






Transformer 模型是一种基于自注意力机制(Self-Attention)的深度学习架构,彻底革新了自然语言处理(NLP)、计算机视觉(CV)等序列数据处理领域。其核心设计摒弃了传统循环神经网络(RNN)的顺序依赖性,实现了高效并行计算与长距离依赖捕捉能力
1 核心架构与机制
Transformer 模型是一种基于注意力机制的深度学习模型,最初由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。
Transformer 彻底改变了自然语言处理(NLP)领域,并逐渐扩展到计算机视觉(CV)等领域。
Transformer 的核心思想是完全摒弃传统的循环神经网络(RNN)结构,仅依赖注意力机制来处理序列数据,从而实现更高的并行性和更快的训练速度。
以下是 Transformer 架构图,左边为编码器,右边为解码器。
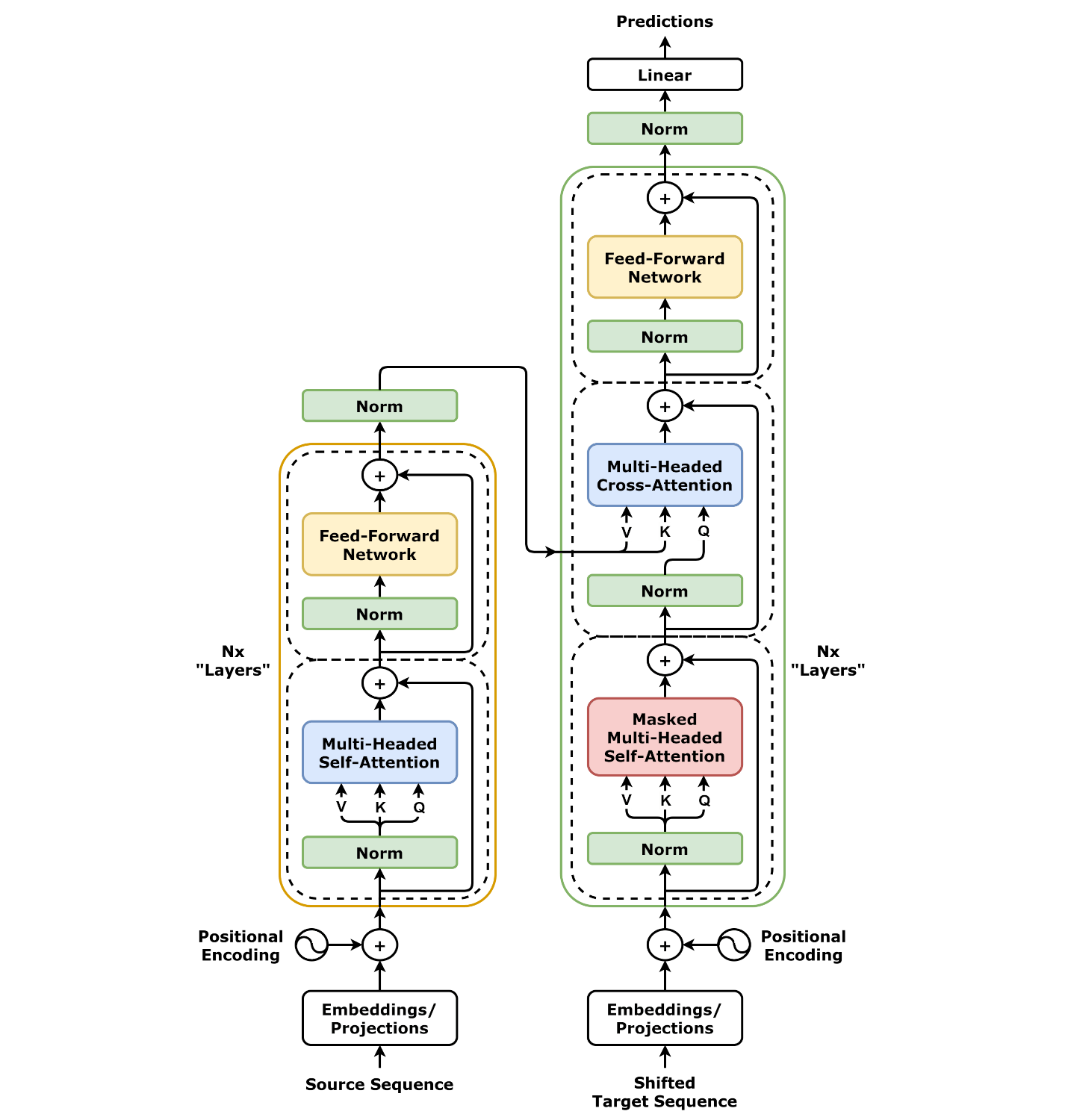
Transformer 模型由 编码器(Encoder) 和 解码器(Decoder) 两部分组成,每部分都由多层堆叠的相同模块构成。
1.1 编码器(Encoder)
编码器由 NN 层相同的模块堆叠而成,每层包含两个子层:
- 多头自注意力机制(Multi-Head Self-Attention):计算输入序列中每个词与其他词的相关性。
- 前馈神经网络(Feed-Forward Neural Network):对每个词进行独立的非线性变换。
每个子层后面都接有 残差连接(Residual Connection) 和 层归一化(Layer Normalization)。
1.2 解码器(Decoder)
解码器也由 NN 层相同的模块堆叠而成,每层包含三个子层:
- 掩码多头自注意力机制(Masked Multi-Head Self-Attention):计算输出序列中每个词与前面词的相关性(使用掩码防止未来信息泄露)。
- 编码器-解码器注意力机制(Encoder-Decoder Attention):计算输出序列与输入序列的相关性。
- 前馈神经网络(Feed-Forward Neural Network):对每个词进行独立的非线性变换。
同样,每个子层后面都接有残差连接和层归一化。
在 Transformer 模型出现之前,NLP 领域的主流模型是基于 RNN 的架构,如长短期记忆网络(LSTM)和门控循环单元(GRU)。这些模型通过顺序处理输入数据来捕捉序列中的依赖关系,但存在以下问题:
-
梯度消失问题:长距离依赖关系难以捕捉。
-
顺序计算的局限性:无法充分利用现代硬件的并行计算能力,训练效率低下。
Transformer 通过引入自注意力机制解决了这些问题,允许模型同时处理整个输入序列,并动态地为序列中的每个位置分配不同的权重。
1.3 核心思想
自注意力机制是 Transformer 的核心组件。
1.3.1 自注意力机制(Self-Attention)
自注意力机制允许模型在处理序列时,动态地为每个位置分配不同的权重,从而捕捉序列中任意两个位置之间的依赖关系。
-
输入表示:输入序列中的每个词(或标记)通过词嵌入(Embedding)转换为向量表示。
-
注意力权重计算:通过计算查询(Query)、键(Key)和值(Value)之间的点积,得到每个词与其他词的相关性权重。
-
加权求和:使用注意力权重对值(Value)进行加权求和,得到每个词的上下文表示。
公式如下:
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V)=softmax(dkQKT)V
其中:
- QQ 是查询矩阵,KK 是键矩阵,VV 是值矩阵。
- dkdk 是向量的维度,用于缩放点积,防止梯度爆炸。
1.3.2 多头注意力(Multi-Head Attention)
为了捕捉更丰富的特征,Transformer 使用多头注意力机制。它将输入分成多个子空间,每个子空间独立计算注意力,最后将结果拼接起来。
-
多头注意力的优势:允许模型关注序列中不同的部分,例如语法结构、语义关系等。
-
并行计算:多个注意力头可以并行计算,提高效率。
1.3.3 位置编码(Positional Encoding)
由于 Transformer 没有显式的序列信息(如 RNN 中的时间步),位置编码被用来为输入序列中的每个词添加位置信息。通常使用正弦和余弦函数生成位置编码:
PE(pos,2i)=sin(pos100002i/dmodel)PE(pos,2i)=sin(100002i/dmodelpos)PE(pos,2i+1)=cos(pos100002i/dmodel)PE(pos,2i+1)=cos(100002i/dmodelpos)
其中:
pospos 是词的位置,ii 是维度索引。
1.3.4 编码器-解码器架构
Transformer 模型由编码器和解码器两部分组成:
- 编码器:将输入序列转换为一系列隐藏表示。每个编码器层包含一个自注意力机制和一个前馈神经网络。
- 解码器:
根据编码器的输出生成目标序列。每个解码器层包含两个注意力机制(自注意力和编码器-解码器注意力)和一个前馈神经网络。
1.3.5 前馈神经网络(Feed-Forward Neural Network)
每个编码器和解码器层都包含一个前馈神经网络,通常由两个全连接层组成,中间使用 ReLU 激活函数。
1.3.6 残差连接和层归一化
为了稳定训练过程,每个子层(如自注意力层和前馈神经网络)后面都会接一个残差连接和层归一化(Layer Normalization)。
2 技术优势
| 特性 | 说明 |
|---|---|
| 并行计算能力 | 摆脱序列顺序限制,大幅提升训练速度(相比 RNN/LSTM) |
| 长距离依赖建模 | 自注意力直接关联任意距离的元素,解决梯度消失问题 |
| 跨领域泛化性 | 成功扩展至 CV(如 VGGT 统一 3D 几何感知)、语音识别等领域 |
3 前沿应用与优化
-
工业级优化案例
- 英伟达 DLSS 4:采用 Transformer 替代卷积神经网络(CNN),显存占用减少 20%,动态场景重影降低 31%,提升图像渲染质量
- VGGT 模型:纯前馈 Transformer 架构,实现多视图 3D 几何属性(相机参数、点云等)统一推理,获 CVPR 2025 最佳论文
-
NLP 任务实践
- 预训练-微调范式:BERT(编码器)、GPT(解码器)等模型通过海量语料预训练,迁移至下游任务(如机器翻译、情感分析)
- 检索增强生成(RAG):结合外部知识库提升问答系统准确性
- 多模态 结合文本和图像的任务(如 CLIP、DALL-E)。
4 开源生态
- Hugging Face Transformers:提供 BERT、GPT 等预训练模型接口,支持快速部署
- 训练框架:PyTorch、TensorFlow 均内置 Transformer 模块,简化自定义模型开发
典型模型分类:
- GPT 系列(自回归生成)
- BERT 系列(双向编码)
- BART/T5(序列到序列)
Transformer 凭借其架构灵活性与性能优势,已成为 AI 大模型(如 LLaMA、GPT-4)的基石,持续推动多模态智能发展
5 实例
import torch
import torch.nn as nn
import torch.optim as optim
class TransformerModel(nn.Module):
def __init__(self, input_dim, model_dim, num_heads, num_layers, output_dim):
super(TransformerModel, self).__init__()
self.embedding = nn.Embedding(input_dim, model_dim)
self.positional_encoding = nn.Parameter(torch.zeros(1, 1000, model_dim)) # 假设序列长度最大为1000
self.transformer = nn.Transformer(d_model=model_dim, nhead=num_heads, num_encoder_layers=num_layers)
self.fc = nn.Linear(model_dim, output_dim)
def forward(self, src, tgt):
src_seq_length, tgt_seq_length = src.size(1), tgt.size(1)
src = self.embedding(src) + self.positional_encoding[:, :src_seq_length, :]
tgt = self.embedding(tgt) + self.positional_encoding[:, :tgt_seq_length, :]
transformer_output = self.transformer(src, tgt)
output = self.fc(transformer_output)
return output
# 超参数
input_dim = 10000 # 词汇表大小
model_dim = 512 # 模型维度
num_heads = 8 # 多头注意力头数
num_layers = 6 # 编码器和解码器层数
output_dim = 10000 # 输出维度(通常与词汇表大小相同)
# 初始化模型、损失函数和优化器
model = TransformerModel(input_dim, model_dim, num_heads, num_layers, output_dim)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 假设输入数据
src = torch.randint(0, input_dim, (10, 32)) # (序列长度, 批量大小)
tgt = torch.randint(0, input_dim, (20, 32)) # (序列长度, 批量大小)
# 前向传播
output = model(src, tgt)
# 计算损失
loss = criterion(output.view(-1, output_dim), tgt.view(-1))
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Loss:", loss.item())


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









