






 本文探讨了Redis ZSet中score数据精度的问题,指出score必须为浮点型,通常使用double,但存在精度损失。在Java中,double类型的精度问题可能导致错误的结果。建议在商业计算中使用BigDecimal。实验表明,时间戳作为score不会引发精度问题,但超过17位的数字可能会导致精度丢失。因此,应谨慎处理高精度需求,必要时采取预处理措施。
本文探讨了Redis ZSet中score数据精度的问题,指出score必须为浮点型,通常使用double,但存在精度损失。在Java中,double类型的精度问题可能导致错误的结果。建议在商业计算中使用BigDecimal。实验表明,时间戳作为score不会引发精度问题,但超过17位的数字可能会导致精度丢失。因此,应谨慎处理高精度需求,必要时采取预处理措施。
在开测项目服务端的开发中,redis的zset是常用的数据结构。因为它元素不重复且每个元素都有一个分数的特点,经常作为有序队列和元素排序来使用,排序的方式自然是通过每个元素的score的大小。
score的数据类型
在计算机中,字符都是可以比较大小的,那么score的数据类型是不是只要是字符型就可以的呢?答案是否定的。如下图,当我们使用非数字类型的时候会提示“(error) value is not a valid float”的错误信息。同时这个错误信息告诉我们,score类型是浮点型的数据。
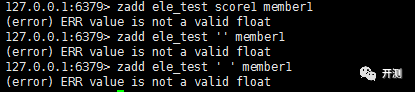
既然是浮点型的数据都可以,那么我们使用int,long,float,double等数字类型,当然都是可以的。但是浮点型数据自然都是有精度的,且会影响我们的业务开发。
Ps: 在相关的参考资料中有说是double类型的,有说是数字转成字符串类型存到redis中,查询时返回是字符串类型,从结果上观察都是成立的。但是在Jedis驱动中入参和出参使用的都是double数据类型。
java的数据精度与redis的数据精度
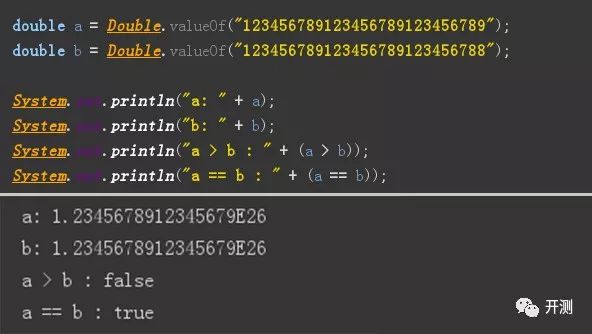
先看一个有趣的例子,如下图,使用java代码,声明两个double的变量a和b,值都是27个数字,a的末位数字比b的末位数字大1,其他位置的数字相同,a是大于b的,但是代码输出的结果是a等于b,a和b也变成了18个有效数字的科学计数。
除了上面的问题,在项目中用到double类型数据四则运算时,经常出现精度丢失的问题,总是在一个正确的结果左右偏0.0000**1。
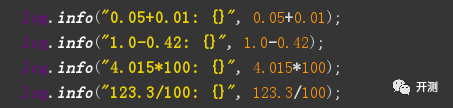
其输出结果如下:
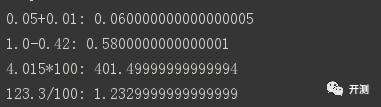
在商业型软件中,这种精度问题,会有很大的影响。在《Effective Java》这本书提供了解决方法,float和double只能用来做科学计算或者是工程计算,在商业计算中我们要用 java.math.BigDecimal。但是在Jedis驱动中,使用的是double作为形参的,我们执行像zset中插入3.14的操作,代码如下。
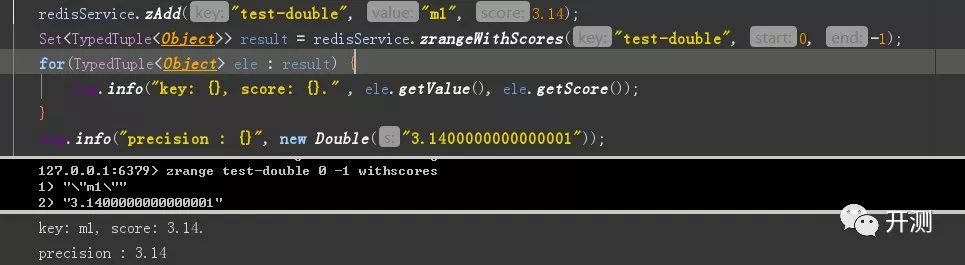
我们通过redis-cli去查看的时候,结果显示的是3.1400000000000001,但是java读取出来的时候显示的是3.14。
通过debug,我们发现,并不是数据插入时导致的精度问题,而是从redis中读取的时候出现的问题,由此我们可以猜测是redis自身的浮点型精度的问题。
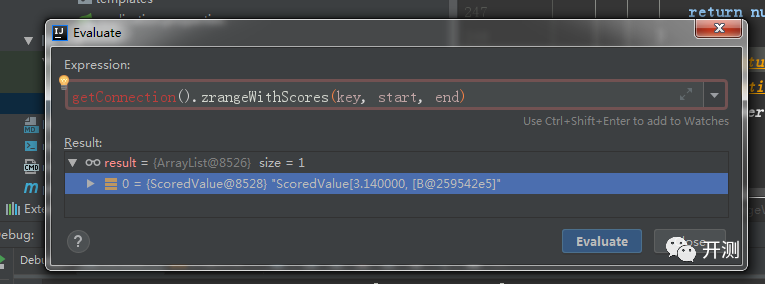
我们可以通过redis-cli来验证一下:
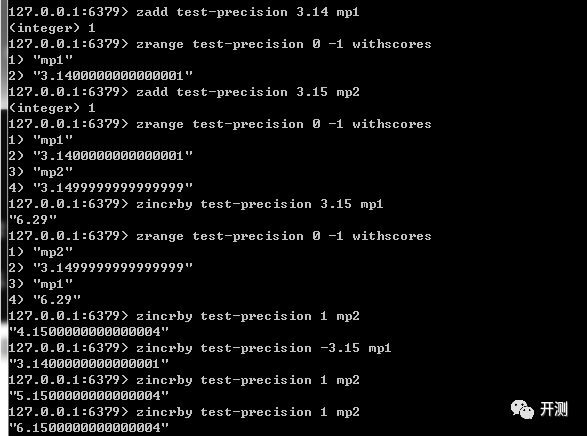
果然如前面猜测的一样,redis自身的浮点型精度是有问题的,并且做zincrby的时候也是有精度问题的。
开测中使用的一个例子
笔者在项目中,目前没有遇到因为精度而导致的问题,只是在开测的服务端开发中,会有使用时间戳作为score来进行任务的排序,时间戳由14位数字组成的长整型,向上转型成double,存入redis中会变成成科学计数法,为了避免精度丢失的问题,才进行了相关实验。
经过实验,当zset中的长整型数字位数超过17位的时候才会出现精度丢失的问题,如下图。
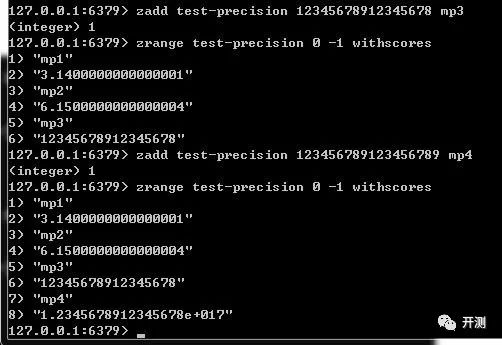
此结果与java的double类型保持一致,所以使用时间戳作为分数不会造成精度丢失的问题,同时,我们应该避免使用超过17位的数字作为分数。如果不得不使用,笔者认为一般是数据量特别大、使用uuid,或者是精度要求比较高,这些情况可以通过一些算法做预处理,只要达到预期的效果就行。
小结
本文对redis的zset的score的数据精度问题做了简单的分析和总结,希望能在以后的开发中,能够避免因为score精度而引起业务问题。
哈喽,喜欢这篇文章的话烦请点个赞哦!万分感谢(*^▽^*)PS:有问题可以联系我们哦v ceshiren001
更多技术文章

















 1319
1319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









