




 这篇博客主要介绍了Stable Baselines库的用户向导,包括如何开始使用该库进行强化学习算法的训练。作者提供了Cartpole环境下的PPO2算法应用实例,并指出大多数强化学习包遵循sklearn的接口设计。此外,还提到了如果环境和策略在Gym中已注册,可以简化模型训练流程。
这篇博客主要介绍了Stable Baselines库的用户向导,包括如何开始使用该库进行强化学习算法的训练。作者提供了Cartpole环境下的PPO2算法应用实例,并指出大多数强化学习包遵循sklearn的接口设计。此外,还提到了如果环境和策略在Gym中已注册,可以简化模型训练流程。
大多数强化学习算法包都试图采用sklearn风格语法。
下面是一个简单的案例,展示如何在Cartpole环境中训练和运行PPO2.
import gym
from stable_baselines.common.policies import MlpPolicy
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines import PPO2
env = gym.make('CartPole-v1')
env = DummyVecEnv([lambda: env]) # The algorithms require a vectorized environment to run
model = PPO2(MlpPolicy, env, verbose=1)
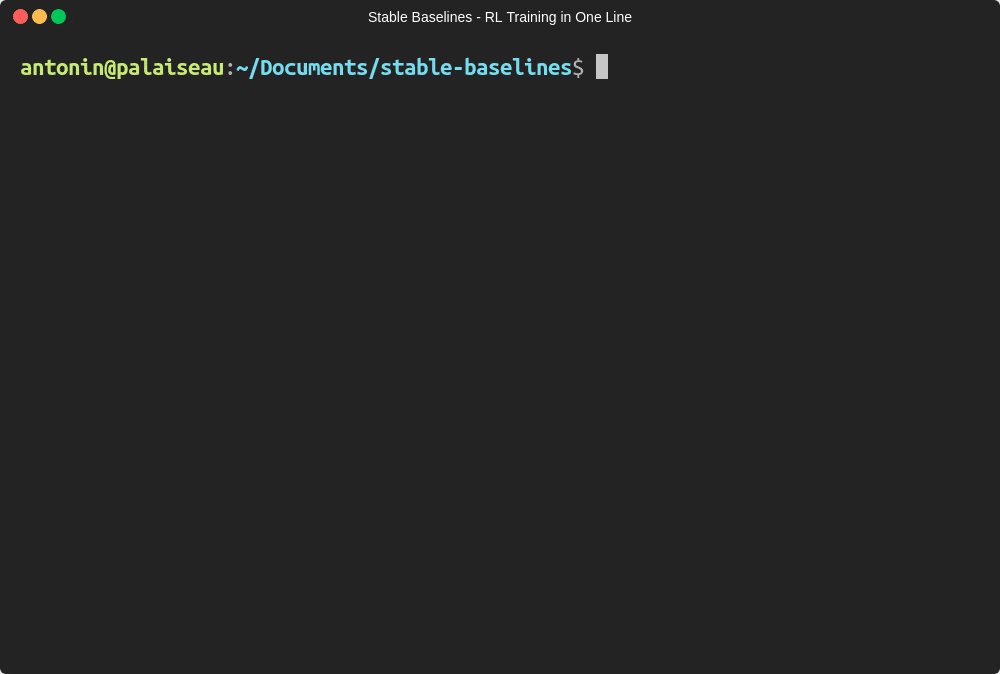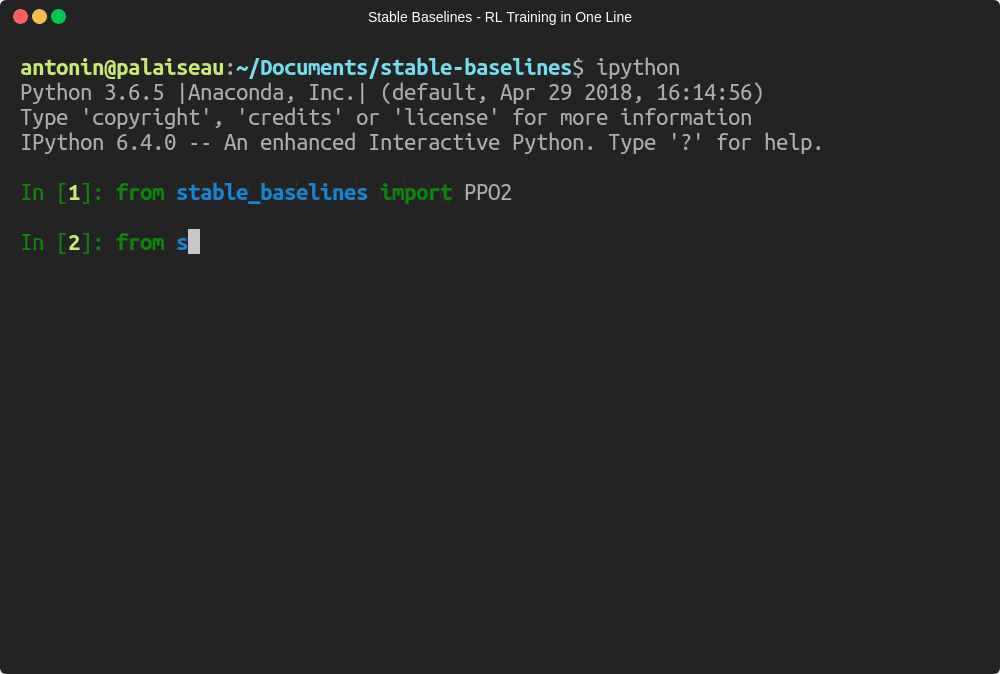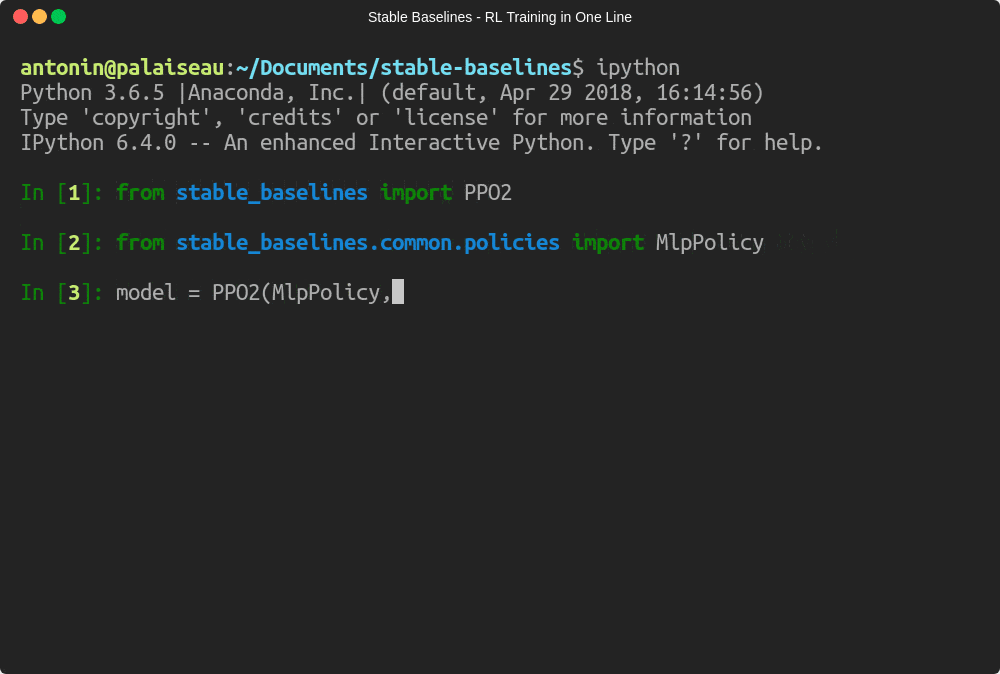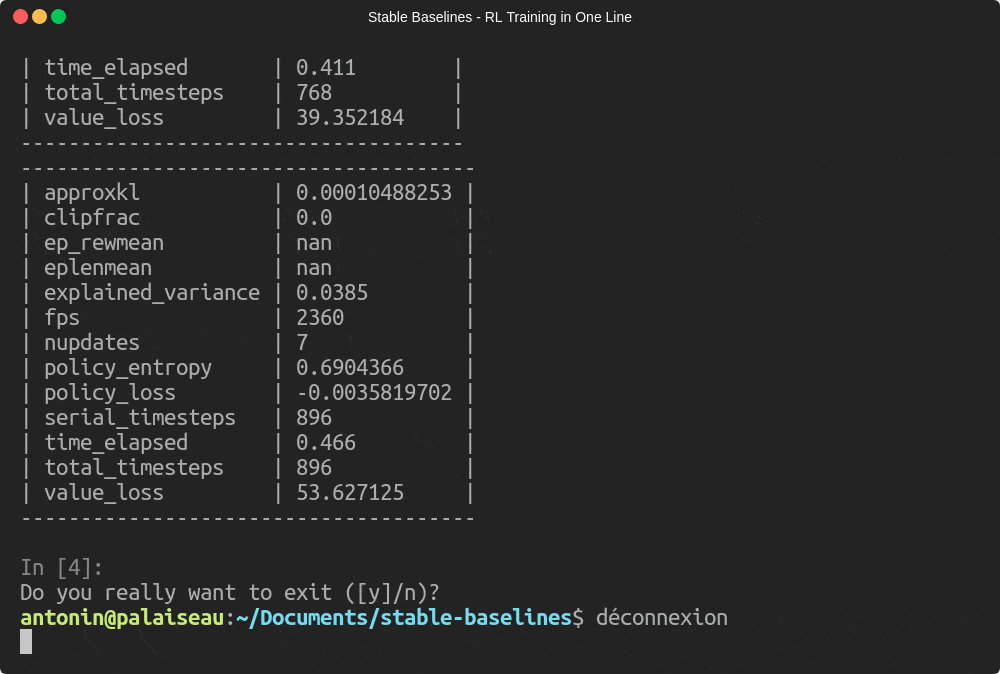
model.learn(total_timesteps=10000)
obs = env.reset()
for i in range(1000):
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
或者,如果环境已在Gym注册、策略也已注册,仅仅用liner训练一个模型:
# 用一行代码定义并训练一个RL agent
from stable_baselines import PPO2
model = PPO2('MlpPolicy', 'CartPole-v1').learn(10000)


















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









