梯度具有相同的方差。如果第一层接收到的梯度远小于最后一层,将难以选择合适的学习率。
作为寻找良好初始化方法的起点,将基于没有激活函数(即恒等激活函数)的线性神经网络分析不同的初始化方法。这样做是因为初始化方法依赖于网络中使用的具体激活函数,之后可以根据特定的选择调整初始化方案。
model = BaseNetwork(act_fn=Identity()).to(device)
1.3.1 常数初始化
首先,可以考虑一种简单的初始化方法,即将所有权重设置为相同的常数值。如果将所有权重都设为零,那么传播的梯度也会是零,这显然不行。但是,如果把所有权重设为一个略大于或小于0的小数值,结果将如何。为了弄清楚这个问题,可以通过编写一个函数来实现这种初始化,并通过可视化这些参数的梯度来观察效果。
def const_init(model, c=0.0):
for name, param in model.named_parameters():
param.data.fill_(c)
const_init(model, c=0.005)
visualize_gradients(model)
visualize_activations(model, print_variance=True)
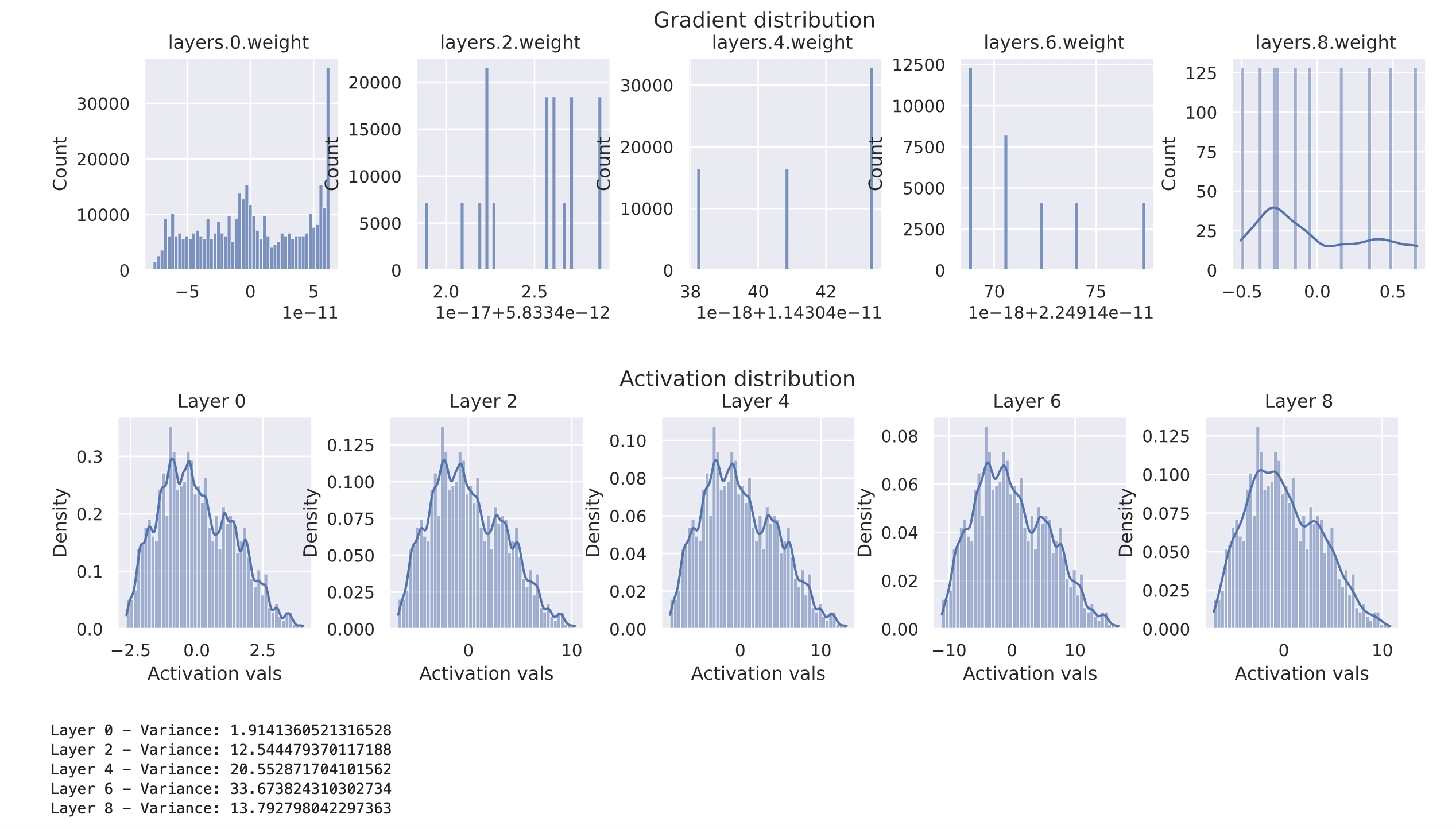
如前面所见,只有第一层和最后一层有不同的梯度分布,而中间三层的所有权重具有几乎相同的梯度(虽然这个值不为0,但通常非常接近0)。这意味着用相同值初始化的参数会始终保持相同的值,这会导致这些参数变得无效,并将有效参数数量减少到1。因此,不能使用常数初始化来训练网络。
1.3.2 恒定方差初始化
从上面的实验可以看出,使用常数值进行初始化是不可行的。那么,如果改为从某个分布(例如高斯分布)中随机采样来进行初始化呢?最直观的方法是为网络中的所有层选择一个相同的方差。下面来实现这种方法,并通过可视化各层的激活值分布来看看效果。
def var_init(model, std=0.01):
for name, param in model.named_parameters():
param.data.normal_(std=std)
var_init(model, std=0.01)
visualize_activations(model, print_variance=True)
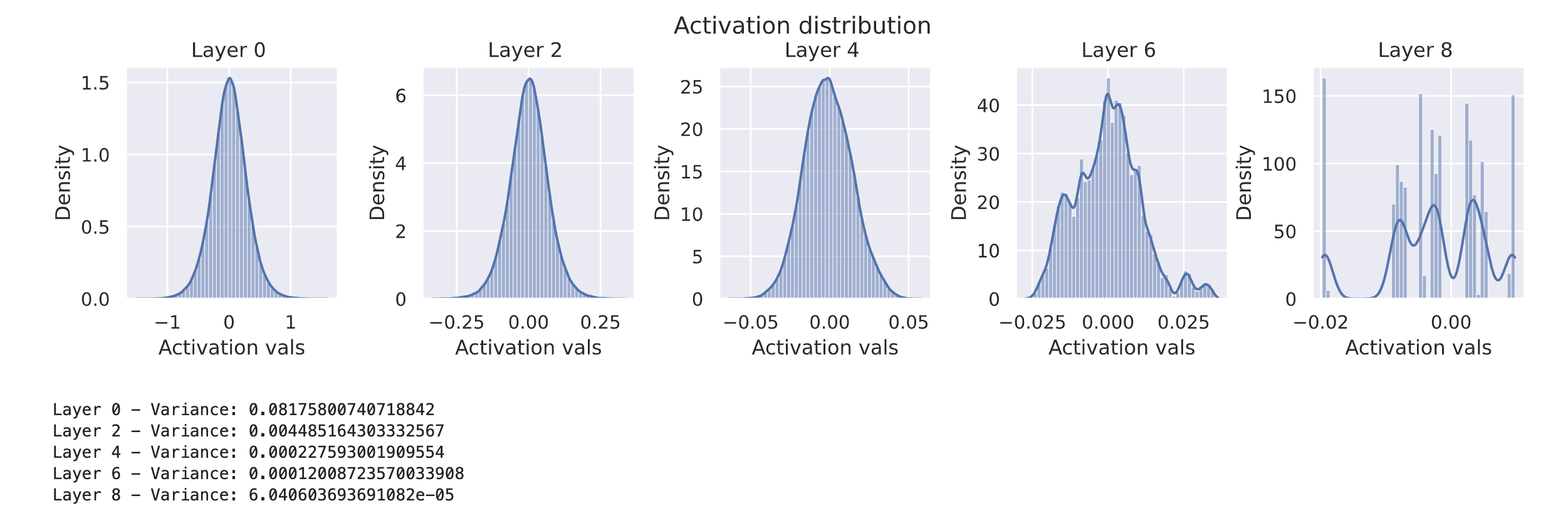
激活值的方差在逐层传递过程中变得越来越小,在最后一层几乎消失。另一种方法是使用更高的标准差:
var_init(model, std=0.1)
visualize_activations(model, print_variance=True)
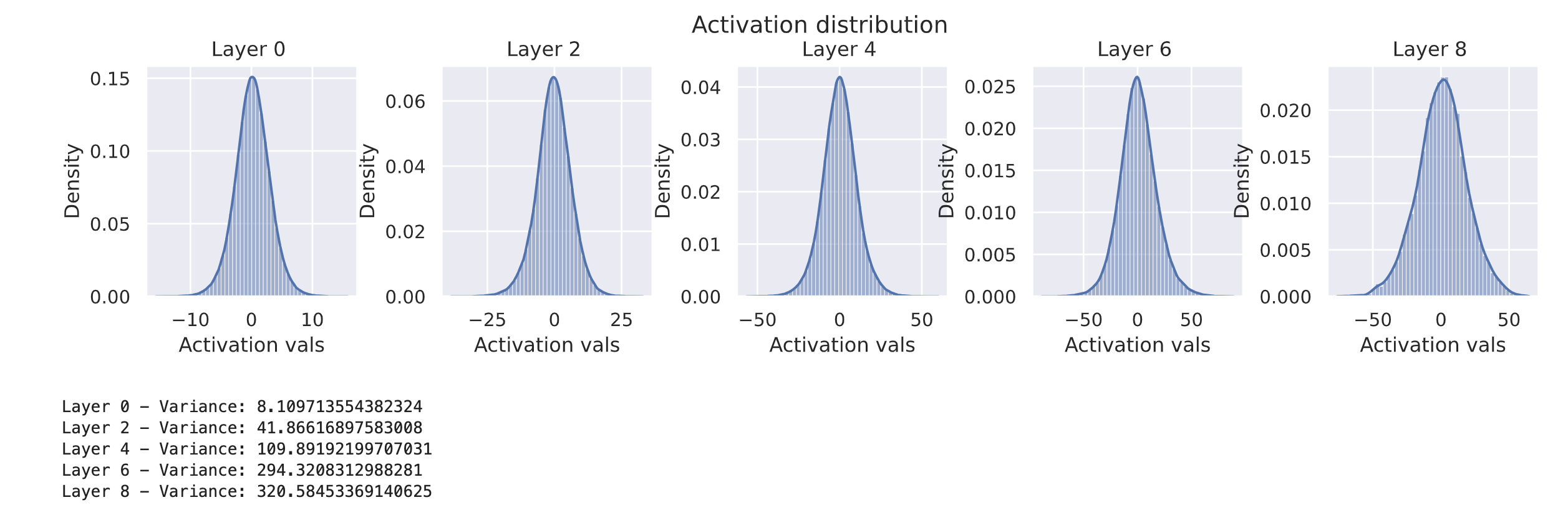
使用更高的标准差时,激活值很可能会变得非常大,甚至“爆炸”。可以尝试不同的标准差值,但很难找到一个既能保证各层激活值分布合理,又特别适合模型的值。如果要改变隐藏层的大小或层数,就需要重新寻找合适的标准差值,这种方法既不高效也不建议采用。
如何找到合适的初始化值
通过上面的实验,知道需要从某个分布中采样权重,但具体应该使用哪种分布还不确定。下一步,将尝试从激活值分布的角度来寻找最佳的初始化方法。为此,提出了以下两个要求:
- 激活值的均值应为零
- 每层的激活值方差应保持一致
假设要为以下层设计一个初始化方法: y = W x + b y=Wx+b y=Wx+b ,其中 y ∈ R d y y\in\mathbb{R}^{d_y} y∈Rdy, x ∈ R d x x\in\mathbb{R}^{d_x} x∈Rdx. 目标是使 y y y 中每个元素的方差与输入相同,即 Var ( y i ) = Var ( x i ) = σ x 2 \text{Var}(y_i)=\text{Var}(x_i)=\sigma_x^{2} Var(yi)=Var(xi)=σx2, 并且均值为零。假设 x x x 的均值也为零,因为在深度神经网络中, y y y 将成为下一层的输入。这意味着权重和偏置的期望值也应为零.实际上,由于 b b b 是每个输出神经元的一个常数值,并且在不同输入间保持不变,将它整体设为零。
接下来,需要计算初始化权重参数所需的方差。在计算过程中,将使用以下方差规则:对于两个独立变量,它们乘积的方差为 Var ( X ⋅ Y ) = E ( Y ) 2 Var ( X ) + E ( X ) 2 Var ( Y ) + Var ( X ) Var ( Y ) = E ( Y 2 ) E ( X 2 ) − E ( Y ) 2 E ( X ) 2 \text{Var}(X\cdot Y) = \mathbb{E}(Y)^2\text{Var}(X) + \mathbb{E}(X)^2\text{Var}(Y) + \text{Var}(X)\text{Var}(Y) = \mathbb{E}(Y^2)\mathbb{E}(X^2)-\mathbb{E}(Y)^2\mathbb{E}(X)^2 Var(X⋅Y)=E(Y)2Var(X)+E(X)2Var(Y)+Var(X)Var(Y)=E(Y2)E(X2)−E(Y)2E(X)2 (这里的 X X X 和 Y Y Y 并不是前面的 x x x and y y y, 而是任意随机变量)。
所需的权重方差 Var ( w i j ) \text{Var}(w_{ij}) Var(wij)的计算步骤如下:
y i = ∑ j w i j x j Calculation of a single output neuron without bias Var ( y i ) = σ x 2 = Var ( ∑ j w i j x j ) = ∑ j Var ( w i j x j ) Inputs and weights are independent of each other = ∑ j Var ( w i j ) ⋅ Var ( x j ) Variance rule (see above) with expectations being zero = d x ⋅ Var ( w i j ) ⋅ Var ( x j ) Variance equal for all d x elements = σ x 2 ⋅ d x ⋅ Var ( w i j ) ⇒ Var ( w i j ) = σ W 2 = 1 d x \begin{split} y_i & = \sum_{j} w_{ij}x_{j}\hspace{10mm}\text{Calculation of a single output neuron without bias}\\ \text{Var}(y_i) = \sigma_x^{2} & = \text{Var}\left(\sum_{j} w_{ij}x_{j}\right)\\ & = \sum_{j} \text{Var}(w_{ij}x_{j}) \hspace{10mm}\text{Inputs and weights are independent of each other}\\ & = \sum_{j} \text{Var}(w_{ij})\cdot\text{Var}(x_{j}) \hspace{10mm}\text{Variance rule (see above) with expectations being zero}\\ & = d_x \cdot \text{Var}(w_{ij})\cdot\text{Var}(x_{j}) \hspace{10mm}\text{Variance equal for all $d_x$ elements}\\ & = \sigma_x^{2} \cdot d_x \cdot \text{Var}(w_{ij})\\ \Rightarrow \text{Var}(w_{ij}) = \sigma_{W}^2 & = \frac{1}{d_x}\\ \end{split} yiVar(yi)=σx2⇒Var(wij)=σW2=j∑wijxjCalculation of a single output neuron without bias=Var(j∑wijxj)=j∑Var(wijxj)Inputs and weights are independent of each other=j∑Var(wij)⋅Var(xj)Variance rule (see above) with expectations being zero=dx⋅Var(wij)⋅Var(xj)Variance equal for all dx elements=σx2⋅dx⋅Var(wij)=dx1
因此,应该使用输入维度 d x d_x dx的倒数作为方差来初始化权重分布。在下面实现这种方法,并验证它是否满足预期:
def equal_var_init(model):
for name, param in model.named_parameters():
if name.endswith(".bias"):
param.data.fill_(0)
else:
param.data.normal_(std=1.0/math.sqrt(param.shape[1]))
equal_var_init(model)
visualize_weight_distribution(model)
visualize_activations(model, print_variance=True)
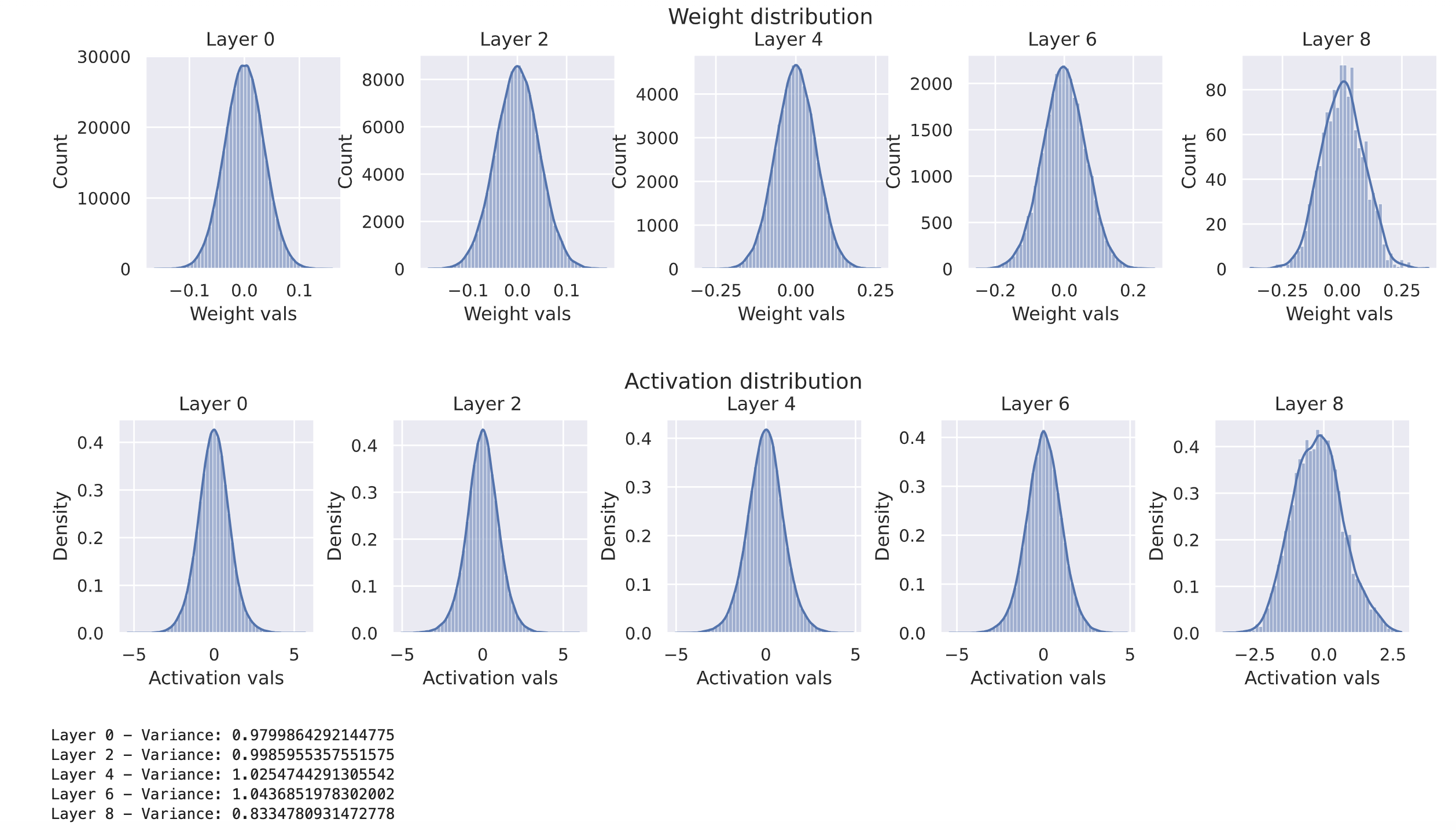
正如预期的那样,方差确实在各层之间保持恒定。需要注意的是,初始化方法不仅限于正态分布,任何均值为0、方差为 1 / d x 1/d_x 1/dx的分布都可以使用。实践中,均匀分布常被用于初始化。相比于正态分布,使用均匀分布的一个小优势在于它可以避免初始化出过大或过小的权重。实践中,均匀分布常被用于初始化。相比于正态分布,使用均匀分布的一个小优势在于它可以避免初始化出过大或过小的权重。
除了激活值的方差外,还希望稳定梯度的方差。这有助于确保深层网络在训练过程中能够平稳优化。实际上,可以从 Δ x = W Δ y \Delta x=W\Delta y Δx=WΔy出发进行类似的计算,最终得出应根据输出神经元数量 d y d_y dy 使用 1 / d y 1/d_y 1/dy 来初始化各层。学员可以自行完成这个计算作为练习,或者参考相关博客文章获取详细解释。为了在这两个约束条件之间找到平衡,Glorot 和 Bengio (2010)提出了使用这两个值的调和平均数的方法。这引出了著名的 Xavier 初始化:
W ∼ N ( 0 , 2 d x + d y ) W\sim \mathcal{N}\left(0,\frac{2}{d_x+d_y}\right) W∼N(0,dx+dy2)
如果使用均匀分布来初始化权重,那么将按照以下方式初始化权重:
W ∼ U [ − 6 d x + d y , 6 d x + d y ] W\sim U\left[-\frac{\sqrt{6}}{\sqrt{d_x+d_y}}, \frac{\sqrt{6}}{\sqrt{d_x+d_y}}\right] W∼U[−dx+dy6,dx+dy6]
将定义一个函数来快速实现 Xavier 均匀初始化,并验证其有效性
def xavier_init(model):
for name, param in model.named_parameters():
if name.endswith(".bias"):
param.data.fill_(0)
else:
bound = math.sqrt(6)/math.sqrt(param.shape[0]+param.shape[1])
param.data.uniform_(-bound, bound)
xavier_init(model)
visualize_gradients(model, print_variance=True)
visualize_activations(model, print_variance=True)
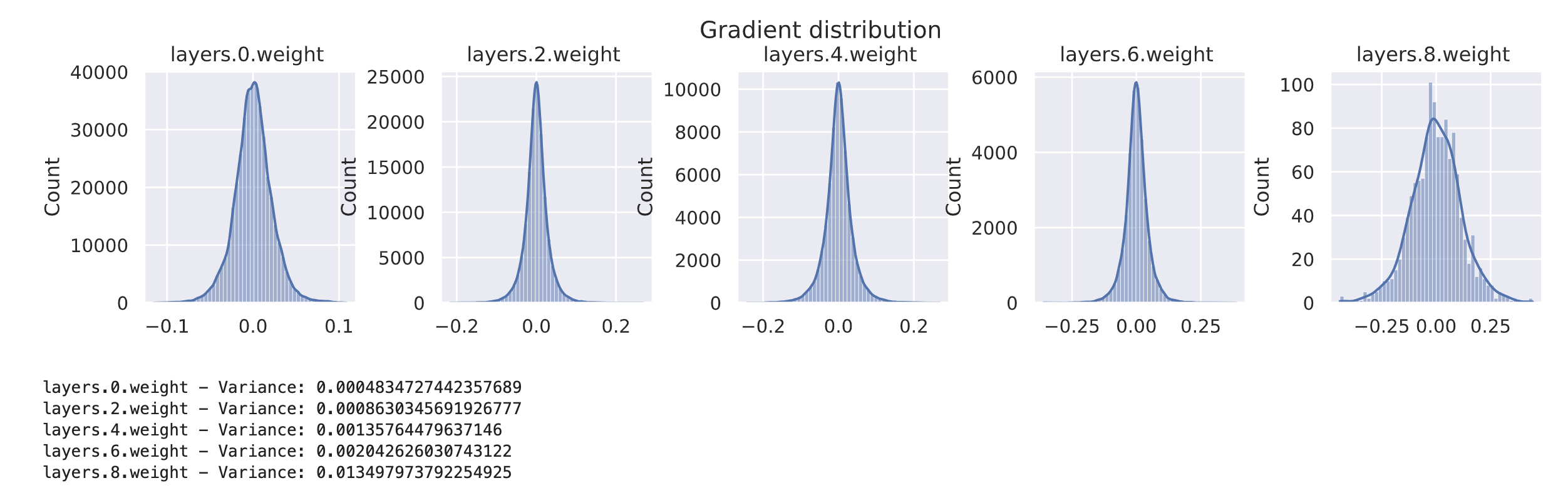
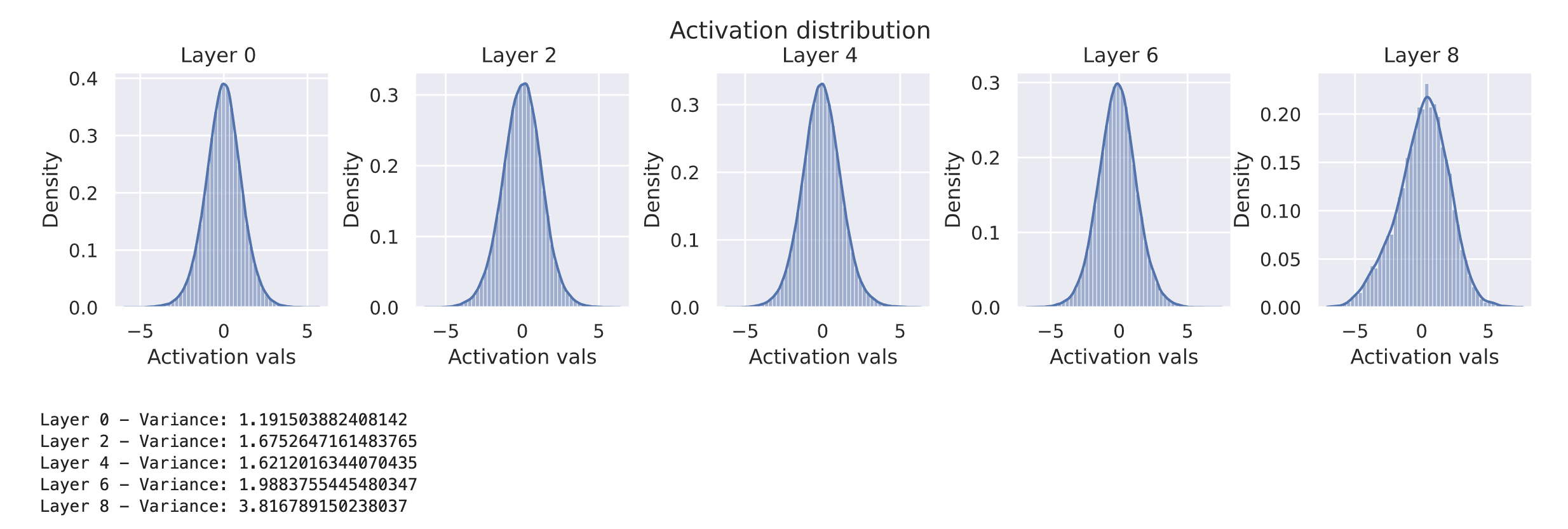
观察到,Xavier 初始化能够平衡梯度和激活值的方差。需要注意的是,输出层的方差显著较高是因为输入维度(128)和输出维度(10)之间存在较大差异。然而,目前假设是激活函数是线性的。如果在网络中加入非线性激活函数,情况会如何变化呢?
在基于 tanh 的网络中,通常假设在训练初期的小值情况下,tanh 函数可以视为线性函数,因此不需要调整之前的计算方法。可以验证这一假设是否同样适用于本次实验场景:
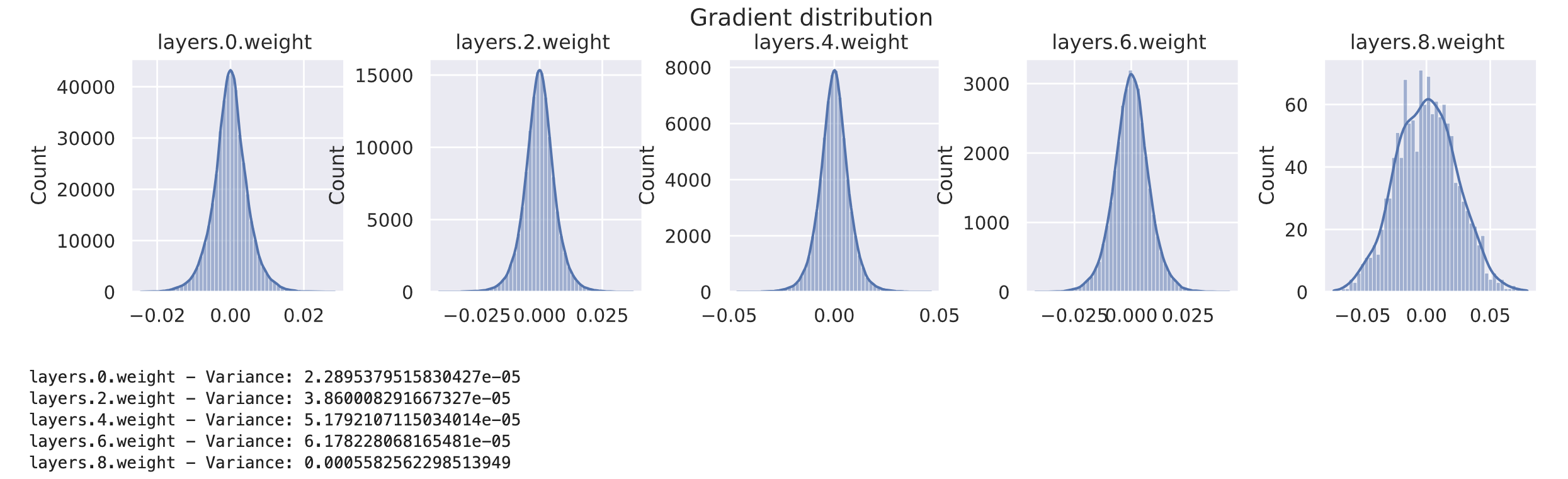
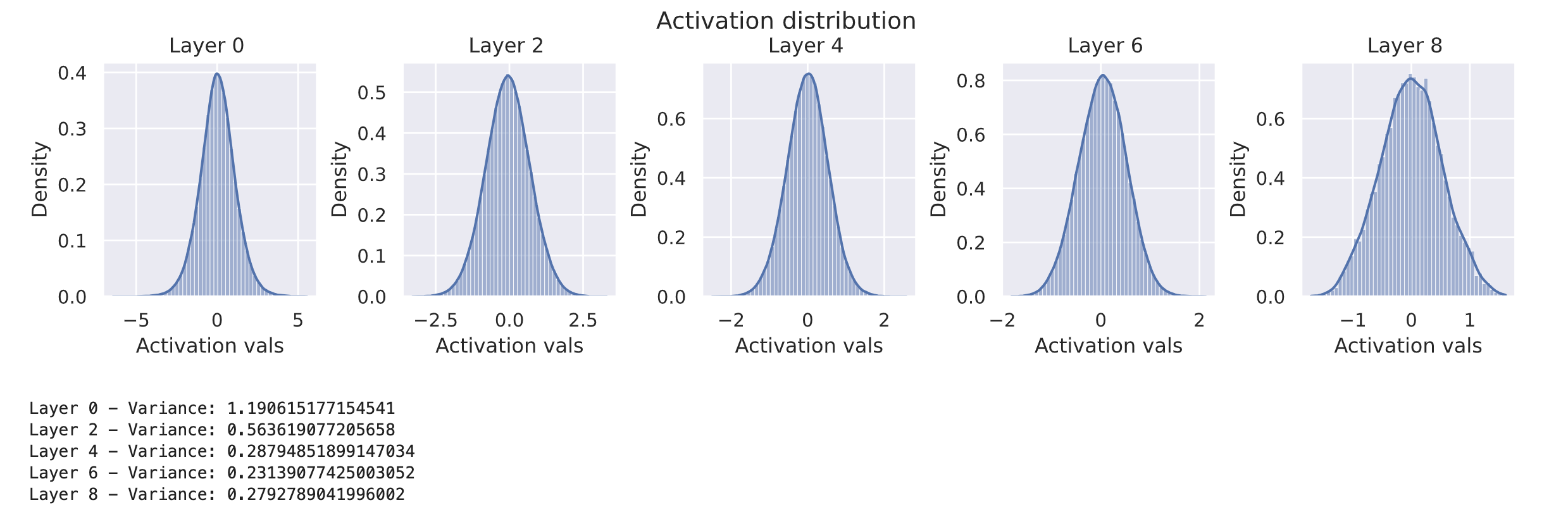
model = BaseNetwork(act_fn=nn.Tanh()).to(device)
xavier_init(model)
visualize_gradients(model, print_variance=True)
visualize_activations(model, print_variance=True)
尽管方差随着网络深度的增加而逐渐减小,但可以看出激活值分布更加集中在较低的数值上。因此,如果网络继续加深,方差将稳定在大约0.25左右。由此可以得出结论,Xavier初始化对于Tanh网络是有效的。但是,对于ReLU网络呢?在这种情况下,无法使用之前的假设,即非线性激活函数在初始阶段的小值情况下可以视为线性函数。ReLU激活函数会将输入中的一半(在期望意义上)设为0,这意味着输入的期望值不再是零。 然而,只要权重 W W W 的期望为零且偏置 b = 0 b=0 b=0,输出的期望值仍为零。ReLU初始化与恒等映射初始化的主要区别在于计算 Var ( w i j x j ) \text{Var}(w_{ij}x_{j}) Var(wijxj):
Var ( w i j x j ) = E [ w i j 2 ] ⏟ = Var ( w i j ) E [ x j 2 ] − E [ w i j ] 2 ⏟ = 0 E [ x j ] 2 = Var ( w i j ) E [ x j 2 ] \text{Var}(w_{ij}x_{j})=\underbrace{\mathbb{E}[w_{ij}^2]}_{=\text{Var}(w_{ij})}\mathbb{E}[x_{j}^2]-\underbrace{\mathbb{E}[w_{ij}]^2}_{=0}\mathbb{E}[x_{j}]^2=\text{Var}(w_{ij})\mathbb{E}[x_{j}^2] Var(wijxj)==Var(wij) E[wij2]E[xj2]−=0 E[wij]2E[xj]2=Var(wij)E[xj2]
如果假设 x x x 是通过ReLU激活函数从前一层的输出得到的,即 x = m a x ( 0 , y ~ ) x=max(0,\tilde{y}) x=max(0,y~)), 可以按照以下方式计算期望值:
E [ x 2 ] = E [ max ( 0 , y ~ ) 2 ] = 1 2 E [ y ~ 2 ] y ~ 是零中心且对称的 = 1 2 Var ( y ~ ) \begin{split} \mathbb{E}[x^2] & =\mathbb{E}[\max(0,\tilde{y})^2]\\ & =\frac{1}{2}\mathbb{E}[{\tilde{y}}^2]\hspace{2cm}\tilde{y}\text{ 是零中心且对称的}\\ & =\frac{1}{2}\text{Var}(\tilde{y}) \end{split} E[x2]=E[max(0,y~)2]=21E[y~2]y~ 是零中心且对称的=21Var(y~)
在方程中有一个额外的 1/2 因子,使得期望的权重方差变为 2 / d x 2/d_x 2/dx. 这给出了Kaiming初始化. 需要注意的是,Kaiming初始化并没有使用输入和输出大小之间的调和平均数。在其论文(第2.2节,反向传播,最后一段)中,他们论证了使用 d x d_x dx or d y d_y dy 都能导致网络中梯度的稳定性,并且仅依赖于整个网络的输入和输出大小。因此,在这种情况下,可以仅使用输入 d x d_x dx:
def kaiming_init(model):
for name, param in model.named_parameters():
if name.endswith(".bias"):
param.data.fill_(0)
elif name.startswith("layers.0"): # 第一层的输入没有应用 ReLU
param.data.normal_(0, 1/math.sqrt(param.shape[1]))
else:
param.data.normal_(0, math.sqrt(2)/math.sqrt(param.shape[1]))
model = BaseNetwork(act_fn=nn.ReLU()).to(device)
kaiming_init(model)
visualize_gradients(model, print_variance=True)
visualize_activations(model, print_variance=True)
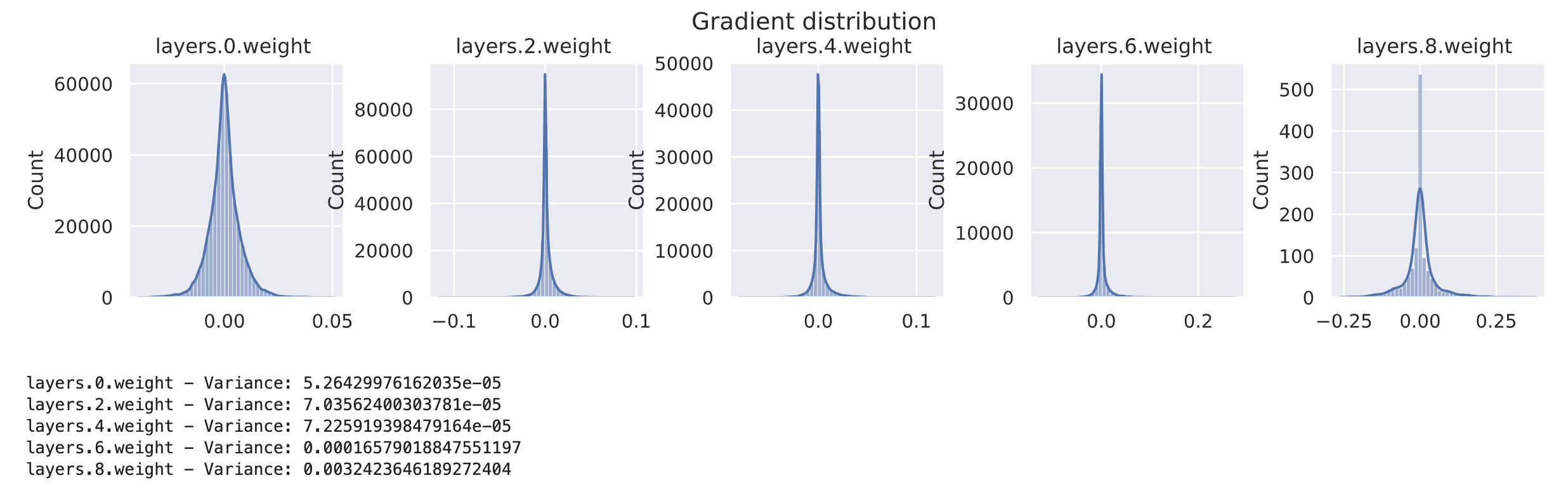
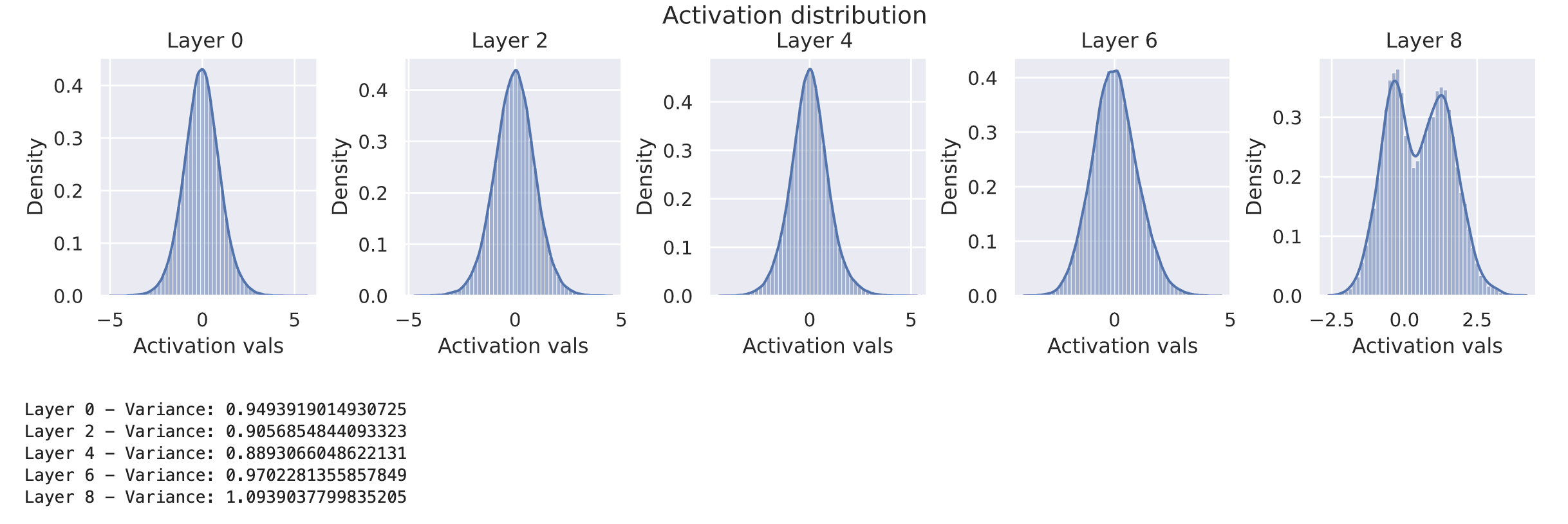
观察到,方差在各层之间保持稳定。这表明Kaiming初始化确实非常适合基于ReLU的网络。需要注意的是,对于Leaky-ReLU等激活函数,由于它们不会将一半的值都设为零,因此需要对方差中的系数2进行适当调整。PyTorch提供了一个名为torch.nn.init.calculate_gain的函数,可以帮助为不同的激活函数计算适当的增益系数.
1.4 模型的优化
除了初始化之外,选择合适的优化算法对于深度神经网络来说也是一个重要的决策。在详细探讨各种优化算法之前,应该定义用于训练模型的代码。
def _get_config_file(model_path, model_name):
return os.path.join(model_path, model_name + ".config")
def _get_model_file(model_path, model_name):
return os.path.join(model_path, model_name + ".tar")
def _get_result_file(model_path, model_name):
return os.path.join(model_path, model_name + "_results.json")
def load_model(model_path, model_name, net=None):
config_file, model_file = _get_config_file(model_path, model_name), _get_model_file(model_path, model_name)
assert os.path.isfile(config_file), f"Could not find the config file \"{config_file}\". Are you sure this is the correct path and you have your model config stored here?"
assert os.path.isfile(model_file), f"Could not find the model file \"{model_file}\". Are you sure this is the correct path and you have your model stored here?"
with open(config_file, "r") as f:
config_dict = json.load(f)
if net is None:
act_fn_name = config_dict["act_fn"].pop("name").lower()
assert act_fn_name in act_fn_by_name, f"Unknown activation function \"{act_fn_name}\". Please add it to the \"act_fn_by_name\" dict."
act_fn = act_fn_by_name[act_fn_name]()
net = BaseNetwork(act_fn=act_fn, **config_dict)
net.load_state_dict(torch.load(model_file))
return net
def save_model(model, model_path, model_name):
config_dict = model.config
os.makedirs(model_path, exist_ok=True)
config_file, model_file = _get_config_file(model_path, model_name), _get_model_file(model_path, model_name)
with open(config_file, "w") as f:
json.dump(config_dict, f)
torch.save(model.state_dict(), model_file)
def train_model(net, model_name, optim_func, max_epochs=50, batch_size=256, overwrite=False):
"""
在 FashionMNIST 的训练集上训练模型
Inputs:
net - BaseNetwork 的对象
model_name - (str) 模型的名称,用于创建检查点名称
max_epochs - (最大)训练的 epoch 数
patience - 如果验证集的性能在 #patience epoch 中没有改善,我们将提前停止训练
batch_size - 训练中使用的批次大小
overwrite - 确定在已存在检查点时如何处理这种情况。如果为 True,则它将被覆盖。
"""
file_exists = os.path.isfile(_get_model_file(CHECKPOINT_PATH, model_name))
if file_exists and not overwrite:
print(f"Model file of \"{model_name}\" 早已存在,跳过训练")
with open(_get_result_file(CHECKPOINT_PATH, model_name), "r") as f:
results = json.load(f)
else:
if file_exists:
print("模型文件存在, 将覆盖")
optimizer = optim_func(net.parameters())
loss_module = nn.CrossEntropyLoss()
train_loader_local = data.DataLoader(train_set, batch_size=batch_size, shuffle=True, drop_last=True, pin_memory=True)
results = None
val_scores = []
train_losses, train_scores = [], []
best_val_epoch = -1
for epoch in range(max_epochs):
############
# 训练 #
############
net.train()
true_preds, count = 0., 0
t = tqdm(train_loader_local, leave=False)
for imgs, labels in t:
imgs, labels = imgs.to(device), labels.to(device)
optimizer.zero_grad()
preds = net(imgs)
loss = loss_module(preds, labels)
loss.backward()
optimizer.step()
true_preds += (preds.argmax(dim=-1) == labels).sum().item()
count += labels.shape[0]
t.set_description(f"Epoch {epoch+1}: loss={loss.item():4.2f}")
train_losses.append(loss.item())
train_acc = true_preds / count
train_scores.append(train_acc)
##############
# 验证 #
##############
val_acc = test_model(net, val_loader)
val_scores.append(val_acc)
print(f"[Epoch {epoch+1:2d}] Training accuracy: {train_acc*100.0:05.2f}%, Validation accuracy: {val_acc*100.0:05.2f}%")
if len(val_scores) == 1 or val_acc > val_scores[best_val_epoch]:
print("\t (New best performance, saving model...)")
save_model(net, CHECKPOINT_PATH, model_name)
best_val_epoch = epoch
if results is None:
load_model(CHECKPOINT_PATH, model_name, net=net)
test_acc = test_model(net, test_loader)
results = {"test_acc": test_acc, "val_scores": val_scores, "train_losses": train_losses, "train_scores": train_scores}
with open(_get_result_file(CHECKPOINT_PATH, model_name), "w") as f:
json.dump(results, f)
sns.set()
plt.plot([i for i in range(1,len(results["train_scores"])+1)], results["train_scores"], label="Train")
plt.plot([i for i in range(1,len(results["val_scores"])+1)], results["val_scores"], label="Val")
plt.xlabel("Epochs")
plt.ylabel("Validation accuracy")
plt.ylim(min(results["val_scores"]), max(results["train_scores"])*1.01)
plt.title(f"Validation performance of {model_name}")
plt.legend()
plt.show()
plt.close()
print((f" Test accuracy: {results['test_acc']*100.0:4.2f}% ").center(50, "=")+"\n")
return results
def test_model(net, data_loader):
net.eval()
true_preds, count = 0., 0
for imgs, labels in data_loader:
imgs, labels = imgs.to(device), labels.to(device)
with torch.no_grad():
preds = net(imgs).argmax(dim=-1)
true_preds += (preds == labels).sum().item()
count += labels.shape[0]
test_acc = true_preds / count
return test_acc
首先,需要理解优化器的实际作用。优化器负责根据梯度更新网络的参数。换句话说,实际上是实现了一个函数 w t = f ( w t − 1 , g t , . . . ) w^{t} = f(w^{t-1}, g^{t}, ...) wt=f(wt−1,gt,...) 其中 w w w 是参数, g t = ∇ w ( t − 1 ) L ( t ) g^{t} = \nabla_{w^{(t-1)}} \mathcal{L}^{(t)} gt=∇w(t−1)L(t) 表示时间步 t t t 处的梯度. 该函数的一个常见附加参数是学习率,记作 η \eta η. 通常,学习率可以看作是更新过程中的“步长”。较高的学习率意味着就会沿着梯度方向对权重做出较大的调整;而较低的学习率则意味着就会采取较小的步长。
由于大多数优化器仅在如何实现更新函数
f
f
f,上有所不同,可以为PyTorch中的优化器定义一个通用模板。这个模板接收模型的参数和学习率作为输入。 zero_grad 函数将所有参数的梯度重置为零,这是在调用loss.backward()之前必须执行的操作。最后, step() 函数指示优化器根据计算出的梯度更新所有权重。以下是模板的具体设置:
class OptimizerTemplate:
def __init__(self, params, lr):
self.params = list(params)
self.lr = lr
def zero_grad(self):
## 将所有参数的梯度设置为零
for p in self.params:
if p.grad is not None:
p.grad.detach_() # 重要,对于二阶优化器
p.grad.zero_()
@torch.no_grad()
def step(self):
## 将更新步骤应用于所有参数
for p in self.params:
if p.grad is None: # We 跳过没有任何梯度的参数
continue
self.update_param(p)
def update_param(self, p):
# 在优化器特定的类中实现
raise NotImplementedError
将要实现的第一个优化器是标准的随机梯度下降(SGD)。SGD使用以下公式来更新参数:
w ( t ) = w ( t − 1 ) − η ⋅ g ( t ) \begin{split} w^{(t)} & = w^{(t-1)} - \eta \cdot g^{(t)} \end{split} w(t)=w(t−1)−η⋅g(t)
正如这个公式所示,SGD实现也非常简单:
class SGD(OptimizerTemplate):
def __init__(self, params, lr):
super().__init__(params, lr)
def update_param(self, p):
p_update = -self.lr * p.grad
p.add_(p_update) # 就地更新 => 节省内存,不创建计算图
将要实现的第一个优化器是标准的随机梯度下降(SGD)。SGD使用以下公式更新参数:
m ( t ) = β 1 m ( t − 1 ) + ( 1 − β 1 ) ⋅ g ( t ) w ( t ) = w ( t − 1 ) − η ⋅ m ( t ) \begin{split} m^{(t)} & = \beta_1 m^{(t-1)} + (1 - \beta_1)\cdot g^{(t)}\\ w^{(t)} & = w^{(t-1)} - \eta \cdot m^{(t)}\\ \end{split} m(t)w(t)=β1m(t−1)+(1−β1)⋅g(t)=w(t−1)−η⋅m(t)
下面是SGD在PyTorch中的具体实现:
class SGDMomentum(OptimizerTemplate):
def __init__(self, params, lr, momentum=0.0):
super().__init__(params, lr)
self.momentum = momentum # 对应于上述方程式中的 beta_1
self.param_momentum = {p: torch.zeros_like(p.data) for p in self.params} # Dict 来存储 m_t
def update_param(self, p):
self.param_momentum[p] = (1 - self.momentum) * p.grad + self.momentum * self.param_momentum[p]
p_update = -self.lr * self.param_momentum[p]
p.add_(p_update)
最后,来看Adam优化器。Adam结合了动量的概念和自适应学习率,后者基于平方梯度的指数平均值,即梯度的范数。此外,为了前几次迭代中的动量和自适应学习率,添加了一个偏差修正:
m ( t ) = β 1 m ( t − 1 ) + ( 1 − β 1 ) ⋅ g ( t ) v ( t ) = β 2 v ( t − 1 ) + ( 1 − β 2 ) ⋅ ( g ( t ) ) 2 m ^ ( t ) = m ( t ) 1 − β 1 t , v ^ ( t ) = v ( t ) 1 − β 2 t w ( t ) = w ( t − 1 ) − η v ^ ( t ) + ϵ ∘ m ^ ( t ) \begin{split} m^{(t)} & = \beta_1 m^{(t-1)} + (1 - \beta_1)\cdot g^{(t)}\\ v^{(t)} & = \beta_2 v^{(t-1)} + (1 - \beta_2)\cdot \left(g^{(t)}\right)^2\\ \hat{m}^{(t)} & = \frac{m^{(t)}}{1-\beta^{t}_1}, \hat{v}^{(t)} = \frac{v^{(t)}}{1-\beta^{t}_2}\\ w^{(t)} & = w^{(t-1)} - \frac{\eta}{\sqrt{\hat{v}^{(t)}} + \epsilon}\circ \hat{m}^{(t)}\\ \end{split} m(t)v(t)m^(t)w(t)=β1m(t−1)+(1−β1)⋅g(t)=β2v(t−1)+(1−β2)⋅(g(t))2=1−β1tm(t),v^(t)=1−β2tv(t)=w(t−1)−v^(t)+ϵη∘m^(t)
epsilon 是一个用于提高数值稳定性的常小值,特别是在梯度范数非常小的情况下。需要注意的是,自适应学习率并不会替代学习率超参数 η \eta η, 而是作为一个额外的因子,确保各个参数的梯度具有相似的范数。
class Adam(OptimizerTemplate):
def __init__(self, params, lr, beta1=0.9, beta2=0.999, eps=1e-8):
super().__init__(params, lr)
self.beta1 = beta1
self.beta2 = beta2
self.eps = eps
self.param_step = {p: 0 for p in self.params}
self.param_momentum = {p: torch.zeros_like(p.data) for p in self.params}
self.param_2nd_momentum = {p: torch.zeros_like(p.data) for p in self.params}
def update_param(self, p):
self.param_step[p] += 1
self.param_momentum[p] = (1 - self.beta1) * p.grad + self.beta1 * self.param_momentum[p]
self.param_2nd_momentum[p] = (1 - self.beta2) * (p.grad)**2 + self.beta2 * self.param_2nd_momentum[p]
bias_correction_1 = 1 - self.beta1 ** self.param_step[p]
bias_correction_2 = 1 - self.beta2 ** self.param_step[p]
p_2nd_mom = self.param_2nd_momentum[p] / bias_correction_2
p_mom = self.param_momentum[p] / bias_correction_1
p_lr = self.lr / (torch.sqrt(p_2nd_mom) + self.eps)
p_update = -p_lr * p_mom
p.add_(p_update)
1.4.1 优化器在模型训练中的比较
在实现了三种优化器(SGD、带有动量的SGD和Adam)之后,现在可以开始分析和比较它们的表现。首先,在FashionMNIST数据集上测试这些优化器优化神经网络的能力。这次实验使用了一个带有ReLU激活函数和Kaiming初始化的线性网络,因为之前的研究表明这种方法对基于ReLU的网络效果很好。值得注意的是,该模型对于这项任务来说是过参数化的,实际上可以用一个更小的网络(例如,每层包含100个节点的三层网络)达到类似的性能。然而,本次实验主要目的是研究优化器在训练深度神经网络时的表现,因此采用了过参数化的设置。
base_model = BaseNetwork(act_fn=nn.ReLU(), hidden_sizes=[512,256,256,128])
kaiming_init(base_model)
为了确保比较的公平性,实验将使用完全相同的模型和随机种子,分别用以下三种优化器进行训练。如果学员想调整超参数,可以自行修改(但这样的话,学员就需要自己来训练模型了)。
SGD_model = copy.deepcopy(base_model).to(device)
SGD_results = train_model(SGD_model, "FashionMNIST_SGD",
lambda params: SGD(params, lr=1e-1),
max_epochs=10, batch_size=256)
SGDMom_model = copy.deepcopy(base_model).to(device)
SGDMom_results = train_model(SGDMom_model, "FashionMNIST_SGDMom",
lambda params: SGDMomentum(params, lr=1e-1, momentum=0.9),
max_epochs=10, batch_size=256)
Adam_model = copy.deepcopy(base_model).to(device)
Adam_results = train_model(Adam_model, "FashionMNIST_Adam",
lambda params: Adam(params, lr=1e-3),
max_epochs=10, batch_size=256)
结果显示,在使用相同模型的情况下,所有优化器的表现都非常相似,差异太小以至于无法得出任何显著的结论。然而,需要注意的是,这也可能与所选择的初始化方法有关。如果将初始化改为较差的方式(例如常数初始化),Adam通常因其自适应学习率而显示出更高的鲁棒性。为了展示各个优化器的具体优势,将继续探讨一些可能导致动量和自适应学习率变得至关重要的损失曲面。
1.4.2 病态曲率
病态曲率是一种类似峡谷的曲面类型,对普通的SGD优化尤其具有挑战性。具体而言,病态曲率在一个方向上有陡峭的梯度,并在中心达到最优值;而在另一个方向上,则存在一个较缓的梯度通向(全局)最优解。首先,创建一个这样的示例曲面并进行可视化:
def pathological_curve_loss(w1, w2):
x1_loss = torch.tanh(w1)**2 + 0.01 * torch.abs(w1)
x2_loss = torch.sigmoid(w2)
return x1_loss + x2_loss
def plot_curve(curve_fn, x_range=(-5,5), y_range=(-5,5), plot_3d=False, cmap=cm.viridis, title="Pathological curvature"):
fig = plt.figure()
ax = plt.axes(projection='3d') if plot_3d else plt.axes()
x = torch.arange(x_range[0], x_range[1], (x_range[1]-x_range[0])/100.)
y = torch.arange(y_range[0], y_range[1], (y_range[1]-y_range[0])/100.)
x, y = torch.meshgrid(x, y, indexing='xy')
z = curve_fn(x, y)
x, y, z = x.numpy(), y.numpy(), z.numpy()
if plot_3d:
ax.plot_surface(x, y, z, cmap=cmap, linewidth=1, color="#000", antialiased=False)
ax.set_zlabel("loss")
else:
ax.imshow(z[::-1], cmap=cmap, extent=(x_range[0], x_range[1], y_range[0], y_range[1]))
plt.title(title)
ax.set_xlabel(r"$w_1$")
ax.set_ylabel(r"$w_2$")
plt.tight_layout()
return ax
sns.reset_orig()
_ = plot_curve(pathological_curve_loss, plot_3d=True)
plt.show()
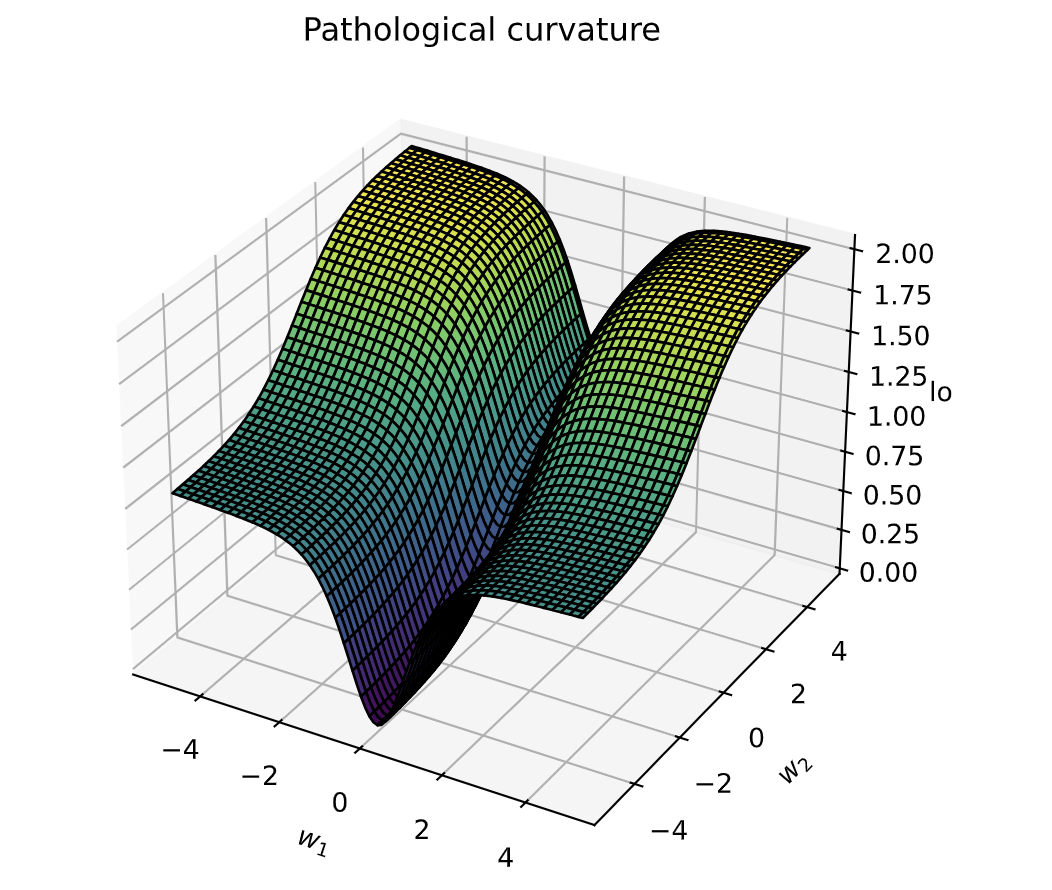
在优化过程中,学员可以想象 w 1 w_1 w1 和 w 2 w_2 w2 是权重参数,而曲率则表示在 w 1 w_1 w1 和 w 2 w_2 w2参数空间上的损失曲面。需要注意的是,在典型的神经网络中,通常有更多的参数(远不止两个),并且这样的曲率也可能出现在多维参数空间中。
理想情况下,优化算法应能找到峡谷的中心,并专注于沿
w
2
w_2
w2方向优化参数。然而,如果处于山脊上的某个点,该点在
w
1
w_1
w1 方向上的梯度会远大于
w
2
w_2
w2方向上的梯度,这可能导致优化过程在两侧之间跳跃。由于梯度较大,需要降低学习率,从而显著减慢学习速度。
(PS:上等学习者的学习知识可以通过类比现实中的场景记忆,需要抽象想象思维。最终极的抽象思考者可以思考到世间不存在的物体,比如牛顿发现了重力等,发明创造者一定是一个很棒的抽象思考者!)
为了测试的算法,可以编写一个简单的函数来在这种曲面上训练两个参数:
def train_curve(optimizer_func, curve_func=pathological_curve_loss, num_updates=100, init=[5,5]):
"""
Inputs:
optimizer_func - 使用的优化器的构造函数。应仅采用参数列表
curve_func - 损失函数(例如病理曲率)
num_updates - 优化时要采取的更新/步骤数
init - 参数的初始值。必须是一个列表/元组,其中包含两个元素,分别表示 w_1 和形状为 [num_updates, 3] w_2
Outputs:
umpy 数组,其中 [t,:2] 是步骤 t 的参数值,[t,2] 是步骤 t 的损失。
"""
weights = nn.Parameter(torch.FloatTensor(init), requires_grad=True)
optimizer = optimizer_func([weights])
list_points = []
for _ in range(num_updates):
loss = curve_func(weights[0], weights[1])
list_points.append(torch.cat([weights.data.detach(), loss.unsqueeze(dim=0).detach()], dim=0))
optimizer.zero_grad()
loss.backward()
optimizer.step()
points = torch.stack(list_points, dim=0).numpy()
return points
接下来,将不同的优化器应用于这个曲率问题。需要注意的是,设置的学习率比在标准神经网络中使用的要高得多。这是因为在这里只有两个参数,而在典型的神经网络中有成千上万甚至数百万个参数。
SGD_points = train_curve(lambda params: SGD(params, lr=10))
SGDMom_points = train_curve(lambda params: SGDMomentum(params, lr=10, momentum=0.9))
Adam_points = train_curve(lambda params: Adam(params, lr=1))
为了更好地理解不同优化算法的工作机制,将每个更新步骤可视化为损失曲面上的一条折线图。为了保证图表的可读性,将使用二维表示。
all_points = np.concatenate([SGD_points, SGDMom_points, Adam_points], axis=0)
ax = plot_curve(pathological_curve_loss,
x_range=(-np.absolute(all_points[:,0]).max(), np.absolute(all_points[:,0]).max()),
y_range=(all_points[:,1].min(), all_points[:,1].max()),
plot_3d=False)
ax.plot(SGD_points[:,0], SGD_points[:,1], color="red", marker="o", zorder=1, label="SGD")
ax.plot(SGDMom_points[:,0], SGDMom_points[:,1], color="blue", marker="o", zorder=2, label="SGDMom")
ax.plot(Adam_points[:,0], Adam_points[:,1], color="grey", marker="o", zorder=3, label="Adam")
plt.legend()
plt.show()
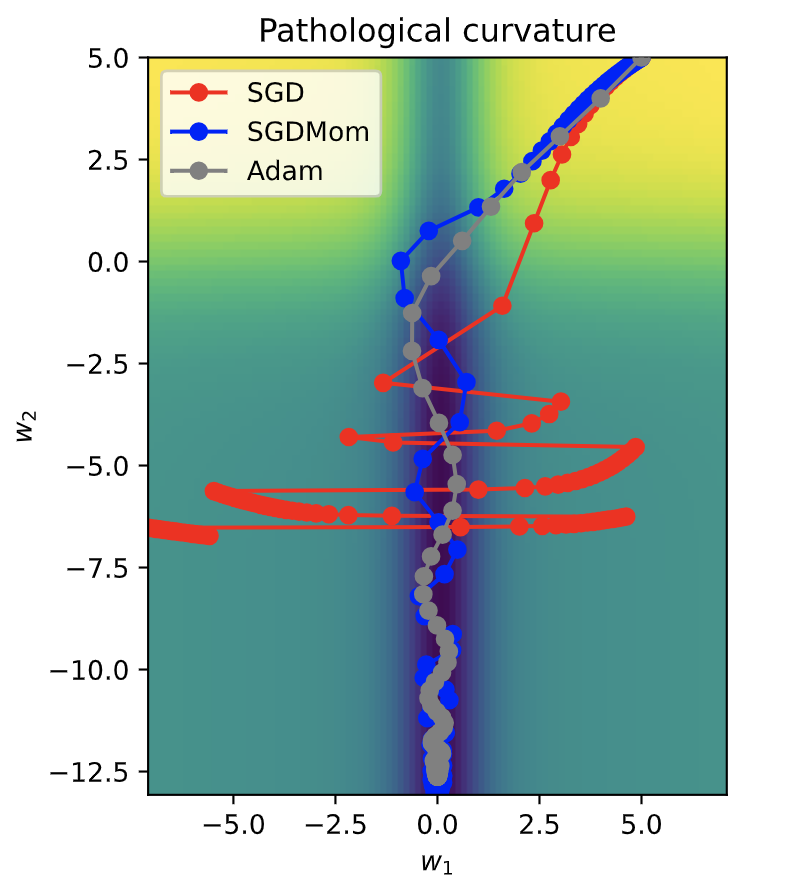
从图中可以明显看出,SGD 由于在 w 1 w_1 w1方向上存在陡峭的梯度,难以找到优化路径的中心位置,导致收敛困难。相反,Adam 和带有动量的 SGD 则能很好地收敛,因为 w 1 w_1 w1 方向上的梯度变化能够相互抵消。在这种类型的曲面上,使用动量机制显得尤为重要。
1.4.3 陡峭的最优值
第二种具有挑战性的损失曲面是陡峭的最优值曲面。在这种曲面上,大部分区域的梯度都非常小,但在最优值附近却存在非常大的梯度。例如,考虑以下损失曲面的情况:
def bivar_gaussian(w1, w2, x_mean=0.0, y_mean=0.0, x_sig=1.0, y_sig=1.0):
norm = 1 / (2 * np.pi * x_sig * y_sig)
x_exp = (-1 * (w1 - x_mean)**2) / (2 * x_sig**2)
y_exp = (-1 * (w2 - y_mean)**2) / (2 * y_sig**2)
return norm * torch.exp(x_exp + y_exp)
def comb_func(w1, w2):
z = -bivar_gaussian(w1, w2, x_mean=1.0, y_mean=-0.5, x_sig=0.2, y_sig=0.2)
z -= bivar_gaussian(w1, w2, x_mean=-1.0, y_mean=0.5, x_sig=0.2, y_sig=0.2)
z -= bivar_gaussian(w1, w2, x_mean=-0.5, y_mean=-0.8, x_sig=0.2, y_sig=0.2)
return z
_ = plot_curve(comb_func, x_range=(-2,2), y_range=(-2,2), plot_3d=True, title="Steep optima")
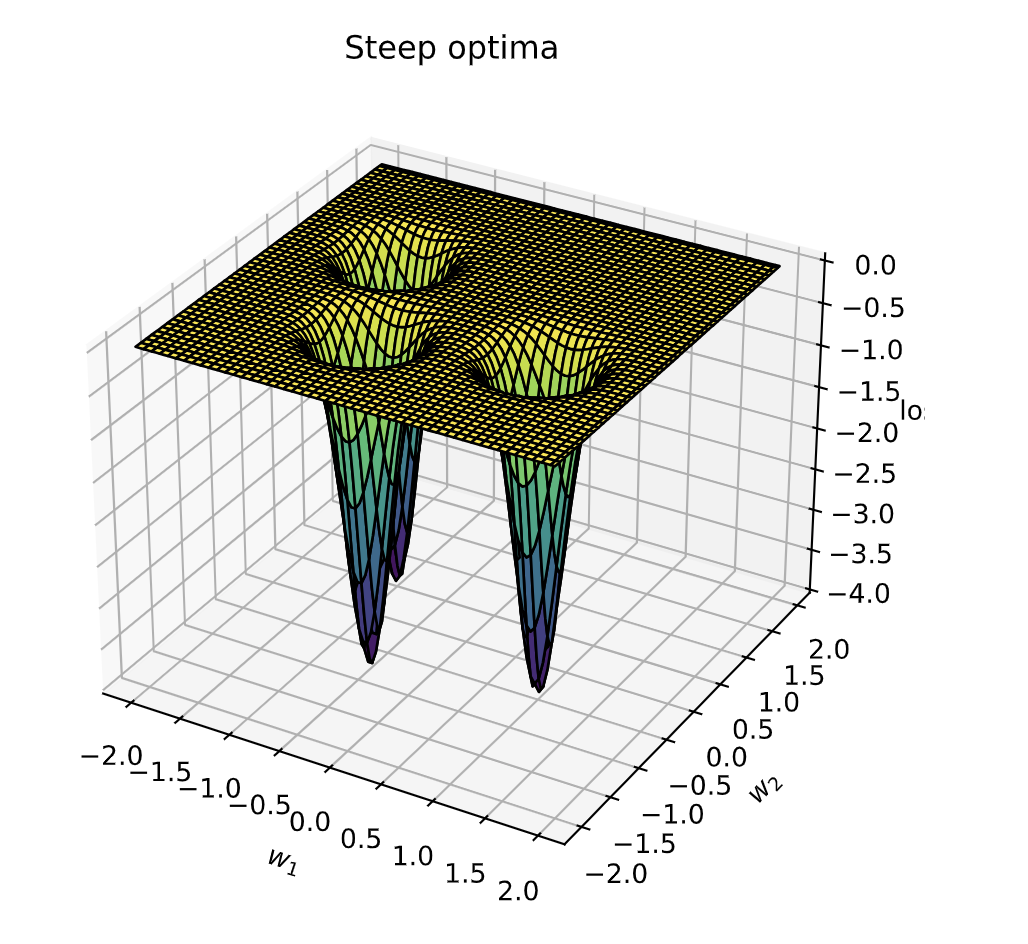
大部分损失曲面区域的梯度都非常小甚至几乎没有梯度。然而,在接近最优值的地方,梯度却变得非常陡峭。因此,当从梯度较低的区域开始优化时,预计自适应学习率将是达到最小值的关键因素。为了验证这一假设,可以在这种曲面上运行三种优化器,并观察它们的表现。
SGD_points = train_curve(lambda params: SGD(params, lr=.5), comb_func, init=[0,0])
SGDMom_points = train_curve(lambda params: SGDMomentum(params, lr=1, momentum=0.9), comb_func, init=[0,0])
Adam_points = train_curve(lambda params: Adam(params, lr=0.2), comb_func, init=[0,0])
all_points = np.concatenate([SGD_points, SGDMom_points, Adam_points], axis=0)
ax = plot_curve(comb_func,
x_range=(-2, 2),
y_range=(-2, 2),
plot_3d=False,
title="Steep optima")
ax.plot(SGD_points[:,0], SGD_points[:,1], color="red", marker="o", zorder=3, label="SGD", alpha=0.7)
ax.plot(SGDMom_points[:,0], SGDMom_points[:,1], color="blue", marker="o", zorder=2, label="SGDMom", alpha=0.7)
ax.plot(Adam_points[:,0], Adam_points[:,1], color="grey", marker="o", zorder=1, label="Adam", alpha=0.7)
ax.set_xlim(-2, 2)
ax.set_ylim(-2, 2)
plt.legend()
plt.show()
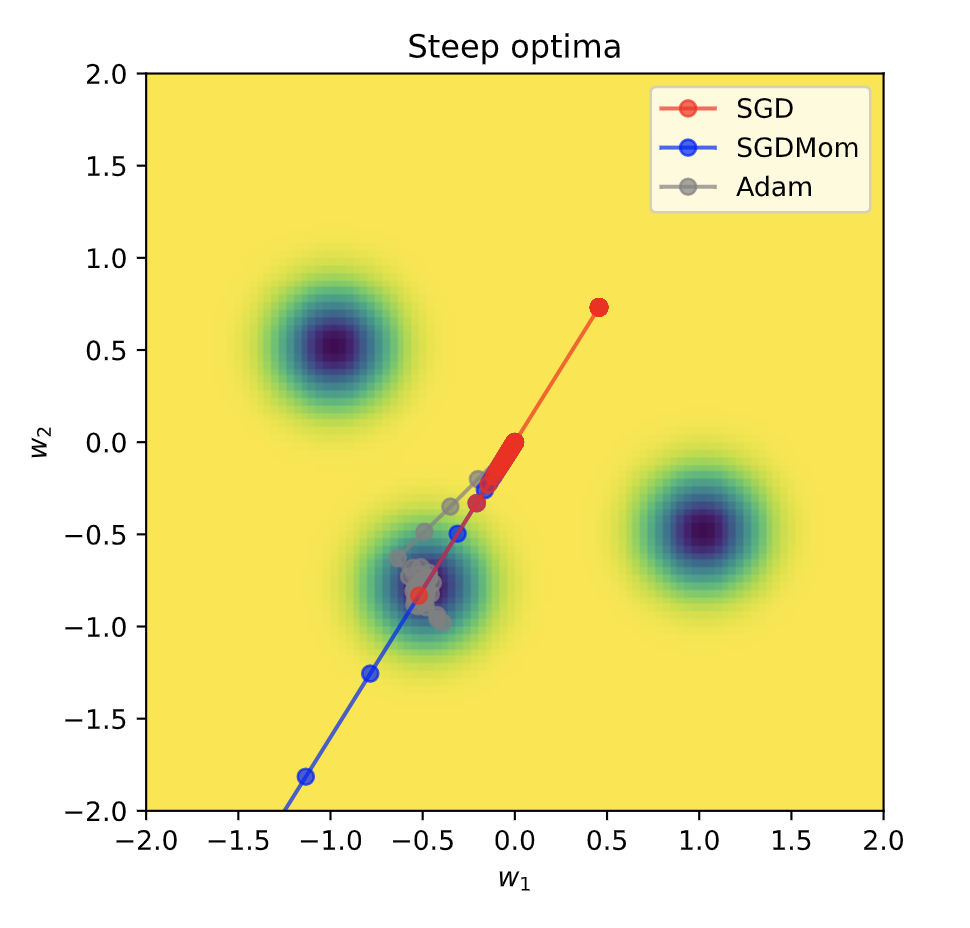
SGD首先会以非常小的步伐前进,直到它触及最优值的边界。首次到达大约
(
−
0.75
,
−
0.5
)
(-0.75,-0.5)
(−0.75,−0.5) 的位置时,梯度方向发生了变化,并将参数推向了
(
0.8
,
0.5
)
(0.8,0.5)
(0.8,0.5) 从这一点开始,SGD无法再恢复(除非经过非常多步)。带有动量的SGD也有类似的问题,只是它继续沿最初触碰最优值的方向前进。该时间点上的梯度比其他任何点都大得多,以至于动量
m
t
m_t
mt 被其主导。最终,Adam能够收敛到最优值,这展示了自适应学习率的重要性。
如何选择优化器
在观察了各种优化器的表现之后,应该如何选择合适的优化器呢?是否应该始终使用Adam而完全放弃SGD?答案是否定的。实际上,有研究表明,在特定情况下,SGD(尤其是带有动量的SGD)在模型泛化方面表现更好,而Adam往往更容易导致过拟合。这种差异与寻找“更宽”的最优解有关。
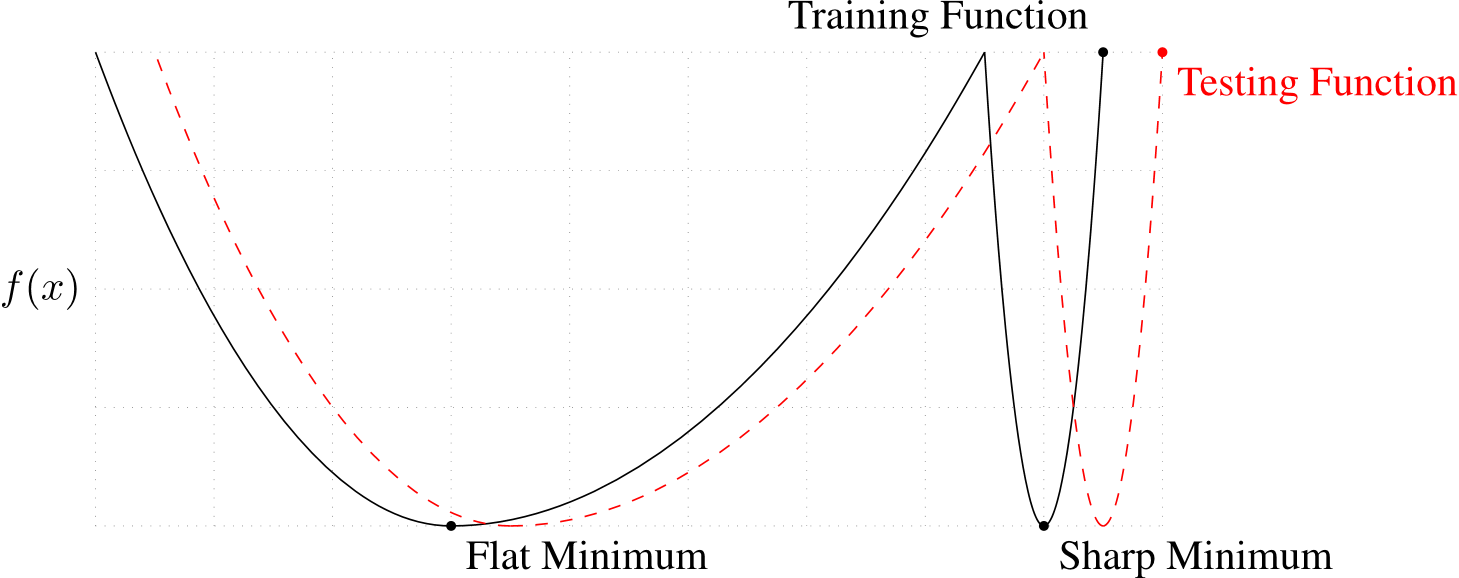
黑色实线代表训练损失曲面,红色虚线则表示测试损失。寻找尖锐且狭窄的最小值有助于降低训练损失。然而,这并不意味着它同样能最小化测试损失,因为平坦的最小值往往表现出更好的泛化能力。由于测试数据集中的样本与训练集中的样本有所不同,测试数据集的损失曲面可能会有轻微的偏移。对于尖锐的最小值,即使是很小的变化也可能对其产生显著影响;相比之下,平坦的最小值通常更能抵抗这种变化,因此更加稳健。
1.5 总结
在本课程中,探讨了神经网络的初始化和优化技术。良好的初始化需要平衡梯度方差和激活值方差的保持。对于基于tanh的网络,可以通过Xavier初始化方法实现这一点;而对于基于ReLU的网络,则可以使用Kaiming初始化方法。在优化方面,动量和自适应学习率等概念可以帮助优化器更好地处理复杂的损失曲面,但这并不保证一定能提高神经网络的性能。这些技术的主要作用在于改善训练过程中的稳定性和效率。在实际应用中,选择合适的初始化方法和优化器是构建高效、稳定神经网络的关键步骤。不同任务可能需要不同的配置,因此理解各种技术背后的原理及其适用场景是非常重要的。
- PyTorch基础与异或问题实践
- 激活函数与神经网络优化
- 数据预处理与模型优化:FashionMNIST实验
- 经典CNN架构与PyTorch Lightning实践
- Transformers与多头注意力机制实战
- 深度能量模型与PyTorch实践
- 图神经网络
- 自编码器与神经网络应用
- 深度归一化流图像建模与实践
- 自回归图像建模与像素CNN实现
- Vision Transformers with PyTorch Lightning on昇腾
- ProtoNet与ProtoMAML元学习算法实践
- SimCLR与Logistic回归在自我监督学习中的应用


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









