




D. Muniraj, K. G. Vamvoudakis, and M. Farhood, “Enforcing Signal Temporal Logic Specifications in Multi-Agent Adversarial Environments: A Deep Q-Learning Approach,” in 2018 IEEE Conference on Decision and Control (CDC), 2018, pp. 4141–4146. doi: 10.1109/CDC.2018.8618746.
Outline
-
用funnel-based解决tractability问题,同时顾及了robustness
-
适用于任意非线性系统
-
使用DQN强化学习算法
-
适用于以下STL约束F/G/FG
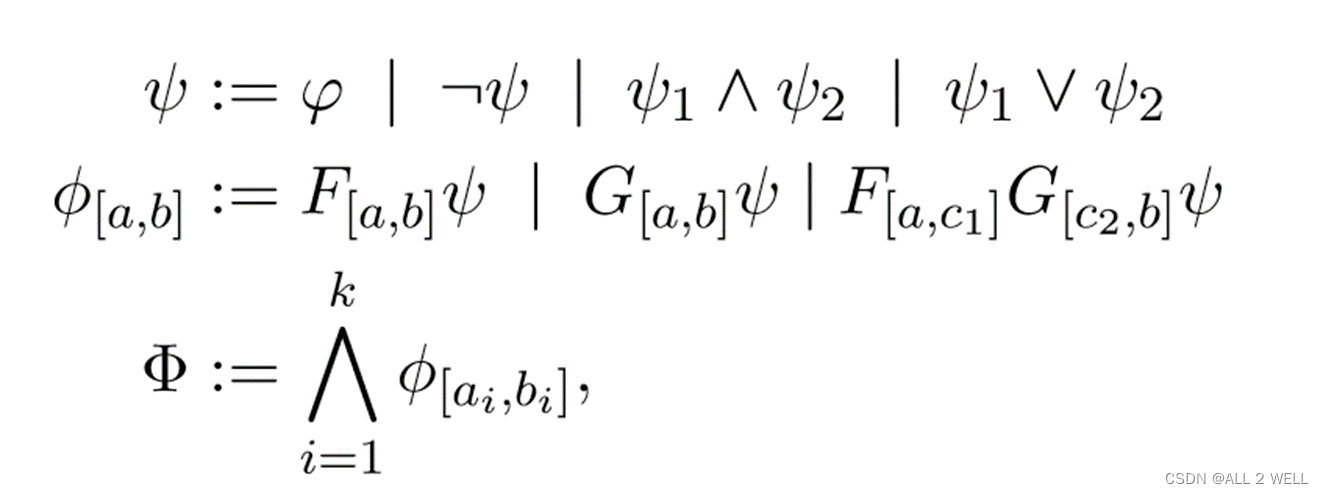
(Saxena et al., 2022, p. 4)
Remark
-
不用把所有的历史信息放入决策过程中,只用到了当前状态的鲁棒度和时间
-
Funnel相当于是用一种启发式的方法限制了robustness的大小,对于eventually这样的算子强行启发出了过零点,有一点点扯
-
强化学习的作用不是很清晰,reward看起来给的是单步reward,但是funnel函数中存在需要整条轨迹才能确定的参数
-
所谓的time-aware不过是reward函数中存在与时间相关的参数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









