




 本文探讨了自监督学习(SSL)在野生动物识别中的应用,特别是利用预训练任务(如图片旋转、上色和补全)进行特征学习。MoCo作为一种对比学习方法,通过查询和键向量的对比优化特征表示。CLD则通过实例聚类改进无监督学习。实验表明,自监督预训练能有效减少标注需求,且在下游任务中表现优于传统的监督预训练。此外,文章还介绍了Kuzikus Wildlife Dataset在预训练和长尾分布情况下的使用策略。
本文探讨了自监督学习(SSL)在野生动物识别中的应用,特别是利用预训练任务(如图片旋转、上色和补全)进行特征学习。MoCo作为一种对比学习方法,通过查询和键向量的对比优化特征表示。CLD则通过实例聚类改进无监督学习。实验表明,自监督预训练能有效减少标注需求,且在下游任务中表现优于传统的监督预训练。此外,文章还介绍了Kuzikus Wildlife Dataset在预训练和长尾分布情况下的使用策略。
目录
二、SSL(self- supervised learning) framework
2.2 Kuzikus Wildlife Dataset Pre-training (KWD-Pre)
2.3 Kuzikus Wildlife Dataset Long-Tail distributed (KWD-LT)
一、key-word
self-supervised pretraining(Pretext task)、MoCo、CLD
1.1 Pretext task
是一种为达到特定训练任务而设计的间接任务。比如训练一个网络来对ImageNet分类,可以表达为 f θ ( x ) : x → y ,目的是获得具有语义特征提取/推理能力的 θ。假设有另外一个任务(也就是pretext),它可以近似获得这样的[公式],比如,Auto-encoder(AE),表示为: g θ ( x ) : x → x 。为什么AE可以近似 θ 呢?因为AE要重建 x就必须学习 x中的内在关系,而这种内在关系的学习又是有利于我们学习 [公式]的。这种方式也叫做预训练,为了在目标任务上获得更好的泛化能力,一般还需要进行fine-tuning(微调)等操作。
因此,Pretext task的好处就是简化了原任务的求解,在深度学习里就是避免了人工标记样本,实现无监督的语义提取,下面进一步解释。
Pretext任务可以进一步理解为:对目标任务有帮助的辅助任务。而这种任务目前更多的用于所谓的Self-Supervised learning,即一种更加宽泛的无监督学习。这里面涉及到一个很强的动机:训练深度学习需要大量的人工标注的样本,这是费时耗力的。而自监督的提出就是为了打破这种人工标注样本的限制,目的是在没有人工标注的条件下也能高效的训练网络,自监督的核心问题是如何产生伪标签(Pseudo label),而这种伪标签的产生是不涉及人工的,比如上述的AE的伪标签就是 [公式] 自身。举几个在视觉任务里常用的pretext task伪标签的产生方式:
·Rotation(图片旋转)
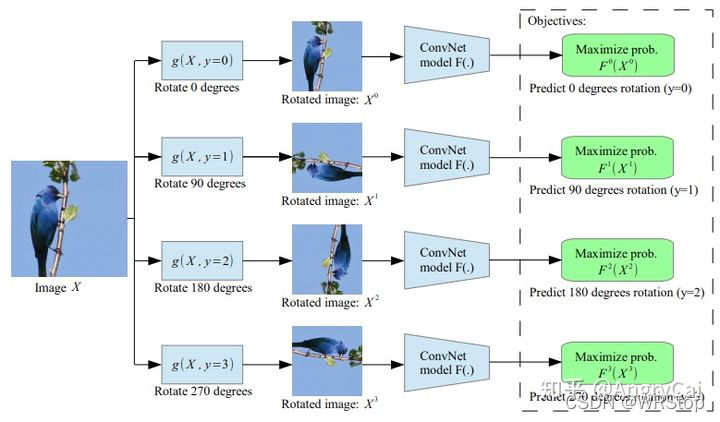
[1] S. Gidaris, P. Singh, and N. Komodakis, “Unsupervised representation learning by predicting image ro
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









