




 本文介绍了如何使用Databricks的免费社区版进行Spark学习和实验。Databricks是由Spark创建者开发的统一分析平台,支持Scala、Python和R。文章详细讲解了注册、配置环境、创建集群以及进行Spark SQL实验的步骤,展示了其在数据处理和可视化方面的便利性,适合初学者使用。
本文介绍了如何使用Databricks的免费社区版进行Spark学习和实验。Databricks是由Spark创建者开发的统一分析平台,支持Scala、Python和R。文章详细讲解了注册、配置环境、创建集群以及进行Spark SQL实验的步骤,展示了其在数据处理和可视化方面的便利性,适合初学者使用。
本文始发于个人公众号:TechFlow,原创不易,求个关注
今天是spark专题的第六篇文章,这篇文章会介绍一个免费的spark平台,我们可以基于这个平台做一些学习实验。
databricks
今天要介绍的平台叫做databricks,它是spark的创建者开发的统一分析平台。单凭spark创建者这几个字大家应该就能体会到其中的分量,其中集成了Scala、Python和R语言的环境,可以让我们在线开发调用云端的spark集群进行计算。
最最关键的是,它提供免费的社区版本,每个开发者都可以获得15GB内存的免费运行环境。非常适合我们初学者进行学习。
说来惭愧我也是最近才知道这么一个平台(感谢sqd大佬的分享),不然的话也不用在本地配置spark的环境了。下面简单介绍一下databricks的配置过程,我不确定是否需要梯子,目测应该可以正常访问。有知道的小伙伴可以在留言板里评论一下。
首先,我们访问:https://community.cloud.databricks.com/
然后点击注册按钮,创建新用户:
跳转之后会让我们填写一些个人的基本信息,比如姓名、公司名称、工作邮箱还有使用这个平台的目的,等等。
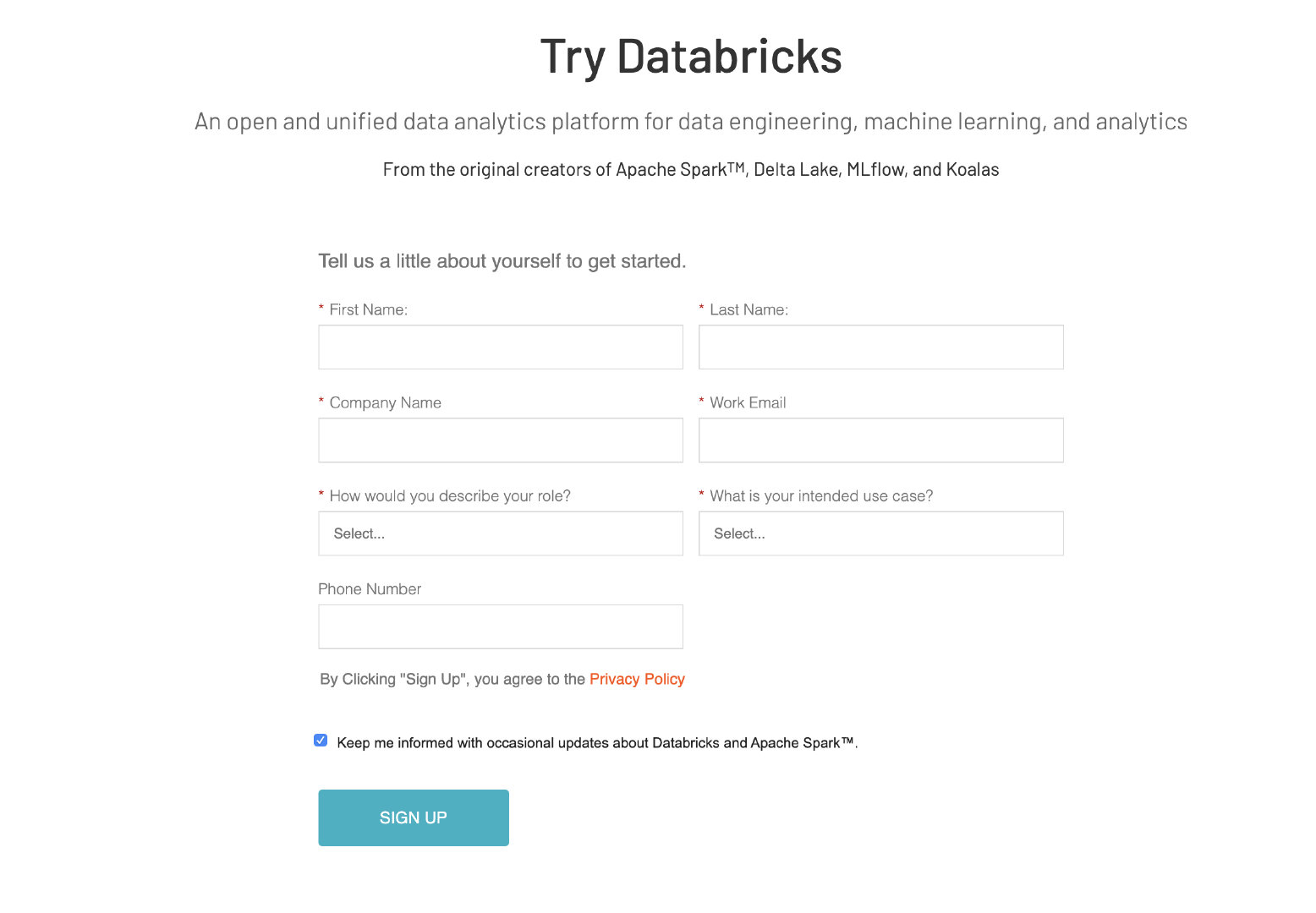
我实际验证过,这里的公司没有校验,应该可以随意填写,比如你可以填tencent或者是alibaba都是可以的。工作邮箱我们可以留qq邮箱,并不会做公司邮箱后缀校验,所以学生党们可以不用担心,假装自己在某家心仪的公司就可以了。然后选一下目的这个也都很简单大家自由选择,选好了之后,我们点击sign up就好了。
这里说明一下,如果留qq邮箱的话验证邮件会被qq当做垃圾邮件放入垃圾箱,所以记得去垃圾箱里查看。然后我们点击邮件中的链接设置密码就完成了。
配置环境
注册好了之后,我们就可以进行愉快地使用了。首先我们创建一个新的集群,点击菜单栏左侧的clusters然后选择一下spark的版本填一下集群的名称即可。
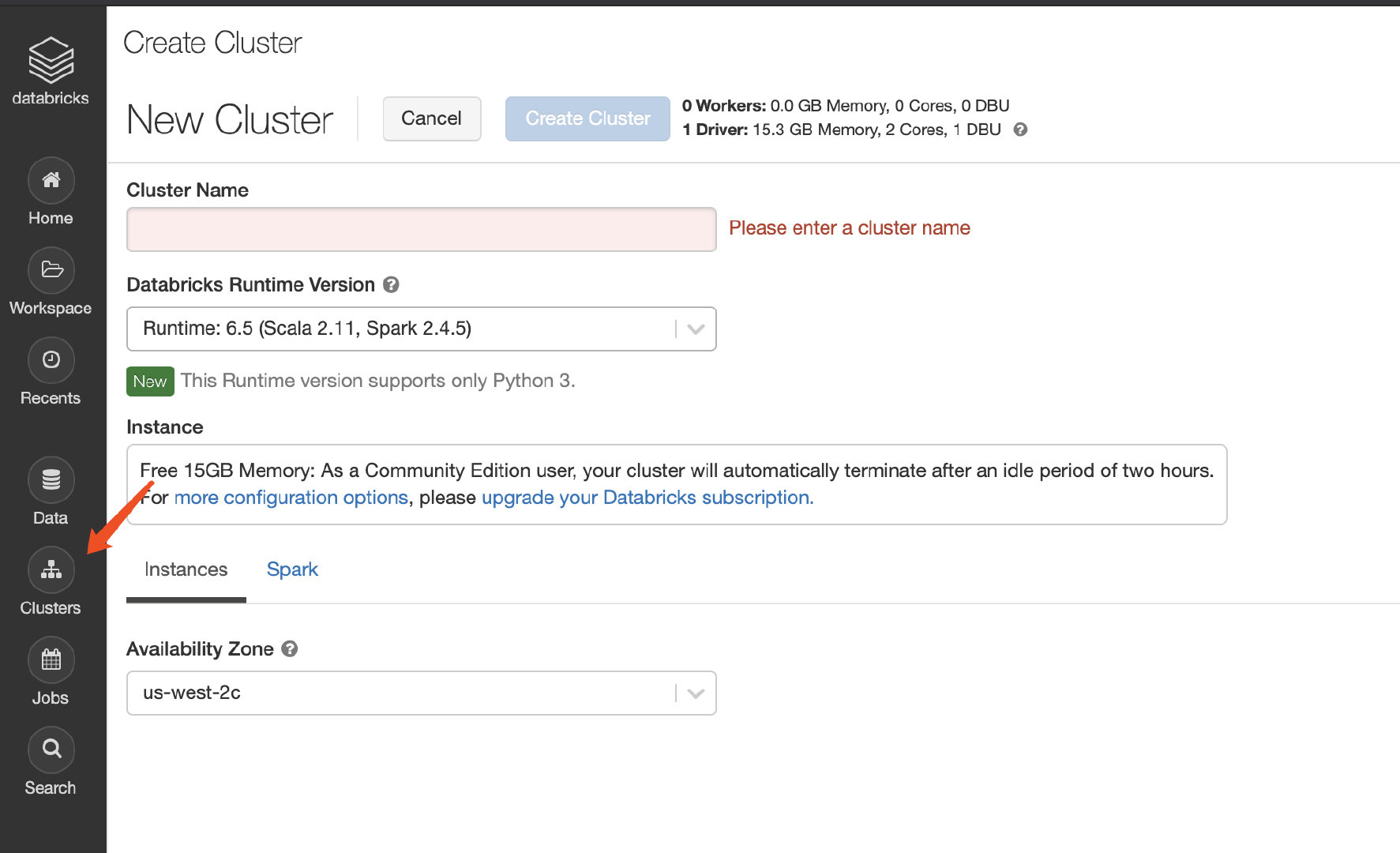
spark的版本可以不用更改,填好名字之后点击create cluster即可。系统有一点点慢,稍微等一会再刷新就会发现列表当中多了一个集群。集群的启动需要一点时间,我们耐心等待即可。

等集群创建好了之后, 我们就可以创建notebook进行愉快地编码了。
我们点击home然后选择自己的账号,点击create notebook。
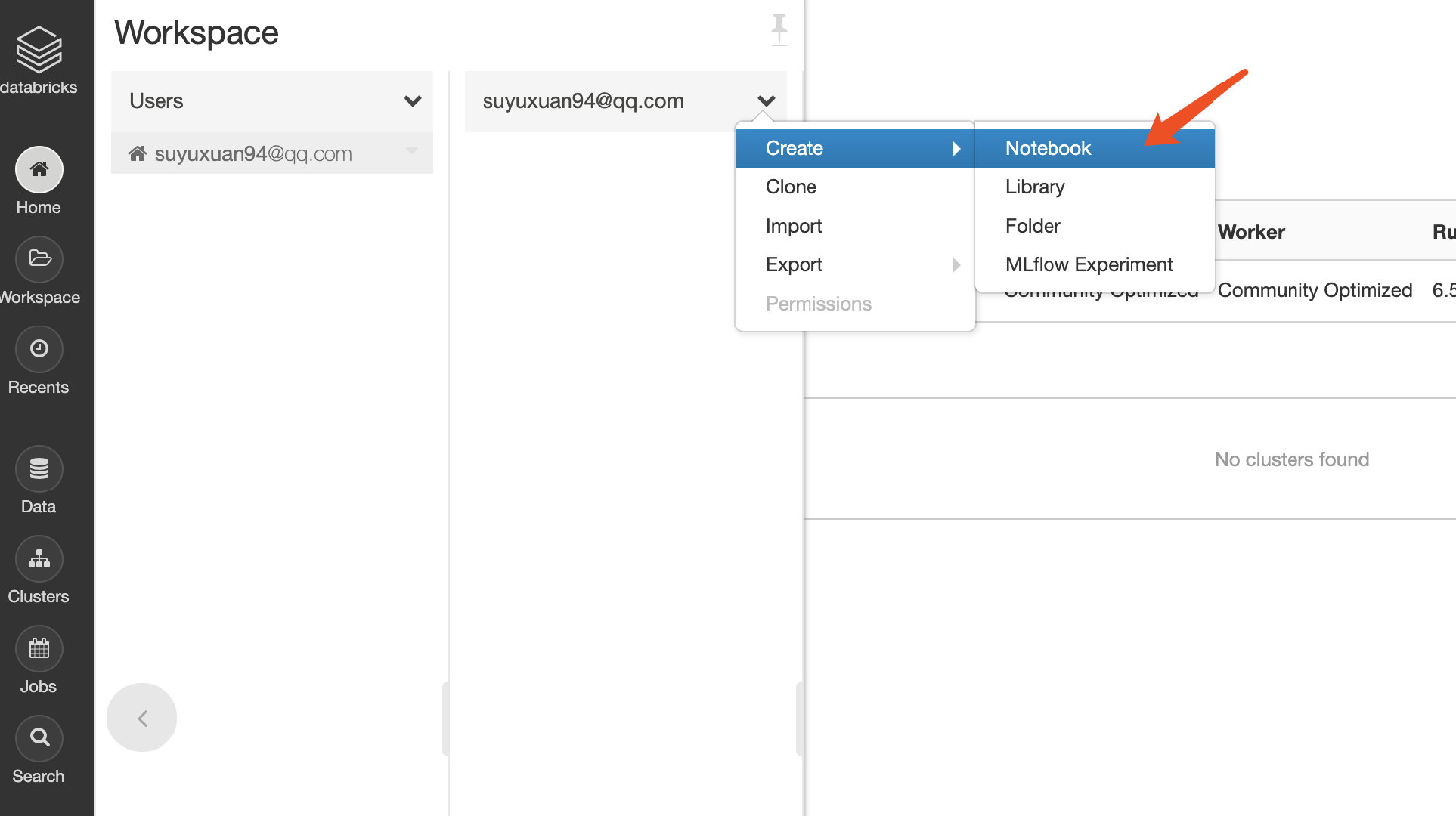
接着会有一个弹框让我们选择语言和集群,这里的语言我们选Python,如果你喜欢也可以换成Scala。集群就选择我们刚才创建的test集群。
我们点击create之后就会自动打开一个notebook的页面,我们就可以在里面编码了。为了测试一下环境,我们输入sc,看一下是否会获得sparkContext。
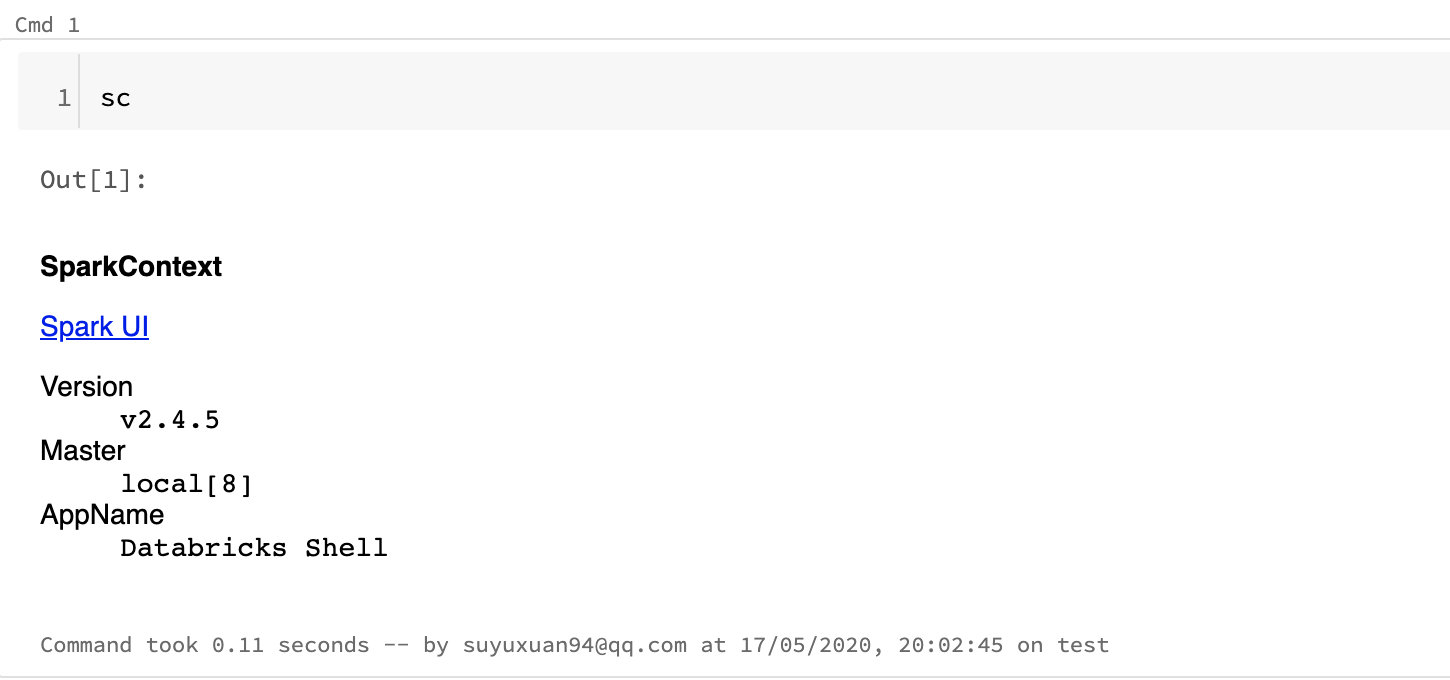
结果和我们预期一致,说明已经配置好了。以后我们就可以在这个集群当中愉快地玩耍和实验了。它除了自带很多给初学者进行学习的数据集之外,还允许我们自己上传文件,可以说是非常良心了。
实验
接下来我们利用这个平台来进行一个spark sql的小实验,来实际体会一下databricks和spark sql的强大。
我们这个实验用到的数据是databricks自带的数据集,一共用到两份数据,分别是机场信息的数据以及航班延误的数据。我们要做的事情很简单,就是将这两份数据join在一起,然后观察一下每一个机场延误的情况。这份数据当中只有美国,所以对我们大多数人没什么价值,仅仅当做学习而已。
首先,我们通过相对路径从databricks的数据集当中获取我们需要的这两份数据:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5228
5228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









