




 本文深入探讨了Pandas在处理大数据集时的性能优化策略,包括使用chunksize参数、dask库、hdf文件格式以及多进程数据帧库Modin。此外,还介绍了Python在数据科学、机器学习和工程实践中的实用技巧,如特征选择、数据读取、编码问题解决、文件转换、数据库操作和模型部署。
本文深入探讨了Pandas在处理大数据集时的性能优化策略,包括使用chunksize参数、dask库、hdf文件格式以及多进程数据帧库Modin。此外,还介绍了Python在数据科学、机器学习和工程实践中的实用技巧,如特征选择、数据读取、编码问题解决、文件转换、数据库操作和模型部署。
1.单一文件数据量很大
1.
.chunksize()
在工作中数据量特别大的单独csv文件时,由于df.read_csv()读取的很慢,并且在进行数据处理的很繁琐。在网上看到read_csv()有.chunksize() 参数,括号里可以设置每一块的数据量,并且类似用groupby()的形式读取,后进行批量操作。
或者采用dask的方式读取文件,代码如下:
相同的2.4G的csv文件,分别用pandas和dask加载。
pandas:2min 3s
dask.dataframe:81.8 ms
import dask.dataframe as dd
import dask
import gc
train_df = dd.read_csv("XX.csv")
gc.collect() #删除无用的变量,使用gc.collect()清空内存
无意中在知乎看到介绍数据hdf文件储存,并且介绍可以第一次读取csv文件后,将其导出为hdf文件格式保存,后续再读取时,读hdf文件(.h5)速度会快很多倍。
start_time = time.time()
df = pd.read_csv(r"C:\Users\yunda\Desktop\test.csv")
end_time = time.time()
print("用时%s秒"%(end_time - start_time))
#用时0.7988379001617432秒
df.to_hdf("C:\\Users\\yunda\\Desktop\\test.h5",key = "df")
start_time = time.time()
df1 = pd.read_hdf(r"C:\Users\yunda\Desktop\test.h5")
end_time = time.time()
print("用时%s秒"%(end_time - start_time))
用时0.04186892509460449秒
2.对dataframe进行迭代(遍历)的时候有三种iterrows(), iteritems(), itertuples()
iterrows(): 将DataFrame迭代为(index, Series)对。
itertuples(): 将DataFrame迭代为元祖。
iteritems(): 将DataFrame迭代为(列名, Series)对
其中速度最快的时.itertuples(),因此在使用的时候首先它
import pandas as pd
inp = [{'c1':10, 'c2':100}, {'c1':11, 'c2':110}, {'c1':12, 'c2':123}]
df = pd.DataFrame(inp)
for row in df.itertuples():
print(row)
print(getattr(row, 'c1'), getattr(row, 'c2'))
for index,row in df.itterrows():
print(row["c2"])
3.pandas衍生库:pandas_profiling(在之前的博客中有此介绍)
其中可以一键生成数据相关报告
import pandas_profiling
data=pd.read_csv("")
file=data.profile_report(title="")
#转化成相应的Html文件
file.to_file(output_file="result.html")
4.更快的读取pandas文件,modin库它是一个多进程的数据帧(Dataframe)库,具有与 Pandas 相同的应用程序接口(API),使用户可以加速他们的 Pandas 工作流。
import numpy as np
import modin.pandas as pd
df = pd.read_csv("my_dataset.csv")
由于modin依赖于ray,而ray目前只支持linux和mac系统, 不支持windows,所以windows还无法使用,后续可能将模型部署在服务器LINUX上可以使用到。
具体底层可自行参照官方文档!
5.关于浮点数转化为二进制代码为:
可以直接乘以某个进制再转换
求负数十六进制的公式为:
负数十六进制 = hex ( 负数 & 0xFF…FF ) (注意:几个F取决于数据类型的范围,如int数据类型取0xFFFFFFFF)
neg十六进制 = hex(-45054 & 0xFFFFFFFF) = hex(4294922242) = 0xFFFF5002
二进制补码等相关可参考:链接
python将16进制与字符串相互转换:
注释函数功能和hexlify相同
import binascii
#字符串转16进制
data = b'2.21.7644'
output = binascii.hexlify(data)
output
#将16进制数转字符串
data = '322e32312e3736343400'
output = binascii.unhexlify(data)
output
**6.**针对pandas中的Series或者某一列进行求标准差,直接df[" “].std()结果和np.std(df[” "])不一样的!其中np. 是正确的。因此在对列进行操作的时要使用第一种方法需要添加参数。
df[" "].std(ddof=0)
**7.**工作需要同时对一个DataFrame中的两列的每个元素进行操作时,运用apply时,给的参数需要是一个列表。
def test(x,y,z):
result = x + y +z
df["3"] = df[["1","2","3"]].apply(lambda x:test([x[0],x[1],x[2]]),axis=1)
**8.**如果需要对一个字符串中每2个数中加一个符号可以使用正则表达式:如果是奇数之类的需要添加判断
s="224466"
"/".join(re.findall(r".{2}",s))
9.将.py文件转换成exe文件可以使用python的Pyinstaller包:
1,先安装该包
2.通过cmd进入到.py文件的地址
3.输入pyinstaller -F *.py 就可以了
如果是一个工程项目的话,选择主文件进行main.py即可
(如果是多个py文件的话,先选择一个文件后,空格或者-p 另外一个文件即可)
打包好的exe就在目录下的dist文件夹里面
-icon=your path 加一个图标
-F 打包成一个文件
-w 无控制台运行界面
-D 创建一个目录,里面包含exe以及其他一些依赖性文件
pyinstaller -h 查看参数
当前工作中发现如果是做Pyqt5的界面程序,-F运行速度太慢,-w运行速度较快。最后封装可以封装成压缩包的形式去解压安装。
**注:**需要提到的是直接在cmd下打包,打包出来的exe文件都很大,因为是吧很多不需要的库也给安装进去了。因此可以使用在虚拟环境中通过pyinstaller打包
主要用到的库是pipenv ,在使用安装他即可
安装好之后 在cmd下运行
pipenv shell#进入虚拟环境
exit#退出环境
然后在此环境安装相应需要的包就可以了。可参考链接
Pipenv相关
虚拟环境二:使用Python直接自己创建虚拟环境打包:在CMD命令行中直接输入以下方式:
python -m venv path\虚拟环境名称
cd /d 虚拟环境目录/Scripts
activate #启动
建议使用pipenv 的方式
(1)出现"utf-8"编码错误则在命令行中先输入 chcp 65001 后运行编译
(2)如果打包遇到以下错误;
pyinstaller;No module named ‘sklearn.utils._cython_blas’:
No module named ‘sklearn.neighbors._typedefs’
等等,可选择屏蔽封装的形式。
解决方案:` pyinstaller -F -w --hidden-import=“sklearn.utils._cython_blas” --hidden-import=“sklearn.neighbors.typedefs” --hidden-import=“sklearn.neighbors.quad_tree” --hidden-import=“sklearn.tree” --hidden-import=“sklearn.tree._utils” 主文件名.py
(3)如果打包遇到以下错误;FileNotFoundError:[Errno2]No such file or directory: ‘C:\Users\24110\AppData\Local\Temp\_MEI15602\dask\dask.yaml’
[21464] Failed to execute script xxx
解决方案:在自己安装的pyinstaller库的hooks文件夹下新建一个hook-dask.py文件,在py中写入:
from PyInstaller.utils.hooks import collect_data_files
datas = collect_data_files(‘dask’)
保存即可
(4)如果打包遇到以下错误:
Unable to find "D:\anaconda3\lib\site-packages\PyQt5\Qt\translations\qtwebengine_locales" when adding binary and data files.
解决方案:原因PyQt5在高版本不再预装QtWebEngineWidgets库,安装QtWebEngineWidgets库后,重新打包。
pip install PyQtWebEngine
(5)如果打包遇到无法调用自己子代码文件可用以下方式打包:
pyinstaller main.py -F -p '对应工程路径'
10.pycharm写代码文件头
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@FILE : ${NAME}.py
@IDE : ${PRODUCT_NAME}
@license: (C)Copyright 2019-2020, teddy
@Modify Time @Author @Version @Description
-------------- ----------- ----------- -----------------
${DATE} teddy 0.1 功能
"""
第一行作用:
在windows上,第一行有没有都不会造成影响(Windows更具扩展名来判断文件类型),Linux上执行文件时是 ./test.py 的形式,所以需要加上解释器的路径信息,告知用何种方式执行这个文件。
这种是为了防止用户并不是将python装在默认的/usr/bin路径里,当系统看到这行代码时,会到env设置里查找python的安装路径,再调用对应路径下的解释器程序完成操作。
可用的预定义文件模板变量为:
${PROJECT_NAME} - 当前项目的名称。
${NAME} - 在文件创建过程中在“新建文件”对话框中指定的新文件的名称。
${USER} - 当前用户的登录名。
${DATE} - 当前的系统日期。
${TIME} - 当前系统时间。
${YEAR} - 今年。
${MONTH} - 当月。
${DAY} - 当月的当天。
${HOUR} - 目前的小时。
${MINUTE} - 当前分钟。
${PRODUCT_NAME} - 将在其中创建文件的IDE的名称。
${MONTH_NAME_SHORT} - 月份名称的前3个字母。 示例:1月,2月等
${MONTH_NAME_FULL} - 一个月的全名。 示例:1月,2月等
11.读取csv文件报错编码错误
具体原理不做详细解释,由于本地通过excel打开新建列名(中文命名)之后读取read_csv会报错编码问题,可以添加 encoding="gb2312" 但是此用法在后续合并读取文件时候,需要自己添加encoding比较麻烦。因此推荐使用
encoding=“utf-8-sig”
12.python 读取.log文件然后操作
1.需要读取.log文件(类似txt文件)操作,如果使用pandas可以直接使用read_table()读取或者使用read_csv(,sep= “\t”)既可。具体格式要求需要查看文件类数据排版格式,读取出来是一个dataframe。
2.通过with open的形式读取,读取出来是一个列表。
filename = r"C:\Users\yunda\Desktop\rtms_20191201_20803_5.log"
with open (filename,"r") as f:
data = f.readlines()
13.关于DataFrame的纵向拼接和合并
1.工作中遇到需要把多个文件合并或者是多个数据框纵向合并目前考虑有三种方法
一:通过 to_csv()的形式进行凭借。先将首文件to_csv生成一个csv文件导出,然后后续的文件通过to_csv(mode= “a”)的形式导入。
缺点:会直接合并上去,不会根据列名自动进行分列拼接
df = pd.read_csv(r"")
df1 = pd.read_csv(r"")
df.to_csv(r"test.csv")
df1.to_csv(r"test.csv",mode="a",header=False,index=False)
二:通过.append()的形式进行数据框的拼接,数据会根据列名相同自动进行拼接,并且如果某一个数据框在没有某一列的情况下,会在合并的数据框中显示NAN
df = pd.read_csv(r"")
df1 = pd.read_csv(r"")
df_all = df.append(df1)
三:通过pd.concat()的形式进行拼接,效果和append相同
df = pd.read_csv(r"")
df1 = pd.read_csv(r"")
df_all = pd.concat([df,df1])
14.关于DataFrame,Series的横向拼接和合并
一:主要使用的是pd.merge()的方法进行凭借,和Mysql里面的Join类似。
df_all = pd.merge(left,right,on = "key")
表的组合都是两两合并
但是merge多表合并:可以用reduce+merge的方法
from functools import reduce
dfs = [df0, df1, df2, dfN]
df_final = reduce(lambda left,right: pd.merge(left,right,on=‘name’), dfs)
有时计算的结果需要将其结果直接append到空数据框中,在使用append的时候需要参数ignore_index=True
result = result.append({"90%":df[df["mins"]<i]["flag"].quantile(0.9),
"95%":df[df["mins"]<i]["flag"].quantile(0.95),
"99%":df[df["mins"]<i]["flag"].quantile(0.99)},ignore_index=True)
二:也可以通过使用concat(axis=1)的形式横向拼接
pd.concat([df1,df2,df3],axis=1)
三:如果是索引相同为键时,dataframe可以使用.join
df.join(df1,lsuffix="-x")
15.DataFrame的列进行交换(重新排列的顺序)
其实方法很多而且很简单,但是很容易突然在做数据框操作时候想使用方法去套用。因此在此做提醒
方法一:
直接进行选择即可 df[[cols]] 其中cols就是你重新排列的列名
方法二:
通过.loc或者.iloc进行选择 df.iloc[:,cols] 其中cols就是你重新排列的列名
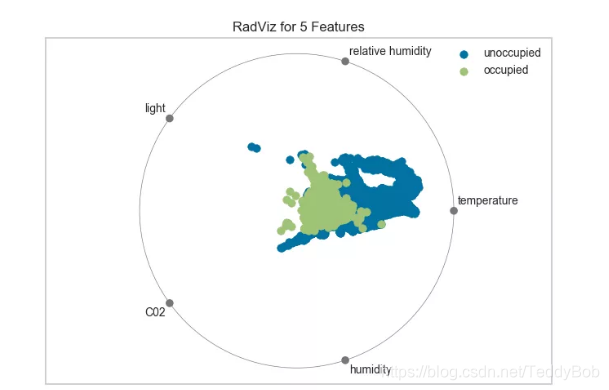
**16.机器学习特征选择工具Yellowbrick
# Load the classification data set
data = load_data("occupancy")
# Specify the features of interest and the classes of the target
features = ["temperature", "relative humidity", "light", "C02", "humidity"]
classes = ["unoccupied", "occupied"]
# Extract the instances and target
X = data[features]
y = data.occupancy
# Import the visualizer
from yellowbrick.features import RadViz
# Instantiate the visualizer
visualizer = RadViz(classes=classes, features=features)
visualizer.fit(X, y) # Fit the data to the visualizer
visualizer.transform(X) # Transform the data
visualizer.poof() # Draw/show/poof the data
17.关于调用另外一个py文件
可以直接调用使用 import .py 前提是相同文件夹内,可以使用其函数。
如果要让其脚本运行,可以使用 os.system(“python a.py”) #记得冒号啊!
18.关于read_csv(4) 报错 have mixed types. Specify dtype option on import or set low_memory=False.
这里是由于某几列中的数据类型是混合在一起的了。所以有2种方式解决。
方法一:
读取文件的时候,将某一列的类型设置好。
pd.read_csv(r"“,dtype={‘name’: ‘str’})
方法二:
读取文件时,设置参数 low_memory=False
pd.read_csv(r”",low_memory=False)
具体逻辑可以参考 链接
方法二中一旦csv文件过大,就会内存溢出;所以推荐用第1中解决方案
19.关于程序计时,以及使用global
Python中定义函数时,若想在函数内部对函数外的变量进行操作,就需要在函数内部声明其为global。
import time,datetime
startDtime = datetime.datetime.now() # 记录当前运行时间
print("Start time: " + str(startDtime))
start_time = time.time()
begin_time = time.time()
def time_count():
'''统计程序执行到此刻所耗时间'''
global start_time
print("Time elapse:%.3f s, total elapse:%.3f min" %(time.time() - start_time,(time.time() - begin_time)/60.0))
start_time = time.time()
20.关于if name ==“main”: 个人理解
当该.py文件自己单独运行的时候,会把if内外的代码都进行运行。即name后作为本身文件的名称
当该.py文件被其他程序使用Import导入的时候,其他程序中会自动运行该文件if以外的代码。即name后作为一个模块名称,比较好的是当你导入的时候if内其不会自动运行,其函数却可以调用。
21.关于Pandas读取数据优化,防止崩溃。
一.使用read_csv()的时候,如果当nrows读取行数超过800W条时,df_train占内存超过80G,在后续的步骤中涉及到切片和数据集复制时会直接崩溃,超过1200W条时会直接无法读取。首先考虑优化读取方式。
read_csv()参数:
na_values = #在读取的时候使用该参数,对数据集中的空值进行替换,比后续单独replace更快捷。
在1.中提到的chunksize= 读取数据后,分开后通过循环每次读取分块数据,再通过list拼接起来。
每次读取完一个chunk,都进行删除,释放对应内存
for chunk in pd.read_csv(path,header=None,sep=',',chunksize=200000,nrows=10000000,error_bad_lines=False,delimiter="\t",lineterminator="\n",
keep_default_na=True, na_values=na_vals):
df_tmp.append(chunk[1:])
del chunk
print("the chunk " + str(count) + " has been stored...")
count+=1
二.数据类型优化。
在读取数据的时候,可以提前对读取的数据列进行类型划定,并且相同数据类型也有大小内存之分,比如float型就有float16、float32和float64这些子类型,其分别使用了2、4、8个字节。dtype参数接受一个以列名(string型)为键字典、以Numpy类型对象为值的字典。
pd.read_csv(r" ",dtype={“age”:“np.float32”})
22.关于python调用dll程序
由于公司同事使用了C 包装dll程序,需要数据分析进行数据处理后,导入得出结果。
这里需要注意的是,dll程序的是32位和64位的需要和自己的解析器Python的位数进行对应!
主要用的库是ctypes
import ctypes
dff = ctypes.windll.LoadLibrary('E:\code\lx_code\dlltest.dll')
dff.xxx()
#目前找到了dll需要输入数组,python对应的数据结构
(ctypes.c_int16*100)(*[1,2,3])
关于其他细节可参考其他博客。
传参技巧
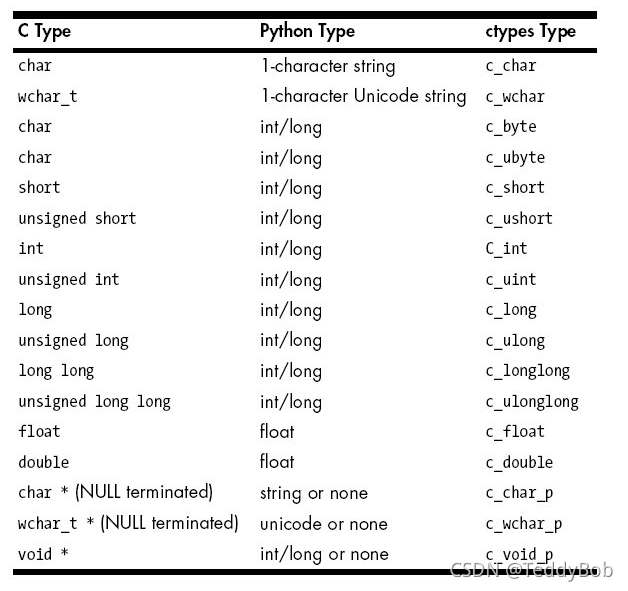
python调用C++ DLL 传参技巧
23.pandas中关于DataFrame行,列显示不完全(省略)的解决办法
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
24 pyinstaller 编译EXE编码错误解决方法
思路:编码格式问题(可直接解决问题)
1、首先尝试将中文解释都去掉
2、然后,改变控制台的编码格式为utf-8 解决方法,先在控制台中输入 chcp 65001,
然后再使用 pyinstaller -F ***.py 打包即可!
25 打包成Pyinstaller获取文件的路径的方式:
import sys
import os
print(sys.path[0])
print(sys.argv[0])
print(os.path.dirname(os.path.realpath(sys.executable)))
print(os.path.dirname(os.path.realpath(sys.argv[0])))
25. pandas直接去数据库读取数据
之前有提到过使用pymysql去连接数据库然后sql读取信息,在此有更好的方法直接读取的结果是DataFrame
具体内部参数可参考:链接
sql1 = """SELECT orgName,cx,ch FROM a_summa LIMIT 30"""
conn = pymysql.connect(host = "10.2.3.",user = "",password="",port=3306,db="inform")
df_db = pd.read_sql(sql1,conn)
也可以使用
conn = pymysql.connect(host='10.2.3.53', user='root', password='admin', database='yzd_ditie', port=3306,charset='utf8')
cur = conn.cursor()
cur.execute(sql)
conn.commit()
df = pd.DataFrame(list(cur.fetchall()),columns=list(zip(*cur.description))[0])
conn.close()
以上两者的效率差不多。
在工程可以通过以下方式读取配置文件,以面对对象的方式写连接方式:
import os
import configparser
import pymysql
import pandas as pd
class ReadConfig:
"""定义一个读取配置文件的类"""
def __init__(self, filepath=None):
if filepath:
configpath = filepath
else:
root_dir = os.path.abspath('.') # 获取配置文件的绝对路径
configpath = os.path.join(root_dir, 'config.ini') # 拼接配置文件名
self.cf = configparser.ConfigParser()
self.cf.read(configpath, encoding='utf-8-sig') # 读取配置文件
def get_param(self, param):
"""获取连接数据库的参数"""
value = self.cf.get('DATABASE', param)
return value
def get_url(self, param):
value = self.cf.get('URL', param)
return value
class MysqlDb:
"""定义一个类连接数据库"""
def __init__(self):
self.data = ReadConfig()
self.conn = None
self.cur = None
def conn_mysql(self):
"""连接数据库"""
host = self.data.get_param('host')
port = int(self.data.get_param('port'))
user = self.data.get_param('user')
passwd = self.data.get_param('passwd')
database = self.data.get_param('database')
charset = self.data.get_param('charset')
self.conn = pymysql.connect(host=host, user=user, port=port, password=passwd, database=database,
charset=charset)
self.cur = self.conn.cursor()
def execute_sql(self, sql):
"""执行操作数据库的相关sql"""
self.conn_mysql()
self.cur.execute(sql)
self.conn.commit()
def search_data(self, sql):
"""执行查询语句"""
self.conn_mysql()
self.execute_sql(sql)
return pd.DataFrame(list(self.cur.fetchall()), columns=list(zip(*self.cur.description))[0])
def close_database(self):
"""关闭数据库"""
self.conn_mysql()
self.cur.close()
self.conn.close()
2X:针对mongodb连接数据的方法和入库的方法
更多可参考:链接
链接数据库的方法以下两种:
import pymongo
#方法一:
client = pymongo.MongoClient(hoset=host,port=port,username=username,password = password,authSource="database")
all_name = client["yzd"].list_collection_names() #获取数据库内所有表名 collection_names()方法效果一样
db = client["database"]
#方法二:
client = pymongo.MongoClient("mongodb://username:password@host:port/?authSource=database")
monogo_table = myclient['database']
import pymongo
from base import base_inform as bs
class My_DataFrame():
def __init__(self):
self.base_inform, self.base_distance = bs.read_baseinform()
self.myclient = pymongo.MongoClient("mongodb://%s:%d/" % (self.base_inform['数据库ip'][0], int(self.base_inform['端口号'][0]))) # 数据库基础信息配置
self.mydb = self.myclient["yzd"] # 指定数据库
#入库
from pymongo import InsertOne
requests = []
for i in range(len(data)):
requests.append(InsertOne(dict(data.loc[i,:])))
db.bulk_write(requests)
#取数:
myclient = pymongo.MongoClient("mongodb://%s:%d/" % (df_infor['数据库ip'][0], int(df_infor['端口号'][0])))
monogo_table = myclient["yzd"]
mydb_car = monogo_table['yzd_cor_train_station_Area']
a = mydb_car.find({},{"lineCode", "direction", "stationId", "sort", "trainType", "startM"}) # 升序排列取其中
data = [doc for doc in a]
a = pd.DataFrame(data)
a = mydb_car.find({"linecode":linecode,"axle":axle,"cyTime":{"$gte":startTime,"$lt":endTime}},
{"lineCode", "direction", "stationId", "sort", "trainType", "startM"}) # $gt大于 $lt小于 $gte 大于或等于 $lte小于或等于
data = [doc for doc in a]
a = pd.DataFrame(data)
#更新:
myclient = pymongo.MongoClient("mongodb://10.2.3.35:27018/")
mydb = myclient["yzd"]
monogo_table = mydb["yzd_cor_diagnostic_conclusion_21018_202202_his"]
a = monogo_table.find({},{"effectiveAcceleration"})
a = [doc for doc in a] # 取出数据
a = pd.DataFrame(a)
a["effectiveAcceleration"] = a["effectiveAcceleration"].apply(lambda x:str(float(x)+100)) #修改数据
for index,row in a.iterrows():
condition = {'_id': row["_id"]}
result = monogo_table.find_one(condition)
result["effectiveAcceleration"] = row["effectiveAcceleration"]
monogo_table.update_one(condition, {'$set': result})#更新数据
26.pandas读取多个sheet的几种方法:
# 方法1
def read_excel(path):
df=pd.read_excel(path,None)
print(df.keys())
# for k,v in df.items():
# print(k)
# print(v)
# print(type(v))
return df
以下是自己常用的方式
df_all = pd.read_csv(path,sheet_name = None)
result = pd.DataFrame()
for name in df_all:
result = result.append(df_all[name])
# 方法2
def read_excel1(path):
data_xls = pd.ExcelFile(path)
print(data_xls.sheet_names)
data={}
for name in data_xls.sheet_names:
df=data_xls.parse(sheetname=name,header=None)
data[name]=df
# print(df)
# print(name)
return data
# 方法3
def read_excel2(path):
data_xls = pd.io.excel.ExcelFile(path)
data={}
print(data_xls.sheet_names)
for name in data_xls.sheet_names:
df=pd.read_excel(data_xls,sheetname=name,header=None)
data[name]=df
return data
方法2,和方法3 比方法1 高效。
(2)将数据保存至同一excel不同sheet中:
# 方法1,推荐方法
with pd.ExcelWriter('test.xlsx') as writer:
data.to_excel(writer, sheet_name='data')
data2.to_excel(writer, sheet_name='data2')
# 写法2
writer = pd.ExcelWriter('test.xlsx')
data.to_excel(writer, sheet_name='data')
data.to_excel(writer, sheet_name='data2')
writer.save()
writer.close()
27.通过python将数据导入mysql的方法
方法1、使用 pymysql 库, 数据一条条插入,或者用Django ORM里面的方法,数据批量插入
方法2、使用 pandas 库,一次性插入,也可批量插入
import pymysql
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:yunda@10.2.3.35:3306/inform')
result_all.to_sql('a_car_place_a', engine, if_exists='append')
方法一:
import pymysql
import pandas as pd
mysql_host = 'localhost'
mysql_db = 'test'
mysql_user = 'root'
mysql_pwd = '123456'
mysql_table = 'data_to_mysql'
class MYSQL:
def __init__(self):
# MySQL
self.MYSQL_HOST = mysql_host
self.MYSQL_DB = mysql_db
self.MYSQ_USER = mysql_user
self.MYSQL_PWD = mysql_pwd
self.connect = pymysql.connect(
host=self.MYSQL_HOST,
db=self.MYSQL_DB,
port=3306,
user=self.MYSQ_USER,
passwd=self.MYSQL_PWD,
charset='utf8',
use_unicode=False
)
print(self.connect)
self.cursor = self.connect.cursor()
def insert_mysql(self, data_json):
"""
数据插入mysql
:param data_json:
:return:
"""
sql = "insert into {}(`name`, `sex`, `age`) VALUES (%s, %s, %s)".format(mysql_table)
try:
self.cursor.execute(sql, (data_json['name'], data_json['sex'], data_json['age']))
self.connect.commit()
print('数据插入成功')
except Exception as e:
print('e= ', e)
print('数据插入错误')
def main():
mysql = MYSQL()
df = pd.DataFrame({
'name': ['戴沐白','奥斯卡','唐三','小舞','马红俊','宁荣荣','朱竹清'],
'sex': ['男', '男', '男', '女', '男', '女', '女'],
'age': [23, 22, 21, 100000, 20, 20 ,20]
})
# orient='records', 表示将DataFrame的数据转换成我想要的json格式
data_json = df.to_dict(orient='records')
for dt in data_json:
mysql.insert_mysql(dt)
if __name__ == '__main__':
方法二:
import pandas as pd
from sqlalchemy import create_engine
mysql_host = 'localhost'
mysql_db = 'test'
mysql_user = 'root'
mysql_pwd = '123456'
mysql_table = 'data_to_mysql'
def main():
engine = create_engine('mysql+pymysql://{}:{}@{}:3306/{}?charset=utf8'.format(mysql_user, mysql_pwd, mysql_host, mysql_db))
df = pd.DataFrame({
'name': ['戴沐白','奥斯卡','唐三','小舞','马红俊','宁荣荣','朱竹清'],
'sex': ['男', '男', '男', '女', '男', '女', '女'],
'age': [23, 22, 21, 100000, 20, 20 ,20]
})
# 表名
df.to_sql(mysql_table, con=engine, if_exists='append', index=False)
"""
to_sql参数:(比较重要)
if_exists:表如果存在怎么处理
append:追加
replace:删除原表,建立新表再添加
fail:什么都不干
chunksize: 默认的话是一次性导入, 给值的话是批量导入,一批次导入多少
index=False:不插入索引index
dtype 创建表结构
需要导入 import sqlalchemy
dtype = {'id': sqlalchemy.types.BigInteger(),
'name': sqlalchemy.types.String(length=20),
'sex': sqlalchemy.types.String(length=20),
'age': sqlalchemy.types.BigInteger(),
})
"""
if __name__ == '__main__':
main()
同理还有read_sql()
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
sql:SQL命令字符串
con:连接sql数据库的engine,一般可以用SQLalchemy或者pymysql之类的包建立
index_col: 选择某一列作为index
coerce_float:非常有用,将数字形式的字符串直接以float型读入
parse_dates:将某一列日期型字符串转换为datetime型数据,与pd.to_datetime函数功能类似。可以直接提供需要转换的列名以默认的日期形式转换,也可以用字典的格式提供列名和转换的日期格式,比如{column_name: format string}(format string:“%Y:%m:%H:%M:%S”)。
columns:要选取的列。一般没啥用,因为在sql命令里面一般就指定要选择的列了
chunksize:如果提供了一个整数值,那么就会返回一个generator,每次输出的行数就是提供的值的大小。
以下主要是在插入数据中,插入字符型的值时,需要在SQL内部语句也要加’’
df = pd.read_excel(r"C:\Users\yunda\Desktop\ceshi.xlsx")
conn = pymysql.connect(host="10.2.3.35",user="root",password="yunda",port=3306,db="data_test",charset='utf8')
cur = conn.cursor()
sql = "insert into a_car_place(OrgName,Cx,Ch,Place_time) values('%s','%s','%s','%s')"%("测试机务段","HXD1C","6001","2000-1-11")
cur.execute(sql)
cur.close()
conn.close()
两种链接数据库的方式:
1.用sqlalchemy构建数据库链接
import pandas as pd
import sqlalchemy
from sqlalchemy import create_engine
# 用sqlalchemy构建数据库链接engine
connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'
engine = create_engine(connect_info)
# sql 命令
sql_cmd = "SELECT * FROM table"
df = pd.read_sql(sql=sql_cmd, con=engine)
2.用DBAPI构建数据库链接
import pandas as pd
import pymysql
# sql 命令
sql_cmd = "SELECT * FROM table"
# 用DBAPI构建数据库链接engine
con = pymysql.connect(host=localhost, user=username, password=password, database=dbname, charset='utf8', use_unicode=True)
df = pd.read_sql(sql_cmd, con)
28.构建随机数据集主要使用faker包
pip install Faker
from faker import Faker
fake = Faker("zh_CN")#不填参数默认英文
fake.name() address(),phone_number(),pystr()'''随机字符串''',email(),ssn()"身份证"
29. 给df中的一个单元格给一个列表的数据。
df.loc[0,'B']=[1,2,3]
此时这样表达,python会报错。可以使用以下方式:
#方式一
df.at[0,"B"] = [1,2,3]
#方式二
df.set_value(0,"B",[1,2,3])
30. 把列表的字符串转化成列表形式:eval()
a = "[1,2,3]"
print(eval(a))
[1,2,3]
eval() 函数用来执行一个字符串表达式,并返回表达式的值
31.机器学习模型训练完成后封装成.pkl
使用sklearn中的模块joblib,核心代码就两行
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
from sklearn.externals import joblib
#方法二:使用sklearn中的模块joblib
(X,y) = datasets.load_iris(return_X_y=True)
rfc = RandomForestClassifier(n_estimators=100,max_depth=100)
rfc.fit(X,y)
print(rfc.predict(X[0:1,:]))
#save model
joblib.dump(rfc, 'saved_model/rfc.pkl')
#load model
rfc2 = joblib.load('saved_model/rfc.pkl')
print(rfc2.predict(X[0:1,:]))
32 将图片存入Mysql数据库
Mysql数据库的表中,存入图片的那列的格式为 Blob
path = r"C:\Users\yunda\Desktop\界面图片\bzlogo.jpg"
with open(path,"rb") as f:
img = f.read()
conn = pymysql.connect(host="10.2.3.35",user="root",password="yunda",db="data_test",port=3306,charset="utf8")
cur = conn.cursor()
sql = """
insert into test_pic(filename,picture) values (%s,%s);
"""
val = ("bzlogo", img)
cur.execute(sql, val)
conn.commit()
cur.close()
conn.close()
33 将时间标签转化为整型或浮点型
df["Date"] = df.apply(lambda x: time.mktime(time.strptime(x["Date"],"%Y/%m/%d %H:%M:%S")),axis=1)
34 flask部署设置app.run(host=“0.0.0.0”) 同网段无法访问
主要原因是Pycharm启动服务后,设置的端口会又默认变成“127.0.0.1”。因此方法有二:
1.通过命令行启动
python app.py
2.将自己ip地址设置成host里面的地址即可,并且运行时右键选择Run File in Console
35 不指定时间格式,直接将字符串转换为datetime格式。
dateutil.parser:为格式转换
import datetime
import dateutil.parser
def getDateTime(s):
d = dateutil.parser.parse(s)
return d
[in] time_str = "2018 9 03"
[in] getDateTime(time_str)
[out] 2018-09-03 00:00:00 <class 'datetime.datetime'>
[in] time_str = "2018-9-03 23:23:9"
[in] getDateTime(time_str)
[out] 2018-09-03 23:23:09 <class 'datetime.datetime'>
dateutil.rrule:计算出两个datetime对象间相差的年月日等时间数量
In [2]: oneday = datetime.date(1970,1,1)
In [3]: today = datetime.date.today()
In [4]: from dateutil import rrule
In [5]: days = rrule.rrule(rrule.DAILY, dtstart=oneday, until=today).count()
In [6]: days
Out[6]: 15282
In [8]: years = rrule.rrule(rrule.YEARLY, dtstart=oneday, until=today).count()
In [9]: years
Out[9]: 42
In [11]: month = rrule.rrule(rrule.MONTHLY, dtstart=oneday, until=today).count()
In [12]: month
Out[12]: 503
36 各类进制,位,编码转换
1)进制转换
hex()转化为16进制
int(“0x21”,16)16进制转换为十进制
浮点数转换为16进制
import struct
struct.pack("<f", 37.6).hex()#低端
struct.pack(">f", 37.6).hex()#高端
16进制转化为浮点数
struct.unpack('<f', bytes.fromhex(s))[0]
2)协议解析相关
struct.unpack('L',codecs.decode('e5020000' ,'hex_codec'))
struct.unpack("h",x) #此方法需要2个去拼凑
struct.unpack("h", codecs.decode(da[2 * j, i] + da[2 * j + 1, i], 'hex'))[0]) #"h"是有符号。"H"为无符号,此处不需要高低交换
struct.unpack("4096h",x) #针对振动数据4096个blob直接转
codecs.decode("ffff","hex")
#以下为16进制转浮点数
import struct
def hex_to_float(hex_str):
hex_int = int(hex_str,16)
return struct.unpack('!f',struct.pack('!I', hex_int))[0]
上述x为字节流,为有符号转换。
codecs.decode:将字符串转为字节型
struct.unpack:
struct解释
37 python读取压缩包里文件操作
names = os.listdir(path)
for name in names:
filename = path + "\\" + name
with tarfile.open(filename, 'r') as f:
for member in f.getmembers():
file = member.name
if '.cor' in file:
da = ['{:02x}'.format(c) for c in f.extractfile(member).read()]
data = np.array(da)
Bm_a.parse_Bm(data,file)
38 读取到16进制数如何转成有符号数值
方法一中,val必须是0xffff这样的格式,即字符串需要转好eval(“0xffff”)
方法二中,value已经是Int(x,16)之后的value
方法三中,用的是按位取反操作转化的,效果应该最好。st为字符串的16进制
方法一:
def get_s16(val):
if val < 0x8000:
return val
else:
return (val - 0x10000)
方法二:
def s16(value):
return -(value & 0x8000) | (value & 0x7fff)
方法三:
def isnegatve_int(st):
if ord(st[1]) > 55: # 负数
complement = ((int(st[1::], 16)^4095)+1)/16
return complement*-1
else: # 正数
return int(st[1::], 16)/16
39. Pyinstaller封装exe文件,读取模型报错(模型文件缺少模块)
出现该类问题,并不是训练好的模型封装出现问题或者是路径问题。具体暂无法定位
解决方法:现首次封装exe程序后,如若出现模型库相关错误,则双击xx.spec文件,手动在hiddenimports=【】列表中增加库名后,再次封装-F xx.spec
40.字符串转换为相应的二进制串
def encode(s):
return ' '.join([bin(ord(c)).replace('0b', '') for c in s])
def decode(s):
return ''.join([chr(i) for i in [int(b, 2) for b in s.split(' ')]])
>>>encode('hello')
'1101000 1100101 1101100 1101100 1101111'
>>>decode('1101000 1100101 1101100 1101100 1101111')
'hello'
41 忽略命令行运行程序中警告
import warnings
warnings.filterwarnings('ignore')
42. 数据库里读取blob格式的图片,通过程序读取出来显示图片(未尝试)
import psycopg2
import matplotlib.pyplot as plt
conn=psycopg2.connect(database='db',user='postgres',password='pw',host='10.120.10.11',port='5432')
cursor=conn.cursor()
cursor.execute("select gmsfhm,picture from gg_gaj_rk_picture limit 10")
data=cursor.fetchall()
conn.commit()
for i in range(len(data)):
f=open(r'C:\Users\lenovo\Desktop\piture\%s.jpg'%data[i][0],'wb')
f.write(data[i][1].tobytes())
43 python下载第三方
pip install keras -i "https://pypi.doubanio.com/simple/"
-i "https://pypi.tuna.tsinghua.edu.cn/simple"
-i "https://mirrors.aliyun.com/pypi/simple/"
43 将列表存入空单元格
原工作代码中以下形式撰写
result_rail["display_time"].loc[i, L_day + 1] = "[]"
result_rail["display_time"][L_day + 1] = result_rail["display_time"][L_day + 1].astype("object")
实际测试过程中发现.使用df[“test”][0] = [1,2,3] 不会报错,使用.loc反而不行。测试代码如下:
df_part.loc[0,"test"] = 0
df_part.loc[:,"test"] = df_part.loc[:,"test"].astype("object")
df_part["test"][0] = [1,2,3]
44 读配置文件(.ini)
新建配置文件:
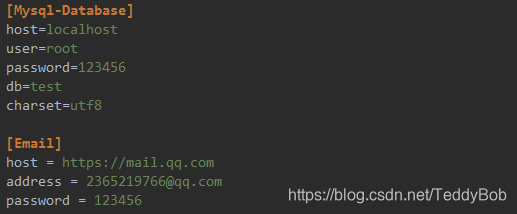
读取配置文件
import configparser
cf = configparser.ConfigParser()
cf.read("E:\Crawler\config.ini") # 读取配置文件,如果写文件的绝对路径,就可以不用os模块
secs = cf.sections() # 获取文件中所有的section(一个配置文件中可以有多个配置,如数据库相关的配置,邮箱相关的配置,
每个section由[]包裹,即[section]),并以列表的形式返回
print(secs)
options = cf.options("Mysql-Database") # 获取某个section名为Mysql-Database所对应的键
print(options)
items = cf.items("Mysql-Database") # 获取section名为Mysql-Database所对应的全部键值对
print(items)
host = cf.get("Mysql-Database", "host") # 获取[Mysql-Database]中host对应的值
print(host)
45 读取json格式文件作为配置文件
读取json格式文件
with open('./jwdandcx.json', 'rb') as load_f:
json_text = json.load(load_f)
保存json格式文件
with open('./a.txt','w') as f:
# 设置不转换成ascii json字符串首缩进
f.write( json.dumps( dict_json,ensure_ascii=False,indent=2 ) )
46 读取inf格式文件作为配置文件
读取inf格式文件
with open(r"F:xx\cl.inf","rb") as f:
data = pickle.loads(f.read())
out:
{'alpha': [1, 0.7, 0.5, 0.3, 0.1],
'sigma': [1, 1.6, 2.5, 6.5, 36],
'weight': [0.1, 0.1, 0.1],
'ideal_rul': 150,
'now_rul': 120}
写入inf格式文件
with open(r"C:\Users\yunda\Desktop\test.inf", "wb") as f:
result = pickle.dumps(data)
f.write(result)
f.close()
47 给二维及多维列表赋值
在开始创建多维列表时,不能用[[]*5],而是需要使用[[]for i in range(5)]。
因为第一种方式在进行赋值的时候相当于在同一个地址下每一个子列表都赋值了。
mm = [[] for i in range(5)]
mm[0].append(4)
48 微服务部署模型
通过flask框架部署微服务,通过请求端口的形式调用函数。封装成EXE运行即可
from threading import Thread
from flask import Flask
app = Flask(__name__)
def asynk(f):
def wrapper(*args, **kwargs):
thr = Thread(target=f, args=args, kwargs=kwargs)
thr.start()
return wrapper
@asynk
@app.route('/tttt', methods=['GET', 'POST'])
def main():
if request.method == 'POST':
result = request.get_json()
print(result)
line_decompose(result)
return {'Message': 'okk'}
else:
return '算法,你现在使用的是GET输入方式'
app.run(host='0.0.0.0', port=2222, debug=True)
49 一串数字转为时间格式
import time
time.time()#获取当前的秒时间戳
根据数字长度计算转换如果是13位需要除了1000,10位的话直接转化即可。
import time
timeNum=1566366547705#毫秒时间戳
timeTemp = float(timeNum/1000)
tupTime = time.localtime(timeTemp)
stadardTime = time.strftime("%Y-%m-%d %H:%M:%S", tupTime)
print(stadardTime)
时间格式转化为一串数字:
stadardTime = "2021/09/09 00:00:00"
mm = datetime.datetime.strptime(stadardTime,"%Y/%m/%d %H:%M:%S")
mm.timestamp() #转化为是10位数
50 ASCII码与字符的相互转换
1.输入字符转换为ASCII码输出:ord(‘字符’)
2.输入ASCII码转换为相应的字符并输出:chr(ASCII码)
in:chr(int("41",16))
out:"A"
51 格式化输出
in:"%02d"%int("09",16)
out:'09'
52 让Python代码运行更快
auto是自动判断函数参数类型
from numba import jit,autojit
@jit
def tt(x):
for i in range(x):
d = i*i
return 10
具体可参考链接
53 统计python程序运行占用内存
链接
54 to_list,to_dict 将df转换成列表和字典形式
实际工作中,对最后的结果的df需要转化成列表和字典可以直接使用此两种方法。
其中to_dict可选择参数输入
dff.to_dict("list")
out:
{'Datetime': ['2019/12/28 0:06', '2019/12/28 0:12'],
'ch': ['7075A ', '7075A'],
'cx': [101, 101],
'Temp_1': [53, 22],
'Temp_2': [3, 43],
'Temp_3': [25, 525],
'Temp_4': [20.0, 634.0],
'Temp_5': [56, 0]}
dff.to_dict()
out:
{'Datetime': {0: '2019/12/28 0:06', 1: '2019/12/28 0:12'},
'ch': {0: '7075A ', 1: '7075A'},
'cx': {0: 101, 1: 101},
'Temp_1': {0: 53, 1: 22},
'Temp_2': {0: 3, 1: 43},
'Temp_3': {0: 25, 1: 525},
'Temp_4': {0: 20.0, 1: 634.0},
'Temp_5': {0: 56, 1: 0}}
55 变量实例化赋值
对一个对象进行赋值复制的时候,如果直接给=。会把内存地址复制过去,这样修改一个变量后,所有值都会改变。
因此需要使用copy库。
import copy
station_nei = copy.copy(station)
56 python读取.mat文件
当数据集大小大于2GB的时候,Python就不能正确读取mat文件了。同时matlab也不能保存相应的文件。
import scipy.io
data = scipy.io.loadmat('matData.mat') # 读取mat文件
# print(data.keys()) # 查看mat文件中的所有变量
print(data['matrix1'])
print(data['matrix2'])
matrix1 = data['matrix1']
matrix2 = data['matrix2']
print(matrix1)
print(matrix2)
scipy.io.savemat('matData2.mat',{'matrix1':matrix1, 'matrix2':matrix2}) # 写入mat文件
实际工作中,结构体struct格式,读取方式转换如下:
import scipy.io
data = scipy.io.loadmat(r"C:\Users\Administrator\Desktop\test.mat")
mm = pd.DataFrame(data['SULTSAMPLE_left_down']["display_time2"])
nn = pd.DataFrame(data['SULTSAMPLE_left_down']["kilometer"])
result = pd.concat([nn,mm],axis=1)
result.columns = ["kil","data"]
result["kil"] = result["kil"] .apply(lambda x:x[0][0])
result["data"] = result["data"] .apply(lambda x:[i[0] for i in x])
cell格式,读取方式转换如下:
import scipy.io
data = scipy.io.loadmat(r"C:\Users\Administrator\Desktop\cell_test.mat")
pd.DataFrame(data["right_up_data"])
data_result = scipy.io.loadmat(r"C:\Users\Administrator\Desktop\460-result.mat")
data_lis = list(data_result.keys())[3:]
df_SULTSAMPLE_left_down = pd.DataFrame()
for i in range(len(data_result['SULTSAMPLE_left_down'])):
df_SULTSAMPLE_left_down = df_SULTSAMPLE_left_down.append(pd.DataFrame(data_result['SULTSAMPLE_left_down'][i]))
57 python 导报取局部最大值和最小值
使用的是argrelextrema方法,输出的是原数组的索引。
from scipy.signal import argrelextrema
x = np.array([2, 1, 2, 3, 2, 0, 1, 0])
argrelextrema(x, np.greater) #局部最大值
argrelextrema(x, np.less)#局部最小值
argrelextrema(x, lambda a,b: a>b) #匿名函数
out:(array([3, 6], dtype=int32),)
58 jupyter notebook 增加插件功能
方法一:
安装并启用jupyter_contrib_nbextensions,Jupyter Nbextensions Configurator
pip install jupyter_contrib_nbextensions
pip install jupyter_nbextensions_configurator
jupyter contrib nbextension install --user
jupyter nbextensions_configurator enable --user
方法二:
pip install jupyter_contrib_nbextensions && jupyter contrib nbextension install
59 Flask框架 新增日志功能
相关简单可直接使用代码为:
LOG_FORMAT = "%(asctime)s - %(levelname)s - %(message)s"
DATE_FORMAT = "%m/%d/%Y %H:%M:%S %p"
logging.basicConfig(filename='my.log', level=logging.DEBUG, format=LOG_FORMAT, datefmt=DATE_FORMAT)
会默认在相同文件夹生成my.log文件,txt格式。默认为a
该框架服务下会一直运行,可以放在app.run下
可以通过logging.info(“测试”),logging.warning(“”)等添加
程序框架中可用异常捕获try,except,捕捉记录。
相关链接可参考:链接
注意:在需要对日志按日期划分的时候,或者根据文件大小判断时,主要用到了 logging.handlers.TimedRotatingFileHandler方法。
但是在Falsk框架中使用,会出现原日志一直被占用的情况。方法有两种:
一:这是由于多进程造成的,可以修改原函数方法进行调用。(网上有教程,但是个人不建议使用)
二:则是在执行框架 app = Flask(name)前设置好全局变量。代码如下:
def log_config():
# 设置日志的的登记
logging.basicConfig(level=logging.DEBUG)
# 日志输出目录
# log_path = os.path.join(get_cwd(),'flask.log')
# 创建日志记录器,设置日志的保存路径和每个日志的大小和日志的总大小
isexit("./cor_log")
file_log_handler = handlers.TimedRotatingFileHandler("./cor_log/cor.log", when='D', interval=1, encoding="utf-8")
# 创建日志记录格式,日志等级,输出日志的文件名 行数 日志信息
formatter = logging.Formatter("%(levelname)s %(asctime)s [%(filename)s]: %(lineno)s - %(funcName)s - %(message)s")
# 为日志记录器设置记录格式
file_log_handler.setFormatter(formatter)
# 为全局的日志工具对象(flaks app使用的)加载日志记录器
logging.getLogger().addHandler(file_log_handler)
#方案二
# logger = logging.getLogger()
# # format = logging.Formatter('%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
# format = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s")
# isexit("./cor_log")
# rotahandler = handlers.TimedRotatingFileHandler("./cor_log/cor.log", when='D', interval=1, encoding="utf-8")
# rotahandler.setLevel(logging.INFO)
# rotahandler.setFormatter(format)
# logger.addHandler(rotahandler)
#老方案
# LOG_FORMAT = "%(asctime)s - %(levelname)s - %(message)s"
# DATE_FORMAT = "%Y/%m/%d %H:%M:%S"
# isexit("./cor_log")
# dd = str(datetime.datetime.now()).split(" ")[0]
# logging.basicConfig(filename='cor.log', level=logging.DEBUG, format=LOG_FORMAT, datefmt=DATE_FORMAT)
# logging.basicConfig(filename='./cor_log/cor.log', level=logging.DEBUG, format=LOG_FORMAT, datefmt=DATE_FORMAT)
log_config()
app = Flask(__name__)
logging.info("程序开始")#后续会成为全局变量使用存入日志。
也可参见链接
60 程序循环进度条
在进行循环时,为了更好的显示进度条。可以使用库tqdm。
其中tqdm中,参数使用:
desc:进度条前面显示
ncols:进度条长度
mininterval:刷新频率
leave:是否保留进度条,多重嵌套时,必须使用leave=False
colour :进度条颜色
from tqdm import tqdm,trange
#实例1
for i in tqdm(range(20),desc='总进度'):
for j in tqdm(range(10),desc='子进度',leave=False):
time.sleep(0.1)
#实例2
for i in trange(3, colour='pink', desc='outer loop'):
for i in trange(100, colour = 'green', desc='inner loop', leave=False):
sleep(0.01)
61 将word文档转化为pdf格式
一行代码即可实现,而且速度还很快
from docx2pdf import convert
convert(r"./test.docx")
path = r"./test.docx"
save_path = r"./test.pdf"
convert(path,save_path)
62 自动出word模板报告
该方法相关链接:链接
from docxtpl import DocxTemplate
doc = DocxTemplate(r".\test.docx")
context = {"var":"测试内容"} #文本模板中内容为{{var}}
mm = ["小","中","大"]
context = {"lis":mm}#循环内容列表,文本中为:{% for var in lis %}{{ var }}{% endfor %}
#{% for var in dict %}{{ var.key }}{% endfor %} #key为字典的键
doc.render(context)
doc.save(r".\result.docx")
63 输出结果有颜色(print)
主要有两种方式 :一种是由于终端显示颜色是用转义序列控制,因此可以通过转义序列进行表示。第二种则是调用相关库文件
from termcolor import colored
在此由于简单方便记忆主要介绍方法二:
from termcolor import colored
text = colored('Hello World', 'red','on_yellow') #第一个参数是将要输出的文本,第二个参数是设置该文本的颜色,第三个参数则是
print(text)
print(colored('%s' % 'Hello World', 'red', 'on_yellow')) #也可以通过格式化输出
64 自动解压压缩包
主要是用的是第三方库zipfile 和tarfile库。
from tarfile import TarFile
untar = TarFile(r"压缩包地址")
untar.extractall(r"输出文件地址")#tar包则会自动将所有内容解压出来
from zipfile import ZipFile
unzip = ZipFile(r"压缩包地址")
unzip.extractall(r"输出文件地址")#zip包会自动生成压缩包名的文件夹
65 通过api访问JAVA函数
工作遇到完成算法计算后,需要给JAVA函数通知,主要用的就是requests库。工作代码如下:
import requests
import json
data = {"message":"t"}
postdata = json.dumps(data,ensure_ascii=False).encode("utf-8")
res = requests.post(url,postdata)#url为Java接口
66 python 实现巴特沃斯滤波器
工作中对数据进行信号处理时,需要一个高通滤波器,python实现代码如下:
from scipy import signal
b,a = signal.butter(n,2*w/k,"highpass")#K为采样频率,W为截止频率。
data_deal = signal.filtfilt(b,a,data)
通常在滤波前对数据会进行降采样,对应代码如下:
signal.resample(data,500)#500为最后的点数
67 Linux封装python工程
工作中需要对Flask框架的算法微服务进行封装并在Linux环境下使用,因此需要封装成Linux格式使用。目前在centos7封装下的格式,也可以是Ubantu环境下使用
方式和Windows环境下类似
1.Linux环境进入超级管理员方式,到代码根目录;
2.使用Pyinstaller -F main.py进行封装即可;(如果有相应报错和windows处理方式相同)
3.到对应根目录使用 ./main进行调用即可。
并且可以关闭命令窗进行调用,主要使用nohup指令,对应可参考相关链接
当然也可以使用Docker的方式进行封装调用,目前自己仅测试安装,暂未实现调用。
可以参考此链接进行学习调用相关链接
68 随机生成一组时间序列
主要使用的pandas里面的date_range()方法:
df = pd.DataFrame(
{
"ds":pd.date_range(start="2017-01-01",periods=150,freq="D"),
"y":[10+20*np.sin(i/10) + np.random.normal() for i in range(150)]
}
)
out:
69 Python实现简单滑动平均
工作中还是比较常用滑动平均对趋势线的异常点进行消除,其中pandas自带该功能,如下所示:
window_size=7
df["moving_average"] = df["columns_name"].rolling(window=window_size).mean()
自己也可以简单写一个函数进行呈现,如下所示:
def windows_move(data,step,window):
result = []
data_len = len(data)
for i in range(0,data_len,step):
part = data[i:(i+window)]
if len(part) == window:
result.append(np.mean(part))
#result.append(np.max(part))
return result
一般滑动平均都会拟合曲线,目前常用的就是numpy库里的polyfit
import numpy as np
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([1, 3, 2, 5, 7, 11])
# 线性拟合
coefficients = np.polyfit(x, y, deg=1)
print("系数:", coefficients)
输出的 coefficients 数组可能是类似 [a, b] 的形式,其中 a 是斜率,b 是截距。在这个例子中,coefficients[0] 就是斜率,coefficients[1] 就是截距。如果你进行更高阶的多项式拟合,比如 deg=2 的二次拟合,返回的系数数组将包含三个元素,第一个是x2的系数,第二个是 x 的系数(也就是斜率),第三个是常数项(也就是截距)。
简单的滑动平均,可以更好的把异常值进行过滤掉。但是当窗口过大时,而数据又是季节性真实的值时,则会将在过渡平滑。在这其实可以用一种新方法Savitzky-Golay 滤波器
Savitzky-Golay 滤波器是一种平滑滤波器,它在平滑数据的同时尽可能保持数据的形状和特征,特别是数据的局部特征。
通过Python实现则savgol_filter 是一个在 Python 中用于平滑数据的函数,它属于 scipy.signal 模块
savgol_filter 函数的基本语法如下:
scipy.signal.savgol_filter(signal, window_length, polyorder)
signal: 输入的原始数据序列。
window_length: 窗口长度,即滤波器的窗口大小。必须是奇数。
polyorder: 多项式的阶数。通常为窗口长度的一半,但可以是其他值。
参数说明
signal: 需要平滑的数据序列。
window_length: 窗口长度,必须是奇数,且大于 polyorder。这个参数决定了滤波器的平滑程度,窗口越大,平滑效果越强,但可能会丢失更多的细节。
polyorder: 多项式的阶数,通常为 (window_length + 1) / 2。这个参数决定了滤波器的拟合程度,阶数越高,拟合越精确,但可能会引入噪声。
以下为参考代码:
假设我们有一个包含噪声的数据序列,我们可以使用 savgol_filter 来平滑这个序列:
import numpy as np
from scipy.signal import savgol_filter
# 生成示例数据
x = np.linspace(-1, 1, 100)
y = np.exp(-x**2) + np.random.normal(0, 0.1, 100)
# 应用 Savitzky-Golay 滤波器
window_length = 31
polyorder = 5
y_smooth = savgol_filter(y, window_length, polyorder)
# 绘制原始数据和平滑后的数据
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x, y, label='Original data')
plt.plot(x, y_smooth, label='Smoothed data')
plt.legend()
plt.show()
注意事项
savgol_filter 对数据的边界点处理可能不够完美,可能会在边界处产生一些不平滑的现象。
选择合适的 window_length 和 polyorder 对于获得好的平滑效果至关重要。


















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









