



---------------------------------------------------------------------------------------------------------------------------------
版权所有 © 2025 刘丹。
本文的全部内容(包括文字、插图、表格、图表、代码示例等)受版权法保护。未经版权所有者书面明确许可,任何单位或个人不得以任何形式(包括但不限于复印、转载、摘编、影印、扫描、改编、录入计算机检索系统、互联网传播、网络下载或以其他方式使用)复制、传播或改编本文的全部或任何部分。
违者将依法追究法律责任。
如需转载或引用本书内容进行教学、研究或出版,请通过以下联系方式申请许可:
联系人:刘丹;电子邮件:3549233510@qq.com。
---------------------------------------------------------------------------------------------------------------------------------
本章把前面若干章节的理论与方法学成果落到工程可执行的路线图上,给出从研究原型到可用系统的阶段化里程碑、常见陷阱的形式化分析与工程对策、以及按预算分档的开源工具链与硬件清单(以类别与能力为单位,而非逐品牌型号),使读者能把学术成果稳健、可复现地推向部署。本章以严密的逻辑推导、简单可检验的条件与判据为核心:每一项工程建议都伴随可测量的接受标准或概率界定,便于作为教学或工程规范使用。
16.1 从研究到可用系统的关键里程碑(阶段化计划)
工程化的核心问题是风险分散与信息积累:在有限资源下,按阶段获取信息、验证假设、修正设计,是最小化总期望成本与失败概率的最优策略。下面把阶段化计划形式化、给出代价-收益比较,并给出可操作的里程碑模板与验收准则。
16.1.1 阶段化模型的数学表述与最优性理由

![]()
16.1.2 阶段化里程碑模板(可量化的验收准则)
以下为常见的五阶段工程化路线,各阶段给出目标、关键任务、可度量验收准则与典型时间尺度(项目、数据与团队规模会影响实际时间):

16.1.3 阶段里程碑的统计验收准则示例

16.2 常见陷阱与工程建议(性能、鲁棒性、可维护性)
本节把常见工程陷阱形式化为“风险源 + 理论证据 + 对策”,并给出可验证的修复/缓解措施。关键陷阱包括:过拟合与数据泄露、分布漂移与性能退化、数值/并行不确定性、运维复杂度与技术债务。
16.2.1 过拟合与数据泄露:理论根源与防护

16.2.2 分布漂移与在线适应:度量与控制

16.2.3 数值与并行不确定性(可重现性问题)
根源:并行浮点运算中的非交换性、不同 BLAS/库实现、不同硬件架构的舍入行为会导致训练/推理结果差异。
理论说明:浮点加法在不同求和顺序下差异可累积,尤其在深层网络梯度累加与随机同步中。模型参数更新视为在真实梯度上加入有界数字噪声,进而影响优化轨迹(见第13章关于数值噪声对训练收敛的分析)。
工程对策:
-
对不可避免的非确定性,记录并报告关键环境信息(库版本、GPU 型号、cuDNN deterministic flag)。
-
在需要严格复现时开启 deterministic 模式并在 CI 中加上可重复性测试(比如相对误差阈)。
-
在模型压缩/量化环节保持混合精度:保存累积梯度/更新为高精度(FP32)以减少漂移。
验收检查:在同一 commit 下,以 N 次不同随机种子跑训练,检查主要指标方差是否在可接受范围内(CV < ε)。
16.2.4 运维复杂度与技术债务

16.3 推荐开源工具链与硬件清单
按照“研究/早期验证”、“小规模生产/边缘部署”与“大规模生产/高吞吐”三档给出工具链与硬件类别建议。每一项给出选型理由、关键能力指标与验收指标(能力阈值),避免固定品牌型号以降低时效性风险。
说明:下列清单以功能能力与工程原则为主;实际采购请根据最新市场与预算做最终决策。
16.3.1 预算档定义(便于决策)
-
低预算(Research / Proof-of-Concept):资源有限、主要目标为快速原型与迭代,预算量级为少量台式机到单台 GPU/FPGA 节点。
-
中等预算(Pilot / 小规模生产):需稳定推理服务与边缘设备部署,预算支持若干服务器与若干边缘设备。
-
高预算(Production / 大规模部署):需要高吞吐、低延迟与高可用集群,支持多副本、负载均衡与专业硬件(定制 ASIC / 高端 GPU 群集)。
16.3.2 软件工具链(按阶段适配)
数据工程与管理
-
功能:数据管道、ETL、数据版本化、Schema 校验。
-
推荐类别:Apache Airflow / Prefect(调度)、Delta Lake / Parquet(列式存储)、DVC 或 MLflow(数据+模型版本化)。
-
验收指标:能重放任意实验数据管道并在 1 小时内复现数据快照。
开发与训练框架
-
功能:模型定义、分布式训练、量化/Pruning 支持。
-
推荐类别:PyTorch / TensorFlow(主流深度学习框架)、Hugging Face Transformers(NLP 模型库)、Ray 或 Accelerate(分布式/调度)。
-
验收指标:支持单机多卡训练与分布式训练;训练脚本可在容器化环境下以配置文件运行。
模型压缩与部署
-
功能:量化、剪枝、蒸馏、ONNX 转换、推理优化。
-
推荐类别:ONNX Runtime、TensorRT、OpenVINO、TFLite(边缘)、nncf/optimum(压缩工具)。
-
验收指标:模型经压缩后满足延迟与精度阈值(例如延迟降低 ≥ X% 且准确率降幅 ≤ Y%)。
CI/CD 与 可观测性
-
功能:测试自动化、镜像构建、日志与指标收集、告警。
-
推荐类别:GitHub Actions / GitLab CI / Jenkins(CI)、Prometheus + Grafana(监控)、ELK/Opensearch(日志)、Sentry(错误追踪)。
-
验收指标:每次 commit 通过基本测试的平均反馈时间 < T_CI;关键 SLI 指标可在 1 分钟内触发告警。
安全与合规
-
功能:镜像签名、模型/数据访问控制、隐私合规。
-
推荐类别:Notary / Cosign(镜像签名)、Hashicorp Vault(密钥管理)、差分隐私库(PyDP)用于敏感数据保护。
-
验收指标:所有部署产物均已签名且存储访问遵守最小权限。
16.3.3 硬件清单(按预算,按类别说明购买策略)
下面按功能角色(开发/训练、推理/边缘、特殊加速如 FPGA/SDR)给出能力性建议。
低预算(快速原型)
-
开发机:配备现代多核 CPU(例如 8–16 核)、至少 32–64 GB RAM、SSD(≥1 TB)。用于数据预处理、轻量训练。
-
加速卡(可选):单台带有中端 GPU(如 1× 单卡,8–32 GB 显存)或低成本 FPGA 开发板(用于算法原型)。
-
边缘设备:树莓派 / Jetson Nano / Coral Dev Board(用于功能验证)。
-
验收能力:能在 1–2 小时内完成原型训练迭代;推理延迟在边缘设备能演示实时性(示例:≤100 ms)。
中等预算(Pilot / 边缘部署)
-
训练服务器:1–4 台 GPU 服务器(每台配 1–4 张 16–48 GB 显存的卡),64–512 GB RAM,快速网络(10–25 Gbps)。
-
推理节点:边缘 CPU + NPU/TPU Lite /中端 GPU(8–16 GB)或工业级嵌入式设备。
-
FPGA/ASIC 加速器:若低延迟硬件路径必要,则引入商用 FPGA 板卡用于算子加速(矩阵乘、FFT、定点算子)。
-
网络与存储:NAS 或对象存储(S3 接口),备份与冗余备份策略。
-
验收能力:能承载小批量真实流量,支持灰度发布,并在突发流量下维持 SLO。
高预算(大规模生产)
-
训练集群:多节点 GPU 群集(每节点 4–8 卡以上,高显存卡),高速互联(HDR InfiniBand、NVLink),分布式训练框架(Horovod/DeepSpeed)。
-
推理集群:GPU 或专用推理加速器(Tensor Processing ASIC / FPGA 池),自动弹性伸缩、区域化分布部署以降低延迟。
-
边缘加速:定制 ASIC、FPGA 逻辑内核部署到边缘设备以保证低功耗与低延迟。
-
企业级存储与备份:多区域冗余、冷备份策略、灾备站点。
-
验收能力:百万级查询吞吐(或相应行业 KPI)、99.9%+ 的可用性、自动化故障迁移与混合云部署能力。
16.3.4 采购与验收(SLA 风险管理)
采购时要把“能力验收”作为合同条款的一部分,明确如下指标并在交付时测验:
-
性能基线:在指定基准上测得的吞吐/延迟指标(详列基准场景与数据)。
-
稳定性:连续 72 小时压力运行无致命错误。
-
可维护性:供应商提供软件镜像的 digest、文档与支持 SLA。
-
互操作性:能在目标容器/镜像中运行既有的训练/推理镜像。
结语:把理论变为可持续工程
把研究成果工程化不仅需要技术堆栈,也需要过程化与可验证的里程碑、严密的统计与决策准则、防御性的运维策略与合理的预算配置。将上述阶段化计划、风险模型与工程清单作为组织级模板,并在每一阶段以统计检验与自动化脚本锁定“是否向前”的判据,能显著降低从原型到生产的失败率并提高长期可维护性与合规性。本章提供了可直接套用的数学判据、验收模板与工具/硬件类别,便于在课堂与工程实践中直接使用与检验。
附录(实用资源)
本附录为工程/研究实战的速查手册与模板集合,便于在开发、实验与教学中快速检索常用数学式、算法伪码、实验室配置与工程实践标准。每个小节都尽量以可直接复制使用的形式呈现:公式、伪代码、清单与目录模板。
A 数学与信号处理速查
A.1 常用变换(定义与关键性质)


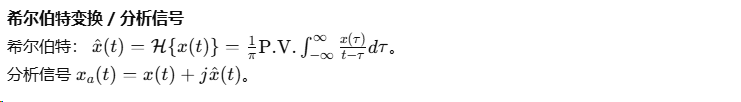
A.2 重要性质(精选)
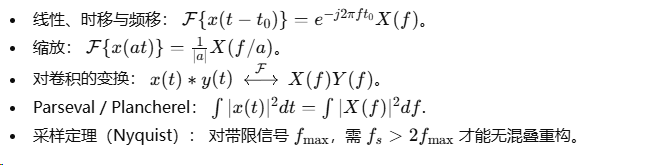
A.3 常用积分及特殊积分(速查)
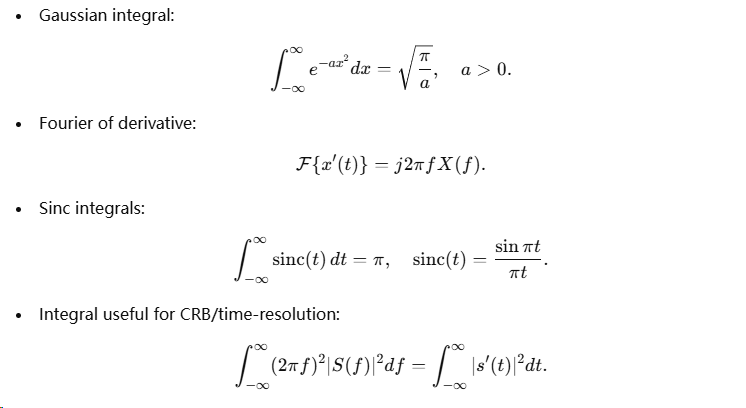
A.4 常用概率分布(PDF、期望、方差)
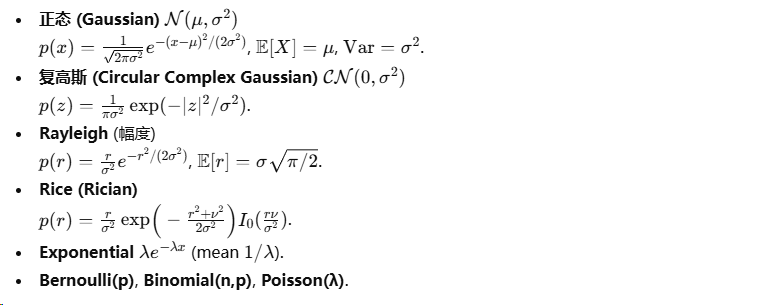
A.5 常用量化/误差界速查
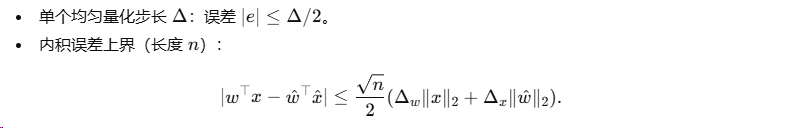
B 常用算法伪代码集合
下面以清晰伪代码给出常用算法;注释中给出复杂度与关键参数说明。
B.1 Cooley–Tukey FFT(递归,长度 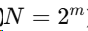 )
)
function FFT(x[0..N-1]):
if N == 1: return x
X_even = FFT(x[0], x[2], ..., x[N-2])
X_odd = FFT(x[1], x[3], ..., x[N-1])
for k = 0 .. N/2 - 1:
t = exp(-j*2*pi*k/N) * X_odd[k]
X[k] = X_even[k] + t
X[k + N/2] = X_even[k] - t
return X
B.2 STFT(短时傅里叶变换,滑动窗口)
function STFT(x, window, hop, Nfft):
frames = []
for start in range(0, len(x)-len(window)+1, hop):
frame = x[start : start + len(window)] * window
X = FFT(zero_pad(frame, Nfft))
append frames with X
return frames
-
参数:window(长度 L)、hop(步长)、Nfft(FFT 点数)。时频分辨率由 L 与 Nfft 决定。
B.3 正交匹配追踪 OMP(稀疏表示)

B.4 卡尔曼滤波(线性高斯模型)

B.5 粒子滤波(Sequential Monte Carlo)

B.6 CNN 基块(前向 + 批归一化 + 激活)
伪代码只说明计算步骤:
function ConvBlock(input, W_conv, b_conv, gamma, beta):
# convolution
conv = conv2d(input, W_conv) + b_conv
# batch norm: compute mean/var over batch & spatial dims
mu = mean(conv)
var = var(conv)
bn = gamma * (conv - mu)/sqrt(var + eps) + beta
out = ReLU(bn)
return out
-
反向需按链式法则求导;实现中用自动微分工具。
C 实验与复现实验室设置清单
下面给出适用于 RF/ML/嵌入式联合实验室的配置清单与布置要点,并给出示例型号(作为参考)与布线/安全注意事项。
C.1 功能区划分(建议)
-
射频/天线区:放置 SDR、天线、射频线缆,需 RF 级接地与电磁兼容(若有可屏蔽室更好)。
-
测量/仪器台:示波器、频谱分析仪、信号发生器、功率计。
-
计算/训练区:高性能 GPU 服务器、调试工作站、网络交换机。
-
嵌入式/开发区:FPGA 开发板、功率供应、编程器、焊台。
-
存储与备份区:NAS、备份磁盘、冷存档空间。
C.2 建议设备清单(示例型号仅供参考)
-
SDR / 前端:Ettus USRP B210 / X310 / NI USRP 系列;LimeSDR。
-
FPGA / 加速:Xilinx Alveo U50/U280 或 Zynq 开发板(ZCU104/MPSoC);Intel (Altera) Arria/Stratix开发板。
-
GPU(训练/推理):NVIDIA A100 / H100(高预算);RTX 3080/4090(中档);RTX 4060/3060(低预算原型)。
-
测量仪器:示波器(≥100 MHz 带宽),频谱分析仪(覆盖至 GHz/THz 取决需求),信号发生器(任意波形),功率计,网络分析仪(若需要天线特性测量)。
-
定位/同步:GPSDO(GPS-disciplined oscillator),恒温 OCXO(高稳定时钟)。
-
网络与存储:10/25/100 Gbps 交换机,NAS(S3 支持)、SSD 冗余阵列。
-
辅助:变压器保护、UPS、接地条、同轴电缆(低损/封装)、阻抗匹配器、衰减器、隔离器、SMA/BNC 转接件。
C.3 电气与 RF 安全、布线建议
-
所有射频线缆需标识与走管,避免交叉长缆绕行;使用适当衰减器避免仪表或接收机过载。
-
射频区应有良好接地,电源与信号地分离;测量仪器应接入 UPS 以避免突断导致数据丢失。
-
若实验产生高功率发射,确保合规与许可(避免干扰商用频段)。
C.4 布置图(ASCII 简图)
+------------------------------------------------+
| RF/ANT ZONE | Measurement Bench |
| [Antenna] | [SpecAn] [SigGen] [Scope]|
| [SDR]---cable----| |
+-------------------+--------------------------+
| FPGA / Edge Dev | Compute Cluster / Rack |
| [FPGA Boards] | [GPU Servers] [NAS] |
+-------------------+--------------------------+
| Workbench / Desk | Storage/Backup Room |
+------------------------------------------------+
C.5 复现实验室运行 SOP(关键步骤)
-
上电顺序(仪表 → SDR → 核心服务器)以防瞬态。
-
校验时钟与 GPS 同步,记录
timebase元数据。 -
校验每个数据文件 SHA-256 并加入元数据记录。
-
实验结束保存日志、配置(docker image digest)、硬件版本信息与照片。
D 推荐代码库结构模板
下面给出一个通用且实践验证的项目目录结构,适用于从数据预处理、模型训练到部署的端到端工作流。每个目录附示例关键文件与简短说明。
project/
├─ README.md
├─ LICENSE
├─ docs/
│ └─ architecture.md
├─ data/
│ ├─ raw/ # 原始不可更改数据(只存索引/hash)
│ ├─ processed/ # 处理后数据
│ ├─ samples/ # 小样本子集(用于 CI / smoke tests)
│ └─ schema/ # JSON schema / metadata definitions
├─ configs/
│ ├─ default.yaml
│ └─ experiments/
├─ src/
│ ├─ __init__.py
│ ├─ data/ # 数据加载与增强
│ ├─ models/ # 模型架构定义
│ ├─ trainers/ # 训练循环、优化器、检查点
│ ├─ eval/ # 评估脚本与指标
│ └─ utils/ # 常用工具(metrics, logging, seed)
├─ notebooks/ # 交互式分析(非必需)
├─ scripts/
│ ├─ run_train.sh
│ ├─ run_eval.sh
│ └─ download_data.sh
├─ docker/
│ ├─ Dockerfile
│ └─ docker-compose.yml
├─ tests/
│ ├─ unit/
│ └─ integration/
├─ ci/
│ └─ pipeline.yml
├─ artifacts/ # 存放训练产物的索引(不要直接放大文件)
│ └─ manifest.json
└─ .gitignore
D.1 关键实践与文件模板
README.md:快速启动指南(包括最低硬件要求、关键命令、镜像 digest 示例)。
configs/default.yaml(示例关键字段):
seed: 42
model:
type: my_model
hidden: 512
training:
batch_size: 32
lr: 1e-4
data:
dataset_name: mydataset
sample_rate: 48000
Dockerfile 最简模板
FROM python:3.10.12@sha256:<digest>
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . /app
CMD ["bash", "scripts/run_train.sh", "--config", "configs/default.yaml"]
(使用镜像 digest 锁定基础镜像)
CI 分层(pipeline.yml) 示例要点
-
step: lint, unit tests (fast)
-
step: build docker image (with digest), run integration tests (container)
-
step: smoke training on samples (check loss decreases)
-
step: upload artifact manifest with model hash and image digest
D.2 版本化与可复现要求
-
所有实验要产出
artifacts/manifest.json包含:commit_hash,image_digest,dataset_hash,config_hash,start_time,end_time,metrics。 -
数据用 content-addressed 存储(DVC 或 object store)并在 manifest 中记录 hash。
E 术语表与缩写表
列出常见术语与缩写,便于快速查阅。
-
ADF — Automatic Delay Finder(示例)
-
A/B Test — 实验设计方法,用于比较两个版本的效果。
-
API — Application Programming Interface。
-
AWGN — Additive White Gaussian Noise,加性白噪声。
-
CI — Continuous Integration,持续集成。
-
CRB — Cramér–Rao Bound,参数估计的下界(基于 Fisher 信息)。
-
CSV — Comma-Separated Values。
-
DFT — Discrete Fourier Transform。
-
DL — Deep Learning。
-
DTFT — Discrete-Time Fourier Transform。
-
DSP — Digital Signal Processing。
-
E2E — End-to-End。
-
EDF — Earliest Deadline First(调度算法)。
-
EWMA — Exponentially Weighted Moving Average。
-
FIR/IIR — Finite/Infinite Impulse Response filters。
-
FFT — Fast Fourier Transform。
-
FLOP — Floating Point Operation。
-
FPGA — Field Programmable Gate Array。
-
GPU — Graphics Processing Unit。
-
HMM — Hidden Markov Model。
-
IAAS/PAAS/SAAS — 云服务分层。
-
IDE — Integrated Development Environment。
-
IoT — Internet of Things。
-
ISAC — Integrated Sensing And Communication。
-
JIT — Just-In-Time(编译)。
-
KPI — Key Performance Indicator。
-
ML — Machine Learning。
-
MMD — Maximum Mean Discrepancy(分布差异度量)。
-
MLE / MAP — Maximum Likelihood Estimation / Maximum A Posteriori。
-
NIST — National Institute of Standards and Technology。
-
NP — Nondeterministic Polynomial time。
-
OTA — Over The Air(远程升级)。
-
OMP — Orthogonal Matching Pursuit(稀疏算法)。
-
PPL — Perplexity(语言模型度量)。
-
PTQ / QAT — Post-Training Quantization / Quantization-Aware Training。
-
ROC / AUC — Receiver Operating Characteristic / Area Under Curve。
-
SDE — Stochastic Differential Equation。
-
SDR — Software Defined Radio。
-
SNR — Signal-to-Noise Ratio。
-
SVD — Singular Value Decomposition。
-
STFT — Short-Time Fourier Transform。
-
TLS / SSL — 安全传输协议。
-
TPU — Tensor Processing Unit(加速器)。
-
UID — Unique Identifier。
-
UUID — Universally Unique ID。
-
VOC — Voice of Customer(或 Pascal VOC 数据集)。
-
XML / JSON — 数据交换格式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









