



MIT和清华大学的研究团队用BiFlow(Bidirectional Normalizing Flow)再度刷新生成式AI的单步生成质量纪录,Normalizing Flow架构重回巅峰。



BiFlow模型打破了传统流模型必须数学可逆的桎梏,通过解耦前向与反向过程,实现了比肩甚至超越扩散模型的高质量图像生成,且推理速度提升了两个数量级。
标准化流模型一步生成的高质量图像
在很长一段时间里,对抗生成网络(GANs)凭借极快的推理速度和不算差的质量占据一方,但难以训练且模式坍塌问题如影随形。
扩散模型以极高的图像质量和多样性统治了当下,代价是高昂的计算成本和漫长的采样步数。
而标准化流模型(Normalizing Flows,简称NFs),这位曾经被寄予厚望的贵族,却因为严苛的数学约束逐渐边缘化。
NFs拥有一个令人着迷的特性:它可以精确计算数据的似然概率,并将复杂的数据分布映射为简单的噪声分布。
这种映射在理论上是双向且精确的。
然而,理论的美感往往伴随着现实的残酷。
为了保证数学上的精确可逆,传统NFs不得不限制网络架构的设计,导致其表达能力受限。即便最新的TARFlow引入了Transformer来增强能力,也因为必须遵循自回归(Autoregressive)的解码方式,陷入了龟速推理的泥潭。
生成一张图需要成千上万次函数评估,这在追求效率的今天显然是不可接受的。
BiFlow提出了一种全新的思路:保留流模型的前向过程作为教师,但在反向生成过程中,不再死磕数学上的解析逆,而是训练一个非受限的神经网络来逼近这个逆过程。
这一改动看似轻描淡写,实则石破天惊。
它解放了网络架构,使得最先进的双向Transformer可以被无缝集成,同时实现了单步生成(1-NFE)。
在ImageNet 256x256基准测试中,BiFlow仅需一步推理就达到了2.39的FID分数,不仅在流模型家族中遥遥领先,更在速度上比其前身TARFlow快了整整两个数量级。
这标志着流模型不仅没有过气,反而找到了一条通往高效生成的新路径。
要理解BiFlow的突破,必须先厘清传统标准化流模型面临的困境。
NFs的核心理念是建立一个从复杂数据分布到简单高斯先验分布的双射函数。这个函数由一系列可逆变换组成,通过变量代换公式,我们可以精确计算数据的对数似然。
这种架构要求每一个变换步骤都必须是显式可逆的,并且其雅可比行列式(Jacobian Determinant)必须易于计算。
这两个要求像两道紧箍咒,死死限制了模型的设计空间。
为了满足雅可比行列式的计算要求,早期的流模型如RealNVP和Glow使用了仿射耦合层(Affine Coupling Layers),虽然巧妙,但对参数的利用率并不高。
后来的自回归流(Autoregressive Flows, AF)大大提升了模型的表达能力,因为它将联合概率分解为条件概率的乘积,每个维度只依赖于之前的维度。
TARFlow是这一路线的集大成者。
它将强大的Transformer架构引入自回归流中,通过因果掩码(Causal Masking)保证了自回归属性。
在训练阶段,这种设计允许并行计算似然,效率极高。但在推理(生成)阶段,问题就暴露无遗了。
由于是自回归模型,生成每一个像素(或Token)都必须依赖之前生成的所有内容。这意味着如果一个图像被编码为1024个Token,模型就必须串行运行1024次。
对于高分辨率图像,这种串行依赖简直是计算资源的噩梦。
TARFlow虽然在质量上证明了流模型可以与扩散模型一战,但在速度上却彻底输了。
生成一张图可能需要几秒甚至几十秒,而这仅仅是因为数学上要求反向过程必须是前向过程的严格解析逆。
BiFlow团队敏锐地捕捉到了这一矛盾:我们真的需要那个数学上严格的解析逆吗?用户关心的是生成的图片是否逼真,而不是这个逆过程是否由严格的代数运算得出。
如果能训练一个神经网络,让它学会把噪声还原成图像,且效果足够好,那么严格可逆的限制就可以被抛诸脑后。
解耦架构实现单步推理与全并行计算
BiFlow的核心哲学是解耦。
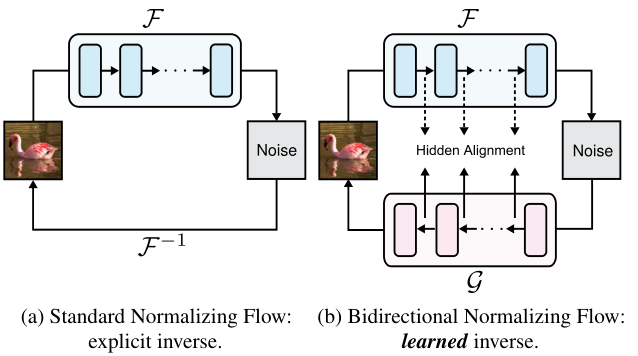
在标准流模型中,前向模型(数据到噪声)和反向模型(噪声到数据)是同一个模型的一体两面,互为数学逆。
BiFlow将它们强行拆开:前向过程依然使用设计精良的流模型(如改进版的TARFlow),因为它能提供高质量的噪声映射和易于训练的目标函数;而反向过程则由一个新的、独立的神经网络来承担。
这个新的反向模型不再受制于必须可逆和雅可比行列式易算的规则。
它变成了一个普通的生成模型,输入是高斯噪声,输出是图像数据。
由于没有了自回归的限制,研究人员可以大胆地使用双向注意力机制(Bidirectional Attention)的Vision Transformer(ViT)。这种架构不仅表达能力更强,更重要的是它支持全并行计算。
在推理阶段,BiFlow只需要一次前向传播(1-NFE)就能将噪声映射回图像。
不需要像扩散模型那样迭代几十步去噪,也不需要像TARFlow那样串行地一个Token接一个Token地崩。数据在网络中畅通无阻,从输入端瞬间流向输出端。
这种设计还带来了一个意外之喜:损失函数的灵活性。
在严格可逆的流模型中,训练目标被锁定为最大化对数似然(Maximum Likelihood Estimation, MLE)。
虽然MLE理论上很好,但它并不总是对应人类感知的最佳画质。
BiFlow的反向模型是独立训练的,这意味着我们可以使用任何能够提升画质的损失函数,比如感知损失(Perceptual Loss, 如LPIPS)或重建损失(MSE)。
这让BiFlow在生成细节丰富、纹理自然的图像方面具有了天然优势。
标准流模型受限于显式可逆,只能亦步亦趋地走钢丝;BiFlow通过引入一个可学习的反向模型,直接跨越了这道鸿沟,通过隐藏层对齐实现了从噪声到数据的飞跃。
确立了学习逆过程的大方向后,接下来的挑战是如何训练这个反向模型。
最直观的方法是朴素蒸馏(Naive Distillation):固定前向模型,给它一张图,算出对应的噪声;然后把这个噪声喂给反向模型,要求反向模型输出的图和原图尽可能像。
这种方法虽然简单,但效果并不理想。
从纯噪声一步跨越到清晰图像,中间的信息鸿沟巨大,单一的重建损失很难指导网络学到复杂的结构信息。
BiFlow团队提出了一种更为精妙的策略:隐藏层对齐(Hidden Alignment)。
流模型通常由多个模块堆叠而成,数据在流动的过程中会产生一系列中间状态(Hidden States)。这些中间状态实际上包含了从数据域逐渐过渡到噪声域的轨迹信息。
如果反向模型能够不仅仅在终点(输出图像)上与原图一致,而是在每一个中间步骤上都与前向模型的轨迹保持对齐,那么学习的难度将大幅降低。
这里有一个技术难点:前向模型和反向模型的中间层特征空间并不一定相同,甚至维度都可能不同。
为了解决这个问题,研究人员引入了轻量级的投影头(Projection Heads)。在计算损失时,反向模型的中间状态先通过投影头映射到与前向模型对应的空间,然后再计算距离。
实验数据表明,这种对齐策略的效果远超朴素蒸馏,甚至优于另一种要求更加严格的隐藏层蒸馏(Hidden Distillation),后者强行要求中间状态回到输入空间,反而限制了模型的表达。

上图清晰地展示了三种策略的区别。(a)是朴素蒸馏,只看结果;(b)是隐藏层蒸馏,步步紧逼但过于死板;(c)是BiFlow采用的隐藏层对齐,既有全程指导又保留了灵活性。
内置去噪模块消除额外计算开销
在TARFlow的原始设计中,为了提升画质,研究人员采用了一种妥协的方案:模型不仅要学习从数据到噪声的映射,还要在输入数据上叠加微小的噪声。
在生成时,先由流模型生成一个带噪的图像,然后再通过一个额外的基于分数的去噪步骤(Score-based Denoising)来去除这个底噪。
这个额外的去噪步骤虽然有效,但代价高昂。它需要对模型进行额外的反向传播计算梯度,或者运行一个单独的去噪网络,这几乎让推理成本翻倍。
BiFlow通过学习去噪(Learned Denoising)优雅地解决了这个问题。
既然反向模型是独立训练的,为什么不让它顺便把去噪的活儿也干了呢?
研究人员在反向模型的末端增加了一个专门的去噪模块(实际上就是多加一层Block)。在训练时,前向模型依然产生带噪数据的潜变量,但反向模型的训练目标直接设定为原始的、干净的图像。
这样一来,反向模型自然而然地学会了在还原数据的同时去除噪声。
这个过程是端到端优化的,不需要显式地计算分数函数,也不需要额外的推理步骤。这一改进不仅简化了流程,还进一步提升了生成质量,可谓一石二鸟。
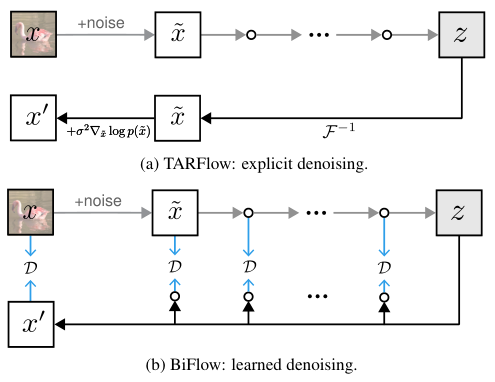
对比图清楚地显示了两种方案的差异。TARFlow需要在生成后走一个复杂的回路来去噪;而BiFlow则将去噪内化为网络的一部分,数据流向笔直向前,毫无阻滞。
分类器无关引导(Classifier-Free Guidance, CFG)是扩散模型成功的关键技术之一,它通过在有条件生成和无条件生成之间进行插值,显著提升了图像的语义一致性和质量。
然而,传统的CFG需要在推理时运行模型两次(一次带条件,一次不带条件),这意味着计算量翻倍。
BiFlow为了追求极致的单步推理速度,将CFG的计算从推理阶段转移到了训练阶段。
实际生成图片时,用户只需要输入一个想要的引导强度,模型跑一次就能得到结果,完全不需要运行两遍。
这一策略将推理成本直接砍半,同时保留了CFG带来的画质提升。实验表明,这种训练时的CFG(Training-time CFG)在效果上与推理时的CFG不相上下,甚至略有胜出。
全方位的实验验证与性能对比
为了验证BiFlow的有效性,研究团队在ImageNet 256x256数据集上进行了详尽的实验。
基准模型是改进后的TARFlow(iTARFlow),它本身就已经是一个经过精心调优的强力基线。
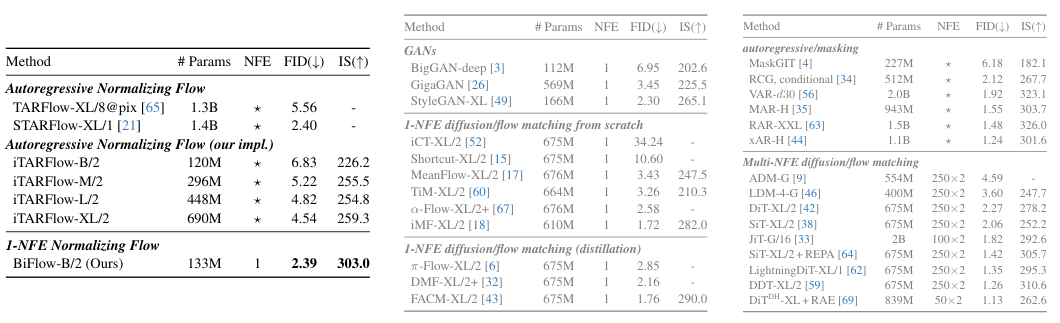
在生成质量上,BiFlow-B/2(基础版)取得了2.39的FID分数。相比之下,作为教师模型的iTARFlow-B/2的FID是6.83。
这看似反直觉,实则合情合理。首先,反向模型使用了更强的非因果Transformer架构;其次,反向模型可以直接优化生成图像与真实图像之间的感知距离(Perceptual Loss),而前向模型只能优化似然函数;最后,端到端的训练方式让模型学会了全局一致的映射,而不是在自回归的每一步中累积误差。
在推理速度上,优势更是压倒性的。
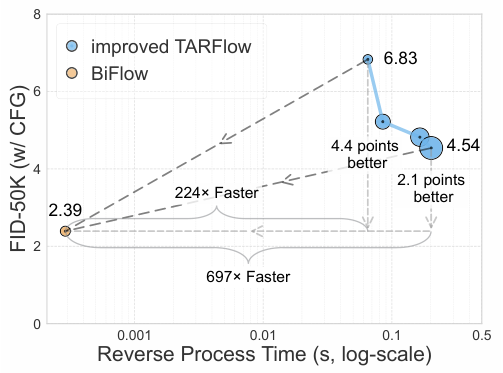
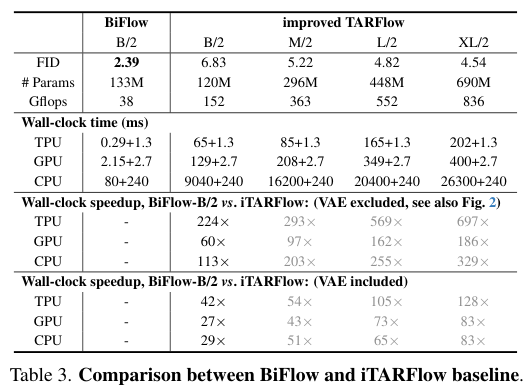
在TPU v4硬件上,BiFlow生成一张图仅需0.29毫秒(不含VAE解码),相比之下,同等规模的TARFlow需要65毫秒。即便算上VAE解码的时间,BiFlow也实现了几十倍到几百倍的加速。
BiFlow仅用Base规模的模型,就击败了X-Large规模的TARFlow教师模型(FID 2.39 vs 4.54),同时速度快了几个数量级。这充分证明了摆脱数学可逆约束后,模型潜力的巨大释放。
与其他类型的生成模型相比,BiFlow同样表现出色。
在单步生成(1-NFE)的赛道上,BiFlow的2.39 FID优于大多数基于流匹配(Flow Matching)和蒸馏扩散模型的方法。例如,InstaFlow、Rectified Flow等著名方法的蒸馏版本,在同等条件下往往难以达到如此高的保真度。
BiFlow不仅在生成图片上厉害,其独特的双向架构还为图像编辑和修复(Inpainting)提供了天然的便利。
由于保留了前向模型,我们可以将任意真实图像映射回噪声空间。
在图像修复任务中,给定一张被遮挡的图片,模型先将其未遮挡部分映射到噪声域,然后在噪声域对遮挡部分进行重采样,最后通过反向模型映射回图像域。
整个过程无需重新训练,即插即用,且能够生成与周围环境高度融合的内容。

同样,类别编辑(Class Editing)也变得轻而易举。将一只猫的图片映射为噪声,然后改变条件标签为狗,再通过反向模型生成,就能得到一张姿态相似但物种改变的图片。这种可控性是许多单向生成模型难以企及的。

BiFlow的成功向社区传递了一个明确的信号:标准化流模型并没有过时,它只是需要一点变通。
通过放弃对反向过程的数学执念,转而拥抱深度学习的拟合能力,流模型找回了它原本应有的位置——一个不仅理论优雅,而且工程高效的生成范式。
对于未来的研究者来说,BiFlow打开了一扇门。
既然反向过程可以学习,那么我们是否可以引入更复杂的网络结构?是否可以将这种思想应用到视频生成或3D生成中?
随着硬件的发展和算法的迭代,基于流模型的生成技术或许将在不久的将来,成为实时生成应用的首选方案。
参考资料:
https://arxiv.org/abs/2512.10953v1

















 8613
8613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









