






🎬 GitHub:Vect的代码仓库
文章目录
1. 基本概念和基本操作
内核观点:进程是担当分配系统资源(CPU时间、内存)的实体
本质:进程=内核数据机构+程序的代码和数据
程序是静态的文件,进程是动态的执行过程,内核数据结构是进程的“身份证+状态记录”
如何进行进程管理呢?—>先描述再组织
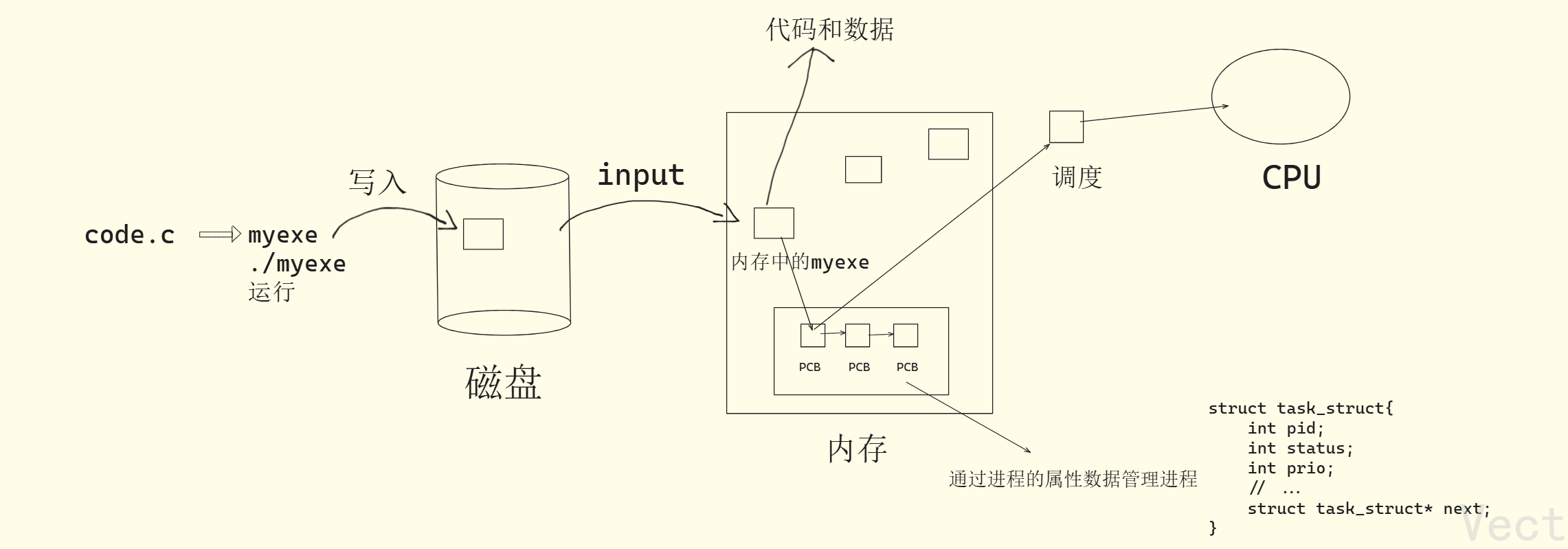
- 先描述:
- code.c: 是静态的源代码文件,只包含程序的代码逻辑
- myexe: 编译后的二进制可执行文件,静态的,存在磁盘中,包含程序初始数据和二进制代码
- 磁盘: 持久化存储介质,存放未运行的静态程序文件
- 内存: 临时运行介质,执行
./myexe时,myexe的代码和数据会从磁盘加载到内存中,同时内核会为它创建PCB(process control block) - PCB(struct task_struct): 进程的属性,每个PCB对应一个进程
- CPU: 执行硬件 ,通过调度机制,从内存中的PCB链表中调度进程,执行对应的代码和数据
- 再组织:
- 静态的
code.c被编译成myexe,以文件形式加载到磁盘中 - 执行
myexe时,代码和数据加载到内存 - 内核为内存中的
myexe创建PCB,并将多个进程的PCB组织成链表 - CPU通过调度,从PCB链表中选择合适的进程,执行代码和数据
- 静态的
所以,进程会被OS根据task_struct属性进行调度和执行
2. PCB内部详细结构(task_struct详解)
PCB(Process Control Block,进程控制块)是内核用于描述进程的核心数据结构,Linux 下具体实现为task_struct,加载在内存中,包含进程所有属性
核心属性分类
- 标识符(pid ppid):描述本进程的唯一id,用于区别其他进程
- 状态:任务状态、退出代码、退出信号等
- 优先级:相对于其他进程,执行的先后顺序
- 程序计数器:程序中即将被执行的下一条指令的地址
- 内存指针:包括程序代码和进程相关数据的指针、其他进程共享的内存块的指针
- 上下文数据:进程执行时寄存器中恢复的数据
- IO状态信息
- 记账信息
这些核心属性都会在下文一一讲解
PCB的组织方式
所有运行在系统里的进程都以task_struct双链表的形式存在内核里,且task_struct包含进程所有属性(标识符、状态、优先级等)
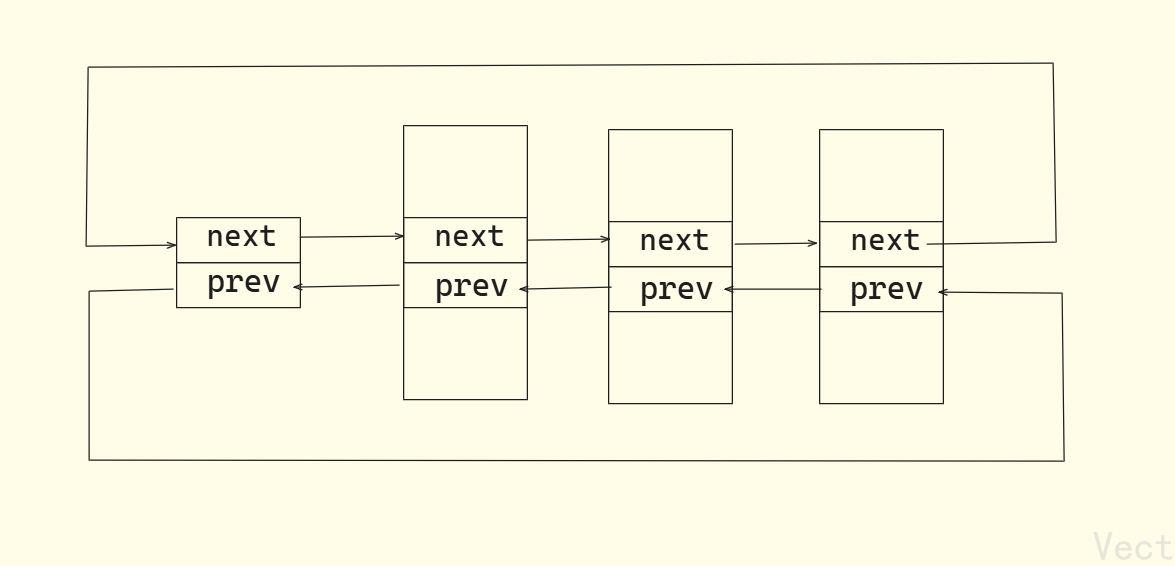
内核通过遍历该链表管理所有进程,如查找、调度、终止进程
3. 如何查看进程?
/proc文件系统(内核直接暴露的进程信息)
我们一般是用户级别访问,而有些文件可能会访问受限
-
原理:Linux把每个进程的详细信息以目录形式存储在
/proc/[PID]下
-
示例:
查看PID=1的信息:
ls /proc/1
ps指令(用户级进程查看工具)
-
ps aux: 查看是同所有进程(a->所有终端,u->用户中心格式,x->无控制终端进程) -
ps -l:查看当前终端进程,详细显示优先级 -
ps ajx | grep 程序名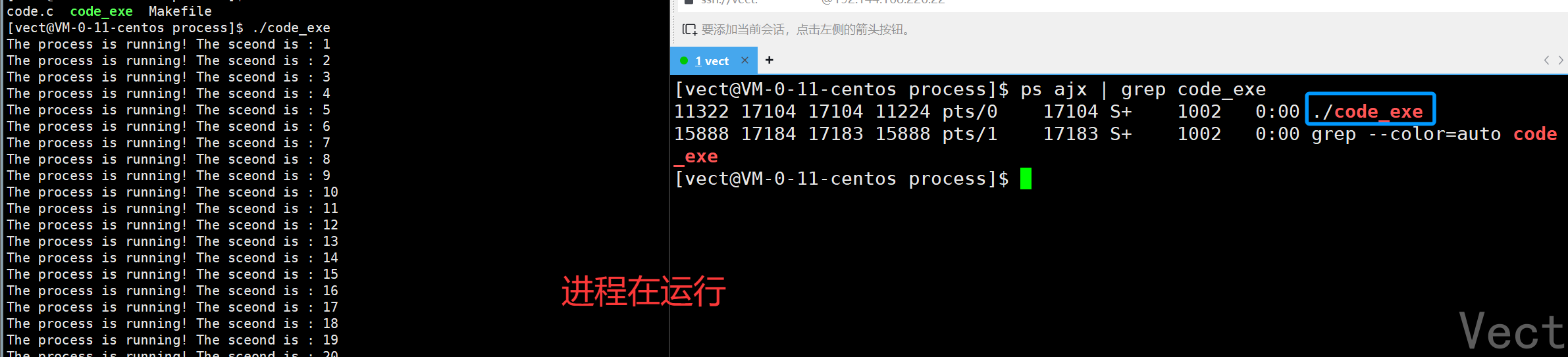

观察一下这个现象:
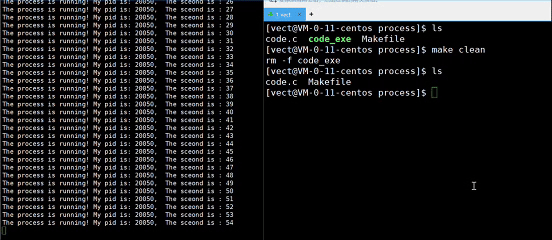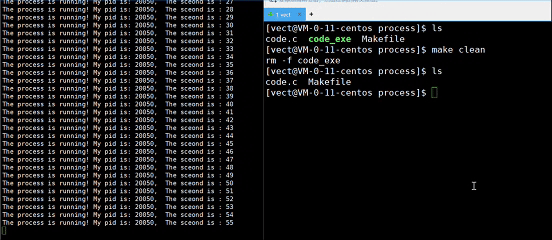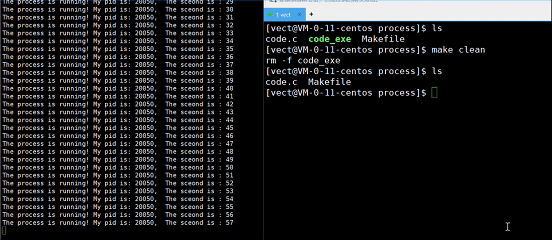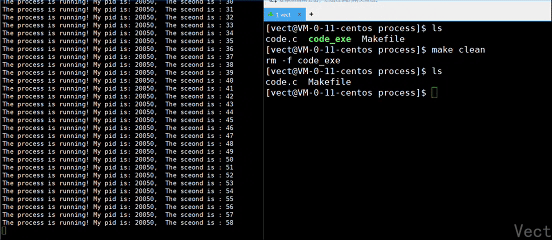
为什么删除了可执行文件,进程还能运行?
我们删除的是磁盘中的文件,而正在执行的文件已经被加载到了内存,二者不相互影响!如果进程终止,下次就无法继续运行了!

top指令(动态监控进程)
实时刷新进程状态(默认3秒一次),支持修改优先级
操作:
- 进入top:输入
top- 调整优先级:按
r->输入进程pid->输入新的nice值- 退出:按
q
pid和nice值后续会详细讲
4. 如何创建进程(fork函数详解)
核心功能:
- 系统调用:
pid_t fork(void);头文件:<sys/types.h> <unistd.h>- 功能:创建一个新进程(子进程),父进程和子进程从
fork之后的代码开始执行
两个返回值:->确保进程之间的独立性
- 父进程:返回子进程的pid->用于识别子进程
- 子进程:返回0,->表示自身是子进程
- 错误返回:-1->表示资源不足或无法创建子进程
通过文档我们可以知道,一个父进程可以有多个子进程,但是一个子进程只能有一个父进程,这个很好理解,所以创建子进程成功,用0表示成功即可,而对于父进程,需要子进程的pid进行管理

代码共享,数据私有:->验证了进程间有独立性
代码段:父子进程共享一份程序代码(
fork后执行相同的后续代码)数据段(全局变量、局部变量):父子进程独立享有数据
代码示例:
#include <stdio.h> #include <unistd.h> #include <sys/types.h> // 全局变量(数据段) int global_val = 100; int main(){ // 局部变量(栈段) int local_val = 10; // fork前:打印初始值,验证代码执行流程 printf("fork前,全局变量: %d, 局部变量:%d\n",global_val, local_val); // 创建子进程 pid_t ret = fork(); if(ret < 0){ perror("fork err"); }else if(ret == 0){ // 子进程分支,代码共享,执行相同的代码逻辑 printf("\n子进程pid:%d, ppid:%d\n",getpid(),getppid()); // 子进程修改前 printf("子进程修改前:全局变量:%d, 局部变量:%d\n",global_val,local_val); // 子进程修改变量 global_val = 500; local_val = 200; // 子进程修改后 printf("子进程修改后:全局变量:%d, 局部变量:%d\n",global_val,local_val); sleep(10); }else{ // 父进程分支 // 父进程sleep休眠 保证子进程完成变量修改 sleep(2); printf("\n父进程pid:%d, ppid: %d\n",getpid(),getppid()); printf("父进程-子进程修改后:全局变量:%d, 局部变量:%d\n",global_val,local_val); sleep(10); } return 0; }输出结果:
fork前,全局变量: 100, 局部变量:10 子进程pid:14567, ppid:14566 子进程修改前:全局变量:100, 局部变量:10 子进程修改后:全局变量:500, 局部变量:200 父进程pid:14566, ppid: 28859 父进程-子进程修改后:全局变量:100, 局部变量:10分析:
pid_t ret = fork();这行代码的行为:
- 基于当前的父进程,创建子进程,形成子进程的PCB
- 父子进程从
fork的下一行代码开始,各自独立执行代码-> 父子进程进入不同的逻辑判断- 数据层面:初始父子进程同值,修改后各自独立
这里再讲一下分支问题:为什么
else if和else这两个逻辑同时执行了?不是同一个进程同时执行两个分支,而是
fork创建了两个独立的进程,各自执行不同的分支!!!
fork调用成功后,内核复制父进程的``task_struct`,创建子进程的 PCB。- 父进程和子进程同时从
fork()之后的代码开始运行,但ret值不同:
- 父进程的
ret是子进程 PID(正数)→ 进入else分支。- 子进程的
ret是 0 → 进入else if (ret == 0)分支。- 两个进程是独立的执行流,因此看起来 “同时” 进入了不同的分支(本质是并发执行)。
补充知识点:详细理解cwd
先来看一段代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(){
FILE* fptr = fopen("new.txt","w");
if(fptr == NULL){
perror("fopen err");
}
pid_t id = getpid();
while(1){
printf("我是一个进程,我的pid: %d\n",id);
sleep(1);
}
return 0;
}
如果文件不存在,则会在当前工作目录创建新文件:

查看cwd:ls -l /proc/PID/cwd

这是代码执行的逻辑:
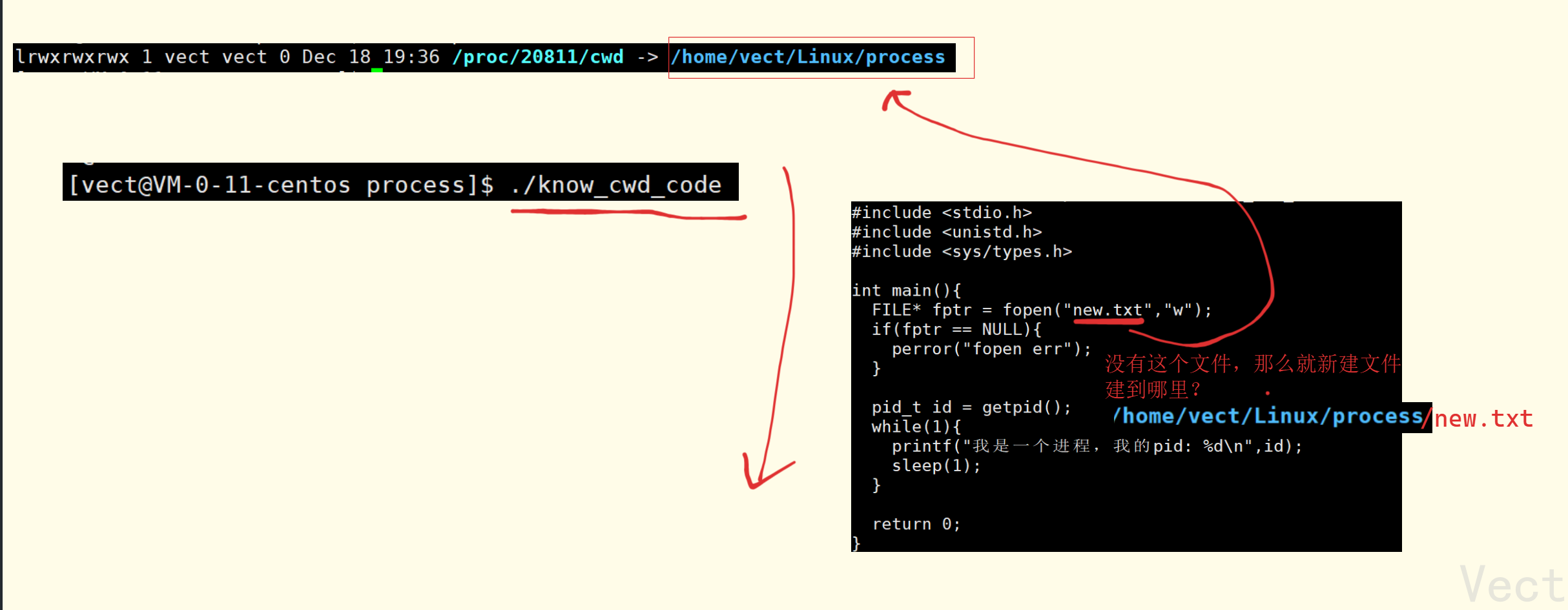
exe文件指向进程的详细路径->源可执行文件路径,而每个进程都会记录自己的exe路径和cwd
想要修改cwd,可以利用chdir函数,这里不做演示
父进程的父进程是谁?
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(){
pid_t id = fork();
if(id == 0){
printf("我是子进程,pid: %d, ppid: %d\n",getpid(),getppid());
}else{
printf("我是父进程,pid: %d, ppid: %d\n",getpid(),getppid());
}
sleep(1000000);
return 0;
}

命令行中,执行命令/执行程序,本质时bash的进程创建的子进程,最终由子进程执行我们的代码
创建多个进程
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main(){
for(int i = 0; i < 10; i++){
pid_t id = fork();
if(id == 0){
printf("子进程PID: %d,PPID: %d, 序号:%d\n",getpid(),getppid(),i + 1);
sleep(2);
return 0; // 子进程退出
}
}
sleep(5); // 让子进程跑完
printf("父进程:%d,所有子进程创建完毕\n",getpid());
return 0;
}
5.进程状态
补充知识:
**并发:**多个进程在一个CPU下执行,CPU给每一个进程预分配一个时间片,基于时间片,进行调度轮转执行进程
**并行:**多个进程在多个CPU下同时执行
时间片: 在Linux/Windows民用级别的OS时分时操作系统,调度任务追求公平
与之对应实时OS,高优先级,比如车载OS,刹车操作时高优先级执行的
操作系统学科视角下的进程状态

- 创建态:进程刚被创建,内核正在分配PCB、内存资源,山我给进入就绪队列
- 就绪态:进程已具备执行条件,等待CPU调度(未占用CPU,但随时能跑,在就绪队列排队)
- 运行态:进程正在CPU上执行指令(单核CPU同一时间只有1个进程处于这个状态)
- 阻塞态:进程因为等待某事件(IO完成、资源可用、信号),无法执行,主动放弃CPU(不占用CPU,在等待队列休眠)
- 终止态:进程执行完毕/被终止,内核正在回收资源,资源回收完成后彻底消失
阻塞(等待)的本质:
阻塞(等待)是进程主动放弃CPU使用权的核心机制:
当进程需要的事件未就绪:
- 读磁盘但数据为到
- 等待用户输入
- 等待子进程退出
等等情况,继续占用CPU只会浪费CPU资源,阻碍其他进程正常运行
因此,进程从运行/就绪态进入阻塞态,被内核放入对应事件的等待队列,直到事件完成之后,内核将其唤醒至就绪态(不能直接到运行态,如果有其他进程在运行态,直接抢占吗?),重新排队等候CPU调度
Linux视角下的进程状态
| 状态 | 缩写 | 全程 | 对应OS理论 | 核心特征 |
|---|---|---|---|---|
| 运行/就绪 | R | Running/Runnable | 运行态+就绪态 | 要么CPU执行,要么在“运行队列”等待调度(Linux不区分运行/就绪,统一为R) |
| 可中断等待(睡眠) | S | Interruptible Sleep | 阻塞态(可中断) | 等待事件(sleep、键盘输入、wait),可被信号(kill、ctrl+c)唤醒 |
| 不可中断等待(睡眠) | D | Uninterruptible Sleep | 阻塞态(不可中断) | 等待关键资源(磁盘IO),不能被信号唤醒 -> 避免数据损坏、丢失 |
| 暂停态 | T | Stopped | 特殊阻塞状态 | 被信号(ctrl+z、kill -19)暂停,可通过fg/bg恢复 |
| 僵尸态 | Z | Zombie | 终止态(未回收) | 进程已退出,代码和数据被清理,但PCB仍保留,等待父进程回收处理 |
| 死亡态 | X | Dead | 终止态(已回收) | 进程资源彻底释放,瞬间状态,ps无法捕获 |
进程状态查看
ps aux / ps axj
- a:显示一个终端所有的进程,包括其他用户的进程
- x:显示没有控制终端的进程,例如后台运行的进程
- j:显示进程归属的进程组ID、会话ID、父进程ID以及与作业控制相关的信息
- u:以用户为中心的格式显示进程信息,提供用户、CPU和内存使用情况等详细信息
代码演示各种状态
R+S态
#include <stdio.h>
#include <unistd.h>
int main(){
pid_t pid = getpid();
printf("进程ID: %d\n",pid);
printf("阶段: R态(死循环,占用CPU)\n");
/*while(1){
// 死循环 持续占用CPU
}
*/
// 以下代码需要注释掉while循环,演示S态
printf("阶段:S态(sleep 10秒,可中断等待\n");
sleep(10);
printf("sleep结束,回到R态\n");
return 0;
}


S态可悲信号唤醒/终止
+代表进程在前台执行
T态(暂停)
#include <stdio.h>
#include <unistd.h>
int main(){
pid_t pid = getpid();
printf("进程PID:%d\n",pid);
printf("按ctrl+z暂停进程,变为T态,用fg恢复变为R态\n");
while(1){
}
return 0;
}

在我们debug时,进程追踪到断点处停下,此时进程就是T状态
Z态
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(){
pid_t child_pid = fork();
if(child_pid == 0){
// 子进程:立刻退出,成为僵尸进程
printf("子进程PID:%d,即将退出\n",getpid());
return 1;
}else{
// 父进程 无限循环 不回收子进程
printf("父进程PID:%d, 子进程PID:%d\n",getpid(),child_pid);
printf("子进程成为Z态,请查看状态\n");
while(1){ }
}
return 0;
}

对于进程退出:代码会不会执行,释放对应的代码和数据,保留退出信息保存在task_struct,方便用户未来管理
而对于僵尸状态:子进程的task_struct由内核维护,方便未来父进程读取退出状态;若是一直没有父进程处理,会一直处于Z态,task_struct就会一直消耗内存,可能导致内存泄漏!这就是僵尸进程
孤儿进程
父进程先退出,子进程成为孤儿进程,此时谁来管理子进程?->被系统的1号进程领养
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(){
pid_t ret = fork();
if(ret == 0){
printf("子进程PID:%d,PPID:%d\n",getpid(),getppid());
printf("子进程不退出\n");
sleep(6);
while(1){ sleep(15); }
}else{
printf("父进程:%d,父进程即将退出\n",getpid());
sleep(5);
return 1;
}
return 0;
}
输出:
父进程:4598,父进程即将退出
子进程PID:4599,PPID:4598
子进程不退出
父进程退出
[vect@VM-0-11-centos process]$ 子进程PID:4599,新的PPID:1
1号进程的信息:
[vect@VM-0-11-centos process]$ ps -p 1 -f
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Nov26 ? 00:04:27 /usr/lib/systemd/systemd --switched-root
6. 进程优先级
优先级的作用
- 决定进程竞争CPU的先后顺序:优先级越高,越先被调度器选中执行
- 解决竞争性问题:多进程并发时,确保重要的进程优先获得CPU资源
PRI和nice值
- PRI(Priority):静态优先级(调度取决于PRI值,越小优先级越高)
- nice:优先级修正值,范围
[-20,19] - 计算公式: P R I ( n e w ) = P R I ( 默认 ) + n i c e PRI(new) = PRI(默认) + nice PRI(new)=PRI(默认)+nice 默认值为80
优先级查看与调整
查看优先级
ps -l
[vect@VM-0-11-centos ~]$ ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 1002 17266 17265 0 80 0 - 29251 do_wai pts/2 00:00:00 bash
0 R 1002 17371 17266 0 80 0 - 38332 - pts/2 00:00:00 ps
UID:执行者的身份,由谁启动的进程
文件会记录下拥有者、所属组,而所有的操作都是进程操作,进程会记录谁启动的自己,这便对应上了权限控制
PID:进程的编号
PPID:父进程的编号
PRI:优先级,越小越先执行
NI:nice值,修正PRI
修正优先级(不建议修改)
-
nice命令(创建进程时设置NI)nice -n [ni值] 程序,例如:nice -n -5 ./test→ 启动 test 进程,NI=-5,PRI=80-5=75 -
renice命令(调整已经运行的进程NI)renice [NI值] -p [PID],例如:renice 10 -p 3239→ 把 PID=3239 的进程 NI 设为 10,PRI=80+10=90 -
top命令(动态调整)
top → 按r → 输入 PID → 输入新 NI 值
7. 进程切换
切换的核心原因
- 时间片耗尽:每个进程都有固定的时间片,用完后必须让出CPU
- 高优先级抢占:新创建的高优先级进程会抢占低优先级进程的CPU
- 进程主动放弃CPU:如进程调用
sleep进入S态、等待IO
注意:一个进程时间片耗尽时,并不一定执行完,这时也必须退出CPU,等待下一次调度,所以一定要保存上下文数据!!!不然下次接着运行发现没数据就尴尬了
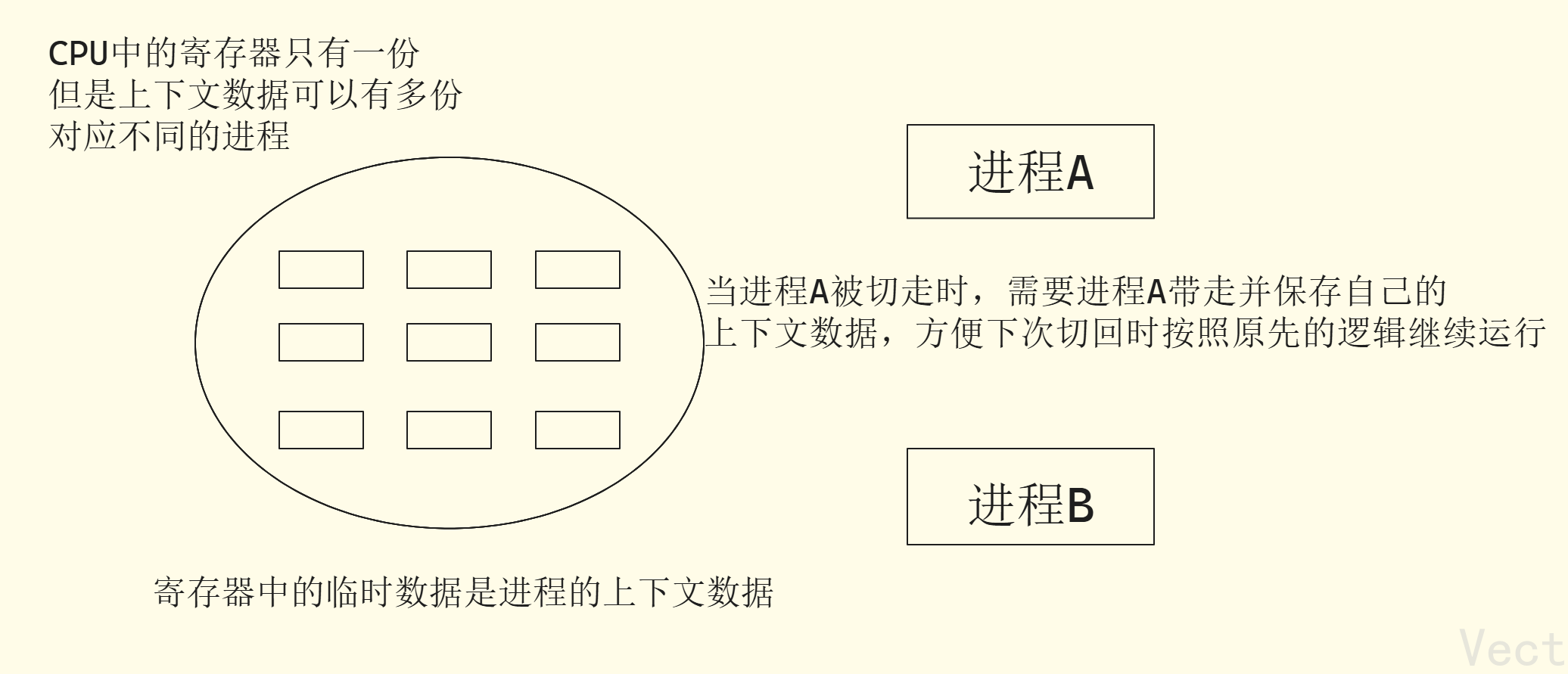
切换的本质:进程上下文数据的保存和恢复
- 上下文: 进程执行时CPU寄存器中的数据
- 切换流程:
- 保存当前进程的上下文(将寄存器里的数据存入进程的
task_struct) - 从就绪队列中选择下一个要执行的进程
- 加载下一个进程的上下文(从下一个进程的
task_struct读取数据,写入寄存器) - 跳转到下一个进程的程序计数器指向的指令,开始执行
- 保存当前进程的上下文(将寄存器里的数据存入进程的
切换的目的是实现并发:单核CPU下,通过快速切换,让多个进程看起来同时执行,人是察觉不到的
8. Linux2.6内核进程 O ( 1 ) O(1) O(1)调度队列

数据结构功能
-
struct queue优先级管理单元是 O ( 1 ) O(1) O(1)调度的最小功能端元,负责管理同一状态(活跃/过期)下的所有优先级进程,三个成员的功能:
-
nr_active:记录当前queue里的进程总数 -
bitmap[5]:优先级标记位图,每个比特位对应一个进程优先级[0,139],其中[100,139]是用户级别的普通优先级为什么设计大小为5? 32 × 5 = 160 > = 140 32 \times 5 = 160 >= 140 32×5=160>=140,刚好能覆盖
-
queue[140]:140个优先级的进程哈希桶
-
-
struct queue array[2]双队列容器这是一个 存 2 个
struct queue的数组,专门用来放活跃队列和过期队列array[0]:默认作为活跃队列(存还有剩余时间片的进程)array[1]:默认作为过期队列(存时间片已经耗尽的进程)
-
struct runqueueCPU就绪队列总管理每个CPU都有一个独立的
runqueue,它是 调度器的总入口,通过两个指针管理双队列:struct queue* active:指向当前的活跃队列(调度器只从这个队列里选进程运行);struct queue* expired:指向当前的过期队列(暂时不参与调度的进程容器)
算法逻辑
1. 初始化就绪队列:哈希桶与映射关系的初始化
runqueue完成初始化(本质是初始化哈希表的容器与映射规则):
- 初始化哈希桶数组:清空
array[0](活跃队列)和array[1](过期队列)的queue[140] - 初始化键的标记位:清空
bitmap(用于标记 “哪些优先级键对应的哈希桶有进程”) - 初始化哈希表状态:清空
nr_active(记录每个哈希表内的进程总数) - 绑定哈希表指针:让
active指向array[0](活跃哈希表)、expired指向array[1](过期哈希表)
2. 新进程入队:哈希表的 “键→桶” 插入操作
当进程被创建 / 唤醒时(本质是向活跃哈希表插入元素):
- 确定哈希键:获取进程的内核优先级(比如优先级 40,这是哈希的键值)
- 执行哈希映射:通过直接地址哈希函数
f
(
键
)
=
键
f(键)=键
f(键)=键,映射到
active哈希表的哈希桶——queue[40]链表 - 插入哈希桶:将进程节点插入到
queue[40]链表(哈希桶)的尾部 - 标记有效键:将
active哈希表的bitmap中 “对应键(优先级 40)的比特位” 设为 1(标记该键对应的哈希桶有元素) - 更新哈希表状态:
active哈希表的nr_active++
3. 调度器选进程运行:哈希表的 “有效键→桶” 查找操作
调度器从active哈希表选进程(本质是查找哈希表中 “有效键” 对应的桶,取头部元素):
- 找有效键:遍历
active哈希表的bitmap(最多遍历 5 次,对应图里的bitmap[5]),找到第一个为 1 的比特位—— 这是当前有进程的 “最高优先级键” - 执行哈希映射:通过
f
(
有效键
)
=
有效键
f(有效键)=有效键
f(有效键)=有效键,映射到对应的哈希桶(比如有效键是 40,对应
queue[40]链表) - 取桶内元素:从该哈希桶的链表头部取出进程,让 CPU 切换到这个进程运行
4. 进程时间片耗尽→移到过期队列:哈希表间的 “键→桶” 迁移操作
进程时间片耗尽时(本质是从活跃哈希表删除元素,插入到过期哈希表):
- 从原哈希桶删除:通过进程的 “优先级键”,映射到
active哈希表的对应桶,将进程从该桶的链表中移除 - 标记键失效:若该桶的链表为空,将
active哈希表bitmap中对应键的比特位设为 0 - 更新原哈希表状态:
active哈希表的nr_active-- - 插入新哈希桶:通过同一个 “优先级键”,映射到
expired哈希表的对应桶(比如键是 40→expired->queue[40]链表),将进程插入该桶 - 标记新键有效:将
expired哈希表bitmap中对应键的比特位设为 1,同时expired哈希表的nr_active++
5. 活跃队列空了→交换两队列指针:哈希表的批量复用
当active哈希表的nr_active=0(所有元素都迁移到过期哈希表):交换active和expired的指针(本质是复用哈希桶数组,保持 “键→桶” 的映射关系不变):
- 原来的
active(指向array[0])现在指向array[1] - 原来的
expired(指向array[1])现在指向array[0]
整个流程的核心是:用 “进程优先级” 作为键,通过直接地址映射到固定的哈希桶(queue[优先级]链表),从而让插入、查找、迁移操作都保持 O (1) 时间复杂度
9. 命令行参数和环境变量
命令行参数:用户显式传递的启动指令
底层结构:argc+argv数组
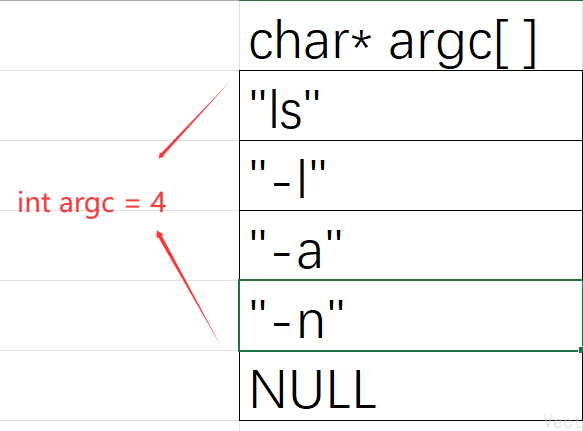
程序启动时,OS会将命令行参数组织成两个核心参数,传递给main函数
int argc:参数个数,至少为1,默认参数是程序自身的路径char* argv[]:参数数组,每个元素是指向参数字符串的指针,最后一个元素为NULL
核心原理:程序启动时的“数据注入”
在Linux系统里,当用户执行一个程序(如ls -l -a -n ...)时,OS会做三件事:
- 创建进程(分配内核数据结构)
- 将程序的代码和数据加载到内存中
- 把命令行参数和环境变量组成数据结构,如下图
对于ls -l -a -n ...这个命令,可以理解为这样的结构
代码1:
#include <stdio.h>
int main(int argc, char* argv[]){
printf("===命令行参数===\n");
printf("argc: %d\n",argc);
for(int i = 0; argv[i]; i++){
printf("argv[%d] = %s\n",i,argv[i]);
}
return 0;
}
输出结果:
[vect@VM-0-11-centos environ]$ gcc -std=c99 -o demand demand.c
[vect@VM-0-11-centos environ]$ ./demand
===命令行参数===
argc: 1
argv[0] = ./demand
代码2:
#include <stdio.h>
#include <string.h>
int main(int argc, char* argv[]){
// 第一步:检查参数个数,至少需要1个选项参数(argv[1])
if (argc < 2) { // 仅输入程序名,未传任何选项
printf("错误:未传入选项!\n");
printf("有效选项:-opt1 或 -opt2\n");
printf("使用示例:./a.out -opt1\n");
return 1; // 非0返回值表示程序异常退出
}
// 第二步:判断argv[1](唯一的选项参数位置)
if (strcmp(argv[1], "-opt1") == 0) {
printf("程序选项1\n");
} else if (strcmp(argv[1], "-opt2") == 0) {
printf("程序选项2\n");
} else {
printf("错误:无效选项「%s」!\n", argv[1]);
printf("有效选项:-opt1 或 -opt2\n");
return 1;
}
return 0;
}
输出结果:
[vect@VM-0-11-centos environ]$ gcc -o demand demand.c
[vect@VM-0-11-centos environ]$ ./demand
错误:未传入选项!
有效选项:-opt1 或 -opt2
使用示例:./a.out -opt1
[vect@VM-0-11-centos environ]$ ./demand -opt1
程序选项1
[vect@VM-0-11-centos environ]$ ./demand -opt2
程序选项2
[vect@VM-0-11-centos environ]$ ./demand -op3
错误:无效选项「-op3」!
有效选项:-opt1 或 -opt2
为什么要设计命令行参数?
解决程序静态性和运行动态性的矛盾->让同一个程序,可以根据命令行参数,指定不同的选项,实现不同的功能。就像我们熟悉的ls是程序,-a -l是不同选项,同一个程序用不同的选项实现不同的功能
-
动态传递配置,无需修改代码
命令行参数让程序无需重新编译,通过不同参数实现不同功能
-
标准化进程启动接口
所有程序都通过
argc/argc接收外部配置,形成统一规范,OS只用按照固定的方式传递参数,不用关心程序内部逻辑->做到OS管理资源,程序专注业务的解耦 -
支持自动化脚本调用
命令行参数可被
Shell脚本批量传递
再来一段代码:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main(int argc, char* argv[]){
// 无效参数提示
if(argc < 2){
printf("当前指令错误!用法:\n");
printf("选项: -add\r -sub\r -mul\r -div\n");
printf("示例: ./calculate -add 10 20 -->计算10+20\n");
return 1;
}
if(argc != 4){
printf("参数个数错误!每个运算需要传入两个数字!\n");
return 1;
}
int num1 = atoi(argv[2]);
int num2 = atoi(argv[3]);
if (strcmp(argv[1], "-add") == 0) {
// 加法:num1 + num2
} else if (strcmp(argv[1], "-sub") == 0) {
printf("%d - %d = %d\n", num1, num2, num1 - num2);
} else if (strcmp(argv[1], "-mul") == 0) {
printf("%d × %d = %d\n", num1, num2, num1 * num2);
} else if (strcmp(argv[1], "-div") == 0) {
if (num2 == 0) {
printf("错误:除数不能为0!\n");
return 1;
}
printf("浮点数结果:%d ÷ %d = %.2f\n", num1, num2, (float)num1 / num2);
} else {
// 无效选项提示
printf("无效选项「%s」!\n", argv[1]);
printf("支持的选项:-add -sub -mul -div\n");
return 1;
}
return 0;
}
输入输出示例:
[vect@VM-0-11-centos environ]$ ./calculate
当前指令错误!用法:
-div -add
示例: ./calculate -add 10 20 -->计算10+20
[vect@VM-0-11-centos environ]$ ./calculate -mul 19 21
19 × 21 = 399
[vect@VM-0-11-centos environ]$ ./calculate -div 19 12
浮点数结果:19 ÷ 12 = 1.58
环境变量
什么是环境变量
环境变量是OS用来指定运行环境的参数,有两个核心特性:
- 全局性: 可以被子进程继承(OS在创建子进程时,会自动拷贝父进程的环境表)
- 配置统一: 帮助程序解决“找不到依赖”的问题(如编译器找动态库、Shell找命令路径),避免每个进程重复匹配
举个例子:
写的一个C程序编译生成a.out,运行时需要链接glibc库。不用告诉程序glibc在哪里——OS 会通过环境变量提前配置好库的搜索路径,程序启动时OS会自动读取环境变量,帮程序找到依赖库
常见的环境变量
| 环境变量 | 作用 | 例子 |
|---|---|---|
PATH | 指定「命令搜索路径」:OS 执行命令时,会遍历PATH中的目录找可执行文件 | 为什么ls能直接运行?因为/bin/ls在PATH中;而自己写的a.out需要./a.out(带路径),因为它不在PATH中 |
HOME | 指定用户家目录:OS 为不同用户(root / 普通用户)分配独立工作空间,统一默认路径 | root 用户echo $HOME输出/root,普通用户输出/home/xxx;cd ~本质是进入HOME指定的目录 |
SHELL | 指定当前终端的解释器:OS 为用户提供统一的命令交互接口 | 通常值为/bin/bash,表示 OS 使用 bash 作为默认 Shell,所有命令输入都由 bash 解析后交给 OS 执行 |
环境变量的使用:OS提供的操作接口
OS提供了命令行工具和系统调用,让用户/程序能直接操作它
用户级接口
echo $NAME:查看某个环境变量值[vect@VM-0-11-centos ~]$ echo $PATH /usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/vect/.local/bin:/home/vect/bin
export NAME=value: 新增/修改环境变量
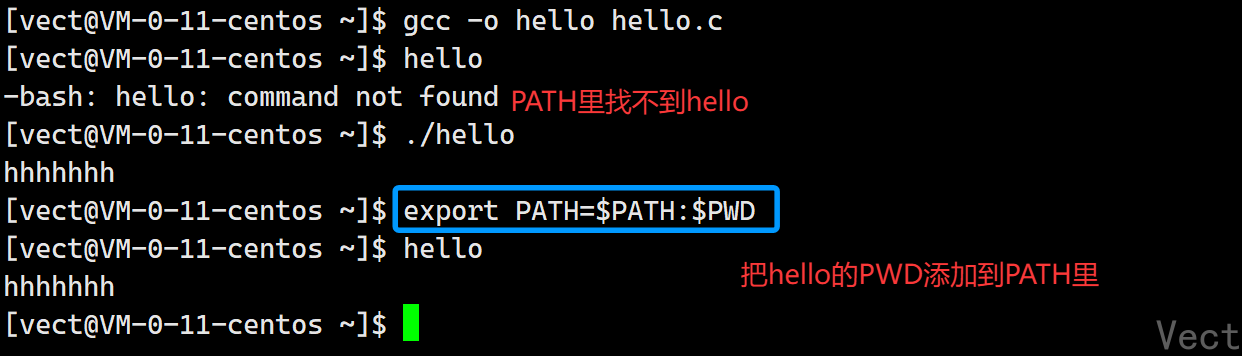
解析一下:
hello所在的当前目录./不在PATH中,OS找不到,添加之后,OS便能在PATH中找到hello->这就是ls直接能运行的原理!
env:查看所有环境变量
截取了几个关键的环境变量,这个显式格式是
KEY=VALUE键值对模型,所以环境变量是以键值对形式存储的!
unset NAME:清除环境变量
set:查看本地Shell变量+环境变量:包含env的输出并多了Shell的本地临时变量
我们再来看两个例子:
#include <stdio.h>
#include <stdlib.h>
int main(){
char* env = getenv("MYENV");
if(env == NULL){
printf("未找到\n");
}else{
printf("成功读取MYENV:%s\n",env);
}
return 0;
}
[vect@VM-0-11-centos environ]$ MYENV="hello"
[vect@VM-0-11-centos environ]$ vim find_myenv.c
[vect@VM-0-11-centos environ]$ gcc -o find_myenv find_myenv.c
[vect@VM-0-11-centos environ]$ ./find_myenv
未找到
分析:
MYENV="hello":OS不会将MYENV写入Shell的环境表中(OS只把export的变量写入环境表),MYENV属于本地变量,存储在Shell进程的私有内存中- 运行
./find_myenv:OS创建子进程执行程序,OS复制Shell的环境表给子进程(没有MYENV),程序调用getenv("MYENV"),遍历子进程的环境表,找不到对应数据
[vect@VM-0-11-centos environ]$ export MYENV="hello"
[vect@VM-0-11-centos environ]$ ./find_myenv
成功读取MYENV:hello
分析:
export MYENV="hello":OS将MYENV写入环境变量表中- 运行
./find_myenv:OS创建子进程执行程序,OS复制Shell的环境表给子进程(有MYENV),程序调用getenv("MYENV"),遍历子进程的环境表,找到对应数据
总结:环境变量是进程的全局配置,OS 在创建子进程时,会复制父进程的 PCB、内存空间,同时也复制环境表—— 保证子进程继承父进程的运行环境,无需重新配置
操作环境变量:OS提供的系统调用接口
命令行第三个参数env[]
OS在启动进程时,会将环境变量表作为第三个参数传给main
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[], char* env[]){
for(int i = 0; env[i]; i++){
printf("%s\n",env[i]);
}
return 0;
}
全局变量environ
OS在libc中提供了全局变量environ,直接指向环境变量表(不用传递参数)
#include <stdio.h>
extern char** environ; // 不在头文件中,需要提前声明
int main(){
for(int i = 0; environ[i]; i++){
printf("%s\n",environ[i]);
}
return 0;
}
系统调用getenv/putenv
int main(){
char* path = getenv("PATH");
printf("PATH:%s\n",path);
putenv("MYENV=hhhh"); // 设置环境变量
return 0;
}
10. 进程地址空间
程序地址空间
先来看一个有趣的现象:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int global = 10;
int main(){
pid_t ret = fork();
if(ret < 0){
perror("fork err\n");
return 1;
}else if(ret == 0){
// 子进程
while(1){
printf("I am child process,pid:%d,ppid:%d,global:%d,global pos:%p\n",getpid(),getppid(),global, &global);
++global;
sleep(1);
}
}else{
// 父进程
while(1){
printf("I am father process,pid:%d,ppid:%d,global:%d,global pos:%p\n",getpid(),getppid(),global, &global);
sleep(5);
}
}
return 0;
}
输出: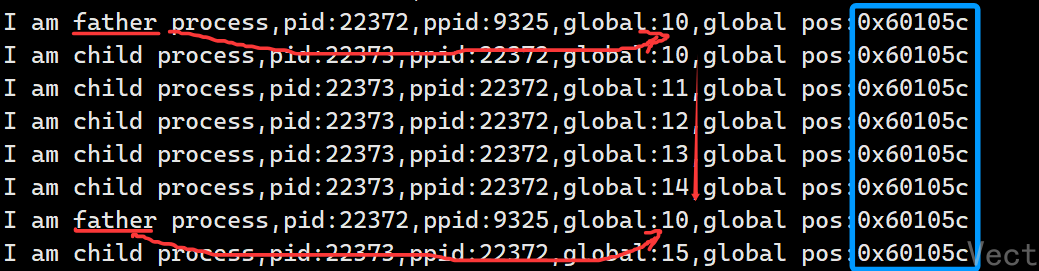
父进程和子进程的数据是各自独立,代码是共享的,这个我们已经了解,但是为什么global的地址一直没有变化?
我们根据输出内容可以推断出:
- 输出的内容不一样,所以父子进程输出的变量绝对不是同一个变量!
- 不同的变量却有相同的地址,说明这个地址一定是虚拟的!
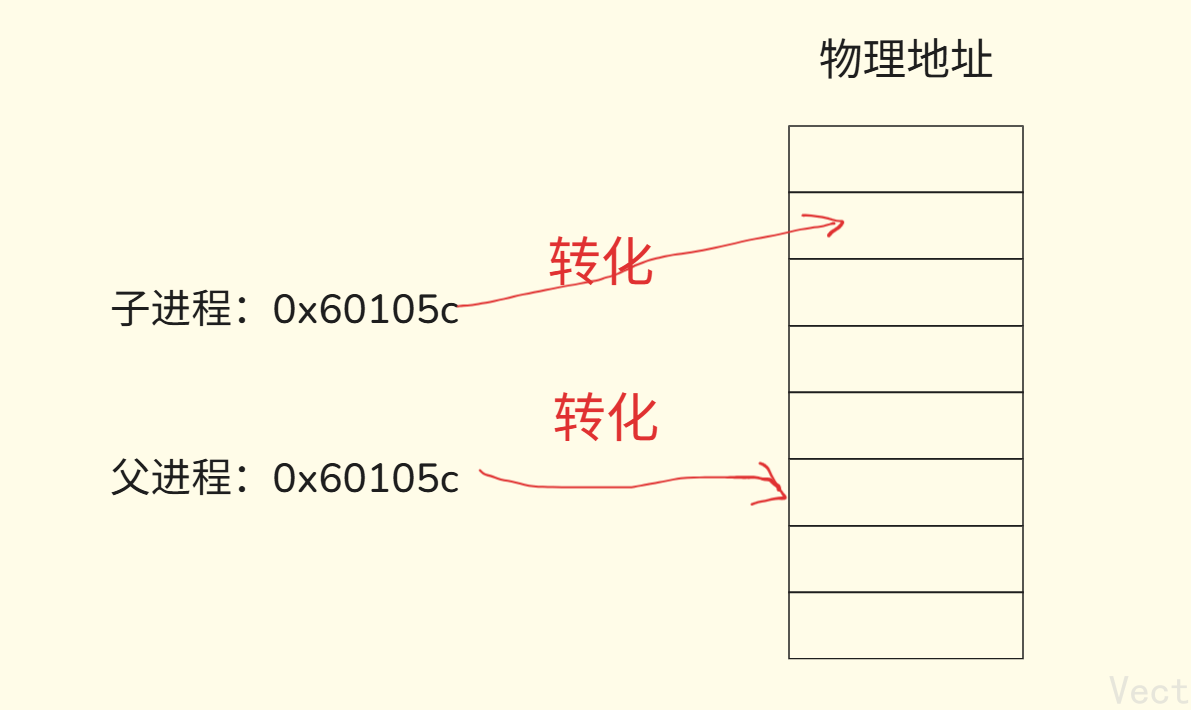
其实,用户层面看不到真实的物理地址,我们能看到的只有虚拟地址!!!
实际的物理地址是由OS统一管理的,OS系统把虚拟地址转化成物理地址
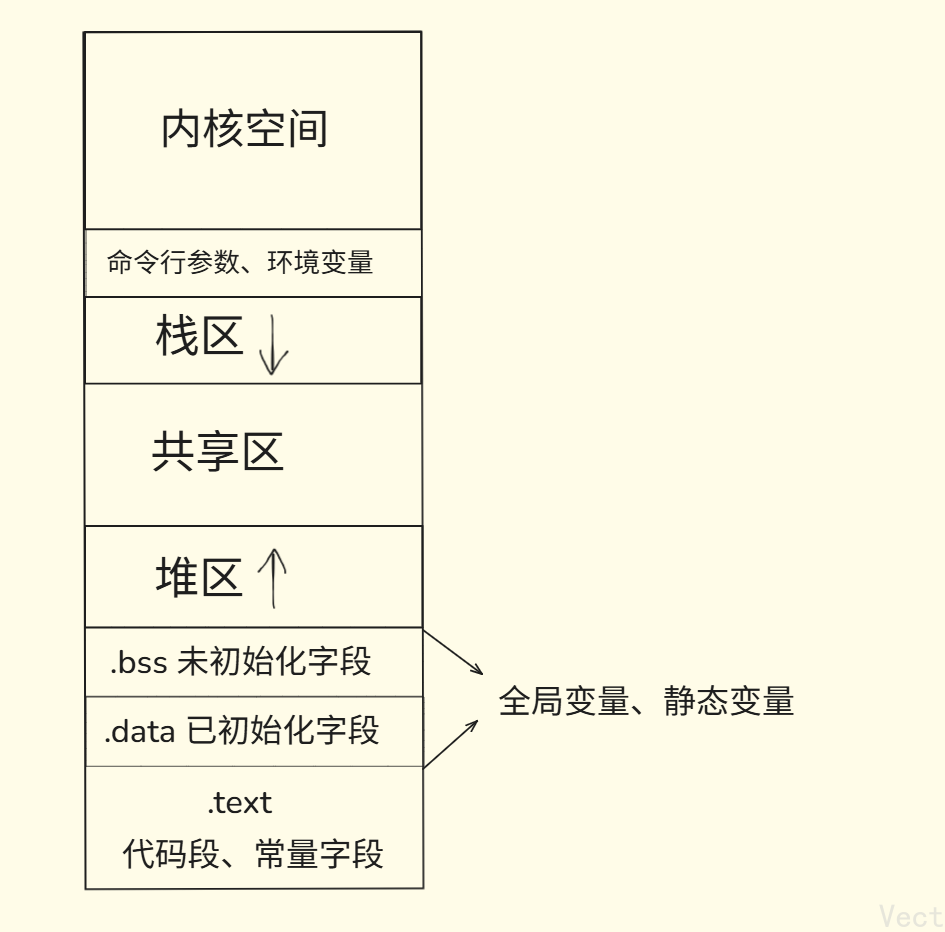
再来回忆一下以前的程序内存布局图:
代码验证:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int global_val = 10;
int g_val;
int main(int argc, char* argv[], char* env[]){
const char* str = "hello";
printf("code addr: %p\n",main);
printf("init global_val addr: %p\n",&global_val);
printf("uninit g_val addr: %p\n",&g_val);
static int test_val = 1;
char* heap_mem1 = (char*)malloc(10);
char* heap_mem2 = (char*)malloc(10);
char* heap_mem3 = (char*)malloc(10);
printf("haep addr: %p\n",heap_mem1);
printf("haep addr: %p\n",heap_mem2);
printf("haep addr: %p\n",heap_mem3);
printf("test_val static addr: %p\n",&test_val);
printf("stack addr: %p\n",&heap_mem1);
printf("stack addr: %p\n",&heap_mem2);
printf("stack addr: %p\n",&heap_mem3);
printf("read only string add: %p\n",str);
for(int i = 0; i < argc; i++){
printf("argv[%d]: %p\n",i,argv[i]);
}
for(int i = 0; env[i]; i++){
printf("env[%d]: %p\n",i, env[i]);
}
return 0;
}
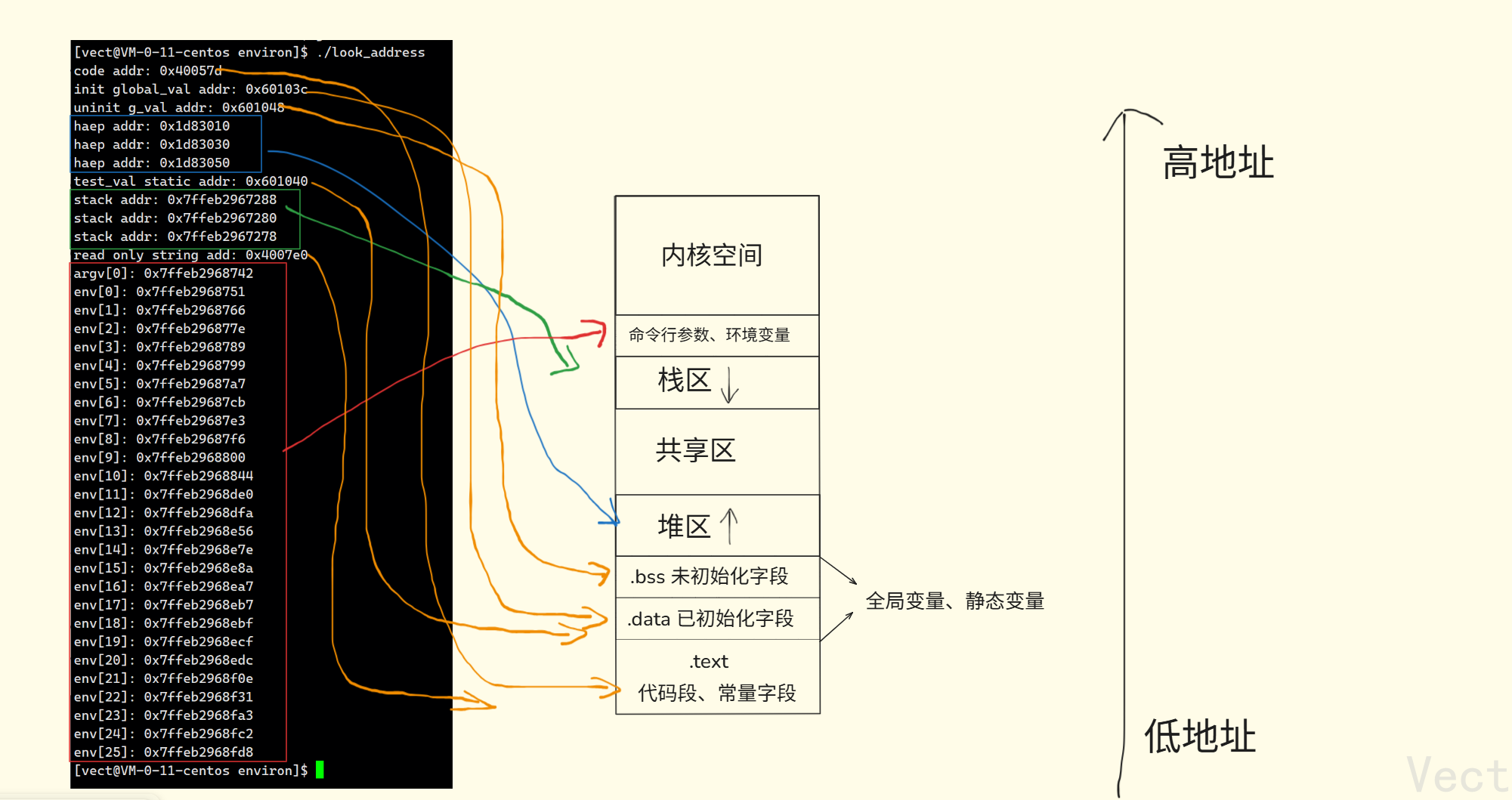
进程地址空间
所以以前所说的程序的地址空间是有些问题的,确切地说是进程地址空间,那张内存布局图应该叫进程地址空间
进程空间地址本质是内核数据结构对象(类似PCB),在Linux中由结构体mm_struct实现
如何理解进程地址空间呢?
进程地址空间类似与一把尺子,尺子的刻度由
0x00000000到0xffffffff,按照刻度被划分为各个区域->代码区、堆区、栈区等等在
mm_struct中,记录了各个边界刻度,如下图所示:
怎么完成区域划分呢?类比”38线“->一条线划分出两个区间,我们知道区间的起始值和结束值,便可划分出一个区域!

在mm_struct中,每个刻度都代表一个虚拟地址,这些虚拟地址通过页表映射与物理内存建立联系。由于地址是从0x00000000到0xffffffff线性增长的,所以虚拟地址又叫做线性地址
所以:
- 堆向上增长以及栈向下增长实际就是改变
mm_struct中栈和堆的边界数值->好比改变“38线”的位置,两个人的所占空间就改变!- 我们生成的可执行程序实际上也被划分为了各个区域,例如初始化区域,未初始化区域、代码段、只读数据段。当可执行程序运行起来,OS则将对应的数据加载到对应内存中即可,大大提高了OS的操作效率,而进行可执行程序的分区操作,实际上是编译器的操作,我们所说的代码优化级别实际上是编译器掌握的
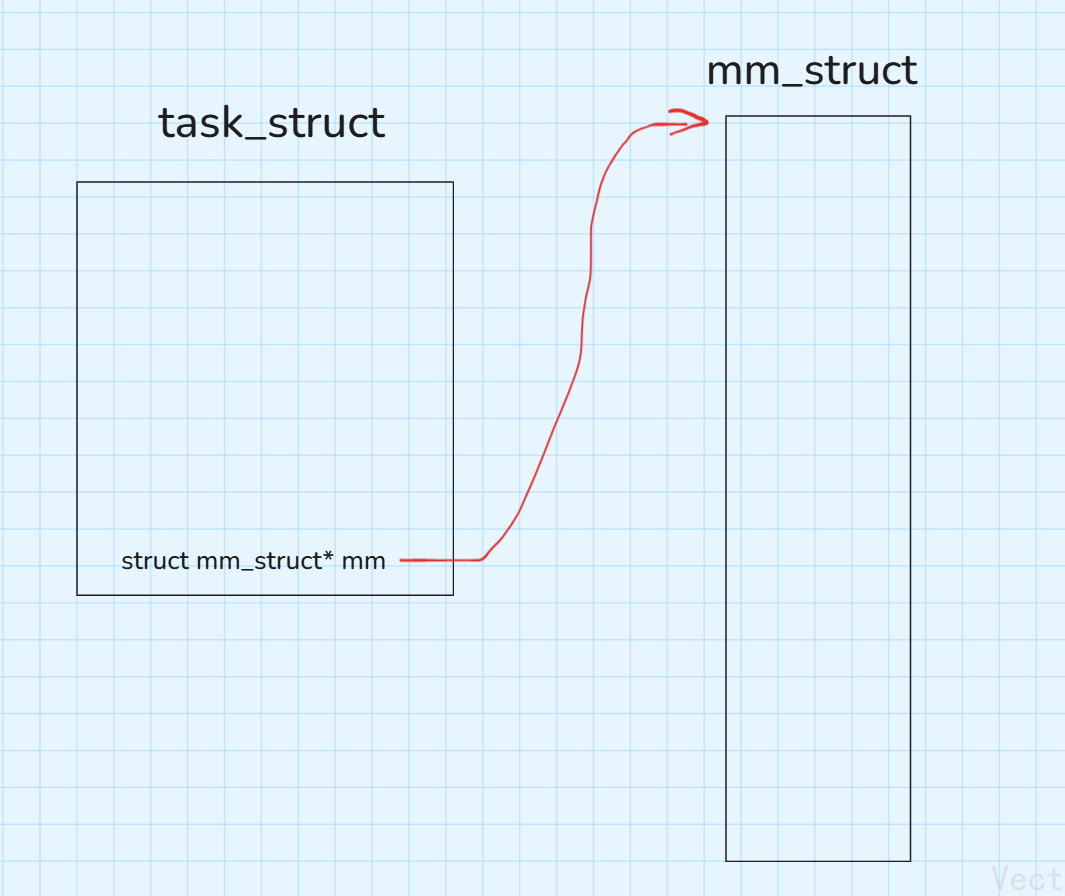
每个进程被创建是,对应的task_struct和mm_struct也会被创建。OS可以通过进程的task_struct找到mm_struct,因为task_struct中有一个结构体指针存的是mm_struct的地址
例如:父进程有自己的task_struct和mm_struct,该父进程创建的子进程也有自己的task_struct和mm_struct,父子进程的mm_struct当中的各个虚拟地址分别通过页表映射到物理空间的具体位置,如下图:
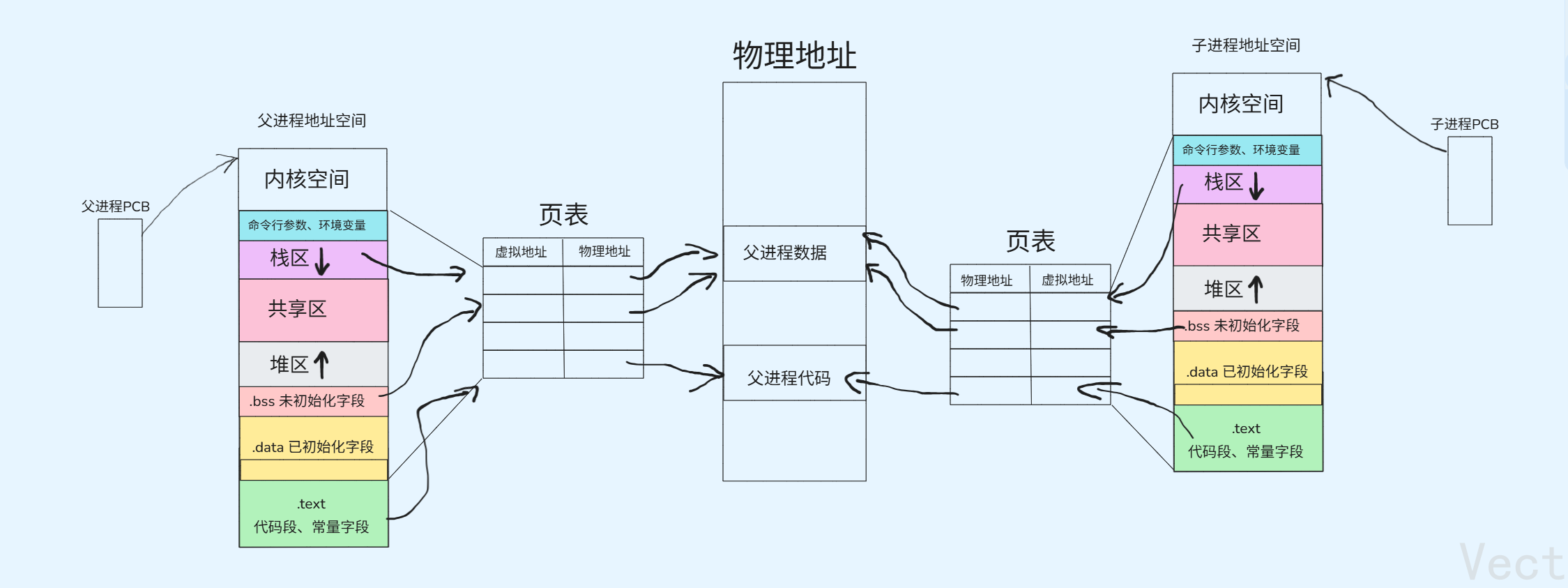
当子进程被创建时,子进程和父进程的,代码和数据是共享的,即父子进程的代码和数据通过页表映射到物理内存的同一块空间。只有当父进程或子进程需要修改数据的时候,才将进程的数据在内存中拷贝一份,然后进行修改
例如,子进程修改global_val的值,那么此时就在内存中的某处存储global_val的新值,并且改变子进程中的global_val的虚拟地址,这个过程通过页表映射即可完成。
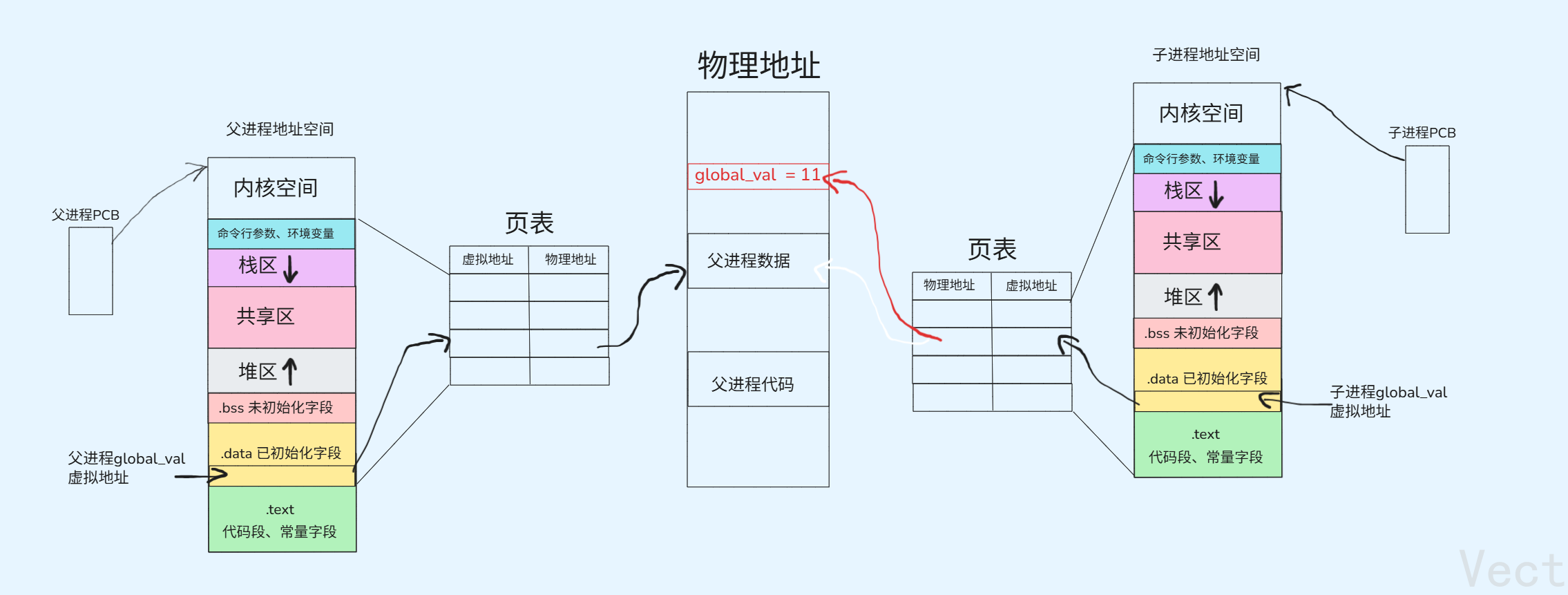
这种方式叫做写时拷贝
为什么要写时拷贝?
进程间具有独立性。多进程运行,需要独享资源,确保多进程运行期间互不干扰,子进程的修改不能干扰父进程
为什么不在创建子进程时就拷贝数据?
子进程不一定会使用父进程的所有数据,并且子进程不对数据写入的情况下,没有必要对数据进行拷贝,按需分配即可,这样可以高效利用空间
总结几个问题
程序加载到内存中的过程
- OS初始化进程的虚拟地址空间->创建
mm_struct,调整区域划分(在编译时,代码段,未初始化字段、初始化字段、只读字段就已经划分好了)- 加载进程(OS创建堆区、栈区、命令行参数和环境变量),申请物理空间
- 将虚拟地址和物理地址通过页表映射
为什么需要虚拟地址和页表?
虚拟地址和页表能保护内存->页表还有个
rwx的标记位,可以判定原有内存数据的权限什么是野指针?
指针指向被释放或未知的地址->物理内存被释放了->对应的页表虚拟地址和物理地址数据要删除,映射关系没了->此时要访问这个空间,查询页表会失败,OS直接杀掉进程->所以,野指针行为可能导致程序崩溃!
为什么
char* str = "hh"; *str = "hhhhhh";能编译通过,但运行时崩了?字符串常量所在的虚拟内存页被页表标记为只读,写操作被硬件和操作系统拦截->所以引入
const关键字,在编译层面先做一层保护!让进程管理和内存管理在OS层面解耦合
进程管理只关心虚拟地址,完全屏蔽物理内存
->创建进程,只需初始化
mm_struct、进程调度,秩序切换页表寄存器、进程销毁,秩序释放页表和mm_struct->完美做到进程隔离,每个进程一份独立页表,保证进程间独立性内存管理只关心物理地址,完全屏蔽进程身份
->分配物理内存,只需按页表分配,更新页表映射关系、回收物理内存,只需检查页表引用位/脏位判断是否被使用、内存共享,只需让多个进程的页表映射到同一物理页
全局变量、字符常量为什么有常性?
在虚拟地址空间中,全局变量存在未初始化区、字符常量存在只读字段区,随着进程一直存在,他们的地址能被所有类和函数看到
申请堆空间,是开辟物理空间吗?
不是!本质是把虚拟空间扩大,改变堆区的起始值和结束值就能做到,在使用时才开辟物理空间

















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









