



 箱线图是一种用于展示数据分布和异常值的统计图表,通过直观地观察中位数、四分位数和离群点,帮助分析数据集中值的范围和集中趋势。本文介绍了箱线图的特点、优点与局限性,并展示了如何在实际数据分析中使用它。
箱线图是一种用于展示数据分布和异常值的统计图表,通过直观地观察中位数、四分位数和离群点,帮助分析数据集中值的范围和集中趋势。本文介绍了箱线图的特点、优点与局限性,并展示了如何在实际数据分析中使用它。
箱线图(Box Plot)
又称为盒须图、盒式图、盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因图形如箱子,且在上下四分位数之外常有线条像胡须延伸出去而得名
箱线图可以显示属性值的分布,快速发现异常,例如重复的值,离群值等,挖掘数据的分布规律
输入
数据:输入数据集
输出
选中的数据:从图中选中的实例
数据:带有额外一列,显示点是否被选中
箱形图小部件显示属性值的分布。使用此小部件检查任何新数据是一个好习惯,
可以快速发现任何异常,例如重复值(例如,灰色和灰色的值)、异常值等。
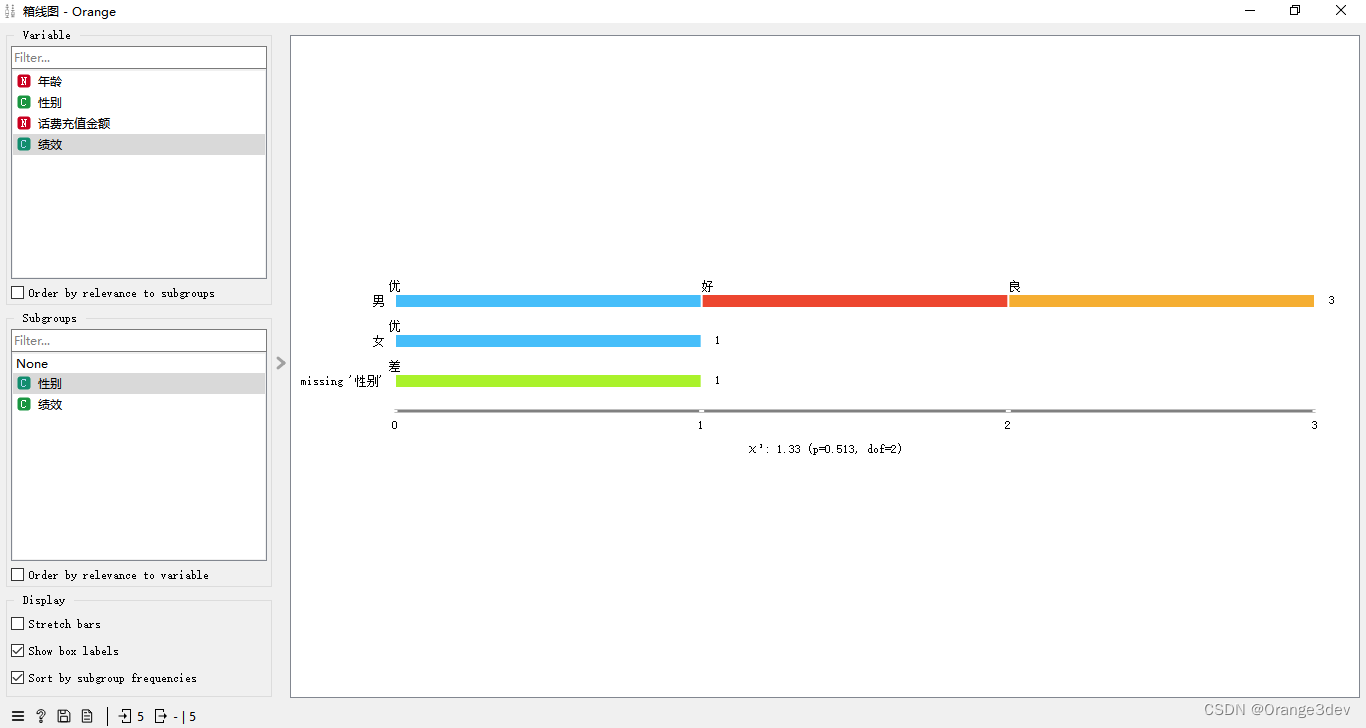
箱型图的特征
1.直观地观察到异常值,如果数据存在离群点,即位于上下边缘区域之外,以圆点的形式表示
2.当箱型图很短时,意味着很多数据多集中分布在很小的范围内
3.当箱型图很长时,意味着数据分布比较离散,数据间的差异比较大
4.当中位数接近底部时,说明大部分的数据值比较小
5.当中位数接近顶部时,说明大部分的数据值比较大
6.中位数所处的高低位置能反映数据的偏斜程度
7.如果上下虚线比较长,说明上下四分位数之外的数据变化比较大,整体数据的方差和标准偏差也比较大
8.箱型图的上下边缘并非最大值或最小值
箱型图的缺点
1.箱型图虽然能显示出数据的分布偏态,但是不能提供关于数据分布偏态和尾重程度的精确度量;
2.对于批量较大的数据批,箱线图反映的形状信息更加模糊;
3.用中位数代表总体平均水平有一定的局限性。
所以,应用箱线图最好结合其它描述统计工具如均值、标准差、偏度、分布函数等来描述数据批的分布形状。
详细说明
-
选择要绘制的变量。勾选“按与子组的相关性排序”以根据所选子组的Chi2或ANOVA对变量进行排序。
-
选择“子组”以查看由离散子组显示的箱线图。勾选“按与变量的相关性排序”以根据所选变量的Chi2或ANOVA对子组进行排序。
-
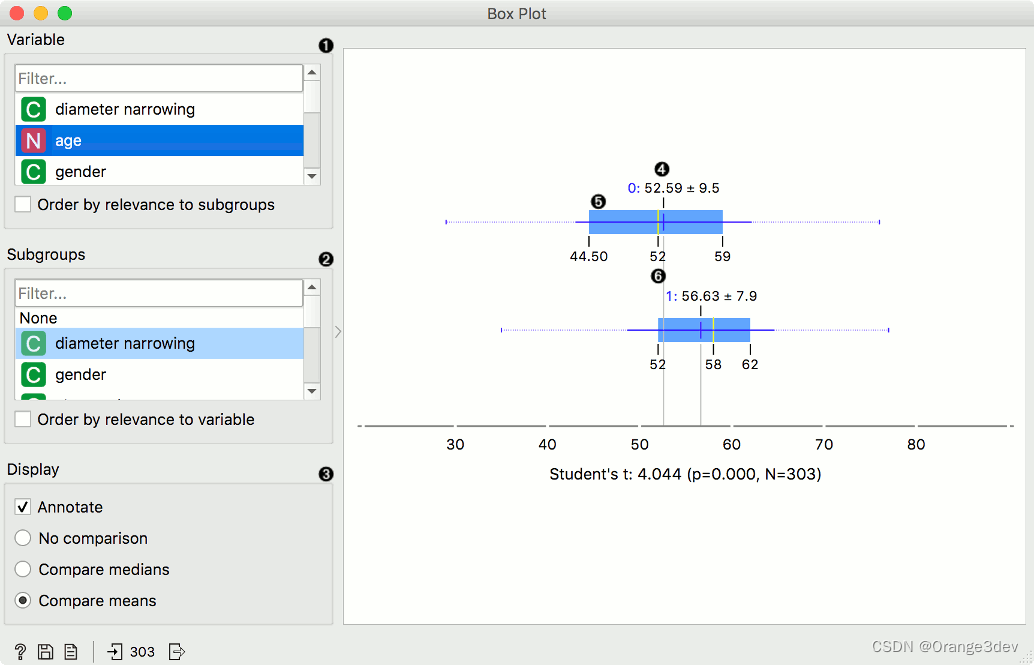
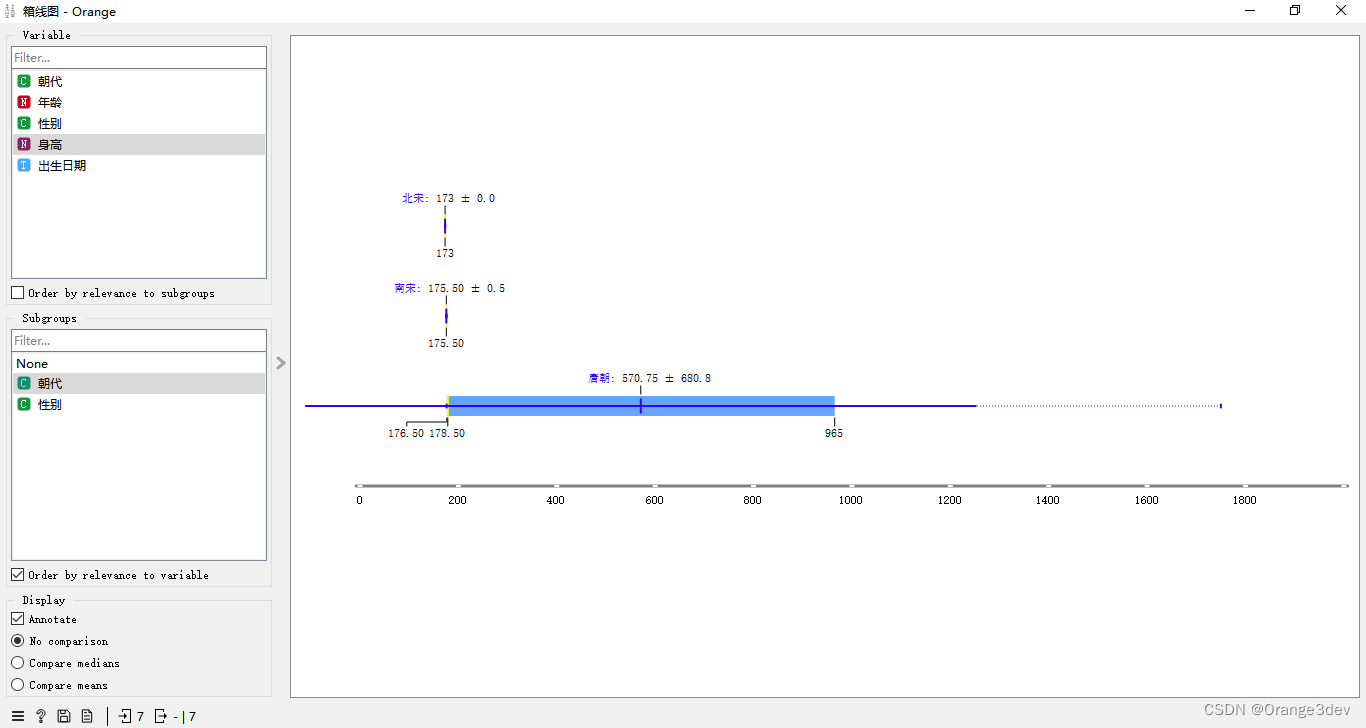
当实例按子组分组时,您可以更改显示模式。带注释的框将显示端值、平均值和中位数,而比较中位数和比较平均值将自然而然地在子组之间比较所选值。
-
-
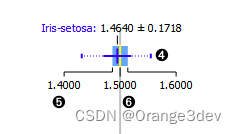
平均值(深蓝色垂直线)。细蓝色线代表标准差。
-
第一个(25%)和第三个(75%)四分位数的值。蓝色高亮区域表示第一个和第三个四分位数之间的值。
-
中位数(黄色垂直线)。
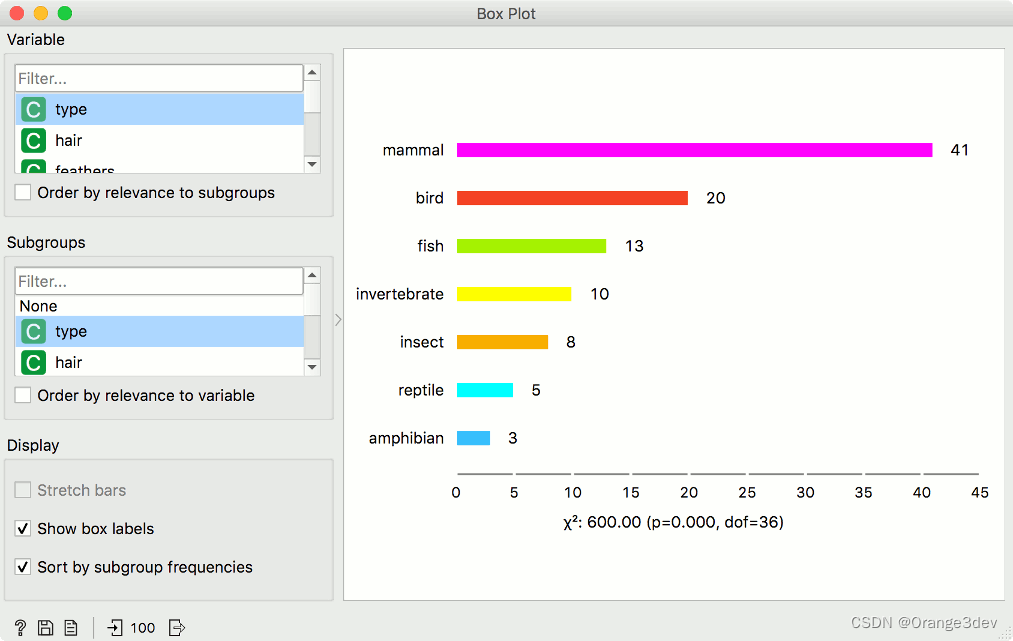
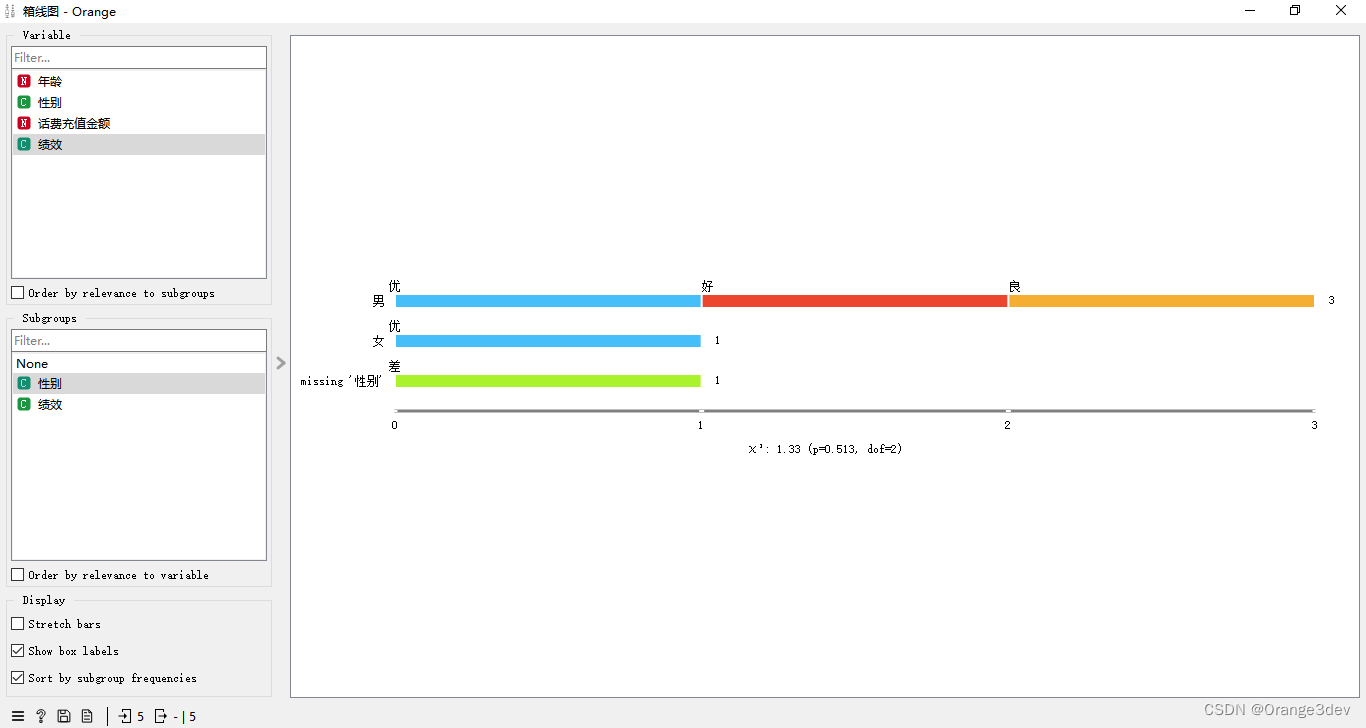
对于离散属性,条形图代表每个特定属性值的实例数量。该图显示了动物园数据集中不同动物类型的数量:有41种哺乳动物,13种鱼,20种鸟类等。
显示选项:
- 拉伸条形:显示数据实例的相对值(比例)。未勾选的框显示绝对值。
- 显示框标签:在每个条形图上方显示离散值。
- 按子组频率排序:按降序对子组进行排序。
示例
软件下载链接: https://pan.baidu.com/s/12drK7Mz7YSqrwIQk5Wh5cw?pwd=8tnd
视频教程:关注我不迷路, 抖音:Orange3dev
https://www.douyin.com/user/MS4wLjABAAAAicBGZTE2kX2EVHJPe8Ugk3_nlJk9Nha8OZh4Bo_nTu8
1-组件概览
2-树查看器-决策树
3-箱线图-离散属性分布
4-箱线图-要素计算
5-箱线图-连续属性分布
6-小提琴图
7-分布图
8-散点图-智能数据可视化
9-散点图-探索性数据分析
10-散点图-高亮选择数据
11-折线图
12-条形图
13-筛网图
14-马赛克图
15-自由投影
16-线性投影
17-雷达图
18-热力图
19-韦恩图
20-轮廓图
21-毕达哥拉斯树
22-毕达哥拉斯森林
23-CN2规则查看器
24-诺莫图

















 166
166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









