



这篇文章的主要内容可以总结如下:
-
问题背景:现有的神经网络在减少浮点运算(FLOPs)的同时,往往忽略了每秒浮点运算(FLOPS)的效率,导致延迟并未显著降低。特别是深度卷积(DWConv)等算子由于频繁的内存访问,导致FLOPS较低。
-
解决方案:作者提出了一种新的部分卷积(PConv),通过仅对输入通道的一部分进行卷积操作,减少了冗余计算和内存访问,从而在降低FLOPs的同时提高了FLOPS。
-
FasterNet:基于PConv,作者设计了一个新的神经网络家族FasterNet。FasterNet在各种设备(如GPU、CPU、ARM)上表现出色,运行速度显著快于现有网络,同时在多个视觉任务(如图像分类、目标检测、实例分割)中保持了高准确率。
-
实验验证:通过大量实验,作者验证了PConv和FasterNet的有效性。FasterNet在ImageNet-1k分类任务上达到了最先进的性能,并在COCO数据集上的目标检测和实例分割任务中表现出色。
-
贡献:
-
强调了在减少FLOPs的同时提高FLOPS的重要性。
-
提出了PConv作为一种高效且简单的算子,有潜力替代DWConv。
-
提出了FasterNet,展示了其在速度和准确性上的优越性。
-
-
未来工作:作者指出了PConv和FasterNet的局限性,并提出了未来可能的研究方向,如优化PConv的实现和扩大FasterNet的感受野。
这篇文章通过提出PConv和FasterNet,解决了现有神经网络在FLOPS上的瓶颈问题,展示了其在各种视觉任务中的高效性和快速性。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目在这里。如下所示:
摘要
为了设计快速的神经网络,许多研究工作集中在减少浮点运算(FLOPs)的数量上。然而,我们观察到,FLOPs的减少并不一定会带来相应程度的延迟减少。这主要是由于浮点运算每秒(FLOPS)的效率低下。为了实现更快的网络,我们重新审视了流行的算子,并证明这种低FLOPS主要是由于算子频繁的内存访问,尤其是深度卷积(DWConv)。因此,我们提出了一种新颖的部分卷积(PConv),通过同时减少冗余计算和内存访问来更高效地提取空间特征。基于PConv,我们进一步提出了FasterNet,这是一个新的神经网络家族,它在各种设备上实现了比其他网络更快的运行速度,同时在不同视觉任务中保持了准确性。例如,在ImageNet-1k上,我们的FasterNet-T0在GPU、CPU和ARM处理器上分别比MobileViT-XXS快3.1倍、3.1倍和2.5倍,同时准确率提高了2.9%。我们的大型FasterNet-L在GPU上实现了83.5%的top-1准确率,与新兴的Swin-B相当,同时在GPU上的推理吞吐量提高了49%,在CPU上节省了42%的计算时间。

图1:我们的部分卷积(PConv)通过仅对少数输入通道应用滤波器,同时保持其余通道不变,实现了快速和高效。PConv的FLOPs比常规卷积更低,而FLOPS比深度卷积/组卷积更高。
1. 引言
神经网络在图像分类、检测和分割等各种计算机视觉任务中经历了快速发展。尽管它们出色的性能推动了许多应用,但当前的趋势是追求低延迟和高吞吐量的快速神经网络,以提供更好的用户体验、即时响应和安全原因等。
如何实现快速?研究人员和实践者更倾向于设计具有降低计算复杂性的成本效益高的快速神经网络,主要衡量标准是浮点运算(FLOPs)的数量。MobileNets、ShuffleNets和GhostNet等网络利用深度卷积(DWConv)和/或组卷积(GConv)来提取空间特征。然而,在减少FLOPs的过程中,这些算子往往伴随着内存访问的增加。MicroNet进一步分解和稀疏化网络,将其FLOPs推至极低水平。尽管在FLOPs上有所改进,但这种方法导致了低效的碎片化计算。此外,上述网络通常伴随着额外的数据操作,如连接、混洗和池化,这些操作在小型模型中的运行时间往往显著。
除了上述纯卷积神经网络(CNN)外,研究人员还对视觉Transformer(ViT)和多层感知器(MLP)架构的小型化和快速化产生了兴趣。例如,MobileViTs和MobileFormer通过将DWConv与改进的注意力机制结合来降低计算复杂性。然而,它们仍然面临DWConv的上述问题,并且需要专用硬件支持改进的注意力机制。使用先进但耗时的归一化和激活层也可能限制它们在设备上的速度。
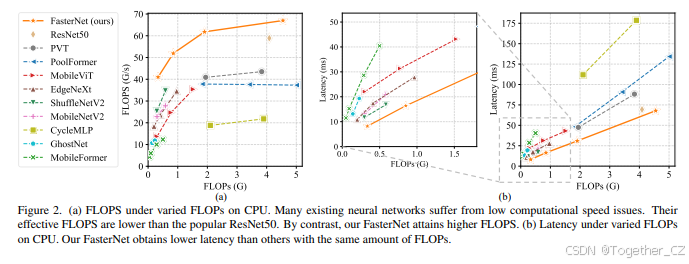
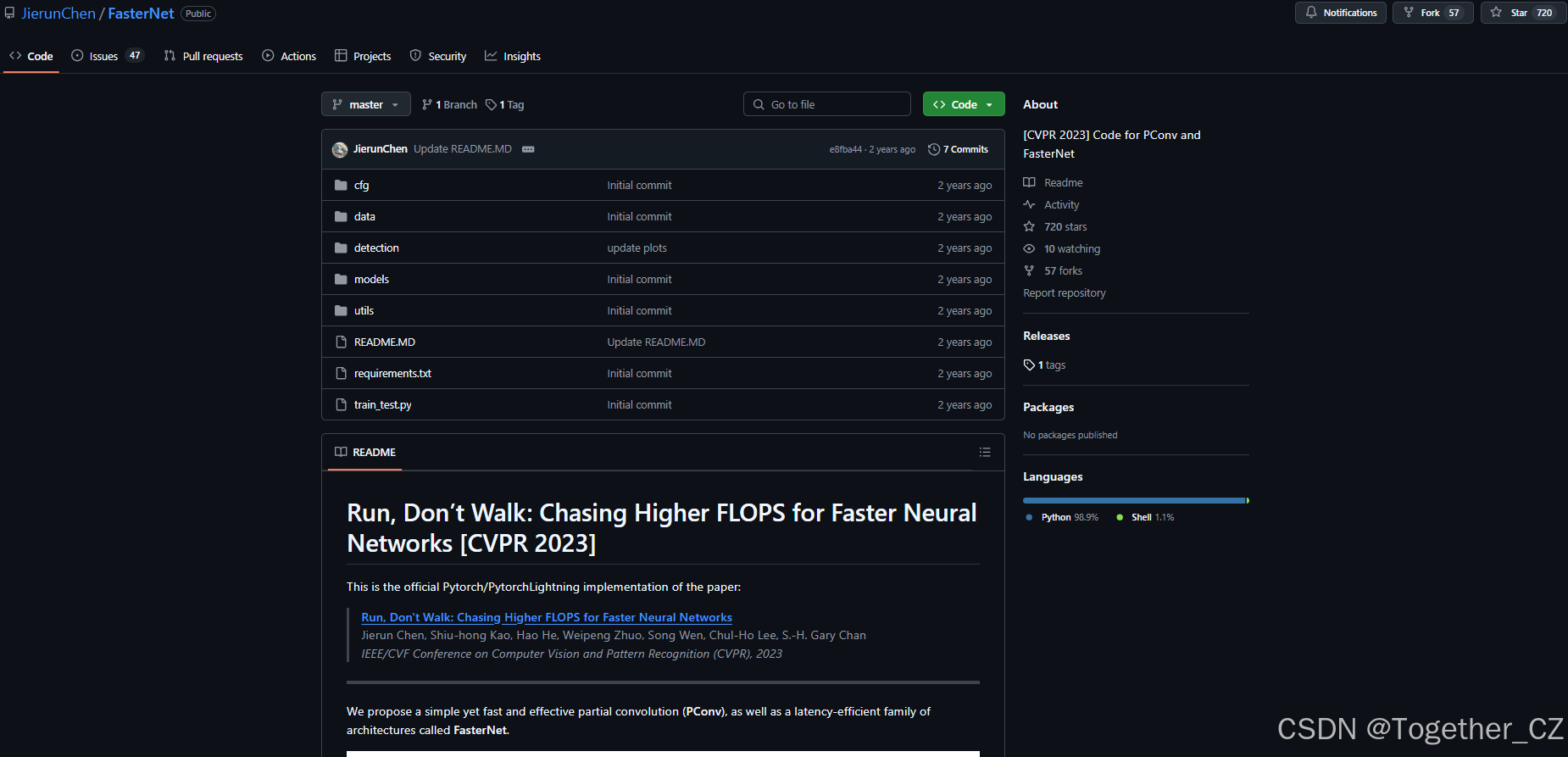
图2:(a) 在CPU上不同FLOPs下的FLOPS。许多现有的神经网络存在计算速度低的问题,其有效FLOPS低于流行的ResNet50。相比之下,我们的FasterNet获得了更高的FLOPS。(b) 在CPU上不同FLOPs下的延迟。我们的FasterNet在相同FLOPs下获得了比其他网络更低的延迟。
这些问题引发了一个疑问:这些“快速”神经网络真的快吗?为了回答这个问题,我们研究了延迟与FLOPs之间的关系,其关系由以下公式表示:
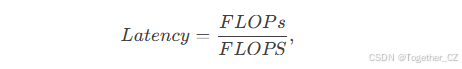
其中FLOPS是每秒浮点运算次数,作为有效计算速度的度量。尽管有许多尝试减少FLOPs,但它们很少同时考虑优化FLOPS以实现真正的低延迟。为了更好地理解这一情况,我们比较了典型神经网络在Intel CPU上的FLOPS。图2中的结果显示,许多现有神经网络的FLOPS较低,且其FLOPS通常低于流行的ResNet50。由于FLOPS如此低,这些“快速”神经网络实际上并不够快。它们减少的FLOPs并不能转化为相应程度的延迟减少。在某些情况下,甚至没有改进,甚至导致更差的延迟。例如,CycleMLP-B1的FLOPs是ResNet50的一半,但运行速度更慢(即CycleMLP-B1 vs. ResNet50:111.9ms vs. 69.4ms)。请注意,FLOPs与延迟之间的这种差异在之前的工作中也已被注意到,但部分由于它们使用了DWConv/GConv和各种低FLOPS的数据操作,因此仍未解决。人们认为没有更好的替代方案可用。
本文旨在通过开发一种简单、快速且有效的算子来消除这种差异,该算子在减少FLOPs的同时保持高FLOPS。具体来说,我们重新审视了现有算子,特别是DWConv,从计算速度(FLOPS)的角度进行了分析。我们发现导致低FLOPS问题的主要原因是频繁的内存访问。然后,我们提出了一种新颖的部分卷积(PConv)作为竞争性替代方案,它减少了计算冗余以及内存访问次数。图1展示了我们PConv的设计。它利用了特征图中的冗余,并系统地对输入通道的一部分应用常规卷积(Conv),而其余部分保持不变。从本质上讲,PConv的FLOPs比常规Conv低,而FLOPS比DWConv/GConv高。换句话说,PConv更好地利用了设备上的计算能力。PConv在提取空间特征方面也非常有效,正如我们在后文中通过实验验证的那样。
我们进一步介绍了FasterNet,它主要基于我们的PConv构建,作为一个新的网络家族,能够在各种设备上高速运行。特别是,我们的FasterNet在分类、检测和分割任务中实现了最先进的性能,同时具有更低的延迟和更高的吞吐量。例如,我们的FasterNet-T0在GPU、CPU和ARM处理器上分别比MobileViT-XXS快3.1倍、3.1倍和2.5倍,同时在ImageNet-1k上的准确率提高了2.9%。我们的大型FasterNet-L实现了83.5%的top-1准确率,与新兴的Swin-B相当,同时在GPU上的吞吐量提高了49%,在CPU上节省了42%的计算时间。总结来说,我们的贡献如下:
-
我们指出了在减少FLOPs的同时实现更高FLOPS的重要性,以实现更快的神经网络。
-
我们引入了一种简单、快速且有效的算子PConv,它有潜力取代现有的首选算子DWConv。
-
我们引入了FasterNet,它在GPU、CPU和ARM处理器等各种设备上运行速度快且通用。
-
我们在各种任务上进行了广泛的实验,验证了PConv和FasterNet的高速和有效性。
2. 相关工作
我们简要回顾了之前关于快速高效神经网络的工作,并将本文的工作与之区分开来。
CNN。CNN是计算机视觉领域的主流架构,尤其是在实际部署中,快速与准确同样重要。尽管有许多研究致力于提高效率,但其背后的原理或多或少都是进行低秩近似。具体来说,组卷积和深度可分离卷积(由深度卷积和点卷积组成)可能是最受欢迎的。它们已被广泛应用于面向移动/边缘的网络中,如MobileNets、ShuffleNets、GhostNet、EfficientNets、TinyNet、Xception、CondenseNet、TVConv、MnasNet和FBNet。尽管它们利用滤波器中的冗余来减少参数数量和FLOPs,但在增加网络宽度以补偿准确率下降时,它们会面临内存访问增加的问题。相比之下,我们考虑了特征图中的冗余,并提出了一种部分卷积,以同时减少FLOPs和内存访问。
ViT、MLP及其变体。自从Dosovitskiy等人将Transformer的应用范围从机器翻译扩展到计算机视觉领域以来,研究ViT的兴趣日益增长。许多后续工作试图在训练设置和模型设计方面改进ViT。一个显著的趋势是通过减少注意力算子的复杂性、将卷积引入ViT或两者兼而有之来追求更好的准确率-延迟权衡。此外,其他研究提出用简单的基于MLP的算子替换注意力机制。然而,它们往往演变为类似CNN的结构。在本文中,我们专注于分析卷积操作,特别是DWConv,原因如下:首先,注意力机制相对于卷积的优势尚不明确或有争议。其次,基于注意力的机制通常比其卷积对应物运行得更慢,因此在当前行业中不太受欢迎。最后,DWConv仍然是许多混合模型中的热门选择,因此值得仔细研究。

图3:预训练ResNet50中间层特征图的可视化,左上角的图像为输入。从定性角度来看,我们可以观察到不同通道之间存在高度冗余。
3. PConv和FasterNet的设计
在本节中,我们首先重新审视DWConv并分析其频繁内存访问的问题。然后,我们引入PConv作为解决该问题的竞争性替代算子。之后,我们介绍FasterNet并解释其细节,包括设计考虑。
3.1 预备知识

3.2 部分卷积作为基本算子
我们下面展示了通过利用特征图中的冗余可以进一步优化成本。如图3所示,特征图在不同通道之间具有高度相似性。这种冗余也在许多其他工作中被提及,但很少有人以简单而有效的方式充分利用它。
具体来说,我们提出了一种简单的PConv,以同时减少计算冗余和内存访问。图4的左下角展示了我们的PConv的工作原理。它仅对输入通道的一部分应用常规卷积以提取空间特征,而其余通道保持不变。为了连续或常规的内存访问,我们将前或后连续的![]() 通道视为整个特征图的代表进行计算。在不失一般性的情况下,我们考虑输入和输出特征图具有相同的通道数。因此,PConv的FLOPs仅为:
通道视为整个特征图的代表进行计算。在不失一般性的情况下,我们考虑输入和输出特征图具有相同的通道数。因此,PConv的FLOPs仅为:

3.3 PConv后接PWConv

3.4 FasterNet作为通用骨干网络
基于我们新颖的PConv和现成的PWConv作为主要构建算子,我们进一步提出了FasterNet,这是一个新的神经网络家族,它在许多视觉任务中运行速度快且高效。我们旨在保持架构尽可能简单,没有花哨的设计,以使其在硬件上友好。
图4:FasterNet的整体架构。它有四个层次化阶段,每个阶段由一堆FasterNet块组成,前面是一个嵌入层或合并层。最后三层用于特征分类。在每个FasterNet块中,一个PConv层后接两个PWConv层。我们将归一化和激活层仅放在中间层之后,以保持特征多样性并实现更低的延迟。
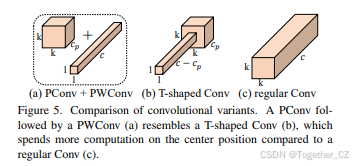
图5:卷积变体的比较。PConv后接PWConv(a)类似于T形卷积(b),与常规卷积(c)相比,它在中心位置上花费了更多的计算。
我们在图4中展示了整体架构。它有四个层次阶段,每个阶段之前都有一个嵌入层(一个步幅为4的常规Conv 4×4)或一个合并层(一个步幅为2的常规Conv 2×2),用于空间下采样和通道数扩展。每个阶段都有一堆FasterNet块。我们观察到,最后两个阶段中的块消耗较少的内存访问,并且往往具有更高的FLOPS,正如表1中经验验证的那样。因此,我们在最后两个阶段中放置了更多的FasterNet块,并相应地分配了更多的计算。每个FasterNet块都有一个PConv层,后跟两个PWConv(或Conv 1×1)层。它们一起表现为倒置残差块,其中中间层具有扩展的通道数,并且放置了一个快捷连接以重用输入特征。
除了上述算子外,归一化和激活层对于高性能神经网络也是必不可少的。然而,许多先前的工作在整个网络中过度使用这些层,这可能会限制特征的多样性,从而损害性能。它还可能减慢整体计算速度。相比之下,我们仅在每个中间PWConv之后放置它们,以保持特征的多样性并实现更低的延迟。此外,我们使用批量归一化(BN)而不是其他替代方案。BN的好处是它可以合并到其相邻的卷积层中以进行更快的推理,同时与其他方法一样有效。至于激活层,我们根据运行时间和有效性,经验性地为较小的FasterNet变体选择GELU,为较大的FasterNet变体选择ReLU。最后三层,即全局平均池化、Conv 1×1和全连接层,一起用于特征转换和分类。
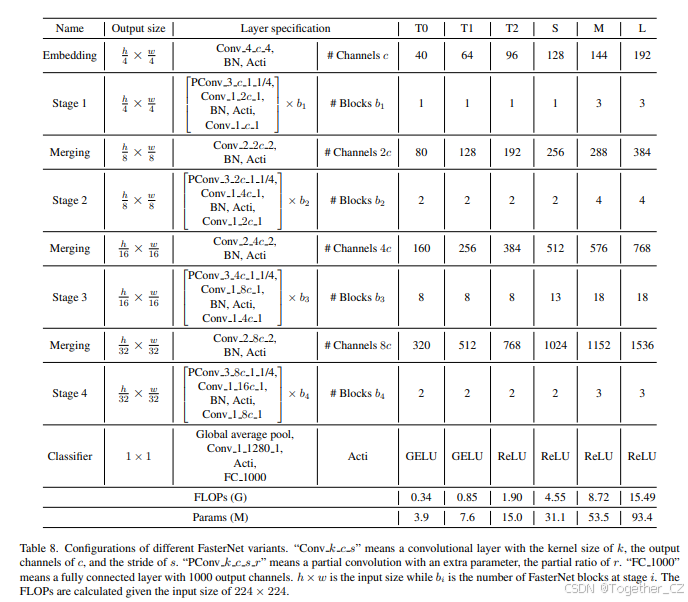
为了服务于不同计算预算下的广泛应用,我们提供了FasterNet的微小、小型、中型和大型变体,分别称为FasterNet-T0/1/2、FasterNet-S、FasterNet-M和FasterNet-L。它们共享相似的架构,但在深度和宽度上有所不同。详细的架构规格在附录中提供。
4. 实验结果
我们首先检查了PConv的计算速度及其与PWConv结合时的有效性。然后,我们全面评估了FasterNet在分类、检测和分割任务中的性能。最后,我们进行了简要的消融研究。
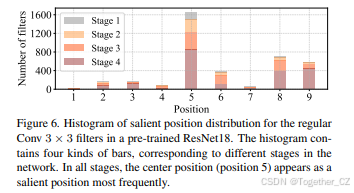
图6:预训练ResNet18中常规3×3卷积滤波器的显著位置分布直方图。直方图包含四种条形,分别对应网络中的不同阶段。在所有阶段中,中心位置(位置5)最频繁地作为显著位置出现。
为了对延迟和吞吐量进行基准测试,我们选择了以下三种典型的处理器,它们涵盖了广泛的计算能力:GPU(2080Ti)、CPU(Intel i9-9900X,使用单线程)和ARM(Cortex-A72,使用单线程)。我们报告了它们在批量大小为1的输入上的延迟,以及在批量大小为32的输入上的吞吐量。在推理过程中,BN层在适用的情况下合并到其相邻层中。
4.1 PConv具有高FLOPS且速度快
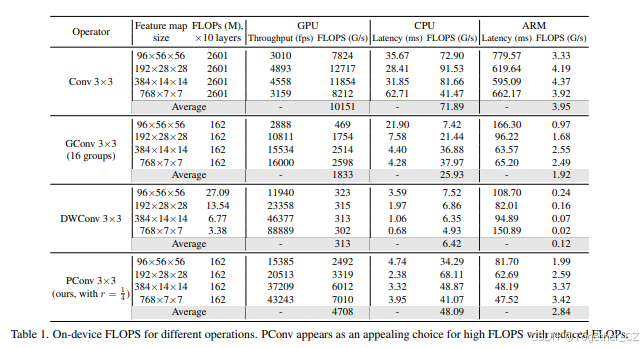
我们下面展示了我们的PConv速度快且更好地利用了设备上的计算能力。具体来说,我们堆叠了10层纯PConv,并将典型维度的特征图作为输入。然后,我们在GPU、CPU和ARM处理器上测量FLOPs和延迟/吞吐量,这还允许我们进一步计算FLOPS。我们对其他卷积变体重复相同的过程并进行比较。
表1中的结果显示,PConv总体上是一个具有高FLOPS和减少FLOPs的有吸引力的选择。它的FLOPs仅为常规Conv的1/16,并且在GPU、CPU和ARM上分别比DWConv高14倍、6.5倍和22.7倍的FLOPS。我们并不惊讶地看到,常规Conv具有最高的FLOPS,因为它已经经过多年的优化。然而,它的总FLOPs和延迟/吞吐量是无法承受的。GConv和DWConv尽管显著减少了FLOPs,但FLOPS却急剧下降。此外,它们倾向于增加通道数以补偿性能下降,然而,这增加了它们的延迟。
4.2 PConv与PWConv结合有效
我们接下来展示了PConv后接PWConv在近似常规Conv以转换特征图方面是有效的。为此,我们首先通过将ImageNet-1k验证集图像输入预训练的ResNet50来构建四个数据集,并提取每个阶段中第一个Conv 3×3前后的特征图。每个特征图数据集进一步分为训练(70%)、验证(10%)和测试(20%)子集。然后,我们构建了一个由PConv后接PWConv组成的简单网络,并使用均方误差损失在特征图数据集上对其进行训练。为了进行比较,我们还在相同设置下构建并训练了DWConv + PWConv和GConv + PWConv的网络。
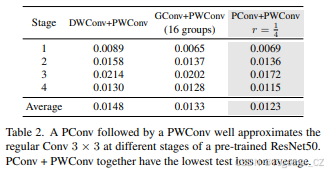
表2显示,PConv + PWConv实现了最低的测试损失,这意味着它们更好地近似了常规Conv的特征转换。结果还表明,仅从特征图的一部分捕获空间特征是足够且高效的。PConv显示出在设计快速有效神经网络方面成为新选择的巨大潜力。
4.3 FasterNet在ImageNet-1k分类上的表现
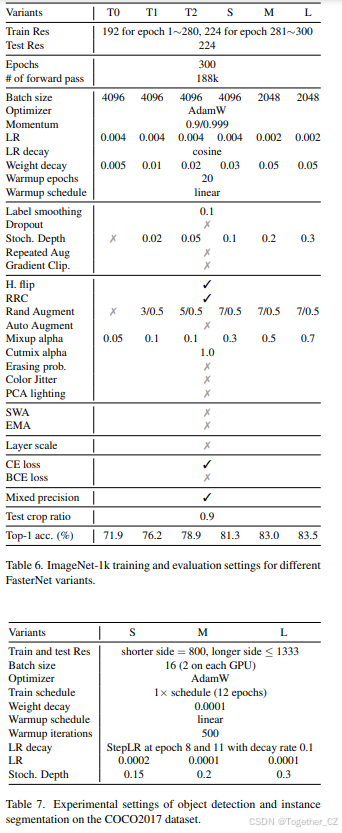
为了验证FasterNet的有效性和效率,我们首先在大规模ImageNet-1k分类数据集上进行了实验。它涵盖了1000个常见对象类别,包含约130万张用于训练的标记图像和5万张用于验证的标记图像。我们使用AdamW优化器训练我们的模型300个epoch。我们将FasterNet-M/L的批量大小设置为2048,其他变体的批量大小设置为4096。我们使用余弦学习率调度器,峰值值为0.001 ⋅ batch size/1024,并进行20个epoch的线性预热。我们应用了常用的正则化和增强技术,包括权重衰减、随机深度、标签平滑、Mixup、Cutmix和Rand Augment,不同FasterNet变体的幅度不同。为了减少训练时间,我们在前280个训练epoch中使用192×192分辨率,在剩余的20个epoch中使用224×224分辨率。为了公平比较,我们没有使用知识蒸馏和神经架构搜索。我们报告了在224×224分辨率和0.9裁剪比例下验证集上的top-1准确率。详细的训练和验证设置在附录中提供。
表3:ImageNet-1k基准测试的比较。具有相似top-1准确率的模型被分组在一起。对于每个组,我们的FasterNet在GPU上实现了最高的吞吐量,在CPU和ARM上实现了最低的延迟。所有模型均在224×224分辨率下进行评估,除了MobileViT和EdgeNeXt使用256×256分辨率。OOM表示内存不足。
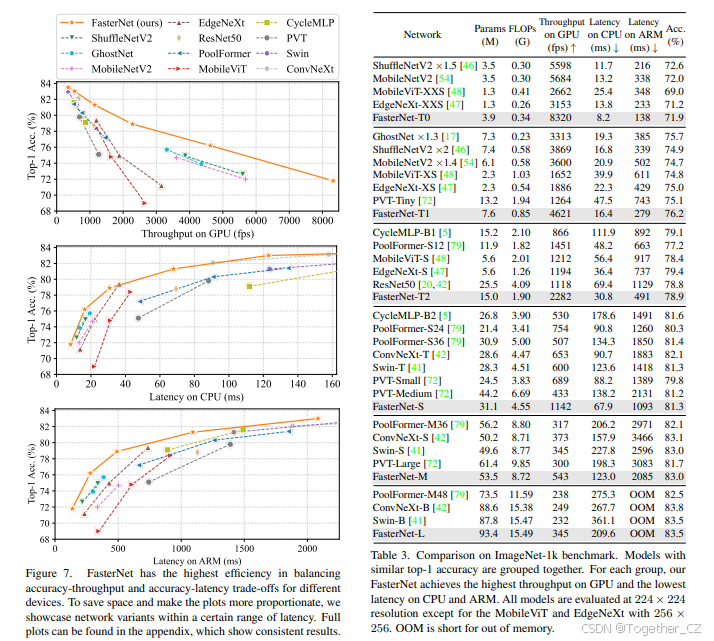
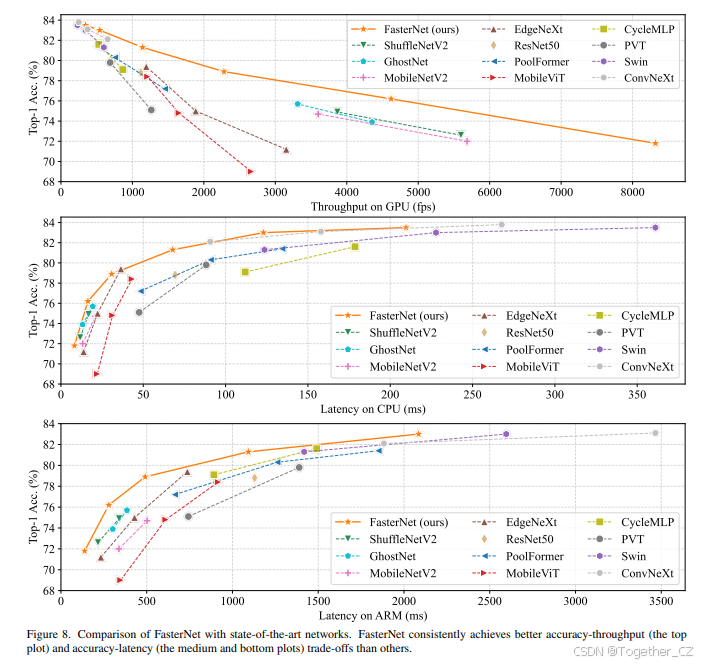
图7:FasterNet在不同设备上平衡准确率-吞吐量和准确率-延迟的权衡中具有最高的效率。为了节省空间并使图表更加均衡,我们展示了在一定延迟范围内的网络变体。完整的图表可以在附录中找到,结果显示一致。
图7和表3展示了FasterNet相对于最先进分类模型的优越性。图7中的权衡曲线清楚地表明,FasterNet在所有网络中在平衡准确率和吞吐量/延迟方面设定了新的最先进水平。从另一个角度来看,FasterNet在具有相似top-1准确率的情况下,比各种CNN、ViT和MLP模型在广泛设备上运行得更快。如表3所示,FasterNet-T0在GPU、CPU和ARM处理器上分别比MobileViT-XXS快3.1倍、3.1倍和2.5倍,同时准确率提高了2.9%。我们的大型FasterNet-L实现了83.5%的top-1准确率,与新兴的Swin-B和ConvNeXt-B相当,同时在GPU上的推理吞吐量提高了49%和39%,在CPU上节省了42%和22%的计算时间。鉴于这些有希望的结果,我们强调,FasterNet在架构设计上比许多其他模型简单得多,这展示了设计简单而强大的神经网络的可行性。
4.4 FasterNet在下游任务中的表现
为了进一步评估FasterNet的泛化能力,我们在具有挑战性的COCO数据集上进行了目标检测和实例分割实验。作为一种常见做法,我们使用ImageNet预训练的FasterNet作为骨干,并为其配备流行的Mask R-CNN检测器。为了突出骨干本身的有效性,我们简单地遵循PoolFormer并采用AdamW优化器、1×训练计划(12个epoch)、批量大小为16以及其他训练设置,无需进一步的超参数调整。
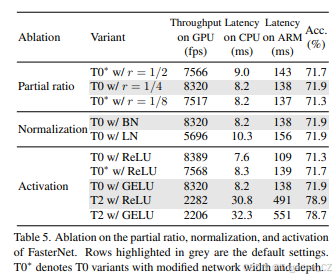
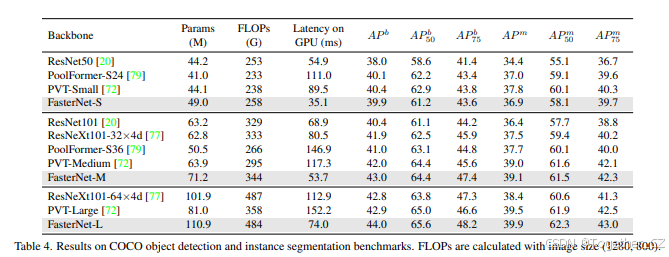
表4显示了FasterNet与代表性模型之间的比较结果。FasterNet始终优于ResNet和ResNext,具有更低的延迟和更高的平均精度(AP)。具体来说,FasterNet-S节省了36%的计算时间,并且与标准基线ResNet50相比,box AP提高了+1.9,mask AP提高了+2.4。FasterNet还与ViT变体竞争。在相似的FLOPs下,FasterNet-L将PVT-Large的延迟减少了一半,即从152 ms减少到74 ms(在GPU上),并且box AP提高了+1.1,mask AP提高了+0.4。
4.5 消融研究
我们对部分比例rr的值以及激活和归一化层的选择进行了简要的消融研究。我们比较了不同变体在ImageNet top-1准确率和设备延迟/吞吐量方面的表现。结果总结在表5中。对于部分比例rr,我们默认将其设置为1441,这在相似复杂度下实现了更高的准确率、更高的吞吐量和更低的延迟。过大的部分比例rr会使PConv退化为常规Conv,而过小的值会使PConv在捕获空间特征方面效果较差。对于归一化层,我们选择BatchNorm而不是LayerNorm,因为BatchNorm可以合并到其相邻的卷积层中以进行更快的推理,同时在我们的实验中与LayerNorm一样有效。对于激活函数,有趣的是,我们经验性地发现GELU比ReLU更适合FasterNet-TO/T1模型。然而,对于FasterNet-T2/S/M/L,情况则相反。由于篇幅限制,我们仅在表5中展示了两个示例。我们推测,GELU通过具有更高的非线性加强了FasterNet-TO/T1,而对于较大的FasterNet变体,这种好处逐渐消失。
5. 结论
在本文中,我们研究了现有神经网络普遍存在的低每秒浮点运算(FLOPS)问题。我们重新审视了一个瓶颈算子DWConv,并分析了其导致速度下降的主要原因——频繁的内存访问。为了克服这一问题并实现更快的神经网络,我们提出了一种简单、快速且有效的算子PConv,它可以轻松地插入许多现有网络中。我们进一步介绍了基于PConv的通用FasterNet,它在各种设备和视觉任务上实现了最先进的速度和准确率权衡。我们希望我们的PConv和FasterNet能够激发更多关于简单而有效的神经网络的研究,超越学术界,直接影响工业和社区。
致谢:本工作部分由香港研究资助局资助,资助号为16200120。C.-H. Lee的工作部分由美国国家科学基金会资助,资助号为IIS-2209921。
附录
在附录中,我们提供了实验设置的更多细节、完整的比较图、架构配置、PConv的实现、与相关工作的比较、局限性以及未来工作。
A. ImageNet-1k实验设置
我们在表6中提供了ImageNet-1k的训练和评估设置。它们可用于重现我们在表3和图7中的主要结果。不同的FasterNet变体在正则化和增强技术的幅度上有所不同。随着模型变大,幅度增加以缓解过拟合并提高准确率。请注意,表3和图7中的大多数比较工作,例如MobileViT、EdgeNext、PVT、CycleMLP、ConvNeXt、Swin等,也采用了这种高级训练技术(ADT)。有些甚至严重依赖超参数搜索。对于没有ADT的其他工作,即ShuffleNetV2、MobileNetV2和GhostNet,尽管比较不完全公平,但我们仍将其包括在内以供参考。
B. 下游任务实验设置
对于COCO2017数据集上的目标检测和实例分割,我们为FasterNet骨干配备了流行的Mask R-CNN检测器。我们使用ImageNet-1k预训练权重初始化骨干,并使用Xavier初始化附加层。详细设置总结在表7中。
C. ImageNet-1k上的完整比较图
图8展示了ImageNet-1k上的完整比较图,它是图7的扩展,具有更大的延迟范围。图8显示了一致的结果,即FasterNet在平衡准确率和GPU、CPU和ARM处理器上的延迟/吞吐量方面比其他网络表现更好。
D. 详细的架构配置
我们在表8中展示了详细的架构配置。虽然不同的FasterNet变体共享统一的架构,但它们在网络宽度(通道数)和网络深度(每个阶段的FasterNet块数)上有所不同。架构末尾的分类器用于分类任务,但在其他下游任务中被移除。
E. PConv的实现
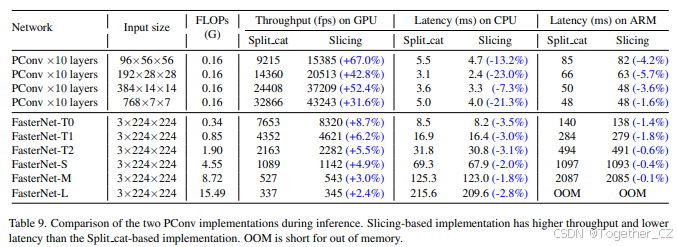
我们在列表1中提供了基于PyTorch的PConv实现。有两个前向传递选择,即forward_slicing和forward_split_cat。forward_slicing选择将卷积输出写入输入的位置,用于更快的推理,但不用于训练,因为就地操作会修改梯度计算。相比之下,forward_split_cat选择将卷积输出与未触及的特征图连接,保留了中间梯度计算,用于训练。表9显示了推理期间这两种选择的速度比较。forward_slicing实现比另一种实现运行得更快,特别是对于小型模型和计算能力更强的设备,例如在GPU上的FasterNet-T0。
F. 与相关工作的更多比较
提高FLOPS。还有一些其他工作也在研究FLOPS问题并试图改进它。它们通常遵循现有算子并尝试找到适当的配置,例如Repl_KNet简单地增加内核大小,而TRT-ViT重新排序架构中的不同块。相比之下,本文通过提出一种新颖且高效的PConv推动了该领域的发展,开辟了新的方向,并可能为FLOPS改进提供更大的空间。
表8:不同FasterNet变体的配置。“Conv k c s”表示卷积层,其内核大小为k,输出通道为c,步幅为s。“PConv k c s r”表示部分卷积,其中r为部分比例。“FC 1000”表示具有1000个输出通道的全连接层。h × w是输入大小,而bi是第i阶段的FasterNet块数量。FLOPs是在输入大小为224×224的情况下计算的。
PConv vs. GConv。PConv在原理上等同于修改后的GConv,它在一个组上操作并保持其他组不变。尽管简单,但这种修改在之前未被探索。它在防止算子过度内存访问方面具有重要意义,并且在计算上更高效。从低秩近似的角度来看,PConv通过进一步减少滤波器内冗余来改进GConv。
FasterNet vs. ConvNeXt。我们的FasterNet在用PConv替换DWConv后看起来与ConvNeXt相似。然而,它们的动机不同。虽然ConvNeXt通过试错法寻找更好的结构,但我们在PConv后附加PWConv以更好地聚合所有通道的信息。此外,ConvNeXt遵循ViT使用较少的激活函数,而我们有意从PConv和PWConv的中间移除它们,以最小化它们在近似常规Conv时的误差。
其他高效推理范式。我们的工作专注于高效的网络设计,与其他范式(如神经架构搜索(NAS)、网络剪枝和知识蒸馏)正交。它们可以应用于本文以获得更好的性能。然而,我们选择不这样做,以保持我们的核心思想集中,并使性能增益清晰和公平。
其他部分/掩码卷积工作。有几项工作与我们的PConv共享相似的名称。然而,它们在目标和方法上差异很大。例如,它们在部分像素上应用滤波器以排除无效patch,启用自监督学习或合成新图像,而我们的目标是通道维度以实现高效推理。
1 import torch
2 import torch.nn as nn
3 from torch import Tensor
4
5
6 class PConv(nn.Module):
7 """ Partial convolution (PConv).
8 """
9 def __init__(self,
10 dim: int,
11 n_div: int,
12 forward: str = "split_cat",
13 kernel_size: int = 3) -> None:
14 """ Construct a PConv layer.
15
16 :param dim: Number of input/output channels
17 :param n_div: Reciprocal of the partial ratio.
18 :param forward: Forward type, can be either ’split_cat’ or ’slicing’.
19 :param kernel_size: Kernel size.
20 """
21 super().__init__()
22 self.dim_conv = dim // n_div
23 self.dim_untouched = dim - self.dim_conv
24
25 self.conv = nn.Conv2d(
26 self.dim_conv,
27 self.dim_conv,
28 kernel_size,
29 stride=1,
30 padding=(kernel_size - 1) // 2,
31 bias=False
32 )
33
34 if forward == "slicing":
35 self.forward = self.forward_slicing
36 elif forward == "split_cat":
37 self.forward = self.forward_split_cat
38 else:
39 raise NotImplementedError
40
41 def forward_slicing(self, x: Tensor) -> Tensor:
42 """ Apply forward pass for inference. """
43 x[:, :self.dim_conv, :, :] = self.conv(x[:, :self.dim_conv, :, :])
44
45 return x
46
47 def forward_split_cat(self, x: Tensor) -> Tensor:
48 """ Apply forward pass for training. """
49 x1, x2 = torch.split(x, [self.dim_conv, self.dim_untouched], dim=1)
50 x1 = self.conv(x1)
51 x = torch.cat((x1, x2), 1)
52
53 return xG. 局限性和未来工作
我们已经证明PConv和FasterNet快速且有效,与现有算子和网络竞争。然而,本文存在一些小的技术局限性。首先,PConv设计为仅对输入通道的一部分应用常规卷积,而其余部分保持不变。因此,部分卷积的步幅应始终为1,以便对齐卷积输出的空间分辨率和未触及通道的空间分辨率。请注意,仍然可以通过架构中的附加下采样层来下采样空间分辨率。其次,虽然我们提供了PConv的两种前向传递实现,但我们认为它们不一定是最优的。可能存在更高效的实现,使用通道最后的张量格式、自定义C++和CUDA扩展。最后,我们的FasterNet仅基于卷积算子构建,可能具有有限的感受野。未来的努力可以扩大其感受野并将其与其他算子结合以追求更高的准确率。
总结
本文通过提出PConv和FasterNet,解决了现有神经网络在FLOPS上的瓶颈问题,展示了其在各种视觉任务中的高效性和快速性。未来的研究可以进一步优化PConv的实现,并探索如何扩大FasterNet的感受野以提升其性能。



















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











