



第一章:引言
1.二分查找
使用二分查找时,最多需要检查log n个元素。其中log指的是log2
def find_two(list,item):
high=len(list)-1
low=0
while low <= high:
middle = int((low + high) / 2)
guess = list[middle]
if guess<item:
low=middle+1
if guess>item:
high=middle-1
if guess==item:
return middle
return None
if __name__=="__main__":
a=[1,2,3,4,5,6,7,8,9,10]
print(find_two(a,-2))
2.大O表示法
大O表示法指的并非以秒为单位的速度。大O表示法让你能够比较操作数,它指出了算法运行时间的增速。
大O 表示法指出了最糟情况下的运行时间。
3.一些常见的大O 运行时间

算法的速度指的并非时间,而是操作数的增速。
谈论算法的速度时,我们说的是随着输入的增加,其运行时间将以什么样的速度增加。
算法的运行时间用大O表示法表示。
O(log n)比O(n)快,当需要搜索的元素越多时,前者比后者快得越多。
小结:
二分查找的速度比简单查找快得多。
O(log n)比O(n)快。需要搜索的元素越多,前者比后者就快得越多。
算法运行时间并不以秒为单位。
算法运行时间是从其增速的角度度量的。
算法运行时间用大O表示法表示。
第二章:选择排序
数组和链表:
个人理解:
数组是必须连在一起存放在几个地址中,一般要多预留内存地址给他以便增加元素,但是读取的话可以直接读取最后一个元素。
链表中每个元素都可以放在内存任何一个位置,下一个元素的地址存放在上一个元素的信息中,可以占用更少的内存,但是如果需要读取最后一个元素的话就比较慢。
常见的数组和链表操作的运行时间:
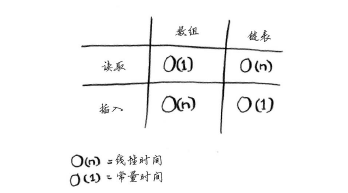
链表比数组插入快,读取单个元素数组读取比链表快。
在中间位置插入数据的话,链表会更快!删除元素,也选择链表
常见数组和链表操作的运行时间:
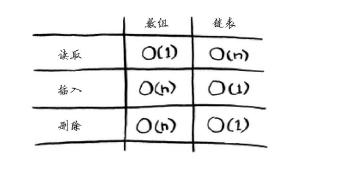
仅当能够立即访问要删除的元素时,删除操作的运行时间才为O(1)。通常我们都记录了链表的第一个元素和最后一个元素,因此删除这些元素时运行时间为O(1)。
常用数组还是链表?
数组用得很多,因为它支持随机访问。有两种访问方式:随机访问和顺序访问。顺序访问意味着从第一个元素开始逐个地读取元素。链表只能顺序访问:要读取链表的第十个元素,得先读取前九个元素,并沿链接找到第十个元素。随机访问意味着可直接跳到第十个元素。本书经常说数组的读取速度更快,这是因为它们支持随机访问。很多情况都要求能够随机访问,因此数组用得很多。
选择排序:
选择排序是一种灵巧的算法,但其速度不是很快,运行时间是O(n²)。快速排序是一种更快的排序算法,其运行
时间为O(n log n)
小结:
计算机内存犹如一大堆抽屉。
需要存储多个元素时,可使用数组或链表。
数组的元素都在一起。
链表的元素是分开的,其中每个元素都存储了下一个元素的地址。
数组的读取速度很快。
链表的插入和删除速度很快。
在同一个数组中,所有元素的类型都必须相同(都为int、double等)。
https://www.cnblogs.com/qingyunzong/p/8888080.html

















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









