



这篇文章介绍了一个名为 QuarkAudio 的统一音频生成与处理框架,其核心研究内容可以概括为以下三个部分:
一、 核心创新:统一的音频表示与框架
-
H-Codec (统一的离散音频分词器)
-
核心思想:设计了一个双流音频编解码器,将声学特征(来自原始波形)和语义特征(来自自监督学习模型,如WavLM/HuBERT)分开并行量化,生成双流离散令牌。
-
技术亮点:
-
解耦表示:声学流负责高保真重建,语义流负责保留高层次语义,解决了音频任务中“保真度”与“语义”的权衡难题。
-
高效性:通过动态帧率机制(H-Codec-1.5)和低帧率设计(如H-Codec-2.0支持48kHz采样率但帧率仅6.25Hz),显著降低了后续语言模型推理的时间步数,提高了生成效率。
-
高性能:实验表明,H-Codec(特别是大规模版本的H-Codec-2.0)在语音、音乐、通用音频的重建质量上达到了最先进水平。
-
-
-
QuarkAudio (统一的音频语言模型框架)
-
核心思想:构建了一个基于仅解码器自回归语言模型的统一生成框架。
-
统一范式:将文本指令、参考音频、待处理音频等所有任务特定的条件信息,编码为连续特征并作为前缀序列输入模型。模型则基于此条件序列,以自回归方式预测H-Codec的多层离散令牌。
-
任务统一方式:通过引入特殊任务令牌来区分不同的任务模式,使单一模型能够处理多种任务,无需为每个任务调整权重。
-
二、 广泛的任务支持
QuarkAudio在一个框架内集成了两大类任务:
-
音频处理任务:
-
语音恢复
-
目标说话人提取
-
语音分离
-
语音转换
-
语言查询的音频源分离
-
性能:在这些任务上取得了与当前最先进的任务特定或多任务模型相当或更优的性能。
-
-
指令驱动的自由形式音频编辑任务:
-
语音语义编辑:根据文本指令(如“插入”、“删除”、“替换”)修改语音的语义内容。
-
音频事件编辑:根据文本描述,在背景音频中插入或删除特定声音事件(如“鸟鸣”、“鼓声”)。
-
意义:这是更具挑战性的新兴方向,展示了框架理解复杂指令并执行细粒度音频操控的能力。
-
三、 关键实验结论
-
H-Codec有效性:H-Codec在多个基准测试(如LibriSpeech, SEED, AudioSet)上,在低比特率/低帧率下实现了卓越的音频重建质量,为下游生成任务奠定了高效、高保真的基础。
-
QuarkAudio通用性:模型在七大任务上均表现优异,验证了其“一个模型应对多任务” 的可行性。
-
编辑任务潜力:在语音和音频事件编辑任务上展示了强大潜力,生成音频质量高、自然度好,但在语音语义编辑的文本准确性上仍有提升空间。
QuarkAudio 的核心贡献是提出并验证了一个“统一表示 + 统一框架”的音频人工智能范式。 它通过创新的 H-Codec 解决了高质量音频表示的问题,再通过基于自回归语言模型的 QuarkAudio 框架,利用条件前缀和任务令牌,优雅地将多种音频处理和生成任务统一到一个简洁、高效的模型中,为构建通用音频大模型迈出了重要一步。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

项目地址在这里, 如下所示:
摘要
许多现有的音频处理或生成模型采用任务特定的架构,导致开发工作碎片化且扩展性有限。设计一个能够处理多种任务的统一框架前景广阔,该框架同时提供鲁棒的指令和音频理解能力,并实现高质量的音频生成。这需要高度兼容的范式设计、强大的骨干网络建模能力以及高保真的音频恢复模块。为满足上述需求,本技术报告介绍了 QuarkAudio,一种新颖的、基于仅解码器自回归语言模型的生成式框架,用于统一多种任务。该框架包含一个统一的离散音频分词器 H-Codec,它将自监督学习表示整合到音频分词和重建过程中。针对 H-Codec 提出了一些创新性改进,例如动态帧率机制和将音频采样率扩展到 48 kHz。QuarkAudio 通过将任务特定的条件信息作为仅解码器语言模型的条件序列来统一任务,并以自回归方式预测目标音频的离散令牌。该框架支持广泛的音频处理和生成任务,包括:语音恢复、目标说话人提取、语音分离、语音转换和语言查询的音频源分离。此外,我们将下游任务扩展到由自然语言指令指导的通用自由形式音频编辑。实验结果表明,H-Codec 在低帧率下实现了卓越的音频重建质量,提高了下游音频生成的效率和性能,并且 QuarkAudio 在多个任务上与最先进的任务特定或多任务系统相比,取得了具有竞争力或相当的性能。
1 引言
能够统一多样化任务的通用大模型的发展已成为人工智能领域的关键趋势,这源于跨模态高效、可扩展解决方案的需求。在文本和视觉领域,诸如 GPT 和 CLIP 等基础模型已在多任务学习框架中取得了显著成功,实现了跨模态对齐和任务无关推理。然而,将这种范式扩展到音频这种以复杂时间动态和异构任务需求为特征的模态,仍然是一个重大挑战。当前特定于音频的模型通常表现出任务碎片化,需要针对不同目标(如语音合成或声音事件检测与定位)使用专门的架构。这种碎片化源于三个关键瓶颈:提取适用于具有不同语义和声学要求的任务的音频表示的困难;缺乏能够协调多样化输入输出模态的统一框架;以及任务特定约束之间的固有冲突,例如生成任务中的高保真重建与交互应用中的实时效率之间的权衡。这些挑战阻碍了向一个类似于文本和视觉领域所观察到的多功能性的、连贯的音频基础模型发展的进程。神经音频编解码器利用神经网络获得音频波形的高度压缩离散表示,并旨在从离散令牌重建高保真信号。声学令牌,例如 SoundStream 利用残差向量量化,其中每个量化器细化前一个量化器留下的残差,获得并行的多层令牌并实现卓越的重建质量。包括 Encodec 和 DAC 在内的许多工作都遵循这一范式来提高性能。这些令牌捕获了原始波形的细粒度声学特征,为传统的帧级特征(如梅尔频谱图)提供了替代方案。声学编解码器的发展主要涵盖以下方向:模型规模化,例如 StableCodec 和 WavTokenizer;可变帧长,例如 SNAC。
相反,语义令牌,如 HuBERT、Whisper 和 CosyVoice,富含语义内容但倾向于丢失声学细节。随着语言模型的发展,编解码器的研究重点逐渐从降低数据传输成本转向与语言模型的集成,这确保了生成音频的高质量。这要求编解码器保留更多可以被语言模型理解和建模的语义信息。X-Codec 整合了来自预训练 SSL 模型的表示以增强语义保留,提高了重建质量和下游 TTS 性能。一些研究探索了更适合语言模型中自回归建模的单层编解码器。X-Codec2 利用有限标量量化执行单层量化,扩大了码本空间。BiCodec 生成一个混合令牌流,结合了语义和全局令牌,它们分别源自 SSL 模型和说话人验证模型。然而,低帧率的单层编解码器在高保真重建方面仍然面临挑战,例如说话人相似度。
在实践中,下游语言模型能够并行生成多层令牌,从而放宽了对单层量化的要求。这种范式更依赖于语言模型的建模能力,提高了编解码器重建能力的上限。在此背景下,编解码器的帧率起着关键作用,它决定了推理的时间步数。为了解决上述问题,我们提出了 H-Codec,一种涉及声学和语义分支的双流音频编解码器,用于高保真波形重建。我们的 H-Codec 受益于 RVQ 技术和 SSL 表示,在语音、音乐和通用音频领域实现了显著的重建质量。低帧率确保与我们的 QuarkAudio 框架集成时能够高效生成。
创建一个能够处理多种任务的统一框架是人工智能领域的一个关键研究目标。对于音频理解任务,KimiAudio 提出了一个音频分词器,将语义音频令牌与来自 Whisper 编码器的连续声学向量连接起来,以增强感知能力并输出离散语义令牌。DualSpeechLM 提出了一种双令牌建模范式,使用专用的 USToken 作为输入,声学令牌作为输出。近年来,许多研究将生成式建模整合到音频任务中。对于 SR 任务,SELM 应用 k-means 将 WavLM 获得的含噪语音表示量化为离散令牌,然后一个基于 Transformer 的语音语言模型将含噪令牌映射到干净令牌。对于 LASS 任务,FlowSep 在变分自编码器潜在空间中学习从噪声到目标源特征的线性流轨迹,这些轨迹由编码的文本嵌入和混合音频指导。对于语音编辑任务,VoiceBox 引入了一种基于流匹配的非自回归编辑范式。然而,其依赖诸如 MFA 之类的对齐模型来指定编辑区域,在实际场景中增加了操作开销。InstructSpeech 代表了一项重大进展,它采用三元组数据构建、多任务学习和多步推理来实现基于指令的编辑。
与基于离散音频编解码器的方法(尤其是仅解码器的自回归模型,它可以优雅地将条件信息作为前缀序列集成)相比,连续方法通常需要复杂的设计来组合多模态条件,限制了扩展到更多任务的能力。此外,离散音频表示在与 LLM 结合方面起着重要作用,连接了自然语言指令和连续波形。因此,我们开发了一个基于仅解码器自回归语言模型的框架,以统一音频任务。它利用连续条件嵌入来最大限度地保留语义和声学信息,预测多层编解码器令牌,从而减少量化损失。
在语音表示方面,理解和生成任务提出了根本不同的需求:理解受益于紧凑、注重语义的编码,而生成则需要丰富、高质量的声学细节。因此,大多数现有的语音语言模型诉诸于两种架构折衷之一:要么为理解和生成保留单独的表示,要么两者都依赖于离散令牌。前一种方法的挑战在于将两种表示方案统一到单一的建模空间中,而后一种方法的性能则受到离散化导致的信息损失的制约。此外,音频生成模型在音频质量和跨任务泛化能力方面仍然面临挑战。这种碎片化导致了冗余的开发工作、不一致的性能和有限的扩展性。
一些研究旨在将多个任务统一在单一框架内,包括 AnyEnhance、UniAudio、LLaSE-G1、UniSE 和 Metis。这些方法利用语言模型骨干结合离散音频编解码器,并展现出卓越的生成能力,这得益于语言模型的语义理解和上下文建模能力。然而,在音频质量和跨任务泛化能力方面仍然存在挑战。例如,很少有统一模型能够处理 SS 任务,因为它通常需要定制架构来输出多轨语音。就语音任务而言,自由形式音频编辑——特别是由自然语言指令指导——是一个新兴且极具挑战性的方向。与基于固定输入输出映射的传统音频任务不同,音频编辑需要对复杂语言语义的深入理解、对声学属性的细粒度控制和高保真生成。例如,用户可能希望"将说话人的情绪从愤怒变为平静"或"在背景中添加鸟鸣"。这种能力需要对音频语义、韵律和环境背景进行联合建模。虽然 WavCraft、SAO-Instruct、Voicecraftx、Step-Audio-EditX 和 Ming-UniAudio 等开创性工作已开始探索这一领域,但现有解决方案在处理组合指令和保持长期音频连贯性方面仍面临重大限制。为了调和表示在理解和生成任务上相互竞争的需求,我们利用连续表示进行鲁棒的语义建模,利用离散表示进行高保真的音频合成,并通过一个统一的大型语言模型来协调这两个表示空间之间的交互。
本工作的贡献可总结如下:
-
统一的离散音频分词器:我们提出了 H-Codec,它将自监督学习表示整合到音频分词和重建过程中。来自波形和 SSL 模型的特征被单独量化,产生双流编解码器令牌。H-Codec 在低帧率下实现了卓越的音频重建质量,提高了下游音频生成的效率和性能。我们进一步提出了 H-Codec 的两个高级版本:H-Codec-1.5 在 H-Codec-1.0 的基础上引入了动态帧率机制,实现对不同内容复杂度的自适应时间分辨率;H-Codec-2.0 在固定帧率下将采样率从 16kHz 扩展到 48kHz,显著提高了音频保真度和高频细节保留。
-
用于生成的统一音频语言模型:QuarkAudio 通过将任务特定的条件信息作为仅解码器语言模型的条件序列来统一任务,并以自回归方式预测目标音频的离散令牌。我们使用特殊的任务令牌来区分多个任务的不同学习模式。请注意,我们的模型使用一组共享权重处理多样化任务,从而消除了对任务特定权重适应的需求。
-
具有高保真生成的多任务:QuarkAudio 支持在单一共享架构内进行广泛的音频处理和生成任务,并能够基于用户指令和可用音频片段进行全面的音频编辑,涵盖语义内容修改和音频事件编辑。此外,该框架在SR、TSE、SS、VC、LASS 和 EDIT 任务方面实现了高保真生成质量,与最先进的任务特定或多任务基线相比,表现出强大的竞争力。
2 模型架构
如图 1 所示,QuarkAudio 是一个统一的、基于自回归语言模型的音频生成框架,由四个关键组件组成:一个新颖的双流 H-Codec;一个带适配器的文本编码器;一个带适配器的音频编码器;一个仅解码器的语言模型骨干。
2.1 统一离散分词器
根据上述设计思路的指导,我们提出了 H-Codec,如图 2 所示。遵循音频编解码器的一般架构,H-Codec 建立在三个核心要素之上:编解码器编码器、量化器模块和编解码器解码器。受 X-Codec 启发,我们结合了预训练模型以促进语义信息的保留。然而,与 X-Codec 融合声学和语义信息然后使用单一码本量化组合表示不同,我们使用单独的码本独立量化两种类型的特征,从而产生双流编解码器令牌。我们将 H-Codec 的原始设计扩展到 H-Codec-1.5 和 H-Codec-2.0,其中前者采用动态帧率机制以降低帧率,后者将音频采样率从 16 kHz 扩展到 48 kHz,支持更高保真的音频重建和更广泛的应用场景,如高质量多媒体内容。
2.1.1 编码器和解码器
在编码阶段,原始波形被馈送到声学编码器中以提取帧级声学特征,其中 代表波形样本数。H-Codec-1.5 继承了 H-Codec-1.0 的模块架构。H-Codec-2.0 升级了声学编码器的架构。我们执行短时傅里叶变换并将幅度谱和相位谱拼接作为输入特征,然后馈送到 ConvNeXtBlock 层和 Transformer 层的堆栈中。使用一个 RVQ 量化器来量化声学特征。同时,一个预训练的 SSL 模型提取 SSL 特征,并通过应用语义编码器和 RVQ 量化器获得量化的语义特征。
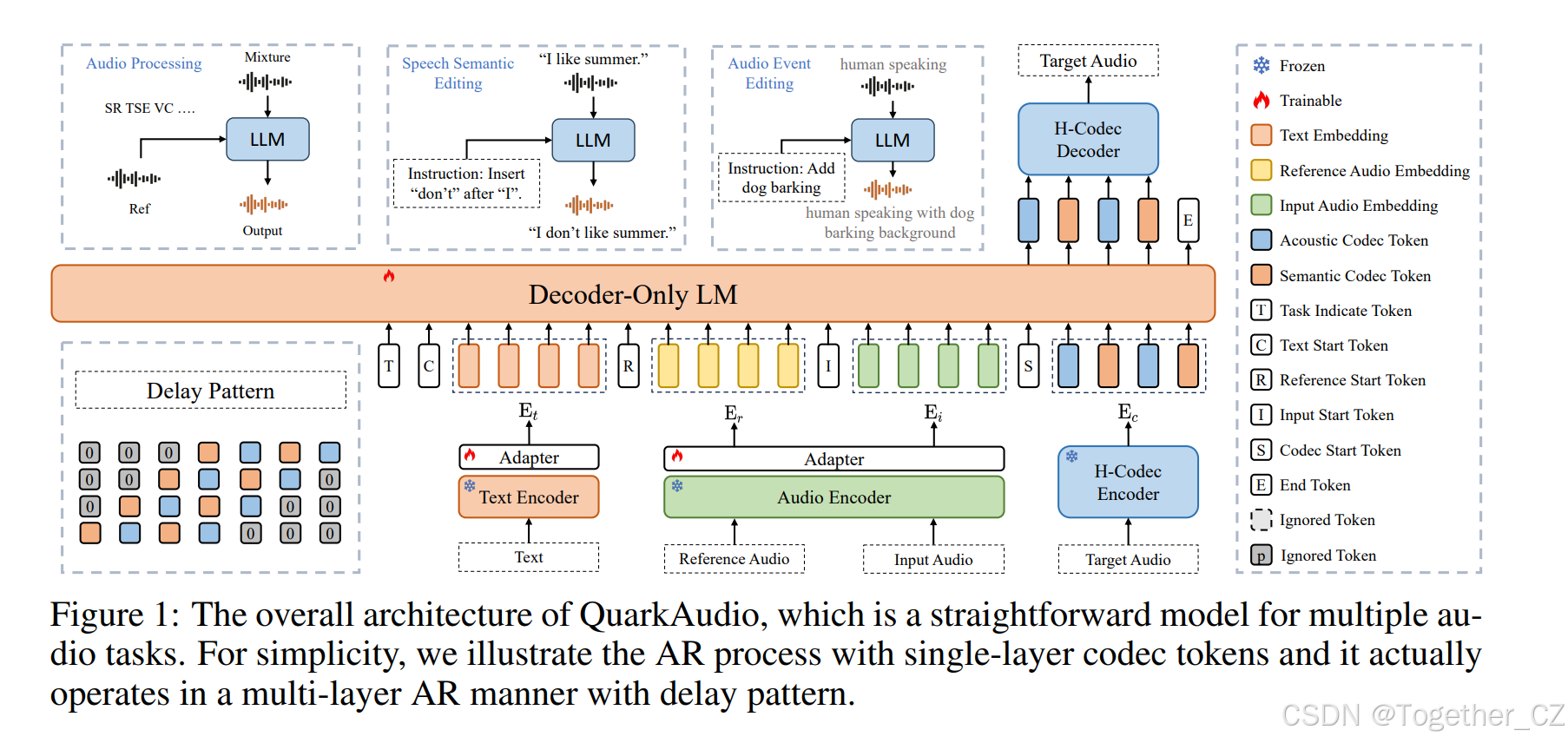
图 1:QuarkAudio 的整体架构,它是一个适用于多种音频任务的简洁模型。为简单起见,我们用单层编解码器令牌说明自回归过程,实际上它以具有延迟模式的多层自回归方式运行。
对于解码阶段,量化后的声学和语义特征沿隐藏维度拼接,并通过声学解码器和仿照 Vocos 的逆短时傅里叶变换头部重建波形。我们认为解耦声学和语义特征使每个分支能够学习不同的表示,这有利于提高重建质量。此外,量化的语义特征由语义解码器处理以重建 SSL 特征。这确保量化的语义特征保留了足够丰富的语义信息。
2.1.2 动态帧聚合与解聚合
受双分支编解码器框架 FlexiCodec 的启发,我们在 H-Codec 中实现了基于语义特征相似度的动态帧率机制。具体来说,系统包括声学和语义分支的聚合和解聚合模块。
语义聚合模块首先计算所有相邻语义特征之间的余弦相似度得分,其中语义特征序列由语义编码器提取。然后扫描相似度序列,以识别所有相似度得分超过预定义阈值的多个连续段。对于每个识别的段,帧随后通过局部注意力机制映射为单个特征表示。声学聚合模块继承由语义聚合模块确定的段边界,以指导声学特征的压缩。这种设计实现了语义引导的声学特征压缩,同时确保跨特征维度的时间一致性。此外,为了便于在解码期间恢复原始帧率,我们遵循 VARStok 的设计,将段长度嵌入到最终的代码索引中,如下所示:

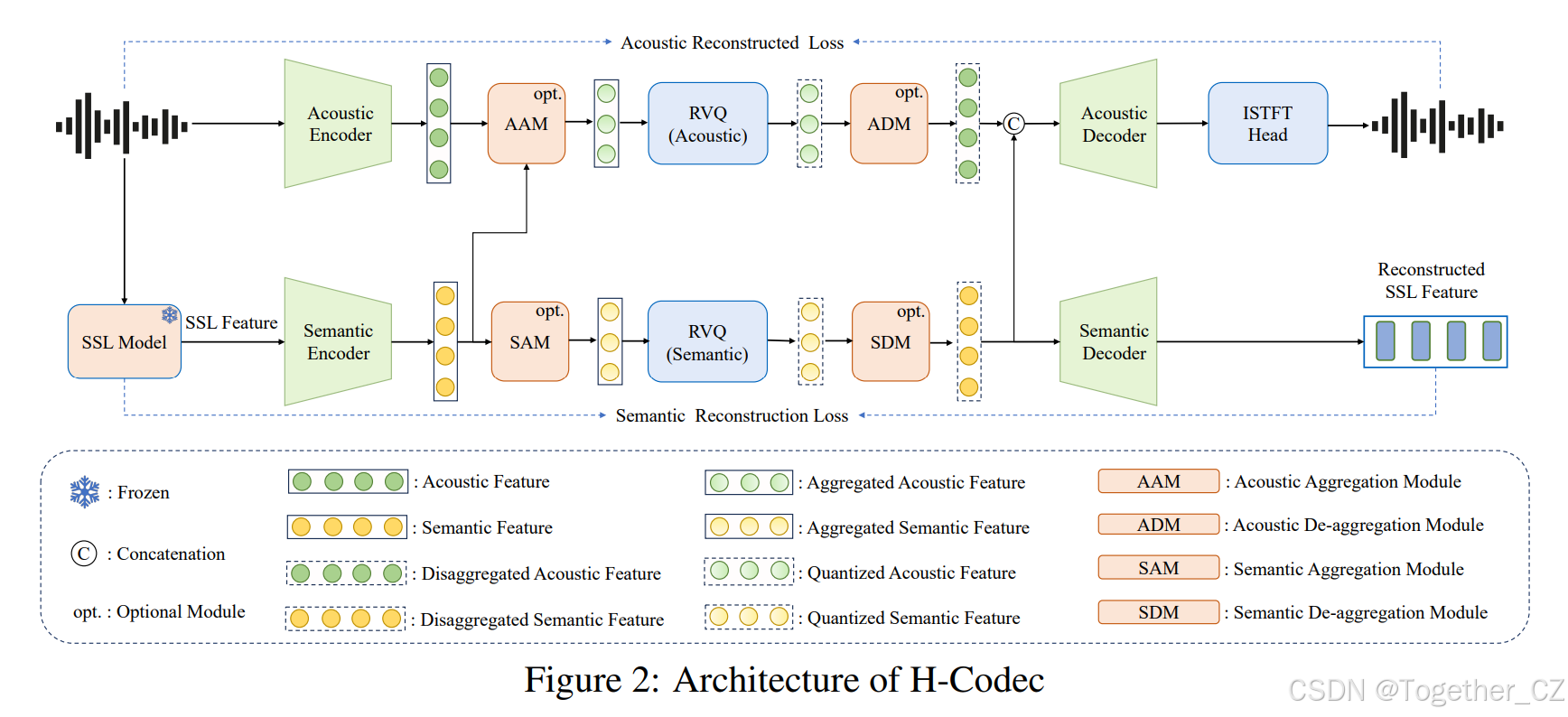
图 2:H-Codec 架构
2.1.3 优化策略
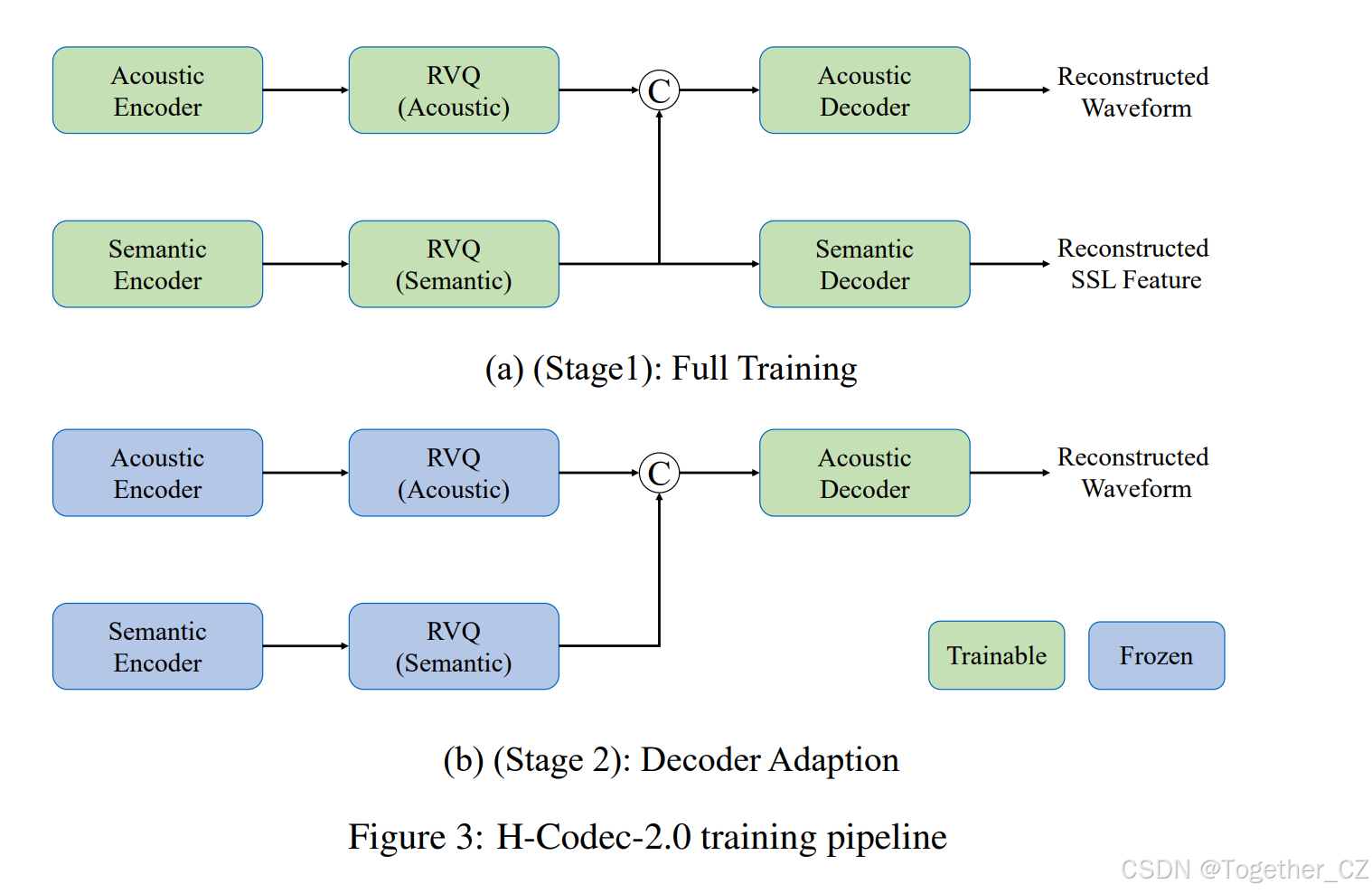
判别器和优化目标函数的配置遵循 UniTok-Audio 中的描述。我们在 H-Codec-2.0 中使用了两阶段训练策略,如图 3 所示。在第 1 阶段,我们在大规模多样化的音频语料库上训练所有模块,增强了在通用音频领域提取令牌的鲁棒性。在第 2 阶段,我们冻结编码器和量化器的参数,以微调声学解码器。此阶段进一步专业化声学解码器,使其能够从固定的量化特征重建音频,而无需适应变化的量化特征。
2.2 统一音频语言模型
2.2.1 整体框架
为了在单一框架内统一各种音频处理或生成任务,我们将任务特定的条件信息提取为仅解码器自回归骨干的条件序列。由于通常从 SSL 模型中提取的连续特征与离散表示相比包含更丰富的音频细节,并且更适应不同的输入条件,我们提取连续特征来组装任务条件序列。具体来说,我们使用 T5-base 作为文本编码器从音频描述中提取嵌入。采用与 H-Codec 中相同的 HuBERT 从音频波形中提取连续特征。两个线性层充当两个适配器,分别将文本嵌入和音频特征映射到适合语言模型自回归建模的表示空间。给定文本和音频嵌入作为条件,我们利用 LLaMA 架构以自回归方式预测目标波形的离散令牌。由于 H-Codec 令牌涉及多层,我们应用延迟模式来安排我们的令牌,以权衡性能和计算成本。范式的细节可以在中找到。最后,H-Codec 解码器根据预测的令牌序列重建高保真音频。
2.2.2 通过操作模式统一任务
遵循我们先前的工作,我们引入特殊的任务令牌来区分不同的操作模式。为了统一七个任务,我们使用七种模式,如表 1 所示。前五个任务在 UniTok-Audio 中定义,而 EDIT-S 和 EDIT-A 分别表示语音语义编辑和音频事件编辑。EDIT-S 根据文本指令的指导,对输入语音的语义执行插入、删除或替换操作。EDIT-A 在没有参考音频辅助的情况下,对输入音频中基于描述的音频事件元素执行插入或删除操作。每种模式对应一个特殊令牌和不同的任务特定条件类型,它们作为语言模型骨干的条件序列,用于估计目标离散令牌的条件概率密度分布。
3 实验
3.1 H-Codec
3.1.1 实验设置
数据集:我们使用多领域数据来训练我们的编解码器,包括语音、音乐和音频。语音样本来自 VoxBox 数据集和内部数据集,前者包含约 100k 小时的语音,后者包括 2.5M 小时的录音。对于音乐领域,我们使用 FMA-full、MUSDB18-HQ 和内部数据集,涉及约 150k 小时的数据。对于音频领域,我们采用 AudioSet、WavCaps 和内部数据集,包括约 100k 小时的录音。我们在 LibriSpeech test-clean 和 Seed-TTS-Eval 上评估语音重建质量。音乐和通用音频的重建质量分别在 MUSDB18-HQ 测试集和 AudioSet 评估集上评估。所有样本根据模型配置或评估指标重新采样到适当的采样率。
实现细节:对于 H-Codec-1.0 和 H-Codec-1.5,每个流中使用 4 层 RVQ 量化器,码本大小为 1024,码本维度为 512。对于 H-Codec-1.5,相似度得分的阈值和聚合的最大长度分别设置为 0.6 和 8,局部注意力窗口跨越前 8 个和后 8 个令牌,具有 8 个注意力头和 32 层。对于 H-Codec-2.0,我们执行帧长为 1920、跳跃长度为 960 的 STFT,产生每秒 50 帧。在使用量化之前,我们将帧率降低到 6.25 Hz。声学和语义分支各由 16 个 RVQ 层组成。在训练期间,我们从音频样本中随机裁剪 5 秒片段。网络使用 AdamW 优化器进行优化,初始学习率为 2×10−4,在 600k 训练步数内基于余弦调度器衰减。
评估指标:我们使用多种指标来衡量语音的重建质量,包括语音质量感知评估、短时客观可懂度、说话人相似度和 UTMOS。计算目标音频和重建音频之间在梅尔尺度频谱和 STFT 频谱上的损失,用于语音、音乐和音频领域的通用评估。编解码器评估指标的详细信息见附录 B.1。
基线:我们将我们的编解码器与一些最先进的基线进行比较,包括 DAC、Encodec、X-Codec、X-Codec2、BiCodec、WavTokenizer、UniCodec、FlexiCodec、MiMO-Audio-Tokenizer、XYTokenizer、BigCodec、Baichuan-AudioTokenizer、Mimi 和 GLM4-VoiceTokenizer。
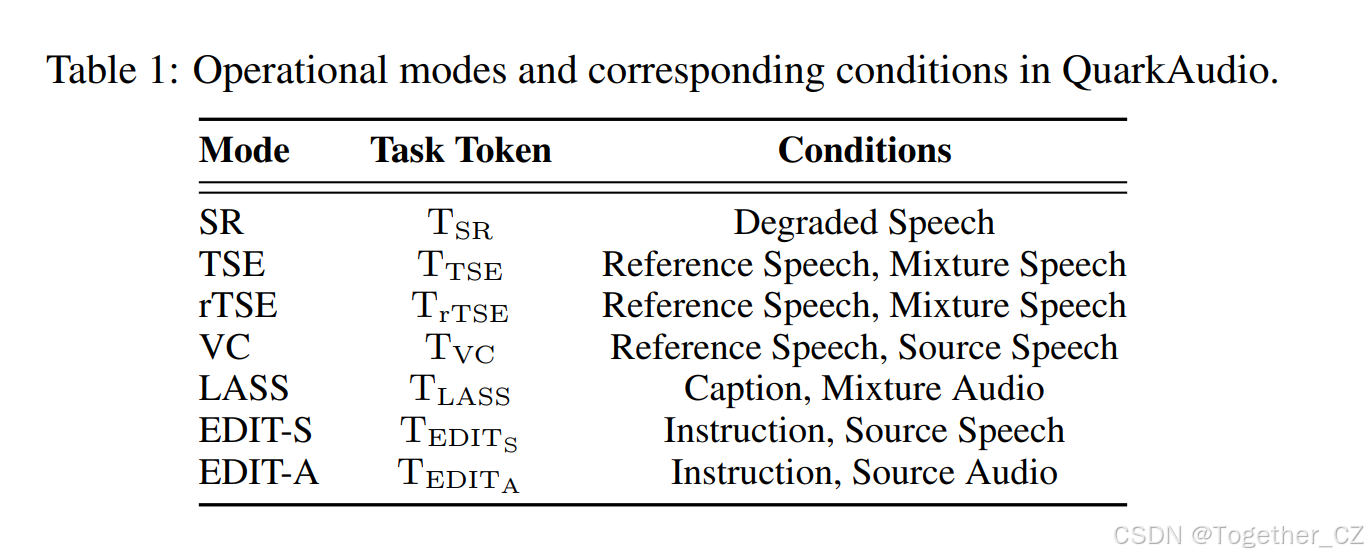
表 1:QuarkAudio 中的操作模式和相应条件。
3.1.2 实验结果
表 2:不同编解码器模型在 LibriSpeech test-clean 集上的比较,其中 FPS 和 BPS 分别表示每秒帧数和每秒比特率。FS、Paras 和 Nq 分别表示模型支持的采样率、参数数量和码本层数。Unified 表示模型是否支持通用音频或仅支持语音。对于 Flexi-Codec 和 H-Codec-1.5,我们计算测试数据集上的平均 FPS 和 BPS。
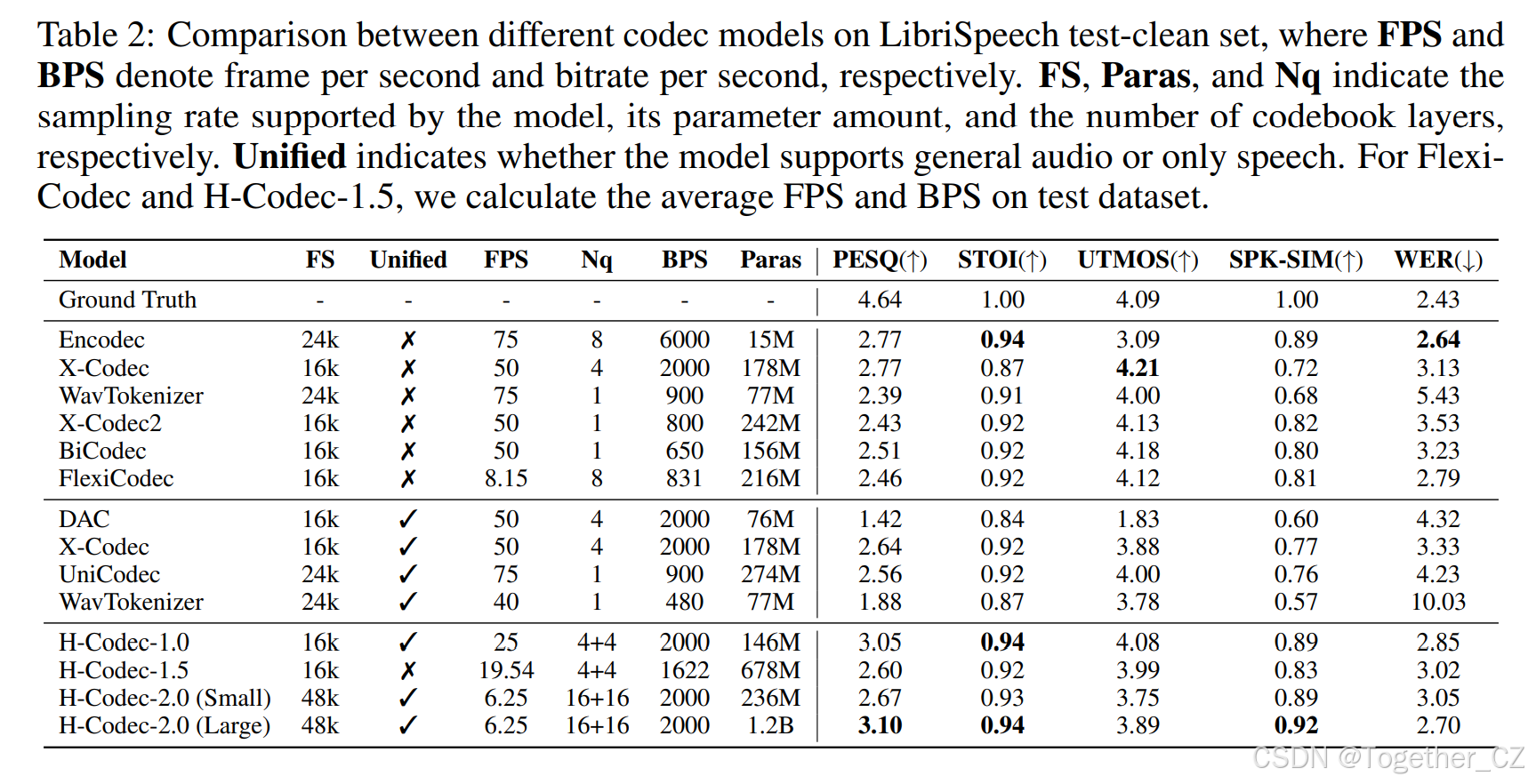
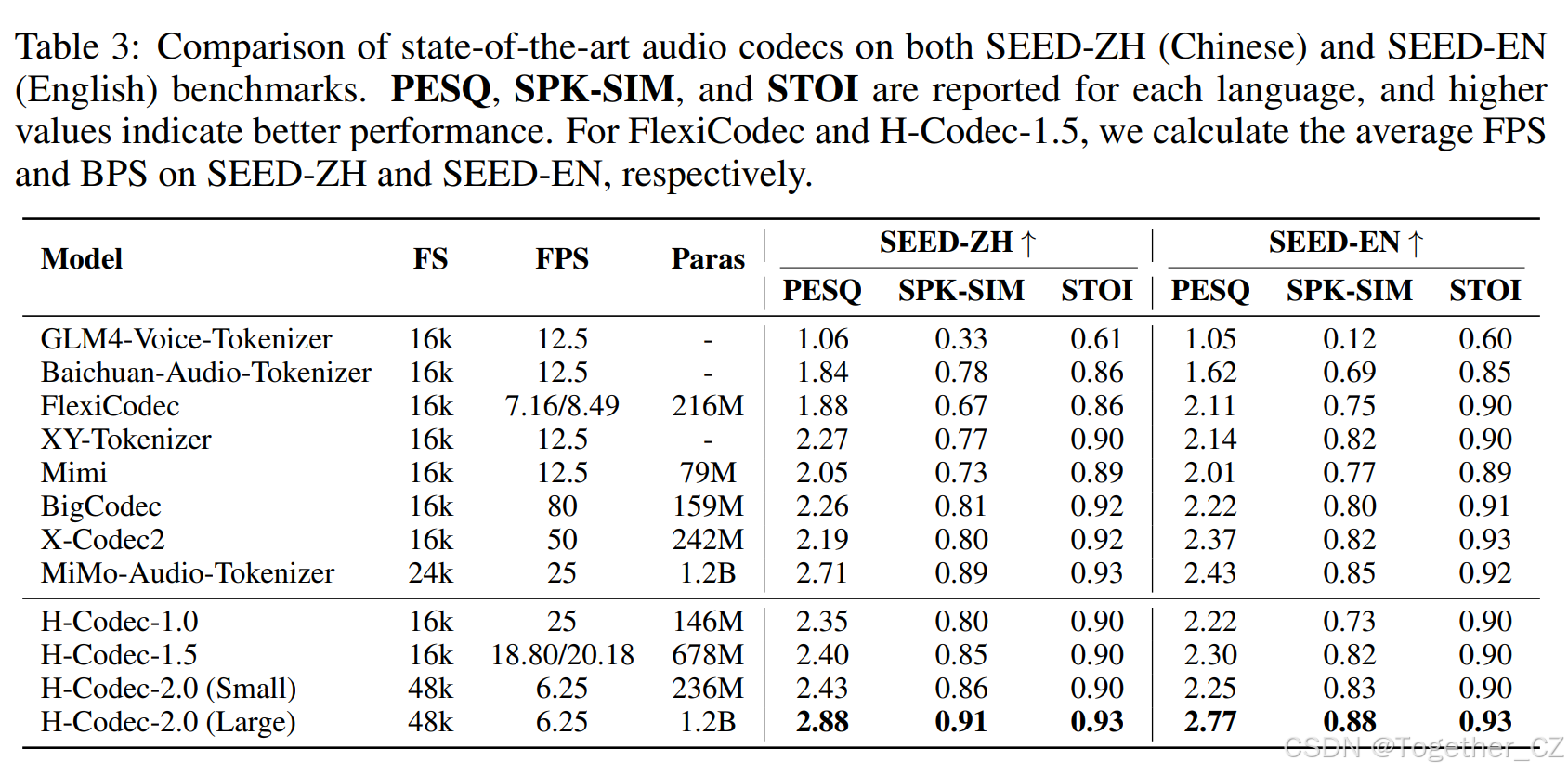
表 3:在 SEED-ZH 和 SEED-EN 基准上最先进音频编解码器的比较。报告了每种语言的 PESQ、SPK-SIM 和 STOI,数值越高表示性能越好。对于 FlexiCodec 和 H-Codec-1.5,我们分别在 SEED-ZH 和 SEED-EN 上计算平均 FPS 和 BPS。
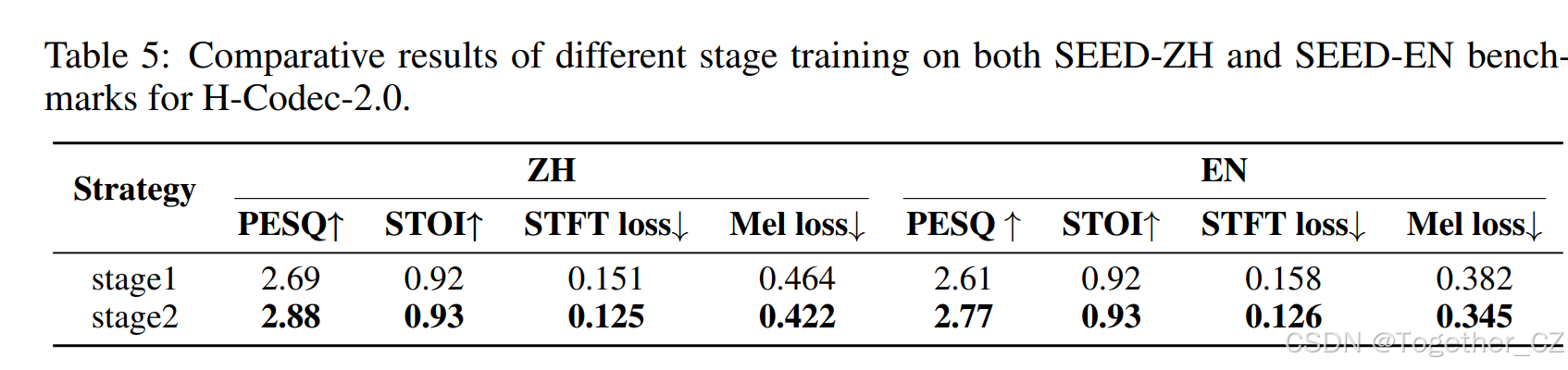
两阶段训练的有效性:如表 5 所示,我们观察到两阶段训练在 SEED-ZH 和 SEED-EN 基准上都比单阶段训练产生更好的性能。这验证了微调解码器有助于进一步提高重建质量,因为解码器可以专注于从固定的表示生成音频。
3.2 统一音频生成
3.2.1 音频处理性能
训练数据集:对于音频处理任务的训练,我们采用来自 VoxBox 数据集的干净语音样本,包括来自 LibriSpeech、MLS_English 和 Emilia_ZH 子集的大约 3.8k 小时数据。噪声语料库包括来自 DNS 挑战赛、FSD50K、WHAM!、DESED、DEMAND、MUSAN、DISCO、MUSDB18-HQ 和 TUT 城市声学场景的大约 460 小时数据。我们加入了来自 SLR28 的 60k 个房间脉冲响应样本以模拟混响。对于 LASS 任务,带有描述的音频样本来自 WavCaps、CLAP_FreeSound、VGGSound 和内部数据集,总共约 40k 小时。对于 EDIT-S 任务,我们使用来自内部数据集的 2M 个中文样本和 1M 个英文样本。对于 EDIT-A 任务,来自 AudioSet 和 CLAP_FreeSound 的样本分别被选为背景样本和音频事件样本。数据准备流程在附录 A 中描述。
实现细节:基于 LLaMA 的语言模型骨干有 16 层,具有 16 个注意力头和 1024 的隐藏维度,产生 481M 个可训练参数。我们的模型使用 AdamW 优化器训练 30 个周期,学习率在 4000 步预热后达到峰值 0.001,并在每个周期以 0.98 的衰减因子降低。参考音频和输入信号的长度在训练和推理阶段均设置为 5 秒。对于 SR、TSE、SS、VC 和 LASS 任务,我们训练多任务版本进行评估。对于编辑任务,我们分别为 EDIT-S 和 EDIT-A 训练任务特定版本。这些下游任务使用 H-Codec-1.0 实现。
评估指标:我们采用多种评估指标来评估跨任务生成音频的不同方面。对于语音任务,我们通过 DNSMOS、NISQA、SIM、WER 和 PLCMOS 评估质量。对于音频任务,我们使用 FAD、CLAPScore 和 CLAPScoreAA 来衡量生成音频的质量。评估指标的详细信息见附录 B.2。
表 4:不同编解码器模型在语音、音乐和音频领域就梅尔损失和 STFT 损失方面的比较。
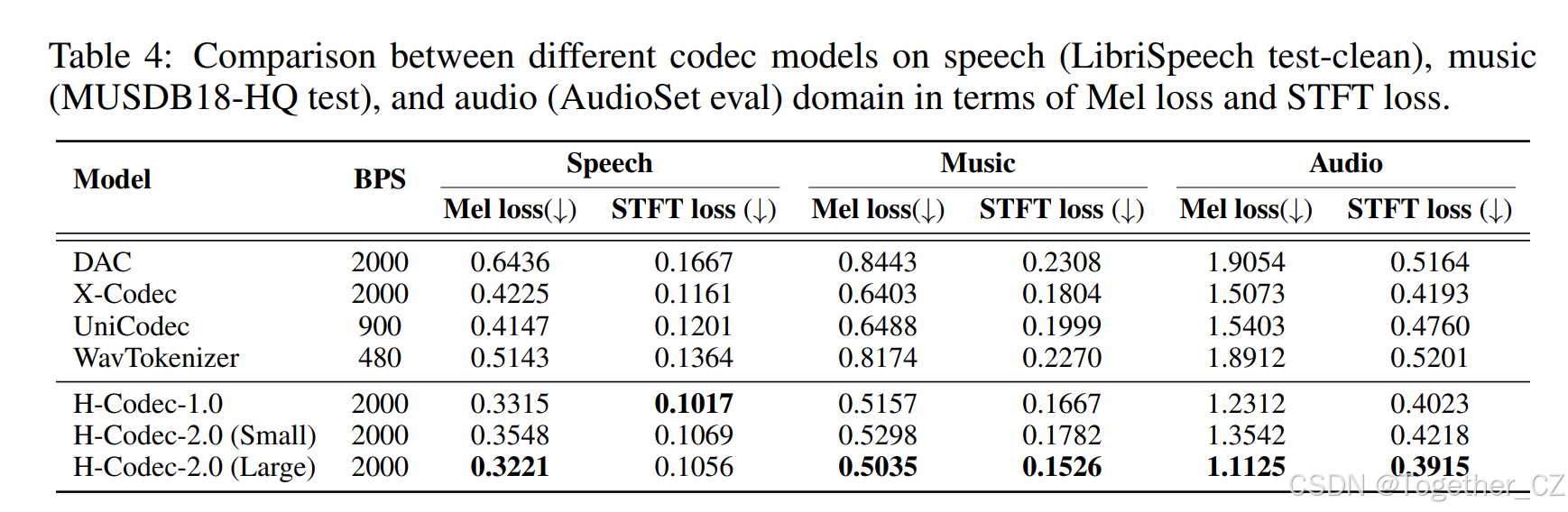
表 5:H-Codec-2.0 在 SEED-ZH 和 SEED-EN 基准上不同阶段训练的对比结果。
评估数据集:对于评估数据集,我们在 2020 DNS 挑战赛测试集和 2022 PLC 挑战赛盲测集上分别评估语音增强子任务和丢包隐藏子任务的语音恢复性能。TSE 的性能在 Libri2Mix clean 测试集上评估。SS、VC 和 LASS 的性能分别在 Libri2Mix noisy 测试集、VCTK 数据集和 2024 DCASE LASS 验证集上评估。
结果:表 6 展示了 QuarkAudio 与先前工作的比较。对于每个任务,我们选择一个训练数据与我们的设置密切相关的现有模型。可以看出,我们的模型取得了与基线相当或更优的性能。更详细的结果可以在 UniTok-Audio 中找到。
3.2.2 语音语义编辑
评估数据集:为了评估语音编辑能力,我们在 SEED-ZH 中随机选择 100 个话语,在 SEED-EN 中选择 100 个话语。对于每种语言,我们基于相应的 100 个话语生成 300 个样本用于插入、删除和替换任务。数据准备流程详见附录 A。
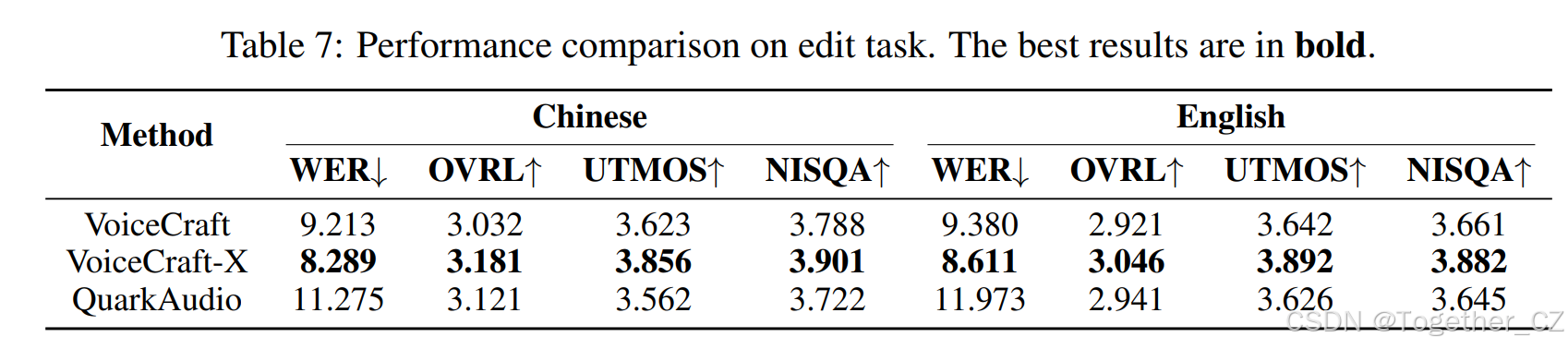
结果:表 7 总结了 EDIT-S 任务的客观结果,QuarkAudio 在 OVRL、UTMOS 和 NISQA 方面实现了与 VoiceCraft 相当的语音质量,展示了强大的信号重建保真度和自然度。然而,它表现出更高的 WER,这可归因于当前框架由于缺乏显式令牌级建模的端到端编解码器架构而导致的较弱语义对齐。正在进行的工作侧重于通过辅助监督改进语义瓶颈,以提高文本准确性而不影响音频质量。
3.2.3 音频事件编辑
评估数据集:我们从 AudioSet 中选择 100 个样本,从 CLAP_FreeSound 中选择 100 个样本,以模拟插入和删除场景的评估数据集。这些样本与训练数据集没有重叠。
表 6:QuarkAudio 和基线在所有任务上的性能评估。
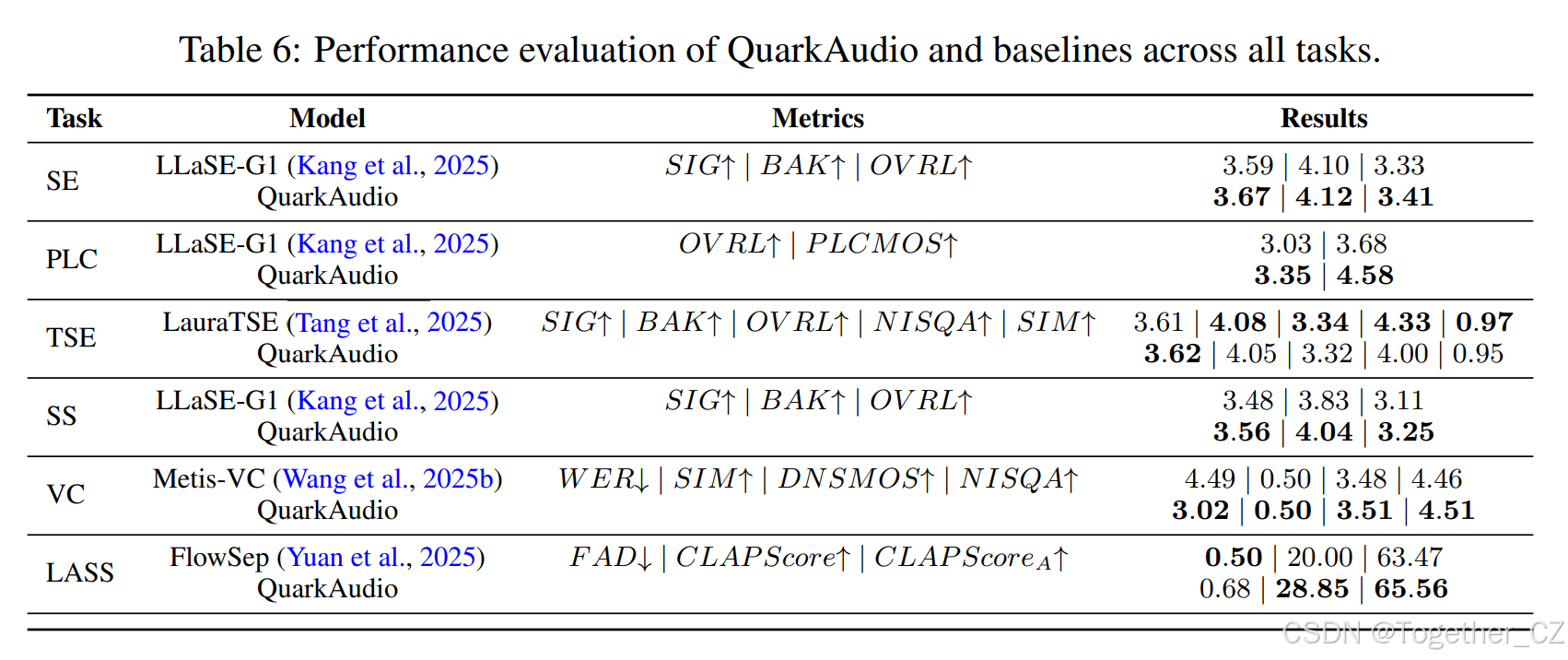
表 7:编辑任务的性能比较。最佳结果以 粗体 显示。
结果:它在文本指导设置下实现了有前景的事件音频编辑性能,在插入场景中达到了 10.08 的平均多尺度谱失真,在删除场景中达到了 9.87 的平均多尺度谱失真。
4 结论
在这项工作中,我们介绍了 QuarkAudio,一个基于离散统一表示的音频生成和编辑统一框架。通过利用 H-Codec 上的连续条件和并行令牌生成,我们的方法支持对语义和声学属性进行高效、指令驱动的编辑。大量实验证明,H-Codec 在多样化基准上取得了有竞争力的性能,不同版本的 H-Codec 支持广泛的实际应用场景。我们将 H-Codec 用于音频处理和编辑的自回归建模,其中任务特定行为通过任务令牌控制,使得在一个单一框架内实现多样化操作。实验结果验证了我们的模型有能力处理各种音频处理任务,并有潜力执行语音或音频事件编辑。我们将继续改进当前模型的性能,特别关注语音语义编辑和声音事件编辑。同时,我们计划进一步推进功能更强大的编解码器变体,并在下游应用中探索更广泛的音频任务类型。



















 3718
3718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











