




一、项目背景
1、背景需求
1、背景需求
项目描述:公司智能工厂产品中一个智慧运输项目,还有设备全生命管理、能源分析、智能楼宇,
开发前期是一个工厂园区的定制项目,为根据国家政策,补助实现工业数字化转型, 他们全国有好几个工业园,每个园区都比较大,园区除他们自己的工厂外,还有其他同行业其他小厂。他们准备自己维护设备管理、物业管理、车辆管理等。
这个项目的需求:
主要是开发一个的用户付费运输货物,自己维护园区中货物转送管理与收益,相当于外面货拉拉业务有自己专门的小程序。
我们主要负责技术实现:
1)用户叫车下订单运输后,后台可实时监控车辆位置,同时会进行相关用户/订单/车辆的统计分析,类似货拉拉。
2)为实现用户车辆订单的分析做好基础,把业务库中四个表同步到hbase表。 不在业务库上分析,不能影响正常业务,我们解耦数据,
3)利用sparkSQL对hbase中几个业务表进行统计分析。
————————————————
实现流程:
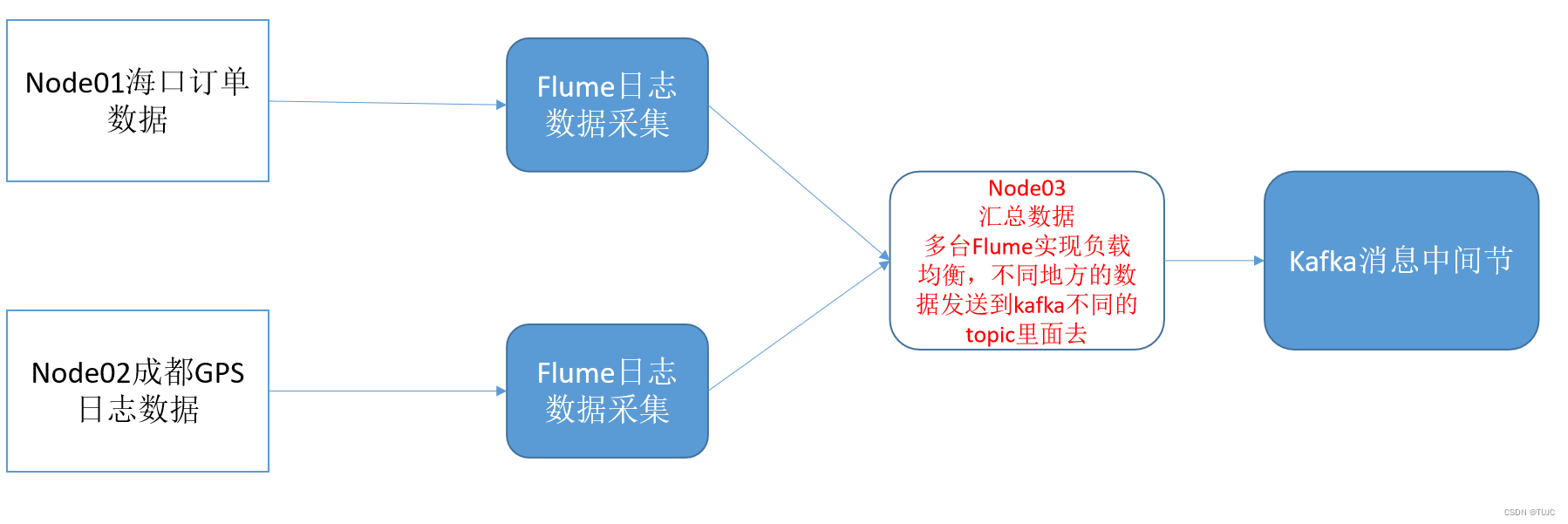
- 轨迹日志数据与订单日志数据,不在一个服务器上。通过两个flume组件采集日志,第三个flume合并数据发送到kafka不同主题;
- spark Stream,采集kafka日志流数据,存到Redis中,进行轨迹监控;存入hbase中,进行持久化操作。
- 同时,消费kafka数据时,自主维护offset,避免宕机后轨迹的重复以及断裂。
- 实时订单ID, sadd 命令,放入集合(Set)中
- GPS信息, Lpush 命令,顺序插入列表(List)头部。
2、数据源描述
用户 一下订单,系统就会有生成订单日志。包括,订单ID、城市ID、订单类型、起终点经纬度 、出行品类、乘车人数的订单属性数据。
运输过程中:司机端APP,每隔一定时间(3秒)上报日志数据。包括,司机ID、订单ID、时间戳、经度、纬度
1)轨迹数据格式说明:一共5个字段
司机ID、订单ID、时间戳、经度、纬度
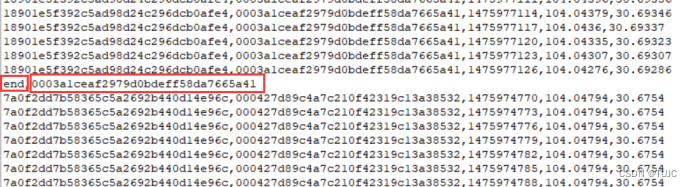
可以看出,时间不是按照递增的方式进行排列,在进行数据处理时需要先对数据按照时间进行升序排列(轨迹点的产生的时间是递增的,排序后便于在地图上进行轨迹的呈现.
2)订单数据格式说明:一共24个字段
订单ID、城市ID、订单类型、起终点经纬度 、出行品类、乘车人数的订单属性数据。
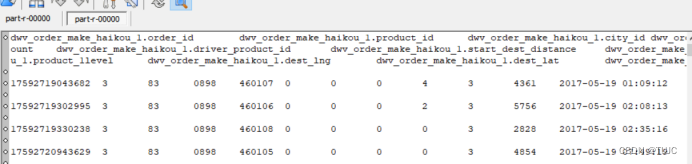
3、项目框架
zk + hadoop + hbase + flume +kafka +redis
-
1)flume:日志数据采集,使用avro source avro sink kafkaSink
-
2)Kafka:对数据进行分区,保证同一个订单的数据跑到kafka的同一个分区里面去
-
3)sparkStreaming:自主维护offset消费kafka数据,sink数据到hbase与Redis
-
4)hbase:存储轨迹数据==> 应该需要对hbase的表做预分区
-
5)Redis:使用list集合做队列的操作 ,还有set集合对订单进行去重
4、项目流程
- flume采集我们的日志数据,然后将数据放入到kafka当中去,
- sparkStreaming消费我们的kafka当中的数据,处理数据, 保存到订单数据到hbase, 轨迹数据到redis当中去
- 前端根据redis中数据,进行规则监测
二、flume采集日志数据
1、node01 采集订单日志
cd /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/
vim flume_client.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 1、配置source
a1.sources.r1.type = taildir
a1.sources.r1.positionFile =/kkb/datas/flume_temp/flume_posit/haikou.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /kkb/datas/destfile/part.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1
## 1.2、sources的拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器功能:往采集到的数据的header中,插入自己定义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = hai_kou_gps_topic
# 2、配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/datas/flume_temp/flume_check
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/datas/flume_temp/flume_cache
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
# 3、配置sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node03
a1.sinks.k1.port = 41414
2、node02采集轨迹日志
cd /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/
vim flume_client.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 1、配置source
a1.sources.r1.type = taildir
a1.sources.r1.positionFile = /kkb/datas/flume_temp/flume_posit/chengdu.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /kkb/datas/destfile/part.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1
## 1.2、sources的拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = cheng_du_gps_topic
# 2、配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/datas/flume_temp/flume_check
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/datas/flume_temp/flume_cache
a1.sources.r1.channels = c1
# 3、配置sink
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node03
a1.sinks.k1.port = 41414
3、node03汇总发送到kafka
cd /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/
vim flume2kafka.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 1、定义source
a1.sources.r1.type = avro
a1.sources.r1.bind = node03
a1.sources.r1.port =41414
# 1.2 添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
# 2、配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/datas/flume_temp/flume_check
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/datas/flume_temp/flume_cache
# 3、配置sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#flume监听的文件数据发送到此kafka的主题当中
a1.sinks.k1.topic = %{type}
a1.sinks.k1.brokerList= node01:9092,node02:9092,node03:9092
a1.sinks.k1.batchSize = 20
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.producer.linger.ms = 1
#组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
三、sparkStreaming消费kafka,自主维护offset,sink到Hbase与redis
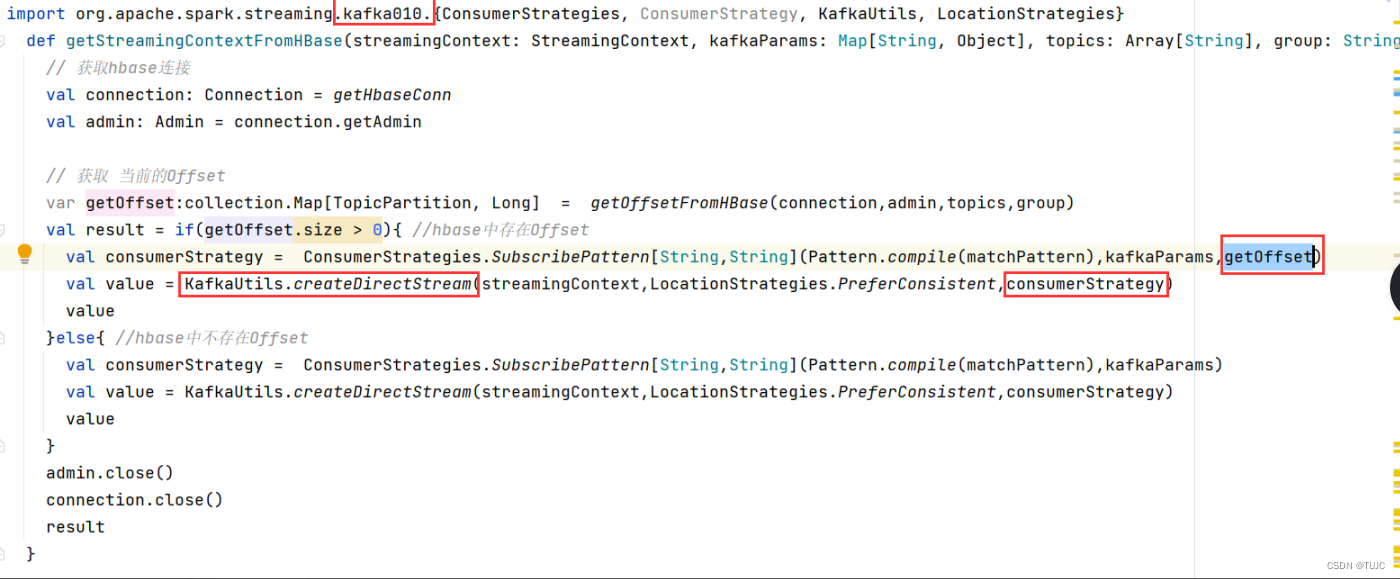
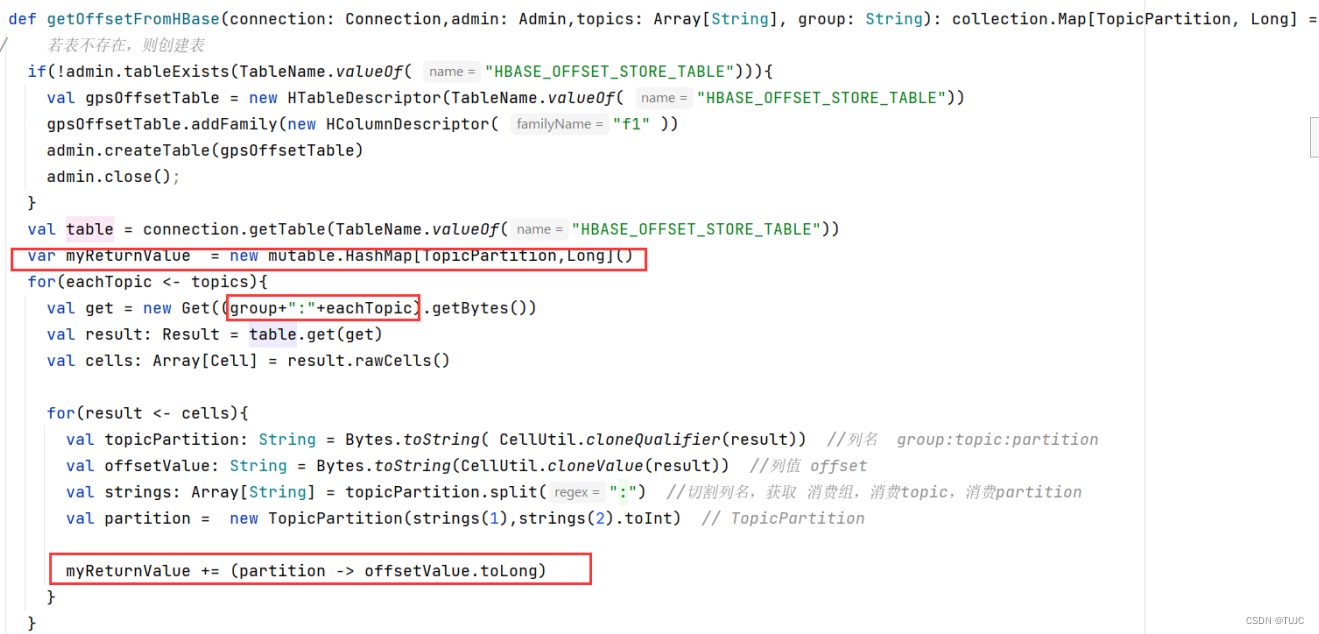
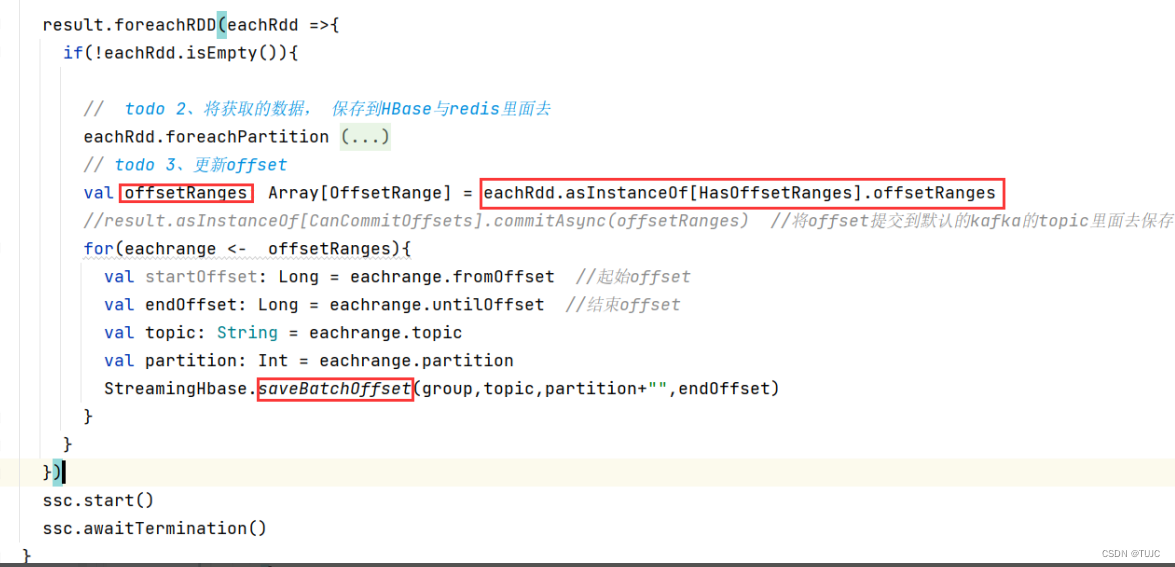
1、消费kafka,自主维护offset到hbase
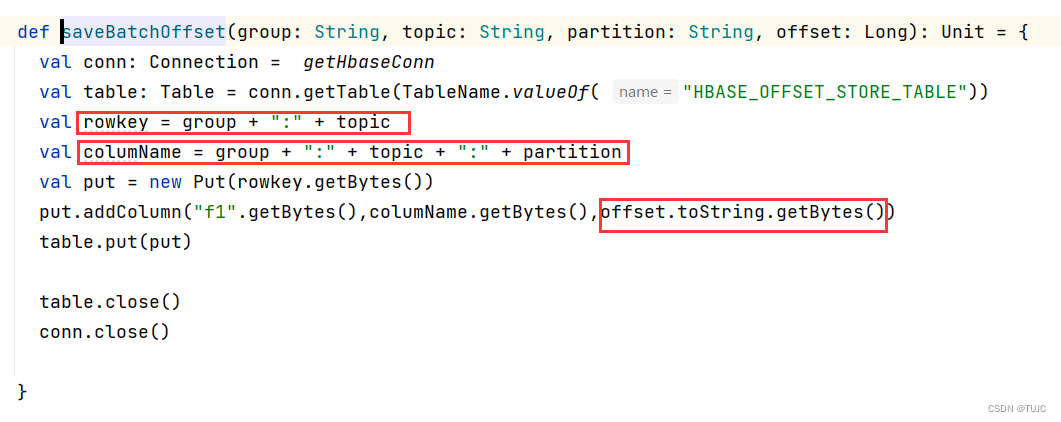
| 列族cf:f1 | |
|---|---|
| 列:group+topic+partion | |
| rowkey:group+topic | offset |
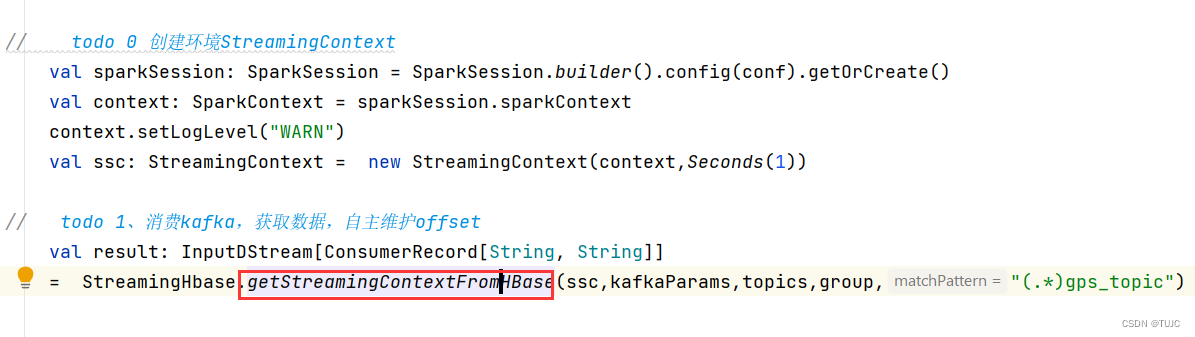
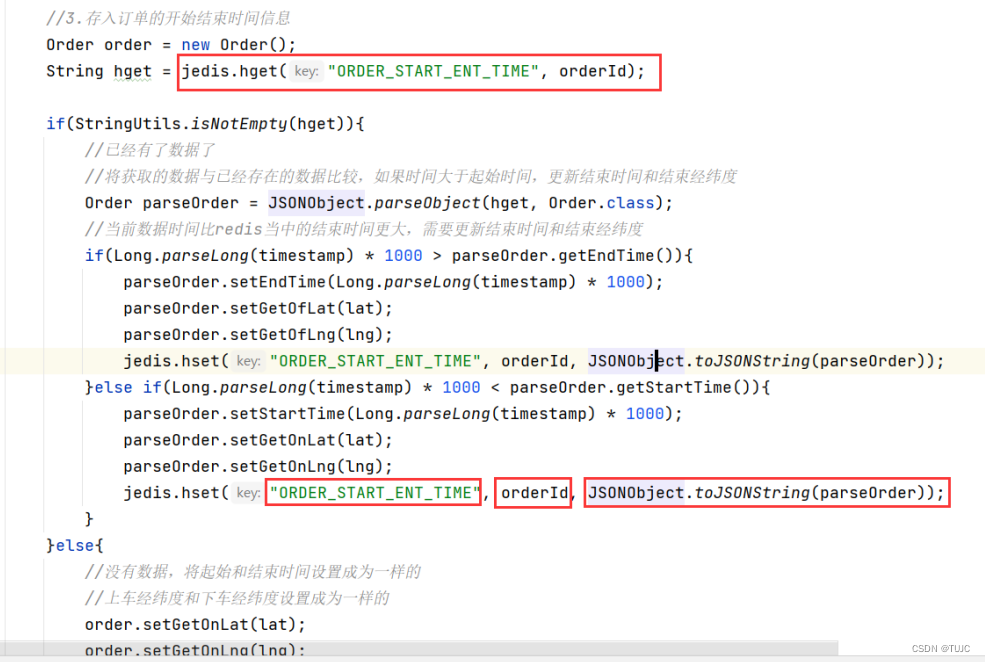
2、将获取的数据, 保存到HBase与redis里面去
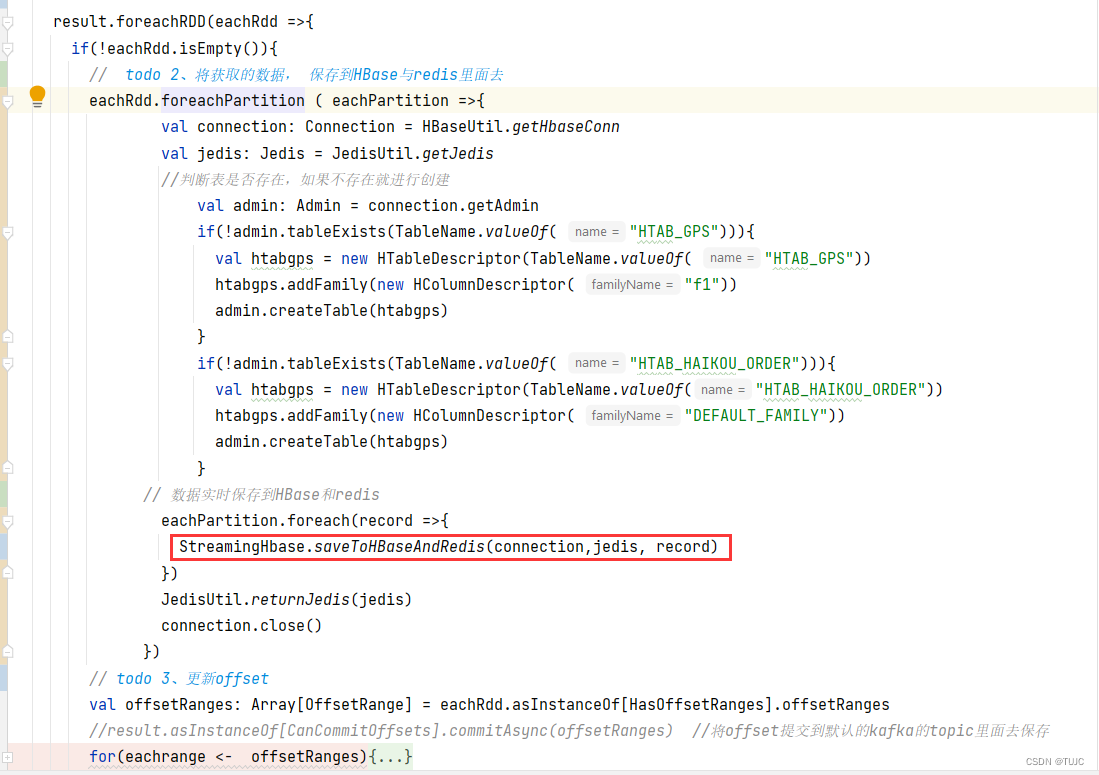
1)轨迹数据保存

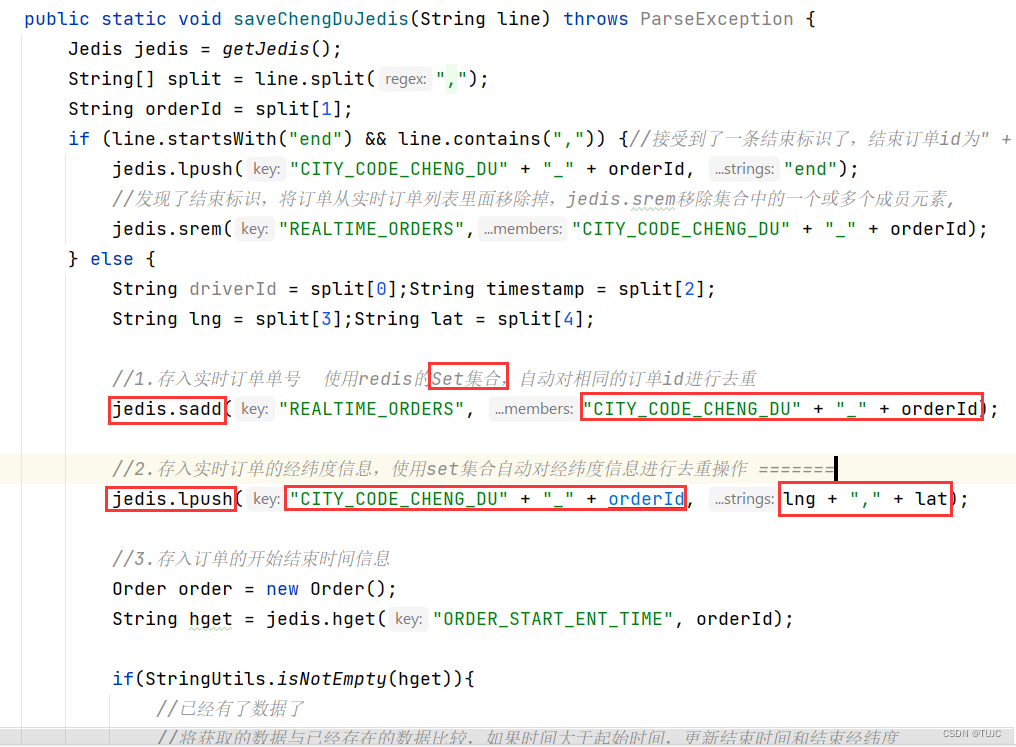
- Srem 命令,用于移除集合中的一个或多个成员元素,不存在的成员元素会被忽略。
- Sadd 命,令将一个或多个成员元素加入到集合中,已经存在于集合的成员元素将被忽略。
- Lpush 命令,将一个或多个值插入到列表头部。
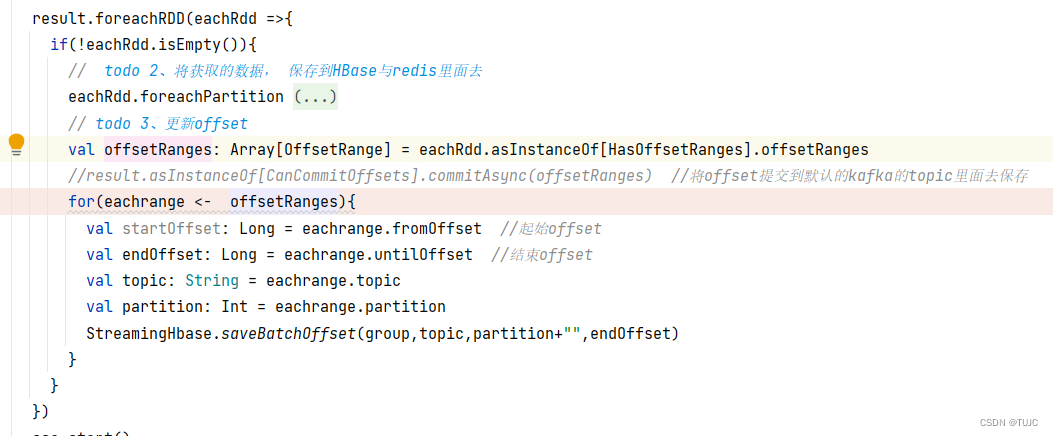
3、更新offset
四、项目问题与经验
1、mapPartitions 以及foreachPartition
-
mapPartitions =>获取的是多个分区的数据 => 涉及到序列化 => 涉及到数据的拷贝
-
foreachPartition=> 严格只拿一个分区的数据
foreachRDD ==> transformation 1 action 2
使用了foreachRdd 转成rdd 之后,比如窗口函数类型的算子应该都不能使用了吧,正确的,那用foreachrdd 这个解决方案是不是有些问题呢
phoenix怎么整合的? SSM的程序 M ==> mybatis phoenix类似的,只需要配置连接池即可
2、 Flume到kafka的乱序
使用flume采集gps的数据到kafka里面去,消费kafka里面的数据
每一条经纬度信息都是带有时间点的,前台页面获取数据,需不需要按照时间点进行先后的获取,一个订单一个分区,不会导致分区太多了吗?
不会,就9个分区,但是一定要保证相同的订单的数据,到了同一个分区里面去了
一百万条订单,9个分区,相同订单跑到同一个分区 里面去就行了
同一订单一个分区 ==> 正解
3、数据延迟上报,导致 数据乱序
如果数据延迟:第三十条数据来了,第一条数据还没来? 可以通过插入redis的时候,比较数据的时间戳
4、自主维护offset
自主维护offset,数据更可靠,实现exactly once的语义。每次消费kafka时,先去获取hbase当中维护的offset,如果没有取到,第一次消费数据;如果取到了第二次及以后消费数据;消费完成的数据,还需要维护offset 。
为啥offset要存到Hbase而不存在broker里。存在broker里面也可以,如果我可以自己控制offset的提交,可以实现每次处理一条数据,提交一次offset,只不过速度比较慢。
sparkStreaming消费kafka的数据,关键点就是维护offset值,维护kafka的offset到hbase里面去。(高频刷新,对zk压力不小,而且写性能不太够,你会发现zk刷一次offset就要1s 很正常,实际工作当中,尽量不要将offset维护到zk里面去,可以维护到redis,或者hbase等等都可以)


















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









