




 本文分享了使用Python爬虫技术从链家网站提取二手房在售数量的具体步骤,包括发送请求获取网页内容、利用BeautifulSoup解析HTML、定位目标数据标签及使用正则表达式精确匹配所需数据。
本文分享了使用Python爬虫技术从链家网站提取二手房在售数量的具体步骤,包括发送请求获取网页内容、利用BeautifulSoup解析HTML、定位目标数据标签及使用正则表达式精确匹配所需数据。
需求场景,爬虫数据提取。
- 通过text = request.get().text()得到目标网页的内容
- 通过text_html = BeautifulSoup(text)得到html形式
- 通过tag = text_html.find_all(label)[i]得到目标数据所在标签
- 通过NavigableString = tag.get_text()得到目标标签内的字符串内容
- 通过正则表达式匹配出特定字母后面的数据,就是想要的数据
本文遇到的是爬取链家二手房在售数目,最后得到这样一段字符串
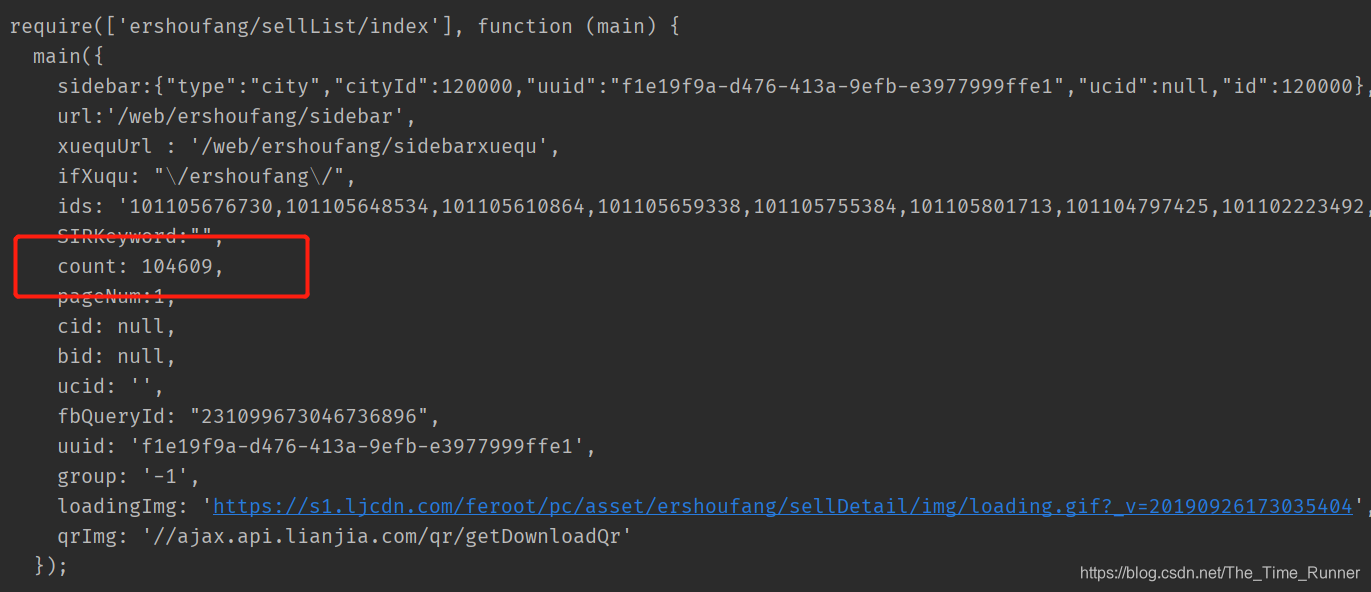
所用正则表达式:count:\s\d{1,9}

















 2245
2245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









