






RK3568上使用4G及以上内存时报错RGA_MMU unsupported memory larger than 4G

2 人赞同了该文章
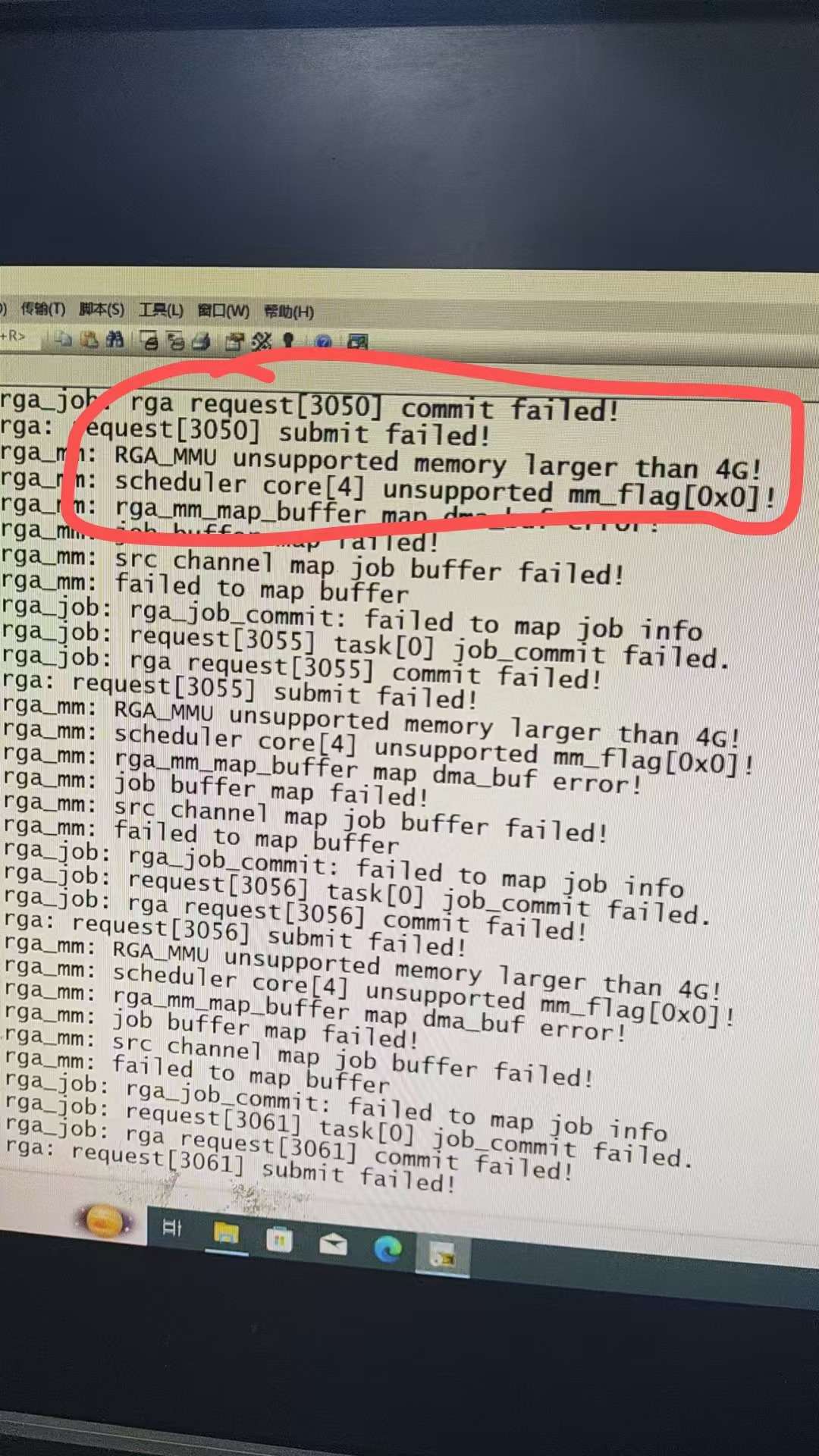
在瑞芯微RK3568上用了4G的内存,然后在使用rga的时候报错:
先看内核启动日志。
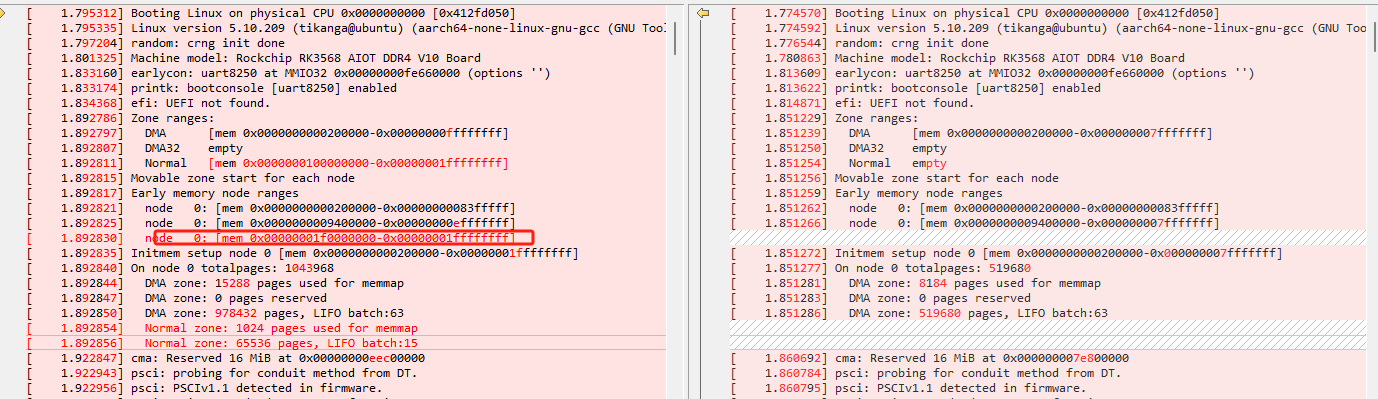
上图左右的Early memory node ranges分别是4G内存板子和2G内存板子启动过程中物理内存分布的内核打印。右边的内存分布的最后一个区间以0x000000007fffffff结尾,这个值刚好是2G。左边的内存分布以0x00000001ffffffff结尾,这个值是8G。对左边的内存分布进行转换和分析:
第一个地址范围:2 MB 到 13.28 MB,大小为11.27MB
第二个地址范围:14.87 MB 到 3,840 MB,大小为3818MB
第三个地址范围:7,936 MB 到 8,192 MB,大小为256MB
4G的物理内存,为什么会有起始地址>4G的第三个地址范围,这应该是RK3568的固件的处理。
这与这张图片中的解释相一致。

为什么第二个地址范围到3840MB的位置结束,而不是到4096MB的位置结束?
查阅了文档《Rockchip RK3568 Technical Reference Manual》,其中Chapter 1 System Overview 中的1.1 Address Mapping 中的表格指定了MMIO映射关系。
MMIO 是一种通过 CPU 访问硬件设备寄存器的方式,它将设备的寄存器空间映射到内存地址空间中,使得操作系统能够像访问普通内存一样访问硬件设备的寄存器。设备的每个寄存器或寄存器组都会映射到一个特定的内存地址,CPU 通过访问这些内存地址来与硬件设备进行交互。
可以看到这个地址是从0xF0000000开始,也就是3840MB:
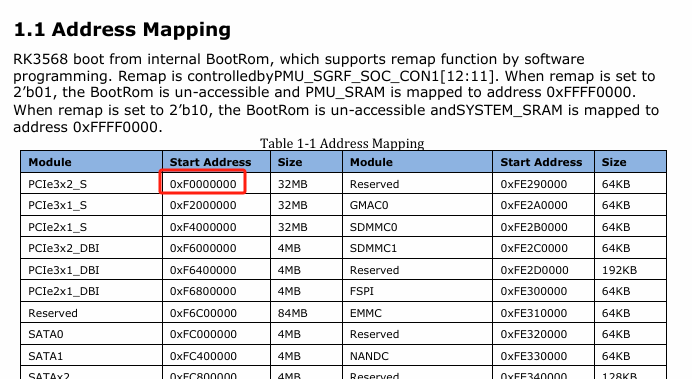
结尾处为0xFE*C0000,大约在4056MB:
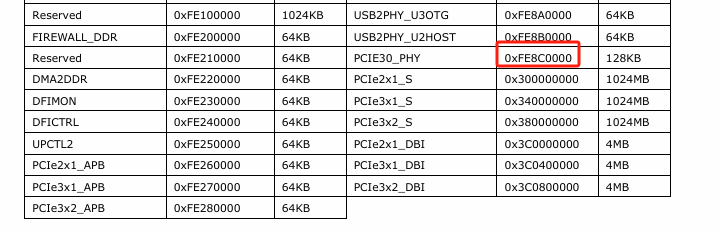
所以可以推断,从3840MB到4096MB的这256M,是rk3568用于MMIO的地址空间,不能用作访问内存的地址空间。为了能访问到4G末尾的[3840MB,4096MB]这一段内存,只能通过从4G以上的内存区间来映射,rk3568用的是前面第三个地址区间,也就是[7936MB,8192MB]来实现。
为什么将驱动从rga3降级到rga2后,能解决这个问题?参考librga/docs/Rockchip_FAQ_RGA_CN.md at main · airockchip/librga 中的1.9:
由于部分RGA1/RGA2的IOMMU仅支持最大32位的物理地址,而RGA Device Driver、RGA2 Device Driver中对于不满足硬件内存要求的调用申请,默认是通过swiotlb机制进行访问访问受限制的内存(原理上相当于通过CPU将高位内存拷贝至符合硬件要求的低位内存中,再交由硬件进行处理,处理完毕后再通过CPU将低位内存搬运回目标的高位内存上。)因此效率十分低下,通常在正常耗时的3-4倍之间浮动,并且引入受CPU负载影响。
RGA Multicore Device Driver(即rga3)中针对访问受限制的内存会禁用swiotlb机制,直接通过调用失败的方式显示的通知调用者申请符合要求的内存再调用,来保证RGA的高效。
rk文档中提供了一种方法,限制内存在0~4G:

注释uboot的以下代码中的红框部分:
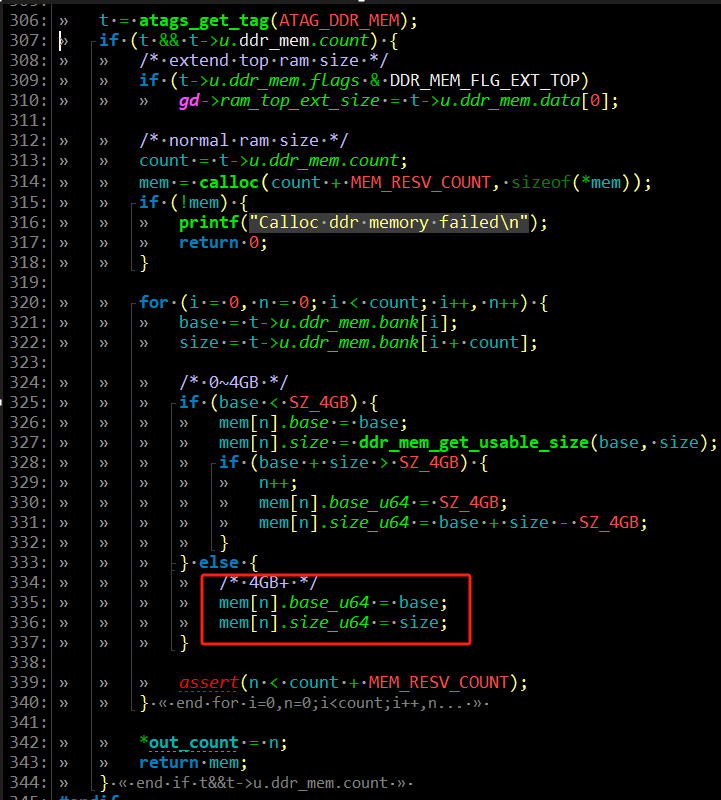
这段代码将使用atags_get_tag函数获取atag信息,并将内存分布存放于mem数组中,mem数组中的每一项对应Early memory node ranges打印中的一个地址范围。将红框中的代码注释掉,相当于大于4G的内存就不使用了,所以就浪费了第三个地址范围内的256M大小的内存,注释前后的对比:
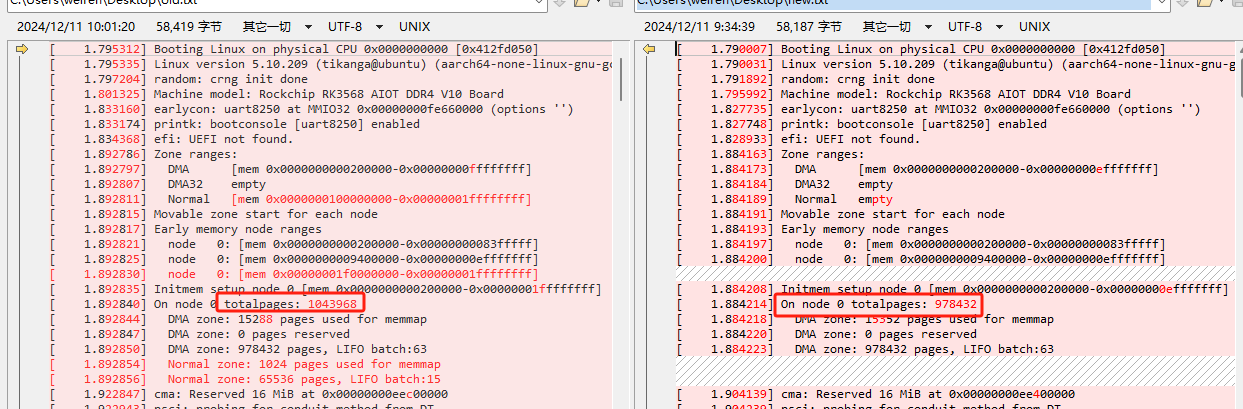
左边是没注释掉方框时的输出,右边是注释掉的,可以观察到第三个地址范围在注释后不再出现了。并且node0的总页面数从1043968下降至978432,下降了65536个页面,相当于256M。
对于4G的内存,考虑一下浪费256M是可否可以接受。
后续如果内存扩展到8G怎么办?
根据文档,有两种方法:
1、申请DMA上的内存:
librga/samples/allocator_demo/src/rga_allocator_dma_demo.cpp at main · airockchip/librga · GitHub
观察图片中的Zone Ranges,DMA段的内存是小于4G的,从这段内存里申请内存给rga用就不会出错。
2、使用drm接口申请内存,带上参数,限制申请4G以下的内存

















 1972
1972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









