



句法分析:构建语言的结构
学习目标
通过本实验的学习,学员将掌握句法分析的基本概念,了解如何使用NLTK库进行句子的句法结构分析,包括依存关系分析和短语结构树的构建。实验将通过理论讲解与实践操作相结合的方式,帮助学员深入理解句法分析在自然语言处理中的应用。
相关知识点
- NLTK句法分析
学习内容
1 NLTK句法分析
1.1 句法分析基础
句法分析是自然语言处理中的一个核心任务,它涉及分析句子的结构,以理解句子中各个成分之间的关系。句法分析可以帮助理解句子的深层含义,对于机器翻译、情感分析、信息提取等应用具有重要意义。
句法分析主要分为两种类型:短语结构分析(Phrase Structure Parsing)和依存关系分析(Dependency Parsing)。短语结构分析关注的是句子的层次结构,通过构建短语结构树来表示句子的组成部分及其关系。而依存关系分析则侧重于句子中词汇之间的直接关系,通过构建依存树来表示这些关系。
在自然语言处理中,句法分析是连接语言形式和意义的桥梁。通过句法分析,可以更准确地理解文本内容,为后续的语义分析和应用提供基础。例如,在机器翻译中,句法分析可以帮助翻译系统更好地理解源语言句子的结构,从而生成更准确的目标语言句子。
1.2 使用NLTK进行短语结构树构建
NLTK(Natural Language Toolkit)是一个强大的Python库,用于处理自然语言数据。它提供了丰富的工具和资源,可以用于文本处理、分词、词性标注、句法分析等任务。在本实验中,将学习如何使用NLTK进行短语结构树的构建。
安装NLTK:
首先,确保环境中已经安装了NLTK。如果还没有安装,可以通过以下命令进行安装:
%pip install nltk
#下载相关依赖离线包
!wget https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_codes/92a7b1422fdd11f0820ffa163edcddae/en_core_web_sm-3.7.1-py3-none-any.whl
!wget https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_datasets/8d13c5dc50de11f09bedfa163edcddae/nltk_data.zip
#解压数据
!unzip nltk_data.zip
导入必要的模块:
接下来,需要导入构建短语结构树所需的模块:
import nltk
from nltk import pos_tag, word_tokenize
from nltk.tree import Tree
构建短语结构树:
构建短语结构树的第一步是对句子进行分词和词性标注。NLTK提供了word_tokenize和pos_tag函数,可以方便地完成这两个任务。例如,对于句子“John saw the man with a telescope”,可以这样处理:
nltk.data.path.append('./nltk_data')
sentence = "John saw the man with a telescope"
tokens = word_tokenize(sentence)
tags = pos_tag(tokens)
print(tags)
输出结果将是:
[('John', 'NNP'), ('saw', 'VBD'), ('the', 'DT'), ('man', 'NN'), ('with', 'IN'), ('a', 'DT'), ('telescope', 'NN')]
接下来,需要定义一个文法(Grammar),用于指导短语结构树的构建。NLTK允许使用上下文无关文法(Context-Free Grammar, CFG)来定义文法。例如,可以定义一个简单的文法:
grammar = """
NP: {<DT|PP\$>?<JJ>*<NN.*>+} # Chunk sequences of DT, JJ, NN
PP: {<IN><NP>} # Chunk prepositions followed by NP
VP: {<VB.*><NP|PP|CLAUSE>+$} # Chunk verbs and their arguments
"""
使用这个文法,可以构建一个短语结构树:
cp = nltk.RegexpParser(grammar)
result = cp.parse(tags)
print(result)
输出结果将是:
(S
(NP John/NNP)
(VP saw/VBD
(NP the/DT man/NN)
(PP with/IN (NP a/DT telescope/NN))))
1.2.4 可视化短语结构树
为了更好地理解短语结构树,可以使用NLTK提供的Tree类来可视化树结构:
result.pretty_print()
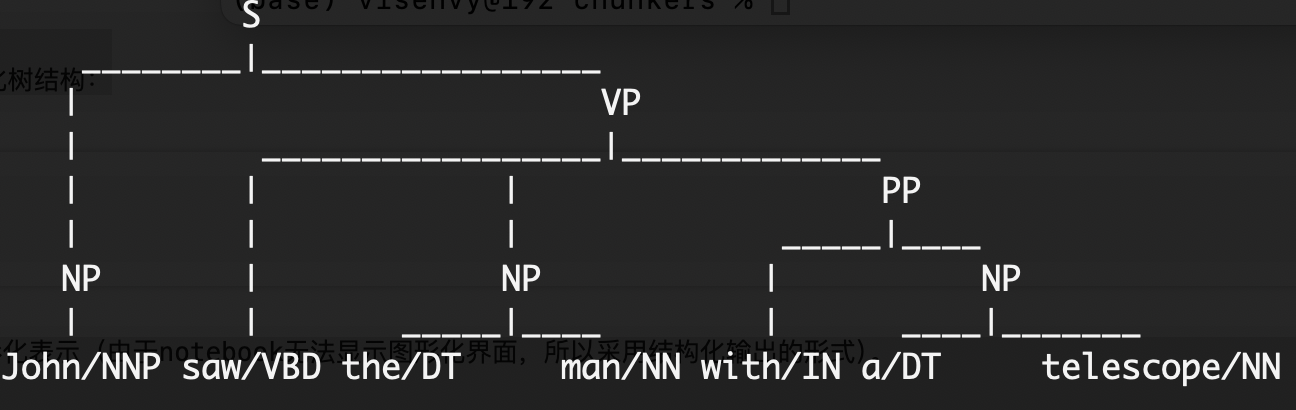
运行result.draw()代码,将弹出一个窗口,显示短语结构树的图形化表示(由于notebook无法显示图形化界面,所以采用结构化输出的形式)。
1.3 依存关系分析
依存关系分析是另一种重要的句法分析方法,它关注句子中词汇之间的直接关系。与短语结构树不同,依存关系树通过有向边表示词汇之间的依存关系,每个节点代表一个词汇,边的方向表示依存关系的方向。
使用NLTK进行依存关系分析:
NLTK本身不直接支持依存关系分析,但可以使用其他库(如spaCy)来完成这一任务。首先,确保已经安装了spaCy和相应的语言模型:
%pip install spacy==3.7.5
%pip install en_core_web_sm-3.7.1-py3-none-any.whl
导入必要的模块:
接下来,需要导入spaCy的模块:
import spacy
进行依存关系分析:
使用spaCy进行依存关系分析非常简单。首先,加载预训练的语言模型:
nlp = spacy.load("en_core_web_sm")
然后,对句子进行处理并提取依存关系:
sentence = "John saw the man with a telescope"
doc = nlp(sentence)
for token in doc:
print(f"{token.text} -> {token.dep_} -> {token.head.text}")
输出结果将是:
John -> nsubj -> saw
saw -> ROOT -> saw
the -> det -> man
man -> dobj -> saw
with -> prep -> saw
a -> det -> telescope
telescope -> pobj -> with
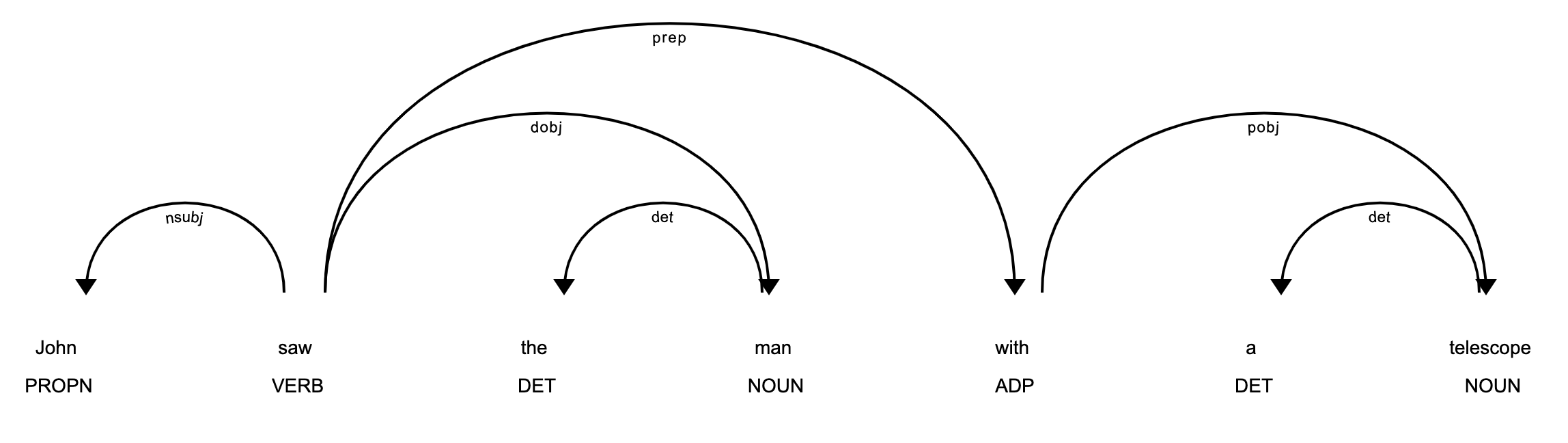
可视化依存关系树:
为了更好地理解依存关系树,可以使用spaCy的可视化工具displacy:
from spacy import displacy
displacy.render(doc, style="dep", jupyter=True)


















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









