



这篇文章介绍了一种名为EliGen的新型框架,用于实现实体级可控图像生成。主要内容总结如下:
-
研究背景与问题:
-
现有的文本到图像生成模型(如扩散模型)在生成高质量图像方面取得了显著进展,但仅靠全局文本提示无法实现对图像中单个实体的细粒度控制。
-
现有方法通常依赖于边界框或全局条件,缺乏对实体位置、形状和语义属性的精确控制。
-
-
主要贡献:
-
提出了EliGen框架,通过引入区域注意力机制,实现了对图像中每个实体的精确控制。该机制无需额外参数,能够无缝集成实体提示和任意形状的空间掩码。
-
构建了一个包含50万个高质量注释样本的数据集,用于训练EliGen模型,使其能够实现鲁棒且准确的实体级操控。
-
提出了一种修复融合管道,扩展了EliGen在多实体图像修复任务中的能力。
-
展示了EliGen与社区模型(如IP-Adapter和MLLM)的集成,解锁了新的创意可能性。
-
-
技术细节:
-
区域注意力机制:通过扩展DiT(扩散变换器)的注意力机制,EliGen能够处理任意形状的实体掩码,并精确控制每个实体的生成。
-
数据集构建:使用Flux生成图像,并通过Qwen2-VL模型进行注释,确保数据集的高质量和一致性。
-
训练与微调:采用LoRA(低秩适应)方法进行高效微调,确保模型快速收敛。
-
-
实验结果:
-
EliGen在实体控制生成任务中表现出色,能够生成高质量、一致性强的图像,尤其是在处理复杂布局时优于现有方法。
-
在图像修复任务中,EliGen通过修复融合管道实现了精确的实体级修改,同时保持了非修复区域的质量。
-
通过与IP-Adapter和MLLM的集成,EliGen展示了其在风格化实体控制和交互式图像生成与编辑中的潜力。
-
-
未来工作:
-
探索集成更多控制模态(如深度图和边缘图)以提高合成精度。
-
研究先进的生成范式,如分组扩散和风格特定LoRA模型,以增强输出多样性。
-
EliGen的任意形状掩码控制能力使其在大规模定制数据合成、虚拟现实等领域具有广泛应用前景。
-
EliGen通过区域注意力机制和高质量数据集,实现了对图像中每个实体的精确控制,显著提升了文本到图像生成模型的灵活性和可控性。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
近年来,扩散模型在文本到图像生成方面取得了显著进展,但仅靠全局文本提示仍无法实现对图像中单个实体的细粒度控制。为了解决这一限制,我们提出了EliGen,一种用于实体级可控图像生成的新框架。我们引入了区域注意力机制,这是一种无需额外参数的扩散变换器机制,能够无缝集成实体提示和任意形状的空间掩码。通过贡献一个具有细粒度空间和语义实体级注释的高质量数据集,我们训练EliGen以实现鲁棒且准确的实体级操控,在位置控制精度和图像质量方面均超越了现有方法。此外,我们提出了一种修复融合管道,扩展了EliGen在多实体图像修复任务中的能力。我们进一步展示了EliGen的灵活性,通过将其与社区模型(如IP-Adapter和MLLM)集成,解锁了新的创意可能性。源代码、模型和数据集已发布在项目页面上。

1. 引言
近年来,扩散模型[21, 9, 10]在文本到图像生成方面取得了显著进展,能够通过全局文本描述生成高质量图像。然而,仅靠全局文本提示无法实现精确的图像设计控制,因为自然语言缺乏像素级精度,图像模型通常难以准确建模空间关系和对象数量[20],这大大限制了其广泛适用性。因此,将多样化的条件集成到文本到图像模型中已成为一个核心研究重点。例如,ControlNet[24]和IP-Adapter[30]等作品引入了深度图、边缘图和法线图等条件,以影响生成图像的布局和风格。然而,这些条件在全局图像级别上操作,而不是针对图像中的特定实体。因此,它们缺乏提供细粒度实体级控制的能力,这对于独立操控单个实体的位置、形状或语义属性至关重要。这一限制阻碍了生成复杂、高度定制化的图像,这些图像需要对每个实体进行精确控制。
在本文中,我们专注于为文本到图像模型添加实体级控制,这一条件也被称为实例级或开放集布局控制。该任务允许输入多个实体条件,每个条件包括相应的空间和语义控制。先前的研究[14, 22, 31, 32]主要依赖于基于UNet的Stable Diffusion模型[20]。这些方法通常通过两种方式编码实体空间条件:(1) 通过边界框表示位置,并使用傅里叶编码和辅助模块;(2) 将空间信息映射到注意力图中,以指导UNet的交叉注意力层。然而,这些方法存在显著的限制。首先,边界框限制了模型的创造力和灵活性,因为用户通常更倾向于输入任意形状的实例掩码。使用精确的边界框坐标进行训练会使网络对数值输入过于敏感,从而降低模型的鲁棒性,并导致生成的图像美学质量较差。其次,现有方法基于UNet,而最近的文本到图像生成进展已转向扩散变换器(DiT)[9, 10]。这种架构差距使得先前的设计过时,并使得DiT中的实体级控制未被探索。

与以往依赖边界框的方法不同,我们旨在扩展DiT中的注意力机制,以实现对任意形状空间掩码的实体控制。为了将实体控制集成到DiT中,DiT接受全局提示和潜在图像嵌入作为输入,我们通过结合局部和全局提示嵌入形成扩展提示序列。此外,基于空间条件,我们构建了联合注意力掩码(实体-潜在、实体间和实体内)。这使得每个实体通过扩展注意力序列和组合掩码实现区域注意力。由于局部和全局提示共享相同的嵌入空间,并且没有引入额外参数,区域注意力即使在没有训练的情况下也是有效的,如图2所示。在图2b中,实体“黄色玫瑰”成功修改了区域细节,而“笔记本电脑”和“书”没有明显变化,这表明局部提示可以影响生成,但未经训练的模型缺乏有效的布局控制能力。
基于上述发现,我们进一步考虑通过训练来增强模型的布局控制能力。对于实体控制任务,每个训练样本需要一张图像、一个全局提示、局部提示和掩码。我们使用Flux生成图像,并使用Qwen2-VL[33]视觉语言模型注释全局提示和实体信息,构建了一个包含50万个高质量注释训练样本的数据集。由于没有引入额外的冗余结构,我们采用LoRA进行高效微调,以确保更快的收敛。
经过训练后,我们的模型EliGen获得了精确且鲁棒的实体级控制能力,能够无缝接受任意形状的位置输入,如图0(a)和0(c)所示。此外,我们引入了一种基于区域的噪声融合操作,称为修复融合,使EliGen能够实现令人印象深刻的修复效果,如图0(b)所示。借助区域注意力的可扩展性,EliGen可以在单次前向传递中对多个实体进行修复。此外,EliGen可以无缝集成其他社区开发的开源模型,如IP-Adapter[16]和MLLM[10],以实现更高水平的创造力。
我们做出了以下贡献:
-
我们提出了EliGen,一种利用细粒度实体级信息实现精确可控文本到图像生成的新方法。
-
我们提出并微调了一种区域注意力机制,以将注意力集中在特定图像区域,使EliGen能够实现鲁棒且精确的实体级控制。
-
大量实验表明,EliGen在实体控制生成方面表现出色,同时在图像修复和与社区模型的无缝集成方面表现出色,突显了其创意潜力。
-
我们发布了一个细粒度实体级控制数据集,以促进实体级控制生成及相关任务的先进研究。
2. 相关工作
文本到图像扩散模型。文本到图像扩散模型[7, 21, 8]通过从文本描述生成高质量图像,推动了生成式AI的演进。潜在扩散模型(LDMs)[19, 20]作为一项关键创新,在压缩的潜在空间中操作,而不是直接在像素空间中操作,这显著降低了计算成本,同时保持了合成质量。这些模型主要通过UNet架构中的交叉注意力模块引入文本条件。扩散变换器(DiT)[17]是第一个利用Transformer的扩散模型,通过自适应LayerNorm将条件集成到图像潜在空间中。SD3[6]和Flux[8]是最先进的模型,采用DiT,通过连接文本和潜在图像模态并执行联合注意力,充分利用文本的语义信息,生成更高质量和更精细的图像。尽管这些模型具有令人印象深刻的能力,但仅从文本生成图像仍然受到限制。社区一直在积极探索引入额外条件的方法[22, 23, 24, 25],实体级控制就是其中之一。
实体级控制生成。为了为基础模型配备细粒度控制能力,研究人员最初探索了无需训练的方法,如扩散融合[1]和交叉注意力引导[24]。然而,这些方法通常产生不稳定的结果,并且在实体遗漏方面面临重大问题。为了解决这些挑战,研究人员引入了额外的模块,使用边界框编码每个实体的空间信息,并进行任务特定的补充训练。GLIGEN[8]是第一个经过训练的实体控制模型,集成了一个额外的门控注意力模块,并通过傅里叶嵌入编码边界框值。随后,IFAdapter[24]和MIGC[26]引入了新组件:实例特征适配器和阴影聚合控制器。它们还将空间信息映射到注意力图上,以指导交叉注意力过程。InstanceDiffusion[24]进一步细化了实体空间信息的表示,将其从粗到细分类,并为每个类别设计独特的标记器。虽然这些基于训练的方法主要专注于设计复杂结构以编码空间信息,但本文将重点转向设计和训练无需额外参数的区域注意力机制。这些机制通过控制实体语义影响的区域直接整合空间信息。
3. 方法
3.1 预备知识

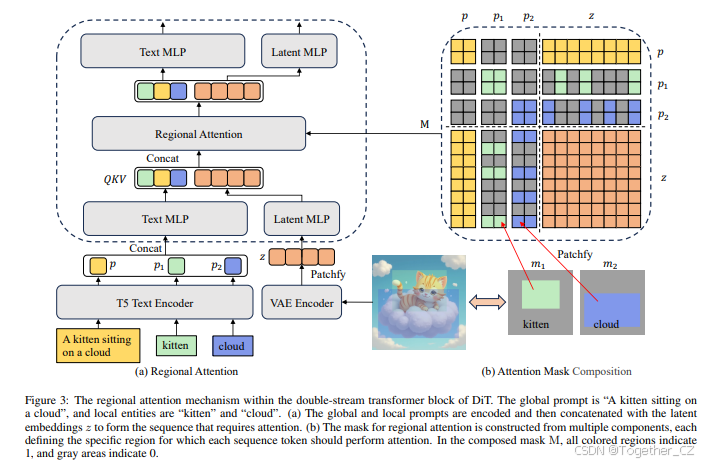
图3:DiT双流Transformer块中的区域注意力机制。全局提示为“一只小猫坐在云上”,局部实体为“小猫”和“云”。
(a) 全局和局部提示被编码后与潜在嵌入z连接,形成需要注意力处理的序列。
(b) 区域注意力的掩码由多个组件构成,每个组件定义了每个序列标记应执行注意力的特定区域。在组合掩码MM中,所有彩色区域表示1,灰色区域表示0。
3.2 区域注意力



3.3 带有实体注释的数据集
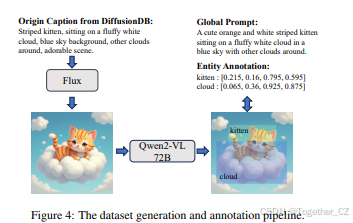
对于实体控制任务,每个训练样本应包括一张图像、一个全局提示和多个实体注释。关于图像来源,先前的工作通常使用开源数据集(如Laion[14])获取图像,但我们观察到Laion的图像分布与基础模型生成的图像分布存在显著差异,导致风格不一致。使用Laion进行训练会扭曲模型分布并降低图像质量(见附录),因为模型需要适应这种不匹配。因此,我们选择直接使用基线模型Flux生成的图像,以避免这种分布差异。
数据集生成流程如图4所示。我们从DiffusionDB中随机选择一个标题,并使用Flux模型生成源图像。然后,我们使用多模态大语言模型(MLLM)[25]对图像进行重新标注,形成全局提示。与之前依赖Grounding DINO[15]的方法不同,我们直接使用Qwen2-VL 72B,这是所有MLLM中最强大的基础模型,随机选择图像中的实体并标注其局部提示和定位(通过边界框)。这确保了局部提示与全局提示的一致性。由于我们的区域注意力采用软编码的空间定位,使用矩形掩码进行训练足以使模型泛化到任意形状的掩码。
3.4 实现细节
我们的模型没有引入任何额外参数。为了实现更快的收敛和更好的社区对齐,我们使用LoRA(低秩适应)[7]方法进行微调。LoRA权重应用于DiT中每个块的线性层,包括Attention前后的投影层以及自适应Layer Norm中的线性层。LoRA秩设置为64。模型使用AdamW优化器进行训练,批量大小为64,训练20K步,学习率为0.0001。为了最小化内存使用,我们采用DeepSpeed[16]训练策略,使用bfloat16精度。模型使用修正流[5]的标准生成损失进行训练。在推理过程中,我们使用Euler调度器[19],采样步数为50,并将无分类器引导(CFG)比例设置为3。此外,Flux中的嵌入引导配置为3.5。
4. 应用
4.1 实体级控制生成
我们通过评估模型在两种掩码输入场景下的表现,评估了模型在实体控制任务中的泛化能力,并与先前的工作(包括Instance Diffusion[26]、GLIGEN[17]、MIGC[22]和Multi-Diffusion[2])进行了比较。

矩形掩码作为输入:在此场景中,实体通过边界框定位。我们的模型将边界框转换为掩码进行输入,而其他模型则使用边界框坐标。定性结果如图5所示,我们的模型在图像质量、一致性和实体准确性方面表现出色。在前两行中,大多数方法都能处理具有不同实体的简单任务,除了Multi-Diffusion。最后两行展示了复杂布局,其中实体紧密耦合。虽然其他模型难以保持准确性和一致性,甚至MIGC和Multi-Diffusion在最后一个示例中也表现不佳,但我们的模型始终如一地生成高质量、一致的图像。

任意形状掩码作为输入:在本工作之前,Instance Diffusion是唯一能够处理任意形状掩码作为输入的方法,因此我们进行了比较评估,如图6所示。Instance Diffusion在仅依赖掩码时表现出较差的图像质量,因此我们为其添加了掩码的最小边界框作为额外输入。结果清楚地表明,我们的模型在图像质量、位置准确性和属性保真度方面优于Instance Diffusion。Instance Diffusion在处理显著偏离矩形形状的掩码(如“中国龙”和“长城”)时难以控制位置。相比之下,我们的模型在没有硬编码位置的情况下,始终如一地提供出色的结果。
4.2 图像修复
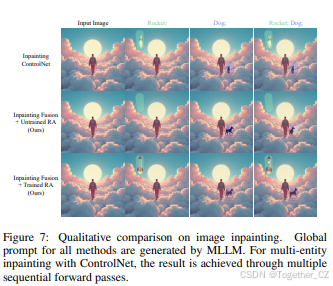
图像修复的目标是在指定的图像位置渲染所需的内容。虽然将输入图像编码为EliGen模型的初始潜在表示是直观的,但这通常会破坏非修复区域。因此,我们提出了修复融合管道,以在保持非修复区域的同时,实现对修复区域的精确、实体级修改。

我们在图7中与Flux-ControlNet[3]进行了比较。如图所示,修复融合确保了背景不变性(第2行),而训练区域注意力进一步使EliGen能够在修复区域渲染所需的对象(第3行)。与Flux-ControlNet(第1行)相比,我们的模型在以下方面表现出色:(1) 保持非修复区域的质量不受损失,(2) 实现对实体位置和形状的精确控制以实现和谐融合,(3) 支持在单次前向传递中对多个实体进行修复。

4.3 潜在的创意扩展
EliGen具有无限的创意潜力,这里我们展示了其与IP-Adapter和MLLM集成时的能力。
使用IP-Adapter进行风格化实体控制:IP-Adapter[4]能够基于参考图像的风格生成目标图像。与EliGen结合使用时,它使我们能够完成风格化实体控制任务。图8展示了一些示例及其生成的变体。通过输入多个实体细节以及参考图像,我们可以实现对目标图像中角色和环境风格的精确控制。
使用MLLM进行交互式图像生成与编辑:MLLM能够解释用户提供的图像和文本内容并进行对话。因此,通过利用MLLM和EliGen的集成,我们可以实现交互式图像设计和编辑。具体来说,基于基础的MLLM(如Qwen2-VL)可以根据文本描述确定实体位置,从而仅通过文本使用EliGen生成图像。此外,MLLM可以用于理解图像并根据特定的图像编辑需求设计实体信息,从而与EliGen结合实现精确的图像编辑。定性结果如图9所示。
5. 结论与未来工作
为了实现具有实体控制的图像生成,我们提出了将区域注意力引入DiT架构,以有效集成实体提示及其位置。此外,我们构建了一个具有细粒度实体信息的数据集,并对区域注意力机制进行了微调,开发了EliGen模型。EliGen在实体级控制图像生成中表现出高度的泛化能力,生成的图像质量优于现有模型。我们进一步提出了一种修复融合管道,扩展了EliGen在图像修复任务中的功能。此外,通过将EliGen与社区模型(如IP-Adapter和MLLM)集成,我们展示了其在创意应用中的潜力,拓宽了其范围和多功能性。
EliGen为未来的研究开辟了有前景的方向。我们将进一步探索集成额外的控制模态(如深度图和边缘图)以提高合成精度。将研究先进的生成范式,包括通过上下文LoRA和风格特定LoRA模型进行分组扩散,以增强输出多样性。其利用任意形状掩码进行高质量生成的独特能力,使其成为大规模定制数据合成的强大工具,具有在合成数据集、虚拟现实等领域的潜在应用。协作、社区驱动的创新将进一步释放其在创意和实际应用中的潜力。




















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











