




文章目录
序
NPLM(Neural Probabilistic Language Model,神经概率语言模型)是由Bengio等人于2003年提出的首个将神经网络与概率语言建模结合的开创性模型,它打破了传统统计语言模型的局限。
NPLM的核心架构通过"one-hot→词嵌入→非线性变换→概率输出"的流程,首次实现了神经网络对语言的有效建模。其四大创新(分布式表示、非线性建模、同步学习、端到端架构)彻底改变了NLP的发展轨迹,是连接传统统计方法与现代深度学习NLP的关键里程碑。
神经概率语言模型提出背景:
在NPLM出现前,NLP领域主流是n-gram模型(基于统计的概率语言模型),其核心问题在于:
- 数据稀疏性:当n增大(如4-gram、5-gram),大量词序列在语料中从未出现,无法估计概率;
- 维度灾难:词汇表规模扩大时,模型参数呈指数级增长;
- 无法建模语义关联:仅依赖词的共现频率,无法捕捉词的深层语义(如“苹果”既指水果也指公司)。
NPLM的核心目标就是通过神经网络解决这些问题,实现更精准的语言概率建模。
1. 神经网络结构
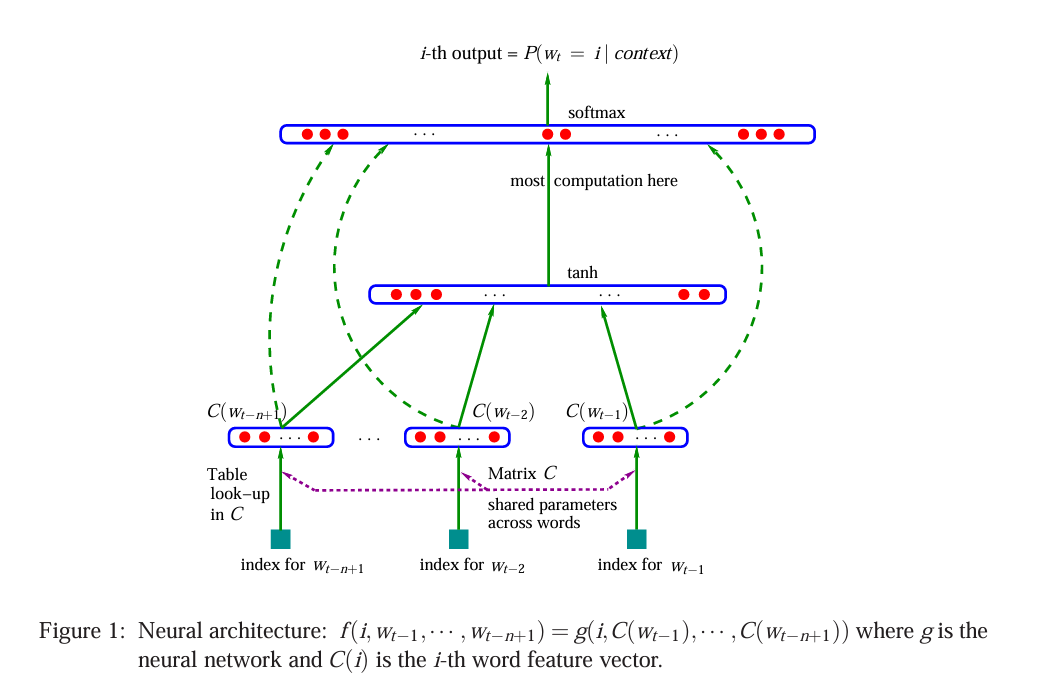
NPLM采用四层全连接神经网络架构,核心是学习"词的分布式表示"和"基于这些表示的概率函数"。模型整体遵循n-gram的马尔可夫假设:下一个词的概率仅依赖于前n-1个词。
(1)输入层(Input Layer)
- 输入形式:前n-1个词的one-hot向量,每个向量维度为|V|×1(|V|是词汇表大小)
- 输入内容:<wₜ₋ₙ₊₁, wₜ₋ₙ₊₂, …, wₜ₋₁>,即目标词wₜ之前的n-1个上下文词
- 作用:将离散的词索引转换为模型可处理的向量形式
(2)词嵌入层(Word Embedding Layer)
这是NPLM最核心的创新层之一,引入了分布式词表示(Distributed Representation)概念。
- 核心组件:词嵌入矩阵C ∈ ℝ^(|V|×m),其中m是词向量维度(远小于|V|,通常取50-300)
- 映射过程:每个输入的one-hot向量w通过矩阵乘法C×w得到对应的词向量e ∈ ℝ^m
- 拼接操作:将n-1个词向量按顺序拼接成一个长向量x ∈ ℝ^((n-1)m),作为隐藏层的输入
- 关键特性:
- 语义相似的词在向量空间中距离相近(如"国王"-“男人”+“女人"≈"女王”)
- 解决了传统模型的数据稀疏性问题,将高维离散空间映射到低维连续空间
(3)隐藏层(Hidden Layer)
- 计算过程:
其中:h = tanh(d·x + b)- d ∈ ℝ^(h×(n-1)m):输入层到隐藏层的权重矩阵
- b ∈ ℝ^h:隐藏层偏置向量
- h:隐藏层神经元数量
- tanh:非线性激活函数,用于捕捉词之间的复杂语义关系
- 作用:对拼接后的词向量进行非线性变换,建模上下文词之间的依赖关系
(4)输出层(Output Layer)
NPLM的输出层设计独特,同时接收隐藏层输出和词嵌入层输出,以增强模型表达能力。
- 计算过程:
其中:y = K·h + M·x + l P(wₜ|wₜ₋ₙ₊₁,...,wₜ₋₁) = softmax(y)- K ∈ ℝ^(|V|×h):隐藏层到输出层的权重矩阵
- M ∈ ℝ^(|V|×(n-1)m):输入层(词嵌入后)到输出层的直接权重矩阵
- l ∈ ℝ^(|V|):输出层偏置向量
- softmax:归一化函数,将输出转换为概率分布,确保所有词的概率和为1
- 作用:输出目标词wₜ的概率分布,完成语言模型的核心任务(预测下一个词)
2. 四大核心创新点
(1)分布式词表示:解决语义缺失问题
- 传统模型痛点:n-gram仅统计词共现频率,无法捕捉语义(如"苹果"的双重含义)
- 创新思路:将词映射到低维连续向量空间,向量的每个维度代表词的一个潜在语义特征
- 突破性意义:首次证明语义可以被量化表示,为后续所有词嵌入技术(Word2Vec、GloVe等)奠定理论基础
(2)神经网络建模非线性关系
- 传统模型局限:n-gram只能建模线性关系,无法处理语言中复杂的句法和语义结构
- 创新设计:通过隐藏层的非线性变换(tanh激活函数)捕捉词之间的高阶依赖关系
- 优势:相比n-gram的简单统计,神经网络能学习更抽象的语言规律,泛化能力更强
(3)同步学习:词向量与概率函数联合优化
- 核心思想:模型同时学习两个关键部分:
- 每个词的分布式表示(词嵌入矩阵C)
- 基于这些表示的词序列概率函数(权重矩阵d、K、M等)
- 训练方式:使用随机梯度下降优化负对数似然损失(Negative Log-Likelihood):
Loss = -∑log(P(wₜ|context)) - 关键优势:词向量的学习直接服务于语言建模任务,确保向量包含语言的核心语义信息
(3)端到端架构:统一语言建模流程
- 传统流程:特征工程(人工设计)→ 模型训练 → 预测,各环节独立
- 创新架构:从原始词输入到概率输出的全链路神经网络,无需人工特征工程
- 意义:开创了NLP的端到端学习范式,为后续Transformer、BERT等模型提供了架构参考
3. 与传统方法的对比分析
- 与传统n-gram模型的核心差异:
| 对比维度 | 传统n-gram模型 | NPLM模型 |
|---|---|---|
| 词表示 | 离散的one-hot向量,无语义关联 | 连续的低维词向量,语义相似词向量相近 |
| 参数规模 | O(|V|ⁿ),随n指数增长,维度灾难 | O(|V|×m + h×(n-1)m + |V|×h),线性增长 |
| 语义建模 | 仅基于词共现频率,无法捕捉语义 | 通过分布式表示和非线性变换建模深层语义 |
| 数据稀疏性 | 严重,大量n-gram组合未出现 | 缓解,低维空间插值能力强 |
| 泛化能力 | 差,未见过的组合无法处理 | 强,可通过语义相似性迁移知识 |
-
主要局限性:
- 计算效率低:输出层softmax需遍历整个词汇表,训练速度慢(当时用并行计算优化)
- 长依赖建模有限:受限于固定窗口大小n,无法有效捕捉更长距离的依赖关系
- 参数共享不足:不同位置的词向量处理使用不同参数,效率不高
-
深远影响:
- 开启神经语言模型时代:直接启发RNN-LM(2010)、Word2Vec(2013)、Transformer-LM(2017)等模型
- 词嵌入成为NLP标配:所有现代NLP模型都基于词/句/段的分布式表示构建
- 奠定深度学习NLP基础:"分布式表示+神经网络建模序列"的核心思路沿用至今
4. RNN-LM做出的改进
RNN(更准确地说是“基于RNN的语言模型(RNN-LM)”)是NPLM的核心迭代与优化版本——它继承了NPLM的核心目标和核心思想,同时解决了NPLM的关键痛点,是神经概率语言模型从“固定窗口”走向“变长序列”的关键演进。
- 关键改进:
NPLM受限于2003年的架构设计(全连接+固定窗口),存在两个致命缺陷,而RNN-LM(2010年由Mikolov等人提出)通过循环结构完美解决,这是两者最核心的差异:
| 痛点维度 | NPLM的问题 | RNN-LM的改进方案 |
|---|---|---|
| 上下文窗口 | 固定长度窗口(如前5个词),无法处理变长序列,长依赖建模能力极弱 | 循环结构天然适配变长序列:逐词处理输入,每一步的隐藏状态都融合“当前词+历史所有词的信息”,理论上可建模任意长度的上下文 |
| 参数效率 | 全连接架构,不同位置的上下文词向量拼接后用独立参数处理,参数规模随窗口长度线性增长 | RNN的循环单元(如tanh-RNN)参数共享:无论序列多长,仅用一套循环参数处理,参数规模固定,效率大幅提升 |
| 序列适配性 | 强制将序列截断/补齐为固定长度,破坏语言的自然序列结构 | 逐词迭代处理,完全贴合语言“时序性”特征,更符合人类语言的生成逻辑 |
举个直观例子:
- NPLM建模“我爱吃苹果”的下一个词时,只能固定取前3个词(如“爱吃苹”),且“爱”“吃”“苹”的参数是分开的;
- RNN-LM处理时,会先处理“我”→更新隐藏状态→处理“爱”→融合“我”的信息更新状态→处理“吃”→融合“我+爱”的信息→处理“苹”→融合“我+爱+吃”的信息,最终用包含全部前文的状态预测“果”,且全程用同一套RNN参数。
论文链接
NPLM:《A Neural Probabilistic Language Model》
RNN-LM:《Recurrent neural network based language model》



















 29
29

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











