 机器人智能系统的工程化方法
机器人智能系统的工程化方法





第一部分 总览与工程化指南
第1章 摘要与阅读指引
机器人技术正处在一个深刻的变革期,其核心驱动力源于计算能力的跃升、海量数据的可得性以及深度学习模型的结构性突破。这场变革重塑了从基础感知、智能决策到精确执行的全技术链条。本章系统回顾基于学习的机器人技术在范式上的核心演进,重点论证并推导三大支柱:基础模型与多模态策略框架、生成式轨迹与动作分布建模、以及从视频到技能的大数据管线。每一节均给出必要的理论依据与形式化表达,为后续章节的原理与工程实现提供可直接引用的教材级内容。
1.1 核心范式速览(概念与形式化)
当前范式的本质性转变可形式化为从模块化流水线向联合概率建模与序列生成的迁移。传统“感知–规划–控制”框架通过分段优化降低问题复杂度,但在开放世界中易受信息瓶颈与误差累积影响;相对地,学习驱动的基础模型通过直接建模条件分布

下面分三个子节形式化并推导关键原理与工具。
1.1.1 基础模型与多模态策略框架(理论与结构化推导)
一、从模块化到联合序列建模的数学动因

二、自注意力与跨模态交互的形式化

三、序列化策略的概率分解与训练目标

若动作为连续变量,则可将条件概率用高斯、混合高斯或生成模型(见下节)建模,并相应使用对数似然或似然下界进行优化。
四、跨模态表征学习的理论收益
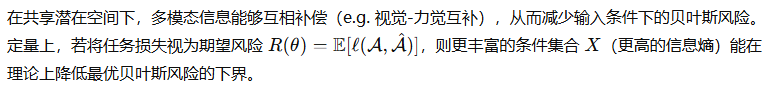
1.1.2 生成式轨迹与动作分布建模(模式多样性的形式化与方法学)
一、模式平均问题的形式化证明

二、生成式模型的概率框架

三、扩散策略(Diffusion Policy)的基本推导要点

四、进行开发时的注意事项(鲁棒性与实时性)
生成式方法往往计算开销更大。工程上常采用:
-
将生成模型输出作为高层候选轨迹,结合快速低层控制器(MPC、跟踪控制)进行实时执行;
-
使用蒸馏(distillation)将高容量生成模型压缩为轻量策略以满足实时性;
-
在动态障碍下对生成分布做快速筛选(collision check)与重采样。
1.1.3 从视频到技能的大数据管线(系统工程与数学建模)
一、问题陈述与挑战形式化

二、总体管线的数学形式化
设计复合损失函数以融合三类数据源(真实专家、仿真示范、网络视频伪标注):

混合系数 λ\lambdaλ 反映数据质量与置信度,可根据验证集进行贝叶斯或交叉验证调整。
三、关键组件与形式化方法


四、蒸馏与最终部署流程

1.2 本书的使用模式与检索策略(结构化工程指南)
为帮助读者在研究与工程实践中高效检索与复现方法,书中采用“问题—证据—方案—配方”的组织原则,并在每个关键技术点后提供实验卡、工程配方与清单。其组织逻辑为:
-
问题(Problem Statement):明确工程背景、约束与评价指标。
-
证据(Evidence):列举理论推导、先验知识与实证结果,指出方案成立的条件与限制。
-
方案(Solution):给出算法、架构与关键实现细节(含伪代码与复杂度分析)。
-
配方(Recipe):提供详细的工程实施清单,包括数据收集、超参建议、硬件规格与常见陷阱的解决办法。
每个章节末尾附 实验卡(step-by-step)、工程清单(checklist)与复现实验配置(包括随机种子、数据分割、评估指标定义),以保证结果的可复现性与落地可行性。
1.3 目标读者与预期先决知识(定位与阅读路径)
本书面向高级研发人员、研究学者与希望将最前沿学习方法工程化的系统工程师。为充分理解本书内容,建议具备如下先决知识:
-
数学基础:线性代数(矩阵分解、奇异值分解)、概率论与统计(条件概率、马尔可夫性、KL 散度)、优化理论(凸优化基础、随机梯度方法);
-
机器学习:监督学习、无监督学习、自监督学习、生成模型(VAE、GAN、Diffusion)、深度强化学习基础;
-
机器人学基础:运动学、动力学、控制理论(PID、MPC)、传感器与嵌入式系统基础。
1.3.1 面向高级研发人员的阅读层次(建议)
-
完全阅读路径:适用于希望从理论到工程实现全面掌握的读者,按章节顺序深入研读并完成实验卡。
-
专项路径:若读者熟悉机械与控制基础,可直接跳转至第二部分(多模态策略)与第四部分(生成式轨迹建模)以快速掌握前沿学习方法。
-
快速回顾:书中提供关键概念索引与符号对照表,便于在查阅具体工程问题时快速检索所需理论或公式。
1.3.2 快速回顾材料的定位与跳读路径(实践建议)
-
需要工程实现与调试:先读第1章(本章)、第2章(基础模型设计)与相关实验卡。
-
关注生成式策略与轨迹:先读第1.1.2 节、第四部分(生成式轨迹)与扩散策略实战章节。
-
目标为大规模训练与数据工程:跳读第1.1.3 节以及大数据管线与数据治理章节。
小结(教材级要点回顾)
-
范式转变:从模块化“感知—规划—控制”向联合、多模态、序列化的基础模型过渡是应对开放世界与任务多样性的理论必然。
-
分布建模的重要性:生成式策略(VAE/GAN/Diffusion)从概率建模角度解决了多模态动作空间的内在歧义,避免了均方回归带来的模式平均问题。
-
数据策略的工程化:海量被动视频的利用依赖于自监督世界模型、伪标注/逆推断与域差减小技术;最终通过混合训练与蒸馏实现可部署策略。
-
可复现与工程化:书中采用“问题—证据—方案—配方”结构,并在每章提供实验卡与工程清单,以确保理论能在现实系统中落地。
第二部分 机器人基础模型与多模态策略
2.1 架构范式与模块化设计(详尽推导)
本节对 编码器—中间表示—解码器三段式架构、层次化条件化与控制接口设计、以及 模型可解释层与安全回退层 的理论基础与严格推导进行系统阐述。目标是用可复现的数学推导把工程直觉变为可证明的设计准则,便于在教材或工程手册中直接引用。
2.1.1 编码器—中间表示—解码器三段式架构
目标与符号约定

信息论视角:信息瓶颈与充分统计量

表征容量与函数近似:解码器可逼近性

融合算子 ggg 的设计:注意力与加权融合

训练目标的构成与期望风险分解

2.1.2 层次化条件化与控制接口设计
层次化控制的形式化(选项框架与半马尔可夫建模)

分层接口的条件化与可组合性条件

满足上述条件,高层决策可独立设计且可组合。否则高层将面临不可预测的状态转移,从而导致任务失败或需要昂贵的联合训练。
层次化条件化的概率分解与学习目标

接口设计的工程准则(来自不等式与稳定性)

2.1.3 模型可解释层与安全回退层设计
一、可解释层:定义、度量与理论属性

注意力权重与因果解释的界限
若解释基于注意力权重 αi\alpha_iαi,严格的数学事实是注意力并非因果贡献的证明:存在构造性反例(不同注意力分配可导致相同输出)。因此需要把注意力解释作为“相关性”证据,并与输入干预实验(causal interventions)结合以验证因果性。
二、安全回退层:可证明的安全性条件与实现


三、可解释性与安全性的协同机制

2.2 预训练范式与数据策略(详尽推导)
本节系统推导多来源示范数据整合、合成/仿真/现实示范的融合策略,以及可操作的数据质量量化与治理流程。所有推导以概率论、统计学习理论与优化理论为基础,目的是把工程直觉形式化为可证明的准则与算法,便于在教材中直接引用与实现。
2.2.1 多来源示范数据的整合方法
问题形式化

重要性重加权(Importance Weighting)与密度比估计

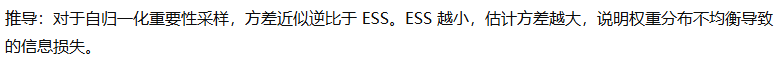
目标风险的上界(域适应视角)

混合损失与自适应加权训练

鲁棒性:对标签噪声与偏差的处理

2.2.2 合成数据、仿真示范与现实示范的融合策略
问题陈述与基本原理

域随机化的理论说明

域对齐(MMD 与对抗)推导

将仿真与现实数据结合的算法架构

蒸馏与混合训练的偏差-方差权衡

2.2.3 数据质量量化指标与治理流程
一、数据质量量化指标(可度量与可估计)

二、数据治理流程(工程化步骤与数学支撑)

三、基于隐变量的质量估计与 EM 算法(示例推导)

四、异常检测与影响函数在治理中的应用

五、合规性、隐私与伦理注意
数据治理必须纳入合规性检查(隐私、许可、去标识化)。在大规模视频来源(互联网视频)使用时,记录来源许可与个人可识别信息处理流程,若存在受保护群体,应做额外审查并在模型行为中加入保护性约束(公平性评估)。
小结(理论要点与工程准则)
-
整合策略的数学基石:重要性重加权、域适应上界与混合训练损失构成多源整合的理论骨架。正确估计或控制分布比、域差异与样本质量是成功整合的前提。
-
仿真/合成/现实的融合:通过域随机化扩大支持、通过 MMD/对抗缩小特征差异、通过重要性重加权校正偏差,结合蒸馏与微调完成从大规模仿真到小规模真实的能力迁移。
-
数据质量治理为核心工程问题:用 ESS、分布差异度量、噪声率估计、影响函数等可量化指标指导样本选择与加权;以 EM/贝叶斯层次模型等方法估计样本置信度;以审计与可追溯管线保证可复现与合规。
2.3 微调、蒸馏与边缘部署策略
本节将以数学与理论推导为主线,系统阐明任务微调(fine-tuning)与冻结(freeze)策略的本质差别与取舍、知识蒸馏、结构剪枝与量化的原理与误差界、以及混合云-边缘推理架构与回退机制的建模与最优决策准则。所有公式均以概率、优化与控制理论为基础,旨在为教材中算法原理章节提供可直接引用的证明与工程化准则。
2.3.1 任务微调与冻结策略比较(理论推导)
问题形式化与目标

偏差—方差视角(样本复杂度的定量化)

Fisher 信息 / EWC 视角(选择冻结参数的精确化)

收敛性与学习率调整的数学建议

实践准则(可证明的经验法则)

2.3.2 知识蒸馏、结构剪枝与量化实践(原理与误差界)
(一)知识蒸馏(Knowledge Distillation):原理与收敛性
体系化表达与损失

为什么蒸馏有效(理论解释)

梯度尺度与温度项的推导

蒸馏的泛化效应(简化证明草图)

(二)结构剪枝(Pruning):二阶导数视角与重要性量化
Taylor 二阶近似与 OBS(Optimal Brain Surgeon)

简化的幅值剪枝与经验解释

结构剪枝(filter/channel level)与硬件友好性
剪掉单独权重产生稀疏矩阵,硬件加速有限;结构剪枝(删除整个卷积过滤器或通道)通过减少计算图的维度带来真实推理加速。对结构剪枝的理论可通过对层输出范数影响的敏感度分析:衡量删除过滤器 jjj 对后续层输入分布与损失的影响并以此为重要性指标。
迭代剪枝与微调
Prune→Fine-tune 循环常用于恢复剪枝后性能。理论上,迭代剪枝能逐步移除对误差影响小的参数并允许微调补偿,提高最终稀疏率下的性能。实证与理论(压缩/近似理论)表明逐步剪枝优于一次性大规模剪枝。
(三)量化(Quantization):误差分析与训练方法
离散化模型与误差界

量化感知训练(QAT)与直通估计器(STE)

混合精度与自适应量化

2.3.3 混合云-边缘推理架构与回退机制(建模、优化与稳定性保证)
系统建模(延迟、能耗与准确率三元模型)
在部署时需在延迟(latency)、**能耗(energy)与准确率(accuracy)**之间作权衡。将推理任务划分为三类运行地点:
-
Edge:本地设备推理(低延迟、低带宽消耗,但计算资源有限,可能精度较低)。
-
Cloud:远端高性能服务器(高精度但通信延迟与带宽受限)。
-
Hybrid(split):将模型切分为前端(edge)与后端(cloud),在边缘计算部分提取中间激活再传输。
延迟模型

能耗模型
![]()
精度模型

最优切点与在线决策(带约束的优化问题)

动态环境下的鲁棒策略

回退机制与稳定性保证(混合切换系统理论)

共同 Lyapunov 函数与驻留时间(dwell time)条件

置信度与触发逻辑(基于概率界与检测)
用模型输出不确定性或置信度估计器(温度标定、预测熵、深度集成或贝叶斯神经网络)判断是否应回退。若置信度低于阈值 cminc_{\min}cmin 或延迟超阈,则触发回退。为避免误触发,结合统计检测(例如基于滑动窗口的 KL divergence between recent activation distribution 和 baseline)判断漂移并触发迁移/回退。
最优部署策略的联合优化(示例数学程序)

受限于带宽与能耗预算。该混合整数优化可用启发式(贪心、贝叶斯优化)或近似松弛(将 uuu 连续化并舍入)解决。
部署流程与工程化步骤(可复现)

小结(理论要点与工程准则)
-
微调 vs 冻结:用偏差—方差分解与 Rademacher 复杂度量化选择可训练参数规模;利用 Fisher 信息实现软冻结与自适应学习率调度以在小样本 regime 中保持稳定并在大样本 regime 中发挥容量优势。
-
蒸馏、剪枝、量化:蒸馏通过软目标降低方差并传递教师“暗知识”;OBS 提供基于 Hessian 的剪枝重要性度量,幅值剪枝为可行近似;量化误差通过 Lipschitz 常数约束传播到输出并可用 QAT/STE 缓解;推荐蒸馏→剪枝→量化的流水线顺序以最小化累计误差。
-
混合云-边缘部署:通过建立精确的延迟/通信/能耗/准确率模型,在线解最优切点并采用概率约束或 CVaR 风险项使策略鲁棒;切换控制应满足最小驻留时间并结合置信度与漂移检测以保证稳定性与安全性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









