







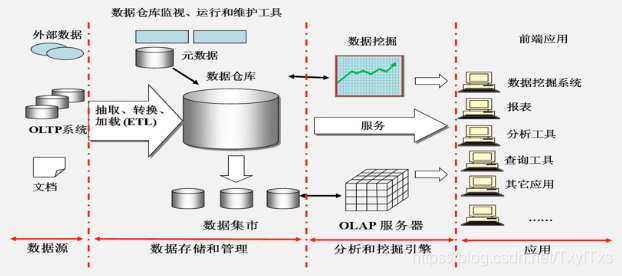
一.概念
1.1 数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
1.2 体系结构
1.3 与传统数据库的区别
- 数据相对稳定,不会频繁发生变化。
- 保留历史信息;
1.4 基于传统数据库的传统数据仓库面临的挑战
- 无法满足快速增长的海量数据存储需求;
- 无法有效处理不同数据类型的数据;
- 计算和处理数据能力不足;
二.Hive 简介
2.1 基于hadoop的Hive数据仓库,水平扩展性好。
- 传统的数据仓库既是数据存储产品也是数据处理分析产品;
- 传统数据仓库同时支持数据的存储于处理分析;
- Hive 本身并不支持数据存储和处理,但提供了一种编程语言HiveQL;
- 架构在底层hadoop核心组件基础之上,借助hadoop的HDFS和MapReduce完成数据的存储和处理;
2.2 Hive提供类似SQL的查询语言HiveQL,通过其来执行具体的MapReduce任务,支持类似的SQL的接口,移植容易,是一个有效合理直观组织和使用的数据分析工具。
2.3 Hive 两方面特性
- 采用批处理方式处理海量数据。
- Hive会把HiveQL语言转化为MapReduce任务进行运行;
- 数据仓库存储的是静态数据,对静态数据分析适合采用批处理方式,不需要快速响应给出结果,而且数据本省不会频繁变化。
- Hive提供了一系列对数据进行提取、转换、加载(ETL)的工具。
- 可以存储、查询和分析存储在hadoop中的大规模数据。
- 这些工具能够很好满足数据仓库各种应用场景。
2.4 Hive 与hadoop组件的关系
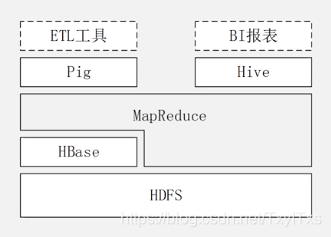
- Hive 依赖于HDFS存储数据;
- Hive 依赖于MapReduce处理数据;
- Pig提供一种面向流式处理的语言Pig Latin(类似SQL),通过Pig Latin脚本语言来执行数据仓库和数据处理等工作。与Hive类似,通过转化为MapReduce任务来执行。
- Pig适合处理实时的交互信息,不适合海量的数据处理。
- Pig 主要用于数据仓库的ETL环节;
- Hive 主要用于数据仓库海量数据的批处理分析。
- HBase 实时交互式查询的数据库产品,弥补HDFS的缺陷。
- Hive 时延高,与Hbase互补;
2.5 Hive与传统数据库

2.6 Hive的应用
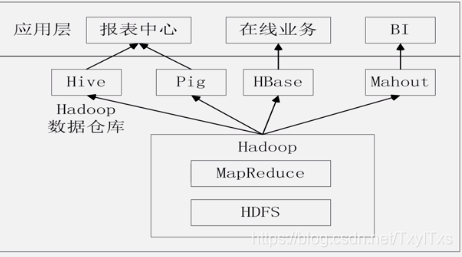
- Mahout:构建商务智能应用;
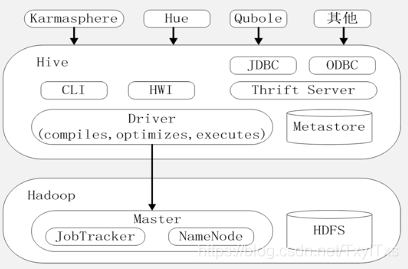
2.7 Hive 系统架构
-
Hive 对外访问接口
- CLI:一种命令行工具
- HWI:Hive web interface是Hive 的文本接口。
- JDBC和ODBC:开发数据库连接接口
- Thrift Server :基于Thrift架构开发的接口,允许外界通过这个接口,实现对Hive 仓库的RPC调用。
-
驱动模块Driver
- 包含编译器、优化器、执行器:负责把HiveQL语句转换成一些列MapReduce作业;
-
元数据存储模块Metastore:是一个独立的关系型数据库;
- 通过MySQL数据库来存储Hive元数据。

- 也可以通过上述接口访问;
- Qubole:直接作为一种服务提供给用户,通过亚马逊AWS平台可以远程使用数据仓库,数据仓库由亚马逊集群管理。
2.8 Hive HA基本原理
- Hive High Availability:由于Hive 很多时候表现出不稳定性,高可用性的解决方案即Hive HA。
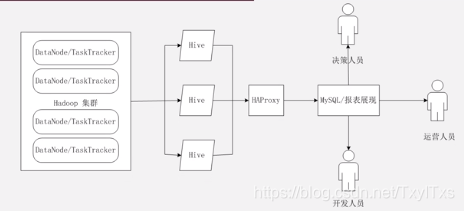
- 外部多个实例访问HA Proxy,Proxy在转发到底层的多个实例上去,执行逻辑可用性测试。
- 每个一定的周期,HA Proxy会重新对列入黑名单的示例进行统一处理。
三.SQL转换成MapReduce作业原理
3.1 Hive 不做具体的数据处理和存储,它把SQL语句转换成MapReduce作业。
3.2 基本原理
-
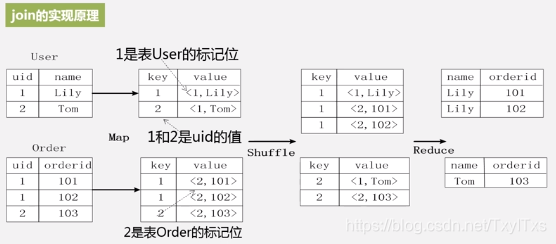
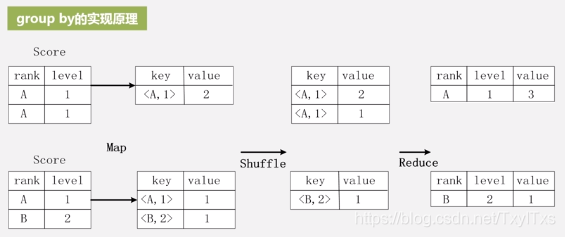
连接:MapReduce实现数据库表的连接
- 编写MapReduce处理逻辑
- Map处理逻辑输入关系数据库的表;
- 通过Map对它进行转换,生产键值对;
-
转化原理
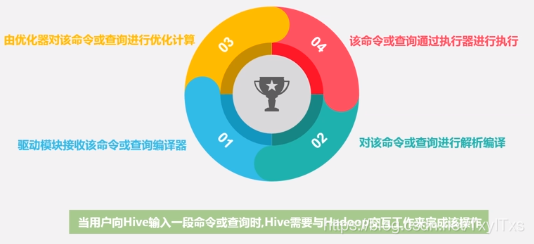
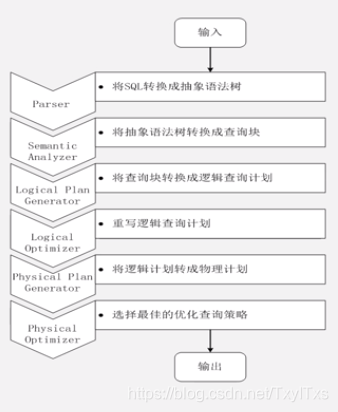
- 说明
- 当启动MapReduce 程序时,Hive 本身是不会生成MapReduce程序的;
- 需要通过一个表示"Job 执行计划"的xml文件驱动执行内置的、原生的Mapper和MapReduce模块。
- Hive 通过和JobTracker通信来初始化MapReduce任务,不必直接部署在JobTracker所在的管理节点上执行
- 通常在大型集群上,会有专门的网关机来部署Hive 工具。
- 数据文件通常存储在HDFS 上,HDFS 由名称节点管理。
- 说明
四.Impala 简介
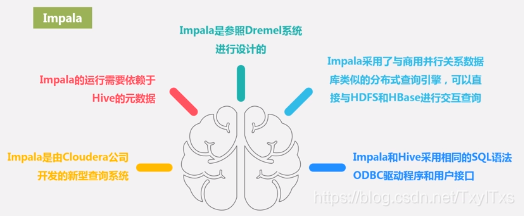
4.1 Impala 是可以实现实时性交互式查询分析的工具,弥补了Hive 的缺点。

4.2 Impala
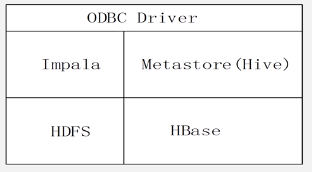
- 允许通过SQL语句查询底层数据,支持PB级别以上的数据,数据可以存储在HDFS和HBase。
- Impala 运行后依赖Hive 元数据,不是独立运行的。
- Impala 是参照Dremel 系统进行设计的;
- Impala 不需要转换成MapReduce任务,而是采用与商业并行关系数据库类似的分布式查询引擎,直接与HFDS和HBase进行交互查询,实时性高;
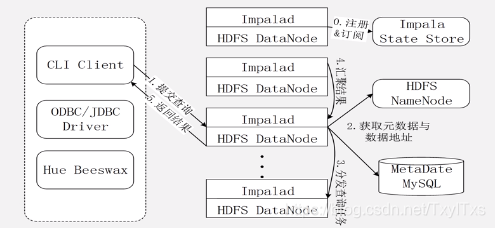
4.3 系统架构
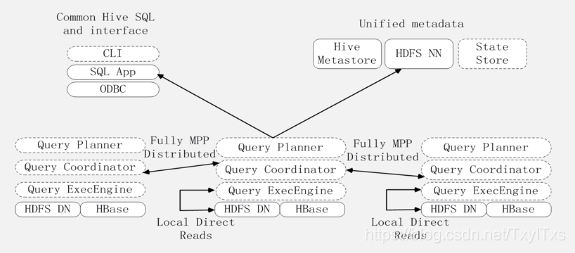
- 虚线部分是Impala的组件,实现部分是Hadoop的其他组件,这些组件需要一起部署在同一个集群上。
- HDFS 和HBase 存储数据;
- Hive 提供元数据存储功能;
- Impala 三个典型组件
- Impalad: 负责具体的相关查询任务;
- Impalad是驻留在不同节点上的进程;
- 包含三个模块
- Query Planner: 查询计划器
- Query Coordinator :查询协调器
- Query Exec Engine:查询执行引擎
- 负责协调客户端提交的查询的执行;
- 与HDFS 的数据节点(HDFS DN)运行在同一节点上。
- 给其他Impalad分配任务以及收集其他Impalad的执行结果并汇总;
- Impalad也会执行其他Impalad给其分配的任务对本地HDFS和HBase 里的部分数据进行操作。
- State Store:负责运输局管理和状态信息维护;
- 查询启动后,系统会创建StateStore的进程;
- 负责收集分布式在集群中各个Impala 进程的资源信息用于查询调度。
- CLI:用户访问接口;
- 提供查询使用的命令行工具;
- 同时提供Hue 、JDBC及 ODBC 的使用接口;
- Impalad: 负责具体的相关查询任务;

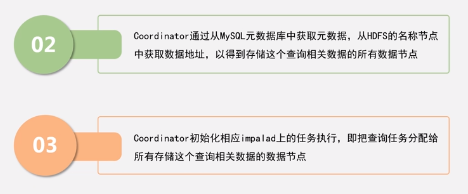
4.4 Impala 查询执行过程


4.5 Impala 与Hive 比较分析
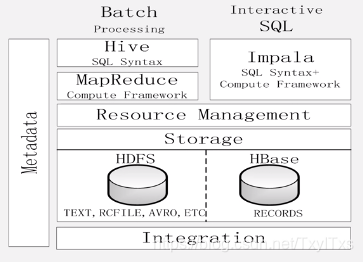
- 不同点
- Hive 适合于长时间的批处理查询分析而Impala 适合于实时交互式SQL 查询。
- Impala 在遇到内存放不下数据时,不会利用外存所以Impala 目前处理查询时会受到一定的限制。
- 相同点
- Hive 与Impala 使用相同的存储数据池都支持数据存储与HDFS和HBase。
- Hive 和Impala 中对SQL 的解释处理比较相似都是通过词法分析生成执行计划。
Impala 的目的不在于替代现有的MapReduce工具,使HIve 和 Impala 的配合使用效果最佳,可以先使用HIve 进行数据转换处理之后再使用Impala 在 Hive 处理后的数据集上进行快速的数据分析。
五.Hive 基本操作
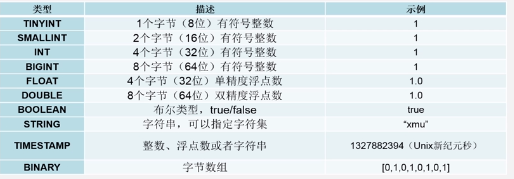
5.1 基本数据类型
5.2 相关操作
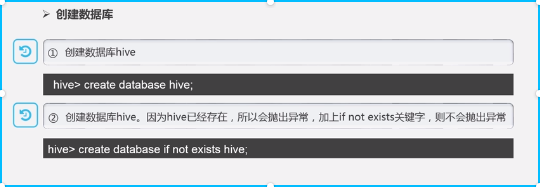
- 创建数据库
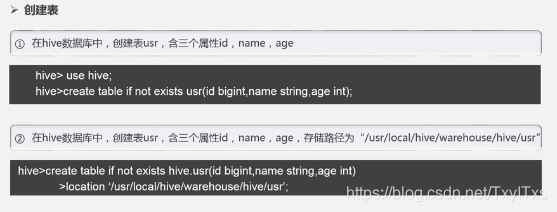
- 创建表,可以设置存储路径。
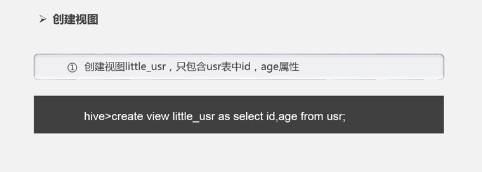
- 创建视图
- 查看数据库

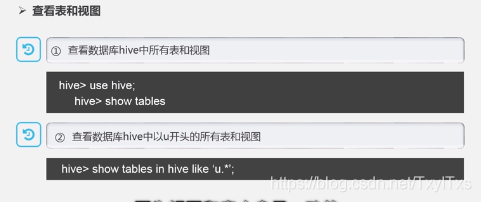
- 查看表,视图
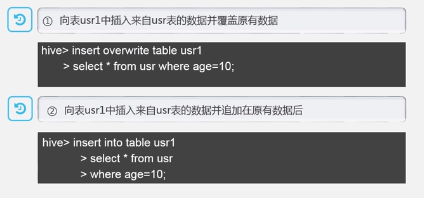
- 插入数据

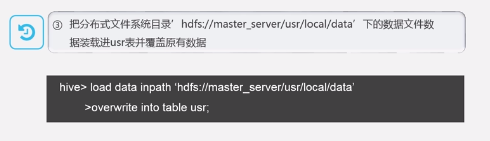
- 插入或导出数据
六. Hive 编程
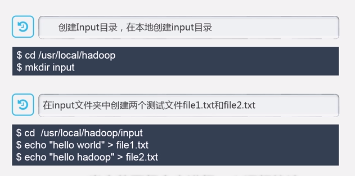
6.1 词频统计

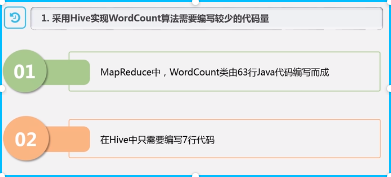
6.2 与MapReduce 的不同点



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











