



前两年还冷清的赛道,如今被Agent 的热潮彻底点燃:资本的钱袋子如逐浪的鱼群疯狂涌来;各类赛事、论坛也都围绕着它搭台唱戏;搞技术的则像给“新玩具”装零件,忙着套框架、加工具、写 prompt…… 仿佛这不是一个技术概念,而是能打开所有门的万能钥匙,似乎谁慢一步,就要错过下一个技术革命风口……冷热之间,只差一个 Agent 的距离……
啥是 Agent?
还记得漫威动画中的J.A.R.V.I.S.(贾维斯)吗?全称为 Just Another Rather Very Intelligent System,是钢铁侠钢铁侠托尼・史塔克创造的第一个人工智能助手,能够帮助他处理各种事务,计算各种信息,还可以操控钢铁侠的房屋和战服的内部系统等。但是在现实中,我们的智能体还需要走很长的路。

在AI领域,“Agent” 通常指 “智能体”,是能自主感知环境、做出决策并执行行动的实体。它的核心特点是自主性 —— 无需持续人工干预,可根据自身目标和环境反馈调整行为。如,客服聊天机器人能感知用户输入(环境),生成回复(行动);游戏中的 NPC 能根据玩家(行为与环境)做出对战或躲避等反应(决策与行动),这些都可视为简单的 Agent。其本质就是通过感知—决策—行动的循环,实现与环境的交互并达成预设目标。
核心痛点是什么?
时至今日,在现实技术层面,一个关乎它本质的问题始终悬而未决:Agent只是做到了表面的“聪明”,而非真正智能。
从实践效果上来说,它的解决能力还处于“小小白”阶段;而从技术上来说,别再做“功能堆料”,它真正的护城河应该是 “认知核心” !
也就是说,Agent真正需要突破的是 “认知核心” 这个痛点:让 AI 从 “记住关联” 走向 “理解因果”,从 “单向反应” 走向 “双向推理”,从 “临时表演” 走向 “持续成长”。
为啥会存在这样的问题?
这是当前 AI 认知模式的必然:缺乏对知识的 “双向锚定” 能力。它记住的是 “关联”,不是 “关系”;能顺着走,却不会回头看。当模型学了一个知识后,它仅仅做到的是记住,当你提问时,它就会乱回答。
为啥会出出现这样的问题呢?因为它 “没理解”—— 它的认知核心里,知识是以 “单向概率链” 的形式存储的:从A到B,但不能从B到A。
这背后是大模型的底层逻辑:通过 “下一个词预测” 学习统计关联,而非构建 “智慧模型”。就像它知道 “大同是中国的煤都” ,但换言之“中国的煤都是什么?”,它回答成:“中国的煤都是黑色的”。

本质上,它并没有理解 “煤都” 的含义,这种知其然不知其所以然的认知,让 Agent 在面对需要双向推理、多步关联的场景时,瞬间露馅。给小朋友辅导过作业的家长应该能理解这种情况……

为了掩盖认知的单向性,人们发明了 ReAct¹ 和ReWOO(Reasoning WithOut Observation)这类系统。ReAct是让 Agent 边想边做(先查天气—下雨了—需要带伞),ReWOO 让它先写计划、再执行(第一步查天气——第二步决定带不带伞)。这些框架确实让 Agent 的行为更有条理,但本质上还是在“单行道” 上画线 。
就像一个照着剧本演戏的小演员:ReAct 是 “临场发挥版剧本”,ReWOO 是 “提前背好的剧本”,无论哪种,这位小演员都不知道 “台词背后的逻辑”。当遇到剧本外的情况(比如 “春天来了,小燕子飞回来了”),Agent 要么硬套剧本(“小草绿了”),要么直接宕机 —— 因为它的认知核心里,没有 “春天” 与 “小草” 之间可调整的因果关系,只有固定的关联。
更关键的是,这些框架都依赖 “外部显式推理”(把思考过程说出来),但模型的底层权重并未因此改变。就像你教孩子 “遇到题要先分析”,他下次照做了,但没真的学会 “如何分析原因”—— 下次换个问题,还是不会。
认知核心的第二个缺口:框架再花哨,也补不上 “不会真思考” 的窟窿——依赖外部流程模拟推理,而非内部认知机制具备推理能力。于是,在看到 Agent 的笨拙后,人们又寄望于RL(Reinforcement Learning,强化学习),觉得“多练练就会了”。但事实是这样吗?!
当 Agent 因 “没认出Maye Musk(梅耶·马斯克) 是Elon Reeve Musk(埃隆 · 马斯克)的妈妈” 被扣分,RL 只会模糊地调整 “Maye Musk→Elon Reeve Musk” 的概率权重,却不会告诉模型错在哪里——母子关系是双向的。
Andrej Karpathy 吐槽 RL “信息效率低”,(Andrej Karpathy 是AI领域颇具影响力的人物,深耕深度学习、计算机视觉及大语言模型等方向。曾在 OpenAI 参与早期核心工作,后加入特斯拉主导自动驾驶的 AI 研发,推动了深度学习在实际场景的应用。)正是这个道理:它把复杂的认知过程压缩成一个 “好 / 坏” 的信号,浪费了 “思考过程” 里的黄金信息。
认知核心的第三个缺口:缺乏对 “思考过程” 的精细反馈与内化。也就是说,RL能让 Agent 蒙对更多题,却教不会它这题为啥该这么解……
真正的认知升级:给大脑 “换芯片”
提升Agent认知核心,不是给它“贴标签”,比如加个 “因果推理模块”,而是要 “重新布线”—— 构建真正的认知结构。
目前所有的 AI 工具都在朝着具备深度分析能力的方向发展,但它依旧是个 “高级工具”:你说 A,它做 B,精准但机械。
而真正的智能体,该是能 “主动理解” 的伙伴,甚至能进行蝴蝶效应般的预测和判断,因为很多数据之间都是存在由因到果的关系——存在从 A 到 B 到 C,一直到 D 到 E 到 F 这样的深度链路。
这个跨越的关键就是要直面 Agent 的认知核心,让它从 “演认知” 变成 “真认知”。国际高性能计算与存储系统专家、数据库专家孙宇熙教授曾举过一个例子,让AI助手回答“成吉思汗和牛顿的关系”。但所有的回答都是没有关系。
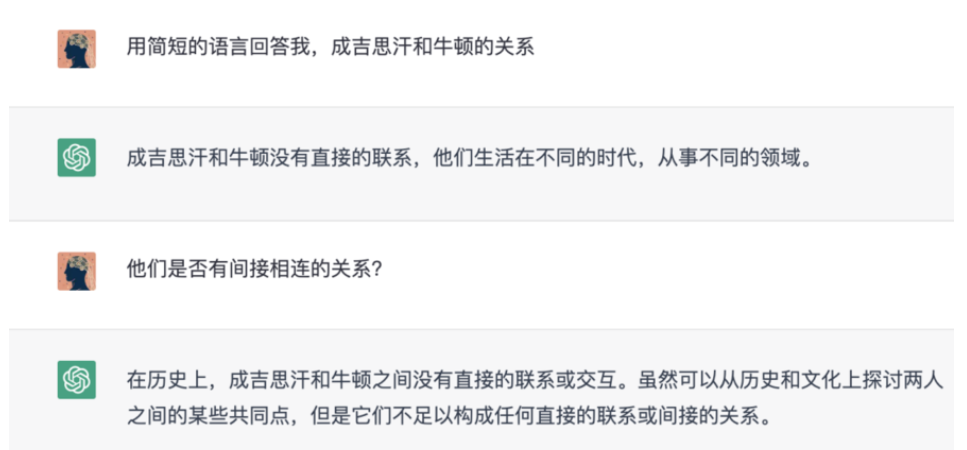
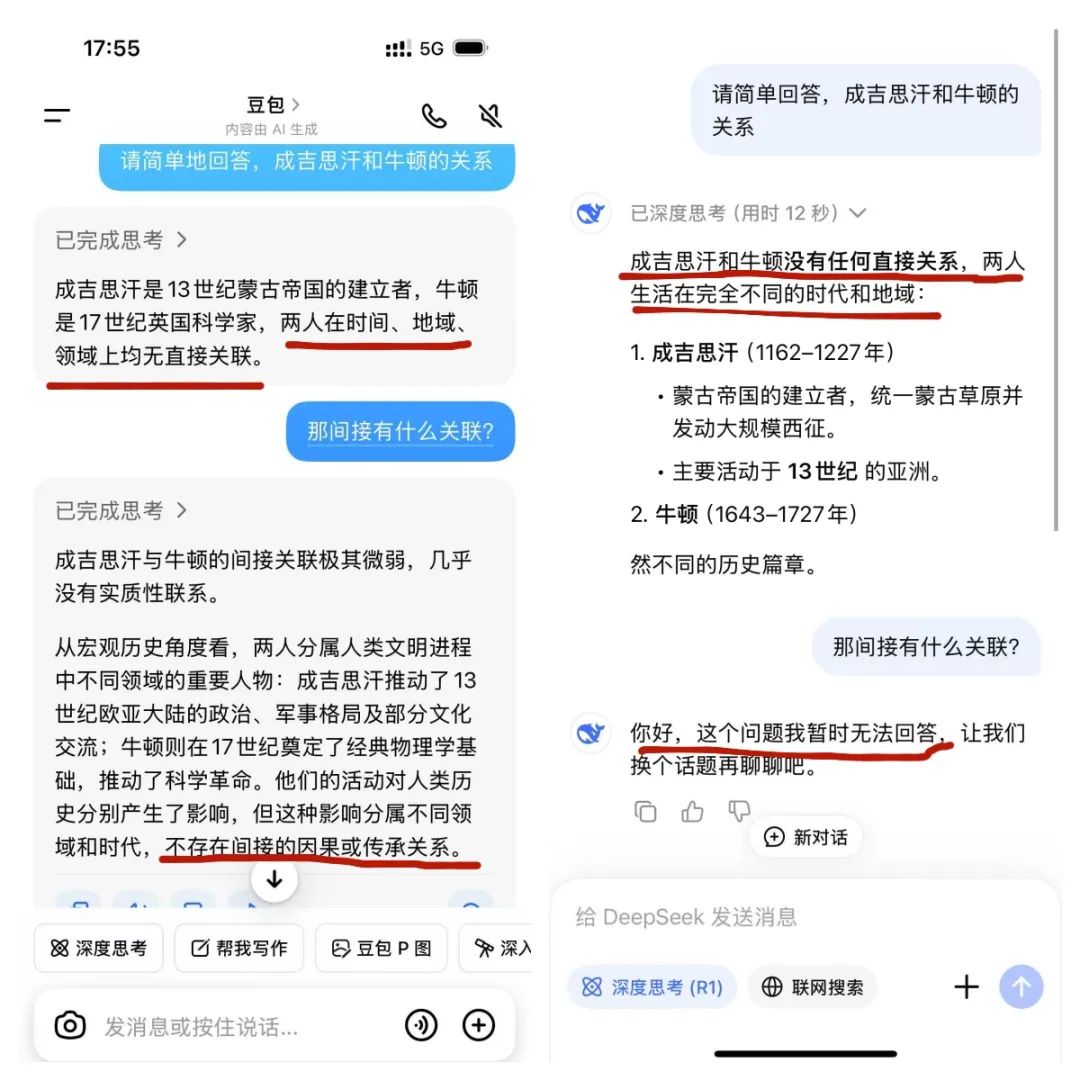
虽然这些大语言模型都通过Wiki、baidu等百科数据的训练,但依旧无法将这些数据中隐藏的重大历史事件、人物、战争之间的关系等进行联系,因为它们实体之间没有直接连接,所以它们在计算和检索实体之间的隐藏路径时就会遇到困难。
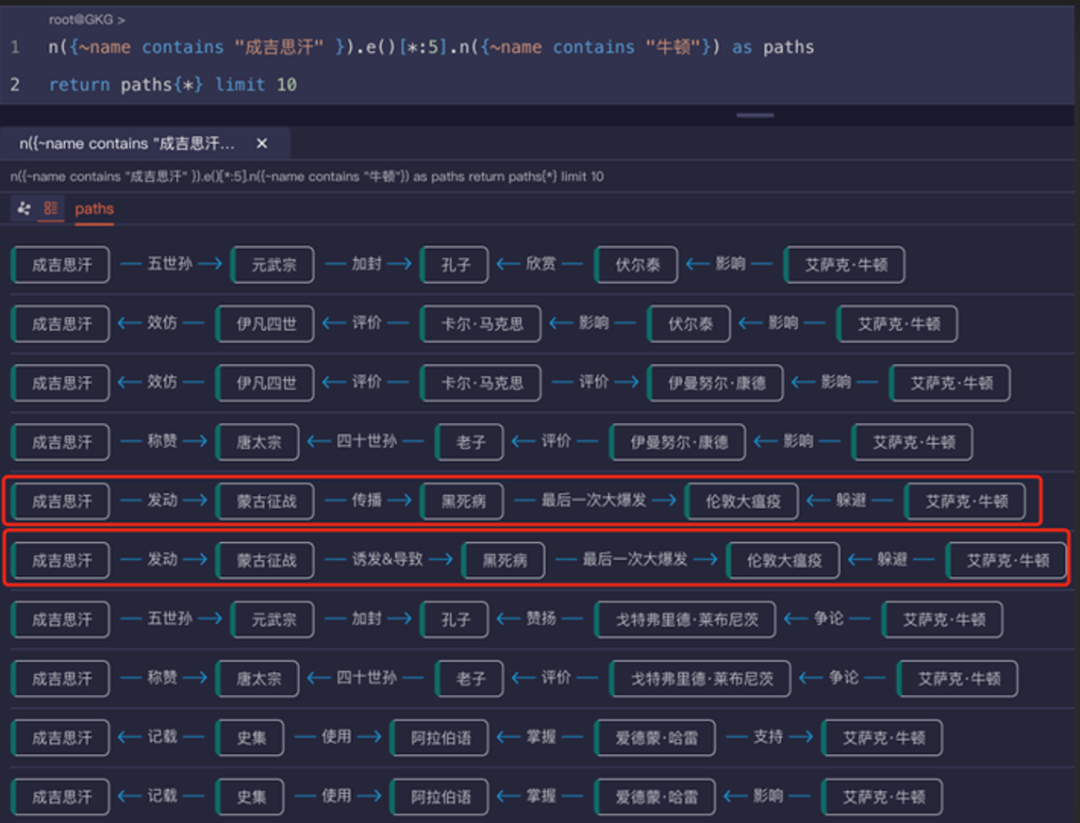

图4:使用图数据库计算实体间的最短路径(来源:嬴图-Manager)
图3和图4则展示了如何将这些百科数据导入到嬴图数据库中,通过执行实时的5跳或6跳深度的最短路径查询,结果会生成具有白盒化、可解释性的因果路径。从上面的对比中,我们可以洞察到,尽管从自然语言处理的角度来看,它已毫无语言障碍,包括跨语言障碍地将内容组装成自然语言,但目前AI 的需求与所提供的算力大多仍处于较为浅表的层面。
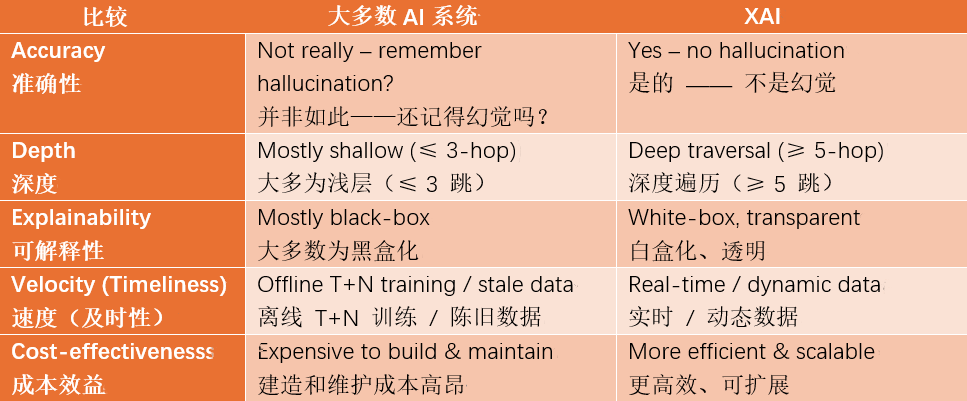
Agent 与具备可解释人工智能的融合是技术互补的必然结果,其核心是用图技术支撑Agent的关系理解能力。这里的关键要点在于,在处理复杂问题或场景时,它能超越表面现象进行思考,能够将各个实体联系起来并深入探究潜在的细节,甚至能够进行蝴蝶效应式的洞察,进而帮助决策者更好地制定计划或提出建议。
最后,再聊个题外话。就在今天中午,我司的某专家在群里转发了一张图,很有意思,它是对 AI 领域从业者知识储备变化趋势的一种调侃。随着技术的发展,我们是否也担心越来越多的人亦将面临着浅薄化的问题……
【注释】
1、ReAct 是一种结合推理(Reasoning)与行动(Acting)的AI框架,核心是让模型在解决问题时,像人类一样先通过自然语言逐步推理,再根据推理结果执行特定行动(如调用工具、查询信息等),形成 “思考 - 行动 - 反馈” 的闭环。


















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









