




〇、绪
什么是词嵌入?
词嵌入(Word Embedding)是自然语言处理(NLP)中的一项核心技术,它将文本中的词语转换为低维实数向量,使得语义相近的词语在向量空间中距离相近。
传统的文本表示方法(如独热编码)无法捕捉词语之间的语义关系,而词嵌入通过学习词语的上下文信息,能够揭示词语之间的内在联系。
“词嵌入的核心思想是:出现在相似上下文中的词具有相似的含义。”
-
语义表示
词嵌入将词语映射到连续向量空间,使得语义相关的词在空间中位置相近。 -
上下文学习
通过词语的上下文信息学习其表示,捕捉词语之间的语法和语义关系。 -
下游任务
词嵌入作为预训练特征,可显著提升各类NLP任务的性能。
独热编码 vs 词向量
独热编码(One-Hot Encoding)
独热编码是一种将词语表示为二进制向量的方法,向量的长度等于词汇表大小,只有对应词语的位置为1,其余位置为0。

- 局限性:
维度灾难:词汇表越大,向量维度越高
语义鸿沟:无法表示词语之间的语义关系
数据稀疏:每个向量只有一个非零元素
词向量(Word Vector)
词向量是一种分布式表示方法,将词语映射到低维连续向量空间(通常为50-300维),语义相近的词语在空间中距离较近。

- 优势:
低维度:显著降低特征空间维度
语义关联:捕捉词语间的语义和语法关系
泛化能力:提高模型在未见数据上的表现
一、word2vec
在自然语言处理(NLP)中,计算机无法直接理解文字,必须将其转化为数值形式。传统的词表示方法存在明显缺陷:
- One-Hot编码: 用长度为词汇表大小的向量表示词,仅对应位置为1,其余为0。但存在维度灾难(词汇表过大时向量过长)和语义孤立(无法体现词与词的关联)。
- 词袋模型(BoW): 忽略词序,且同样无法捕捉语义关系。
2013年,Google团队提出的Word2Vec解决了这些问题:它能将词转化为低维稠密的实数向量(通常50-300维),且向量间的距离(如余弦相似度)可直接反映语义关联。

1. 词向量的核心
分布式假设
Word2Vec的理论基础是分布式假设:
一个词的含义由其周围的词决定(You shall know a word by the company it keeps)
——J.R.Firth
例如,“苹果"在"吃”、“甜"附近时大概率指水果;在"手机”、"品牌"附近时大概率指电子产品。
词向量的本质
词向量是词的分布式表示,每个维度都隐含特定的语义特征(如"性别"、“词性”、"抽象/具体"等),但这些特征无需人工定义,而是模型从数据中自动学习的。
向量空间中,语义相似的词距离更近。例如:vec(“猫”) 与 vec(“狗”) 的距离 < vec(“猫”) 与 vec(“汽车”) 的距离。
2. Word2Vec的两种模型结构
Word2Vec包含两种核心模型:CBOW(Continuous Bag-of-Words,连续词袋模型)和Skip-gram(跳字模型)。两者均基于浅层神经网络,但输入输出逻辑相反。
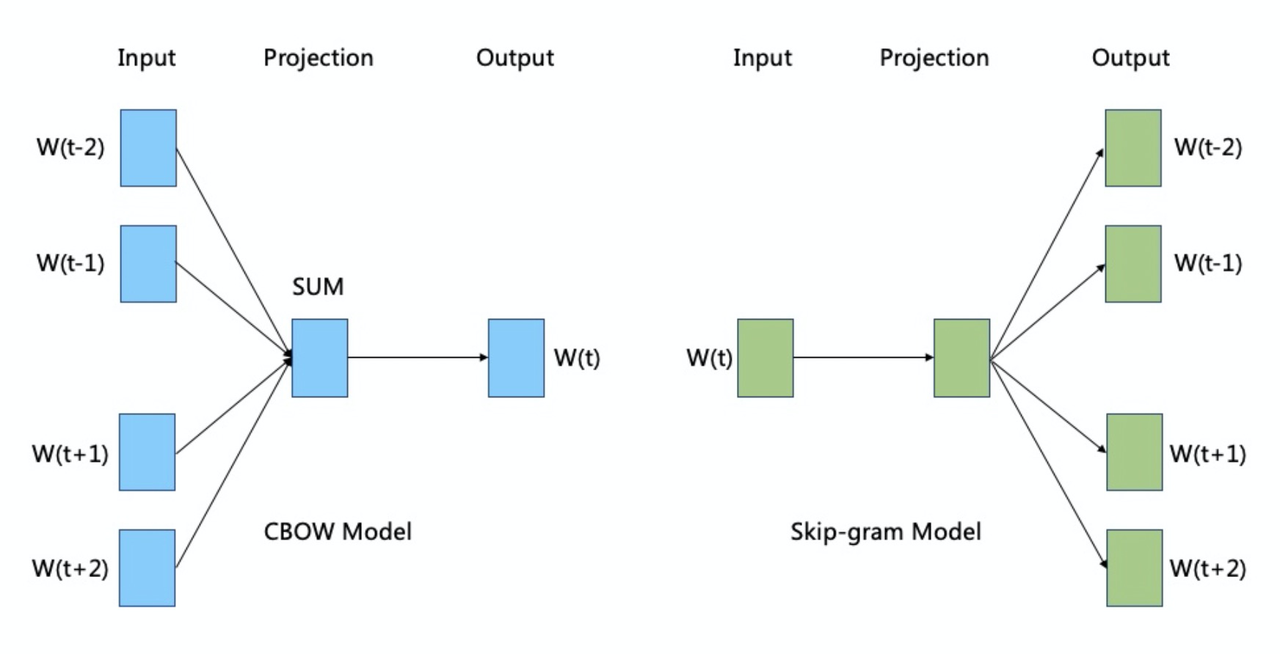
CBOW模型:用上下文预测中心词
CBOW的核心思想:给定上下文词,预测中心词的概率。
- 各层作用:
输入层:上下文词的one-hot向量(长度=词汇表大小V)。
投影层:将上下文词的向量(通过嵌入矩阵查找)进行求和或平均,得到一个固定长度的向量(维度=词向量维度d)。
输出层:通过softmax计算中心词的概率分布(长度=V),目标是使真实中心词的概率最大。
Skip-gram模型:用中心词预测上下文
Skip-gram的核心思想:给定中心词,预测其周围上下文词的概率。
- 与CBOW的对比:
3. softmax
Softmax算法是深度学习中多分类任务的核心激活函数,作用是将模型输出的原始得分(Logits,无约束的实数)转化为0到1之间的概率分布,且所有类别概率之和为1,既让输出结果具备可解释性(代表样本属于各类别的置信度),也能为交叉熵损失计算提供基础。其原理可概括为两步:首先对每个类别对应的Logit取自然指数(
e
z
i
e^{z_i}
ezi),消除负数并放大得分差异;然后将每个指数结果除以所有类别指数结果的总和,完成归一化。公式为:
σ
(
z
)
i
=
e
z
i
∑
j
=
1
K
e
z
j
\sigma(z)_i = \frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}}
σ(z)i=∑j=1Kezjezi
(其中
z
i
z_i
zi是第
i
i
i类的原始得分,
K
K
K是总类别数,
σ
(
z
)
i
\sigma(z)_i
σ(z)i是第
i
i
i类的概率)
实际应用中,Softmax常作为分类模型(如CNN、Transformer分类头)的最后一层,比如图像分类中判断图片属于猫、狗、鸟等类别的概率,或NLP中文本分类的类别置信度排序。
Softmax计算流程图示
直观示例(3分类任务)
假设模型输出3个类别的Logits为 z 1 = 2 z_1=2 z1=2、 z 2 = 1 z_2=1 z2=1、 z 3 = 0 z_3=0 z3=0:
- 指数化: e 2 ≈ 7.389 e^2≈7.389 e2≈7.389, e 1 ≈ 2.718 e^1≈2.718 e1≈2.718, e 0 = 1 e^0=1 e0=1;
- 求和: S = 7.389 + 2.718 + 1 = 11.107 S=7.389+2.718+1=11.107 S=7.389+2.718+1=11.107;
- 归一化:
p
1
≈
7.389
/
11.107
≈
0.665
p_1≈7.389/11.107≈0.665
p1≈7.389/11.107≈0.665,
p
2
≈
2.718
/
11.107
≈
0.245
p_2≈2.718/11.107≈0.245
p2≈2.718/11.107≈0.245,
p
3
≈
1
/
11.107
≈
0.090
p_3≈1/11.107≈0.090
p3≈1/11.107≈0.090;
最终输出概率分布为[0.665, 0.245, 0.090],样本最可能属于第1类。
二、GloVe (Global Vectors)
2014年,斯坦福大学的研究团队提出了GloVe(Global Vectors for Word Representation)模型,这是一种全新的词向量表示方法,结合了两种主流词向量技术的优势:
基于计数的方法(如LSA):利用全局语料统计信息(词共现矩阵)。
基于预测的方法(如Word2Vec):通过局部上下文预测学习词向量。
GloVe的核心思想是:通过词共现矩阵中的统计信息学习词向量,同时保持高效的训练过程。

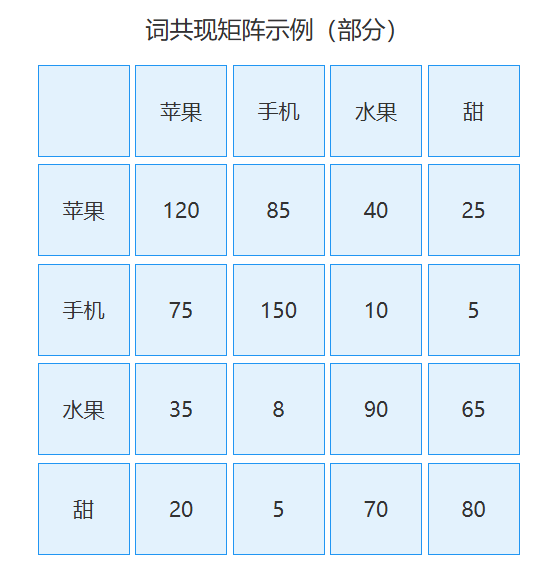
1. 词共现矩阵:GloVe的基石
GloVe(Global Vectors for Word Representation)的核心是依托全局词共现矩阵捕捉词汇语义关联,其原理可梳理为:首先遍历大规模语料库,以固定大小的上下文窗口(如左右各5个词)为单位,统计任意两个词 ( i , j ) (i,j) (i,j)共同出现的频次,构建一个对称的共现矩阵 X X X——矩阵元素 X i j X_{ij} Xij表示词 j j j出现在词 i i i上下文窗口内的总次数( X i i X_{ii} Xii通常为0,避免词自身共现),窗口内不同位置的词可赋予衰减权重(距离越近权重越高,弱化远距离共现的影响);接着GloVe并非直接对共现矩阵做SVD分解(如LSA),而是利用矩阵中蕴含的共现概率比( P i ∣ k P j ∣ k \frac{P_{i|k}}{P_{j|k}} Pj∣kPi∣k,即词 k k k上下文里出现词 i i i和词 j j j的概率之比)来建模语义:若两个词语义相近,它们与其他词的共现概率比会趋于一致,因此GloVe的优化目标是让词向量的点积( w i T w j + b i + b j w_i^T w_j + b_i + b_j wiTwj+bi+bj)近似等于共现频次的对数( log X i j \log X_{ij} logXij),通过最小化这一偏差的加权平方损失,学习到同时融合全局统计信息(共现矩阵的整体分布)和局部上下文特征(窗口内的词关联)的词向量,最终让语义相近的词在向量空间中距离更近。
- 优点:
包含全局统计信息,能捕捉词之间的语义关联。
构建过程简单直接,只需遍历语料库一次。
- 缺点:
维度极高(与词汇表大小的平方成正比),计算和存储成本大。
数据稀疏(大多数词对很少或从未共现)。
无法有效表示多义词和复杂语义关系。
2. GloVe模型的核心思想
GloVe(Global Vectors for Word Representation)模型的核心是融合全局语料的词共现统计信息与词向量的语义关联建模:它摒弃了Word2Vec仅依赖局部上下文预测(CBOW/Skip-gram)的思路,转而通过分析词与词之间的共现概率比值捕捉语义相似性/关联性,并通过优化词向量点积与共现频次对数的拟合程度,学习到兼具全局统计特性和精细语义表达的词向量。
简单来说,GloVe的本质是“用全局统计规律约束词向量的语义关联,让向量空间的相似度对应真实语料中的共现强度”。
关键支撑:共现概率比的语义价值
GloVe的核心洞察来自对共现概率比值的分析,这也是它区别于其他词向量模型的关键:
- 词共现矩阵:设共现矩阵 X X X,其中 X i j X_{ij} Xij表示词 j j j出现在词 i i i上下文窗口中的总次数(全局统计结果); X j = ∑ k X j k X_j = \sum_k X_{jk} Xj=∑kXjk表示词 j j j的所有上下文词的总共现次数。
- 共现概率: P ( i ∣ j ) = X i j X j P(i|j) = \frac{X_{ij}}{X_j} P(i∣j)=XjXij,即“在词 j j j的上下文中出现词 i i i的概率”。
- 概率比的语义意义:
例如,取词 i i i=ice(冰)、 j j j=steam(蒸汽),对比不同上下文词 k k k的概率比 P ( i ∣ k ) P ( j ∣ k ) \frac{P(i|k)}{P(j|k)} P(j∣k)P(i∣k):- 当 k k k=solid(固体)时, P ( i c e ∣ s o l i d ) P ( s t e a m ∣ s o l i d ) ≫ 1 \frac{P(ice|solid)}{P(steam|solid)} \gg 1 P(steam∣solid)P(ice∣solid)≫1(ice与solid强关联,steam弱关联);
- 当 k k k=gas(气体)时, P ( i c e ∣ g a s ) P ( s t e a m ∣ g a s ) ≪ 1 \frac{P(ice|gas)}{P(steam|gas)} \ll 1 P(steam∣gas)P(ice∣gas)≪1(steam与gas强关联,ice弱关联);
- 当
k
k
k=water(水)时,
P
(
i
c
e
∣
w
a
t
e
r
)
P
(
s
t
e
a
m
∣
w
a
t
e
r
)
≈
1
\frac{P(ice|water)}{P(steam|water)} \approx 1
P(steam∣water)P(ice∣water)≈1(两者与water关联度相近)。
这说明:概率比能精准区分词语义上的相似性和关联性,GloVe正是利用这一特性建模语义。
优化目标:词向量点积拟合共现频次对数
GloVe的目标是让词向量的点积(加偏置)与 log X i j \log X_{ij} logXij(共现频次的对数,反映词 i i i和 j j j的共现强度)尽可能拟合——因为 log X i j \log X_{ij} logXij是全局共现强度的量化,而向量点积是向量空间中相似度的经典度量。
1. 核心优化损失函数
J = ∑ i , j = 1 V f ( X i j ) ( w i T w j + b i + b j − log X i j ) 2 J = \sum_{i,j=1}^V f(X_{ij}) \left( w_i^T w_j + b_i + b_j - \log X_{ij} \right)^2 J=i,j=1∑Vf(Xij)(wiTwj+bi+bj−logXij)2
2. 符号详细说明
| 符号 | 含义 |
|---|---|
| V V V | 词汇表总大小(所有唯一词的数量) |
| w i w_i wi | 词 i i i的中心词向量; w j w_j wj:词 j j j的上下文词向量(两者独立训练,最终词向量取均值/和) |
| b i , b j b_i, b_j bi,bj | 词 i i i、词 j j j的偏置项,用于修正拟合偏差(抵消高频词/低频词的系统误差) |
| f ( X i j ) f(X_{ij}) f(Xij) | 加权函数,核心作用: 1. X i j = 0 X_{ij}=0 Xij=0时 f ( X i j ) = 0 f(X_{ij})=0 f(Xij)=0,跳过无共现的词对; 2. 高频共现词(如the和其他词)权重降低,避免主导损失 |
3. 加权函数 f ( X i j ) f(X_{ij}) f(Xij)的定义
为平衡高频和低频共现词的影响,GloVe设计了分段加权函数:
f
(
x
)
=
{
(
x
x
max
)
α
if
x
≤
x
max
1
if
x
>
x
max
f(x) = \begin{cases} \left( \frac{x}{x_{\text{max}}} \right)^\alpha & \text{if } x \leq x_{\text{max}} \\ 1 & \text{if } x > x_{\text{max}} \end{cases}
f(x)={(xmaxx)α1if x≤xmaxif x>xmax
- x max x_{\text{max}} xmax:阈值(通常取100),超过该值的共现次数不再增加权重;
- α \alpha α:衰减系数(通常取0.75),控制低频词的权重衰减速度。
3. 应用场景与总结
- GloVe的优势在于:
- 全局统计+局部语义:既利用了整个语料库的共现规律(比Word2Vec更全面),又通过概率比捕捉了精细的语义关联;
- 高效性:训练速度快于基于SVD的LSA模型,且能处理大规模语料;
- 强语义表达:学习到的词向量能很好地满足语义类比(如 k i n g − m a n + w o m a n = q u e e n king - man + woman = queen king−man+woman=queen)、词性区分、语义范畴聚类等需求。
-
局限性:
与Word2Vec类似,GloVe生成的也是静态词向量,无法处理多义词(如"苹果"的不同含义)。后续发展出的ELMo、BERT等模型通过上下文感知的动态词向量解决了这一问题。 -
GloVe生成的词向量在各种NLP任务中都有广泛应用:
文本分类:将词向量平均作为文本表示,输入分类器(如SVM、CNN)。
语义相似度计算:通过余弦相似度判断两个词或句子的语义关联程度。
命名实体识别:作为特征增强NER模型对实体的识别能力。
机器翻译:初始化翻译模型的词嵌入层,加速训练并提高性能。
问答系统:用于问题和候选答案的语义匹配。
特别适合的场景:需要捕捉词之间精确线性关系的任务,如类比推理(如"国王-男人+女人=女王")。
三、ELMo (Embeddings from Language Models)
ELMo(Embeddings from Language Models)是由Allen Institute for Artificial Intelligence (AI2)开发的一种深度语境化词表示模型,它能够捕捉词汇在不同上下文中的语义信息。与传统词向量模型(如Word2Vec、GloVe)不同,ELMo的词表示是基于整个句子计算的,因此同一个词在不同语境下会有不同的向量表示。
ELMo模型于2018年由Matthew Peters等人在论文"Deep contextualized word representations"中提出,它通过双向LSTM语言模型学习单词的表示,显著提升了多种NLP任务的性能,包括文本分类、命名实体识别、共指消解等。
ELMo的核心创新点
上下文相关的词向量表示:同一个词在不同语境下有不同的向量表示 深层语境化:利用双向LSTM的多层表示捕捉不同层次的语言特征
预训练与微调相结合:在大规模语料上预训练,然后在下游任务中微调
1. 上下文词向量
ELMo的核心贡献是提出了上下文相关的词向量表示方法。传统的词向量模型(如Word2Vec和GloVe)为每个词分配一个固定的向量表示,而不考虑词在上下文中的具体含义。这种方法无法处理一词多义的情况。
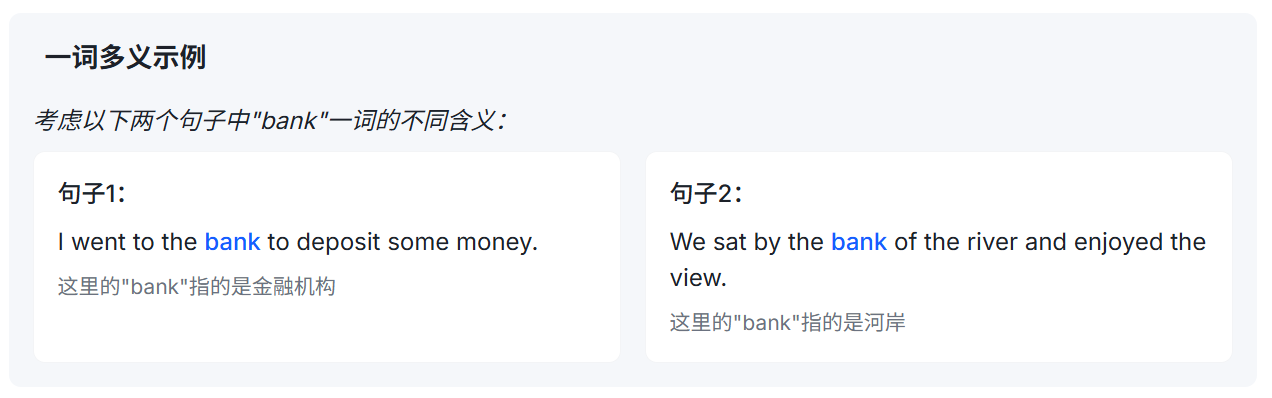
传统词向量与上下文词向量对比
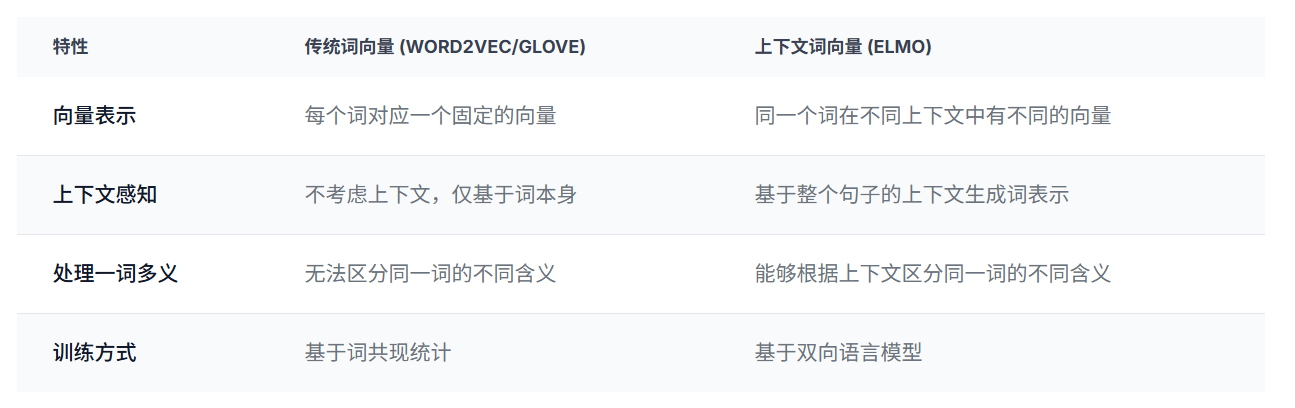
ELMo如何生成上下文词向量
ELMo通过双向LSTM模型学习单词的表示。对于输入句子中的每个单词,ELMo会考虑该单词的左右上下文信息,生成一个基于上下文的词向量。
例如,对于句子 “I love natural language processing”,ELMo会为每个单词生成一个向量,这个向量不仅包含单词本身的信息,还包含了该单词在句子中的上下文信息。因此,"love"在这个句子中的向量表示会不同于在 “She love cats” 中的表示。
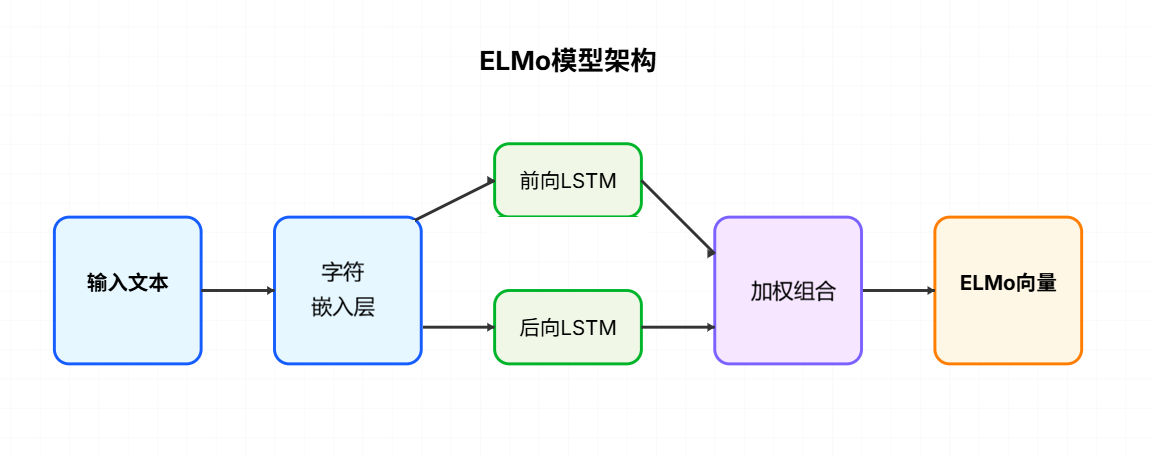
2. 模型架构
ELMo模型基于多层双向LSTM构建,通过双向语言模型(biLM)学习单词的表示。模型的输入是字符序列,经过字符嵌入层和双向LSTM层处理后,输出每个单词的上下文相关表示。
-
字符嵌入层 (Character Embedding)
ELMo使用字符级表示而不是直接使用词嵌入。每个字符被映射到一个低维向量,然后通过CNN和max-pooling操作生成单词的字符级表示。这种方法能够处理未登录词(OOV),并捕捉词的内部结构信息。 -
双向LSTM层 (Bidirectional LSTM)
ELMo使用多层双向LSTM捕捉单词的上下文信息。每一层双向LSTM由两个独立的LSTM组成:一个向前LSTM处理从左到右的上下文,一个向后LSTM处理从右到左的上下文。这两个LSTM的输出被拼接在一起,形成每个单词的上下文表示。 -
ELMo向量生成 (ELMo Vector)
ELMo的最终表示是各层LSTM输出的加权和。每一层的输出捕获了不同层次的语言信息(如语法、语义),通过学习权重可以为不同任务选择最合适的表示组合。

训练过程略
3. 应用场景与总结
ELMo的上下文相关词向量表示在多种自然语言处理任务中都取得了显著的性能提升。由于其强大的语境理解能力,ELMo可以作为特征提取器,为各种下游任务提供高质量的输入表示。
-
应用场景:
命名实体识别 (NER): ELMo能够区分同一词在不同上下文中的不同实体类型,例如"Apple"在产品上下文中指苹果公司,在食物上下文中指水果。
情感分析: ELMo能够捕捉文本中的情感倾向,例如"terrible"在"这电影太terrible了"和"这问题太terrible了需要解决"中的不同情感强度。
语义角色标注: ELMo能够识别句子中每个词的语义角色,例如主语、宾语、谓语等,有助于理解句子的语义结构。
共指消解: ELMo能够确定文本中代词和名词短语的指代关系,例如在"John说他会来"中,正确识别"他"指代"John"。 -
对比分析:
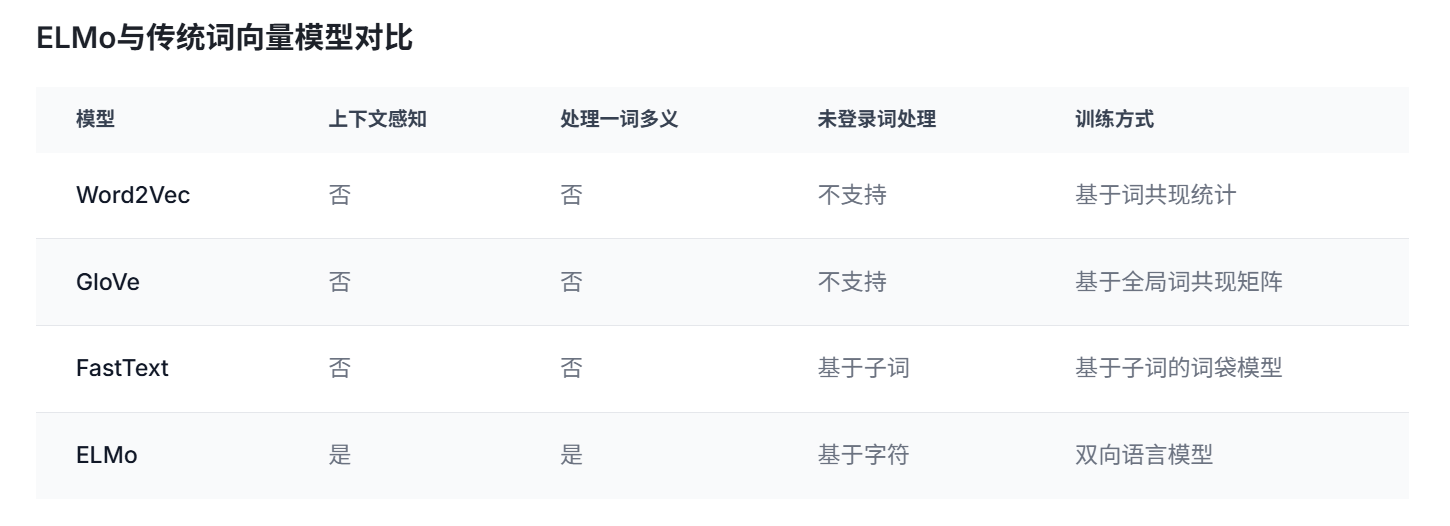
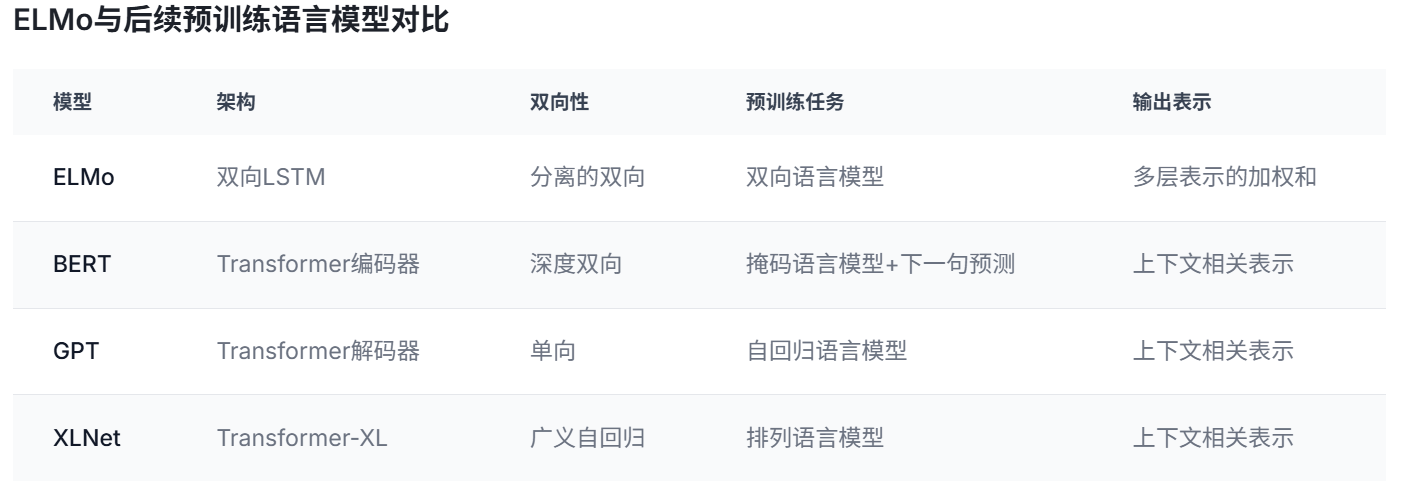
- 优势与局限性:





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











