



Meta与哈佛大学联合推出的Confucius Code Agent(孔子代码智能体,简称CCA)工业级软件工程师。

软件工程的未来不在于更强的模型,而在于更聪明的架构设计与记忆管理。
CCA是一套关于AI如何像人类工程师一样在庞大、复杂的工业级代码库中协作的完整方法论。
通过模仿人类的认知习惯,解决了长上下文推理、持久化记忆以及工具使用等根本性难题。
工业级代码仓库是AI的试金石
大语言模型在写代码这件事上已经展现出了惊人的天赋。
从最开始简单的代码补全,到后来能解决LeetCode级别的算法题,再到最近能在GitHub开源项目中修修补补,进步肉眼可见。但从玩具级Demo到工业级实战存在一个巨大的鸿沟。
在开源社区或者学术Benchmark(基准测试)中,AI面对的往往是隔离良好的环境、清晰的需求和有限的文件依赖。
然而,当你把AI扔进Google或Meta这种级别的单体仓库(Monorepo)时,情况完全不同。
这里有数以亿计的代码行、盘根错节的依赖关系、跨越数个模块的长链路逻辑,以及极其漫长的调试周期。
现有的开源Agent在这种环境下要么因为上下文窗口爆炸而死机,要么在漫长的多轮对话中失忆,忘了自己最开始是要干什么。
而闭源的商业产品如Cursor或Claude Code虽然好用,但它们是黑盒子,企业无法掌控数据安全,开发者也无法根据自己的特殊技术栈进行定制。
CCA是一个基于Confucius SDK(孔子软件开发工具包)构建的复杂系统。它证明了:在相同的模型基座下,优秀的架构设计可以让AI的工程能力实现质的飞跃。
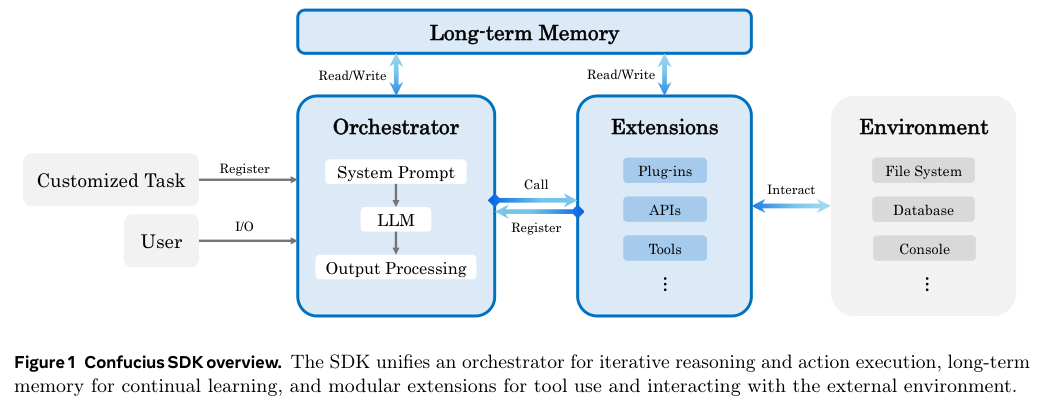
大多数Agent框架在设计时往往只盯着一个目标:怎么让模型把任务做完。
这导致了很多问题,比如为了让开发者看懂日志,把大量的冗余信息塞给了模型,干扰了它的判断;或者为了让模型跑得快,牺牲了人类的可解释性。
Confucius SDK提出了一套非常清晰的三维设计哲学,将Agent体验(AX)、用户体验(UX)和开发者体验(DX)彻底解耦。
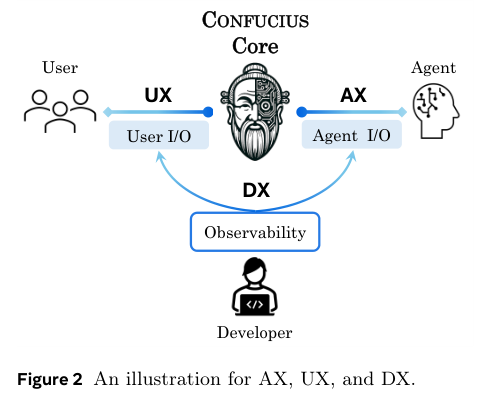
Agent Experience(AX):给模型一个干净的认知空间。
AX关注的是智能体内部的大脑如何工作。模型需要的信息必须是结构化、高信噪比的。
人类看重的大段文字描述、漂亮的UI界面、繁琐的Git Diff(差异对比)细节,对模型来说可能是噪音。
Confucius在AX层面做了大量减法,它通过自适应的摘要和结构化的记忆,确保模型只看到它需要看到的核心逻辑。
User Experience(UX):让人类看到想看的东西。
UX关注的是作为使用者的人类如何感知Agent。通过流式更新、清晰的工件预览,让人类建立信任。
这里有一个非常精妙的分离设计:人类看到的界面可以是图文并茂、细节满满的实时战报,而这背后传递给模型的数据却是高度压缩的。
Developer Experience (DX):给构建者一把手术刀。
DX是关于如何制造和修缮Agent的体验。对于那些试图改进Agent的开发者来说,他们需要看到大脑(AX)和外表(UX)之间发生了什么。
Confucius提供了深度的可观测性,让开发者能像调试代码一样调试Agent的思维过程,能够随意插拔工具、替换模块,而不需要重写整个循环。
这种三维解耦的设计,解决了一个长期困扰业界的矛盾:如何既让人类觉得好用,又让模型觉得好懂。 答案是:别让它们看同一份数据。
举个具体的例子,当Agent修改了一个文件时:
UX(用户看): 屏幕上显示正在修改config.py...,紧接着展示详细的代码Diff,比如新增了PORT=8080,把DEBUG设为了true。
AX(模型看): 模型接收到的并不是那一大串Diff文本,而是一个压缩后的结构化信号:Action: file_edit, Status: Success。

这种信息流的分离,极大地节省了宝贵的上下文窗口,让模型能把脑力用在刀刃上。
记忆的艺术:从短期工作台到长期笔记
在长时间的软件工程任务中,最大的敌人是遗忘。
传统的做法是把所有历史对话塞进Context Window(上下文窗口),或者用RAG(检索增强生成)做简单的切片检索。
Confucius SDK引入了两层更为精细的记忆机制,分别对应人类的工作记忆和长期记忆。
面对超长的执行轨迹,Confucius并没有选择简单的截断旧信息。它设计了一套分层工作记忆(Hierarchical Working Memory)。
想象一下,你在解决一个复杂的Bug。你会先看整体架构(高层),然后进入某个模块(中层),最后修改具体的函数(底层)。
当你修完这个函数退出时,你不需要一直记着函数里的每一行变量名,你只需要记住这个函数修好了,输入输出没问题这个结论。
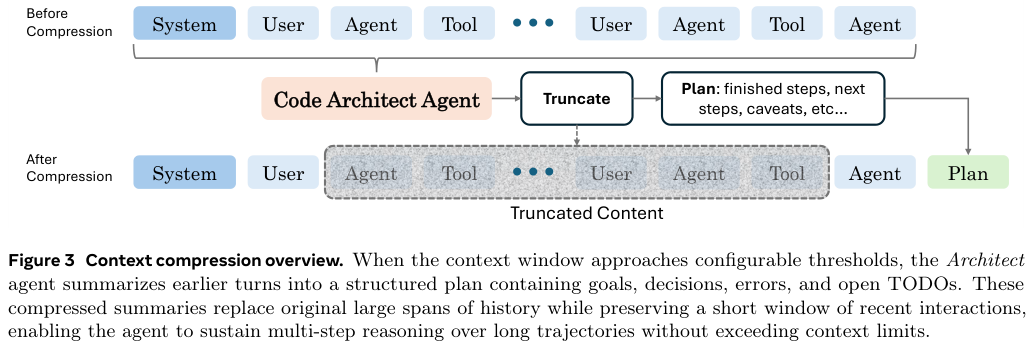
Confucius正是这样做的。它引入了一个名为Architect(架构师)的规划Agent。
当对话历史过长时,这个Architect就会被唤醒。它会审视之前的操作记录,把那些已经完成的步骤、尝试过的错误路径、得到的重要结论,提炼成一份结构化的摘要。
这个摘要会替换掉原始的冗长记录。原本几千个Token(词元)的代码调试过程,被压缩成几句话:尝试了方法A,失败,原因是依赖冲突;切换到方法B,成功。
这样一来,Agent始终保持着清醒的头脑,它知道我在哪、我要去哪、我之前试过什么,而不会被海量的细节淹没。
这就像人类工程师在做复杂项目时,会定期停下来整理思路,把无关的草稿纸扔掉,只保留核心笔记。
如果说工作记忆解决了当下的问题,那么Note-Taking(笔记)模块则解决了成长的问题。
普通的Agent每次启动都是一张白纸,哪怕它昨天刚在一个类似的Bug上摔过跟头,今天还得重摔一次。
Confucius SDK包含了一个专门的笔记Agent。这个Agent不参与具体的写代码工作,它像一个默默观察的记录员,在后台分析主Agent的操作轨迹。
它会生成Markdown格式的笔记,并以文件系统的形式存储下来(例如存放在research/findings.md或solutions/bug_fix.md)。
最精彩的是,它不仅记录成功的经验,还着重记录Hindsight Notes(后见之明)——即那些失败的教训。
比如,在修改这个模块时,千万不要直接删掉引用,因为有一个隐藏的反射机制在调用它,会导致运行时崩溃。
当Confucius Code Agent下次再次处理类似任务或同一个仓库时,它会先去翻阅这些笔记。
这相当于给AI装上了一个经验库。这种机制让Agent随着使用时间的增长,对特定代码库的理解越来越深,真正实现了从新手到资深工程师的进化。
自动化进化的Agent工厂
在Confucius的世界里,Agent的构建不再是纯手工的苦力活。
传统的Agent开发流程是:人类写Prompt(提示词) -> 跑测试 -> 发现不行 -> 人类改Prompt -> 再跑测试。这种手搓模式效率极低,而且很难适应不断变化的工具链。
Confucius引入了一个Meta-Agent(元智能体)的概念。你可以把它理解为制造Agent的Agent。
这就好比你不需要自己去造一辆车,你只需要告诉工厂:我需要一辆能跑山路的越野车,带绞盘,底盘要高。
工厂(Meta-Agent)就会自动根据你的需求,从零件库(SDK Extensions)中挑选组件,组装出一辆车,并在测试跑道上反复试车与调教。
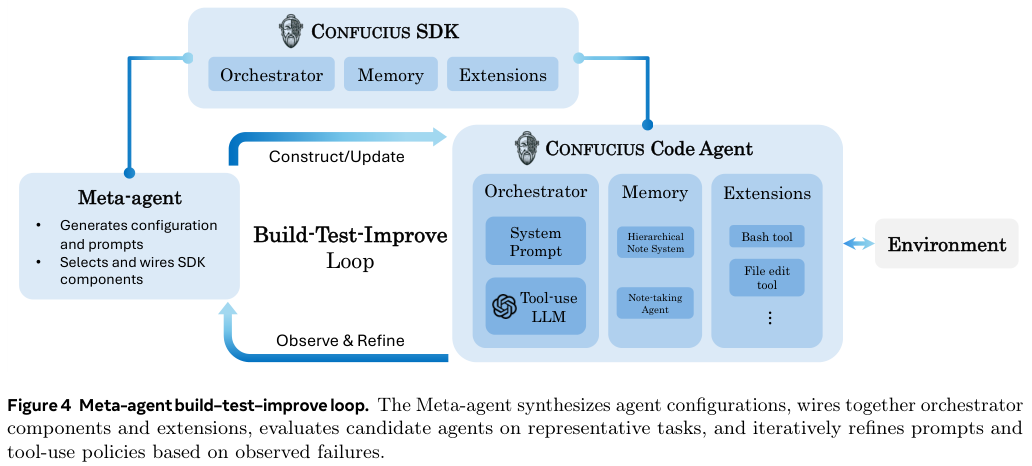
Build-Test-Improve Loop(构建-测试-改进循环):
构建(Build): 开发者用自然语言描述需求(例如:做一个专门修复CI流水线错误的Agent)。Meta-Agent根据描述,自动生成配置文件,选择合适的工具(如CLI工具、文件编辑器),并撰写初始的System Prompt(系统提示词)。
测试(Test): Meta-Agent在本地启动这个新生成的Agent,让它去跑一组回归测试题(比如几个典型的GitHub Issue)。
改进(Improve): Meta-Agent观察新Agent的表现。如果发现它总是选错工具,或者在编译报错时不知所措,Meta-Agent会分析原因,然后自动修改Prompt或调整工具配置。
这个循环反复进行,直到Agent在测试集上的表现达到预期。
Confucius Code Agent本身就是这个流程的产物。它的工具使用策略、错误处理机制,很大程度上是由Meta-Agent在数轮迭代中进化出来的,而不是人类工程师一行行硬写出来的。这种Agentic Scaffolding(智能体脚手架)的自我进化能力,是Confucius区别于其他框架的核心竞争力。
数据验证架构的胜利
所有的设计哲学和架构创新,最终都要落实到数据上。Meta在SWE-Bench-Pro(一个公认的高难度软件工程基准测试)上对CCA进行了严苛的评估。
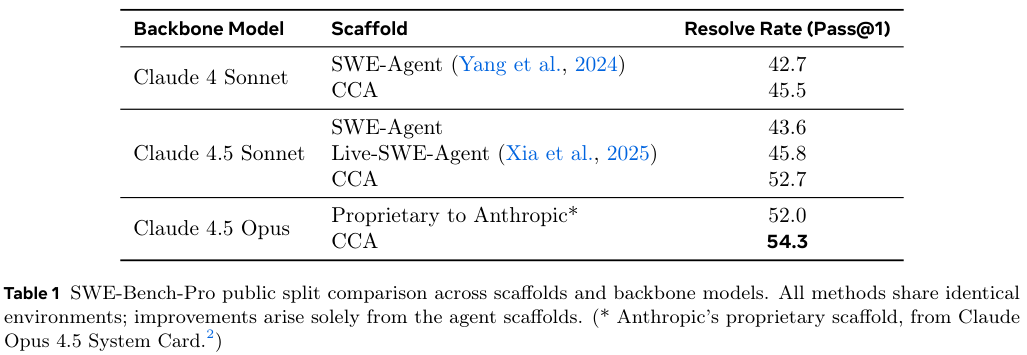
在SWE-Bench-Pro基准测试中,使用Claude 4.5 Sonnet作为基座模型的CCA,达到了52.7%的解决率(Resolve@1)。
这个成绩不仅大幅超越了其他开源Agent(如Live-SWE-Agent的45.8%),甚至击败了使用更强模型(Claude 4.5 Opus)但在专有脚手架上运行的Anthropic官方系统(52.0%)。
更有趣的是,即便是使用较旧的Claude 4 Sonnet模型,CCA也跑出了45.5%的成绩,优于SWE-Agent等基线水平。
这组数据极其有力地证明了模型能力不是决定胜负的唯一因素。
一个精心设计的Agent架构,完全可以弥补模型智力上的差距。Confucius通过优秀的记忆管理和工具编排,让中等生模型发挥出了优等生的水平。

在SWE-Bench-Verified榜单上,CCA更是以74.6%的成绩霸榜,超过了目前最强的开源竞品OpenHands(72.8%)。
目前的大多数Agent还是基于监督微调(SFT)或提示工程(Prompt Engineering)。但Confucius的架构天然适合引入强化学习(Reinforcement Learning, RL)。
由于它将Agent的思维过程(AX)完全结构化了,所有的操作轨迹、决策节点、成功与失败的反馈,都可以直接转化为RL训练中的轨迹和奖励信号。
Meta展望了一个未来:Agent不再仅仅依靠人类喂给它的静态知识,而是在不断的Build-Test-Improve循环中,通过自我博弈和环境反馈,自主地学习如何更高效地写代码、修Bug。
Confucius SDK就是实现这一愿景的基础设施——一个标准化的、可观测的、模块化的训练场。
CCA把只有在科幻小说中出现的自我进化的AI工程师拉近到了现实的边缘。
参考资料:
https://arxiv.org/abs/2512.10398v1

















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









