




组件介绍:
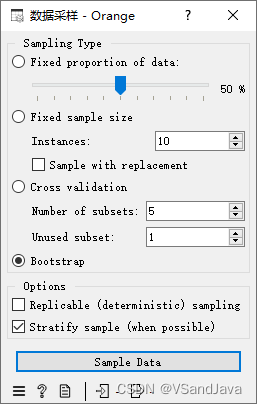
固定数据比例(Fixed proportion of data) 返回整个数据的选定百分比
固定样本量(Fixed sample size) 返回选定数量的数据实例,并可以设置 Sample with replacement(替换样本),该替换样本始终从整个数据集中进行采样(不减去子集中已有的实例)。 通过替换,您可以生成比输入数据集中更多的实例。
交叉验证(Cross validation) 将数据实例划分为指定数量的互补子集。交叉验证是一种评估机器学习模型性能的常用方法,其作用是通过将数据集分为几个互斥的子集(称作“fold”),然后对模型进行多次训练和测试,以评估其泛化能力。
自助采样(Bootstrap) 是一种常用的数据采样类型,它的作用在于用于建立稳健性较强的机器学习模型。
Bootstrap是一种有放回的重新采样方法,它会从原始数据集中随机采集一定量的样本,重复地采样多次,从而得到一组新的采样数据集。
这些新的采样数据集与原始数据集具有相同的大小,但由于采集方式不同,它们的样本和特征分布可能会有所不同,有助于减小因数据分布不均而导致的误差。
具体而言,使用Bootstrap方法可以补偿数据集样本数量不足,增加样本量;对于样本分布不平衡的情况,
可以采用Bootstrap来提高少数类别样本数量,从而避免由于类别不均造成的分类偏差;Bootstrap还可以用来模拟样本数量少的情况,从而评估机器学习模型的泛化能力。
在Orange3中,Bootstrap采样作为数据采样类型可用于构建机器学习模型时,
例如Classification Tree、Random Forest、Boo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3741
3741




 到【灌水乐园】发言
到【灌水乐园】发言







