



商汤科技与南洋理工大学通过构建800万量级的高质量三维空间数据集,训练出在空间智能测试中开源SOTA多模态基础模型。

同时发布了关于空间智能(Spatial Intelligence)的研究论文。论文指出了当前多模态大语言模型(MLLMs)的一块短板:尽管模型能看懂图,却难以理解三维空间。
现有的多模态模型在处理二维平面图像时表现出色,但在涉及三维空间理解、推理以及与物理世界交互的任务上,即使是顶尖模型也显得笨拙。
这种能力被称为空间智能,它是具身通用人工智能(Embodied AGI)感知、适应并与物理世界互动的基石。
对于人类而言,理解物体的前后关系、估算距离或想象从不同角度看物体的样子是近乎本能的微不足道的任务,但对于人工智能,这构成了巨大的认知障碍。
问题的根源不在于模型架构,而在于数据的稀缺与失衡。
高质量、多样化的空间落地数据极度匮乏。现有的数据集虽然规模庞大,但在空间推理的覆盖面和质量上呈现碎片化。
为了突破这一瓶颈,研究团队没有选择单纯堆砌数据量,而是采取了以数据为中心的方法,系统性地构建了名为SenseNova-SI-8M的大规模数据集,并基于Qwen3-VL、InternVL3及Bagel等通用基础模型进行了针对性训练。
数据与训练策略的有效性在结果中得到了直接印证。
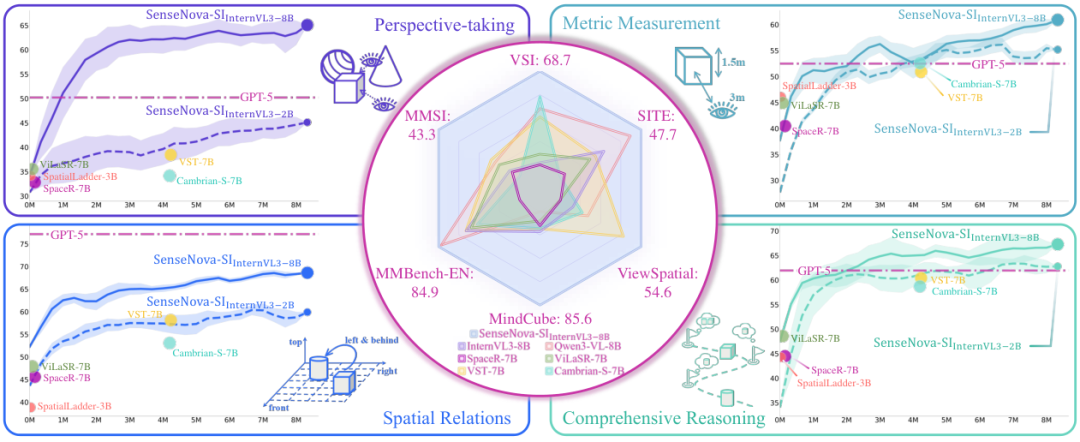
SenseNova-SI系列模型在VSI-Bench、MMSI、MindCube等多个权威基准测试中取得了开源模型中的最佳成绩(State-of-the-Art),并在特定能力上超越了GPT-5。
这一成果不仅证明了数据规模化对空间智能的驱动作用,也为社区提供了一套强健的基线模型。
八百万数据构建空间智能的认知地基
SenseNova-SI-8M数据集的构建逻辑严密遵循空间智能的分类学原理。
研究团队参考EASI协议,将空间智能解构为五大核心能力,确保数据能够覆盖从基础感知到复杂推理的全过程。
这五大能力分别是度量测量、空间关系、心理重构、视角转换以及综合推理。
度量测量(Metric Measurement, MM)是物理感知的起点。
这部分数据训练模型理解物理尺度和典型物体的大小。它不仅包含估算相机与物体之间、物体与物体之间的距离,还涉及跨尺度的尺寸估算,从单个苹果的大小到整个房间的面积。
这种能力要求模型建立起像素与真实世界物理量之间的映射关系。
空间关系(Spatial Relations, SR)要求模型在三维坐标系内进行推理。
在自我中心(Egocentric)的局部视角下,模型需要分辨前、后、左、右、上、下等相对位置。
在全局场景层面,这种关系扩展为近与远、大与小的相对判断。这不仅是识别物体在哪里,而是理解物体在空间结构中的相对站位。
心理重构(Mental Reconstruction, MR)是一项极具挑战性的任务。
它要求模型从有限的二维观测中推断出物体的三维结构。例如,通过诊断性任务识别物体的哪一面是可见的,迫使模型整合稀疏的二维视觉线索,推断出不可见的几何形状,并在以物体为中心的规范坐标系中对齐视图。这模拟了人类脑补物体背面形状的能力。
视角转换(Perspective-taking, PT)是SenseNova-SI-8M数据集的重中之重,也是现有开源资源中极度匮乏的领域。
研究团队构建了一个层级递进的任务体系:
-
视图对应(View Correspondence):建立跨视图的点或物体对应关系,即使在视角变化、尺度缩放或遮挡的情况下,也能识别出这是同一个实体。
-
相机运动推理(Camera Motion Reasoning):推断视图之间相机的相对运动轨迹,将图像外观的变化与三维空间变换联系起来。
-
异地中心变换(Allocentric Transformation):模拟视点转移,表达跨坐标系的空间关系,包括相机坐标系、物体-目标坐标系及自我导向视图。这种设计迫使模型超越简单的图像模式匹配,构建出关于观测结果随视点变化而变换的内部表征。
综合推理(Comprehensive Reasoning, CR)涉及协调多种空间能力,进行长时记忆和多步推理。
尽管这类数据难以大规模获取,团队仍复用了现有数据集作为轻量级补充,以确保模型在复杂场景下的应对能力。

数据集的来源经过了精心的筛选与整合。
通用问答(General QA)部分收集了VSR、SPEC、GQA、VQA及IconQA等开源数据集,贡献了约60万个问答对,用于维持基础的二维图像理解能力。
社区空间智能数据集整合了Open3D-VQA、CLEVR系列、REL3D等现有资源,共计约330万个问答对。
为了填补视角转换和心理重构的空白,研究团队利用MessyTable、ScanNet、ScanNet++、SUN RGB-D、CA-1M、Ego-Exo4D及Matterport3D等含有丰富注释的三维数据集,生成了大规模、精确且任务平衡的问答对。
这一扩展过程贡献了450万条数据,使得整体语料库规模达到了850万个问答对。
特别是引入了点级别、物体级别和场景级别的对应关系,以及相机运动和异地中心视点变换的数据,极大地丰富了数据的维度。
性能全面超越开源模型并逼近专有模型
研究团队选用了三种代表不同架构理念的多模态基础模型进行实验:Qwen3-VL、InternVL-3以及Bagel。
Qwen3-VL代表了从强大语言模型基础扩展至视觉模态的策略;InternVL-3则是原生多模态模型,视觉和语言从头开始联合训练,具备更强的跨模态对齐能力;Bagel则代表了统一理解和生成的范式。
为了保持与现有研究管线的兼容性,团队未修改模型架构,而是坚持以数据为中心的训练策略。
每个模型在SenseNova-SI-8M数据集上使用128个GPU进行了一个周期的训练,批量大小(Batch Size)为2048。这种高强度的训练赋予了模型全新的空间智能。
在五个新近发布的权威基准测试中,SenseNova-SI系列展现了统治级的表现。
VSI-Bench评估基于视频的视觉空间推理,MMSI-Bench考察多图像设置下的空间线索整合,MindCube测试有限观测下的心理建模,ViewSpatial-Bench关注多视角定位,SITE则提供了广泛的认知覆盖。
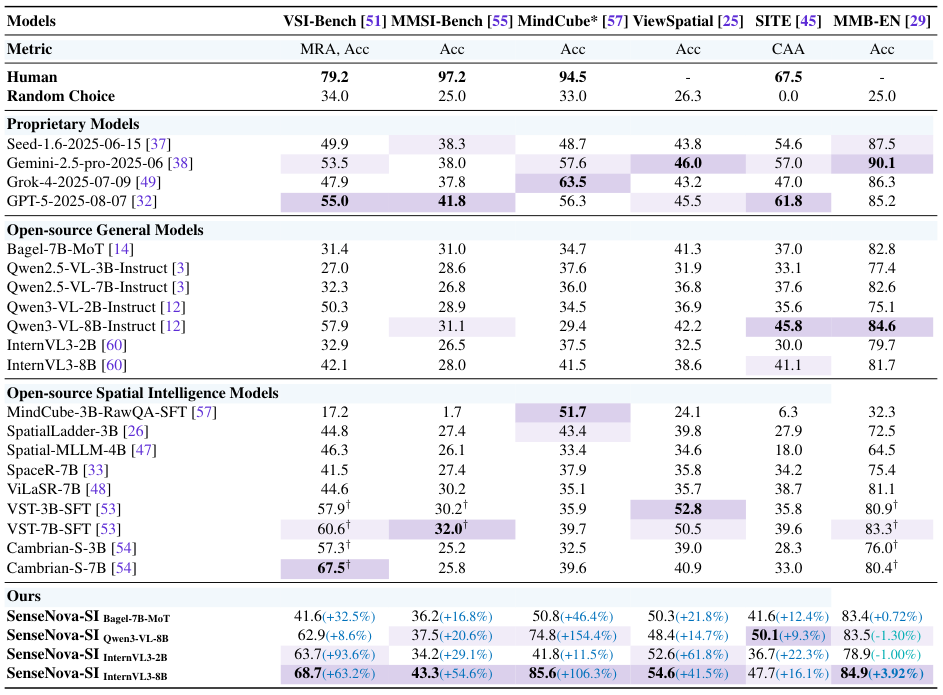
SenseNova-SI-InternVL3-8B模型在VSI-Bench上取得了68.7%的成绩,远超原始InternVL3-8B模型的42.1%。
在MMSI上,得分从28.0%提升至43.3%;在MindCube上,从41.5%跃升至85.6%;在ViewSpatial上,从38.6%提高到54.6%;在SITE上,从41.1%增长至50.1%。
这种全方位的提升证明了专用空间数据训练的巨大价值。
更令人瞩目的是与专有模型的对比。
GPT-5(2025-08-07版本)在VSI-Bench上的得分为55.0%,在MMSI上为41.8%。SenseNova-SI在这些指标上均实现了超越。
虽然GPT-5在空间关系(SR)任务上依然强劲,但在视角转换(PT)方面暴露出明显不足。SenseNova-SI凭借大量针对性的视角转换数据训练,在PT任务上令人信服地击败了GPT-5。
不仅如此,即便训练数据中包含的综合推理(CR)样本非常有限,SenseNova-SI在CR性能上也逐渐超越了GPT-5。
这揭示了一种能力协同效应:基础空间任务(如视角转换和空间关系)的扎实训练,能够正向迁移并增强更复杂的推理技能。
同时,在通用多模态基准MMBench-En上,SenseNova-SI不仅没有出现灾难性遗忘,反而将得分从81.7%提升至84.9%,证明了空间智能训练与通用多模态能力的兼容性。
规模化效应与能力涌现的科学解释
研究深入剖析了数据规模化对模型能力的影响,揭示了空间智能的Scaling Law。
混合数据训练被证明极其有效,通过聚合广泛的公共数据集并扩大语料库,20亿参数(2B)的SenseNova-SI模型在可比数据预算下,超越了现有的70亿参数(7B)空间智能基线模型。
模型尺寸对能力发展轨迹有显著影响。
虽然2B和8B模型在度量测量、空间关系和综合推理上的提升趋势相似,但在视角转换(PT)任务上却出现了分化。
2B模型似乎缺乏足够的容量来鲁棒地学习复杂的视点变换,而8B模型则能有效掌握这一核心能力。
这表明,视角转换可能是空间智能中对模型容量要求最高的一环。
随着数据量的持续增加,性能增益呈现出边际效应递减的饱和趋势。
虽然目前尚不清楚继续扩展是否会触发新的涌现能力,但研究团队认为,仅靠数据堆砌不太可能达到人类水平的空间智能。这也促使团队决定完全开源模型权重,让社区能够站在更高的起点上探索算法创新。
在大规模训练中,模型展现出了令人惊喜的泛化能力和溢出效应(Spill-Over)。
控制实验显示,在单一数据集上训练的模型能够解决完全不同领域的任务。
例如,在基于Ego-Exo4D构建的视图转换数据集上训练的模型,学会了在自我中心和异地中心视点之间进行转换。这种能力被模型举一反三地迁移到了迷宫寻路(Maze Pathfinding)和MMSI Pos-Cam-Cam任务中。
这些任务虽然表面不同,但底层都依赖于连续的视点模拟和跨视图的信息聚合。

外推(Extrapolation)能力是另一个强有力的证据。
尽管SenseNova-SI每个样本最多仅使用16帧视频进行训练,但在推理阶段,它能够有效处理32帧、64帧甚至更多帧的序列。
数据表明,在VSI基准测试中,当推理帧数增加时,SenseNova-SI保持了高性能,甚至在某些情况下优于专门使用64或128帧长上下文窗口训练的竞品模型。
这意味着模型并非简单地记忆训练窗口内的模式,而是真正学会了构建连贯的空间结构,能够跨越更大的时间间隔形成有意义的连接。
拒绝捷径学习与文本思维链的局限
为了验证模型是否真的学会了看图,而不是在玩文字游戏,研究团队进行了严格的鲁棒性分析。
多模态模型常被诟病利用语言捷径(Shortcuts)——即不看图,仅凭问题文本的统计规律猜答案。
在专门设计用于消除纯文本捷径的VSI-Debiased基准上,SenseNova-SI的性能下降幅度远小于其他模型,证明其回答主要依赖于视觉空间理解。

更具说服力的是在MindCube基准上的盲测(Blind Test)。先前的开源最佳模型MindCube-RawQA-SFT在不输入图像的情况下竟能拿到50.7%的分数,与其全视觉输入的51.7%几乎持平,这彻底暴露了其对语言先验的依赖。
相比之下,SenseNova-SI在无视觉设置下得分骤降至52.5%(全视觉为85.6%),这巨大的分差反向证明了它在真正地使用视觉信息进行推理。
研究还探索了热门的思维链(Chain-of-Thought, CoT)技术在空间任务中的应用。
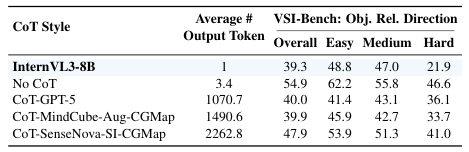
团队尝试了三种CoT方案:使用GPT-5生成CoT、构建JSON风格的认知地图以及增强版的逐步跟踪认知地图。
在约10万个样本上训练后,结果却出人意料:虽然增强版CoT带来了微弱提升,但所有CoT变体的绝对增益都非常有限(约2%)。
这一消极结果具有重要的科学意义。它表明,将基于文本的线性逻辑推理范式简单移植到空间智能中并不是灵丹妙药。空间推理可能需要一种根本不同的机制,单纯的文本描述无法高效承载复杂的三维几何变换。
具身智能的零样本落地应用
空间智能的最终归宿是物理世界。
为了验证实用性,研究将SenseNova-SI应用于EmbodiedBench中的机器人操作任务。
模型被实例化为一个具身智能体,控制虚拟Franka Panda机器人执行包含丰富空间语言(如左、上方、后方、水平)的复杂指令。
值得强调的是,此过程没有对模型进行任何微调(No Finetuning)。研
究对比了两种提示设置:官方提示(OP)仅提供边界框坐标,而面向空间智能的提示(SIP)则增加了物体落地线索,以减少识别歧义。
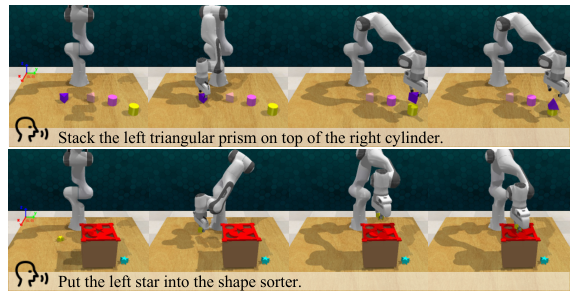
结果显示,SenseNova-SI在两种设置下均大幅优于基线模型。
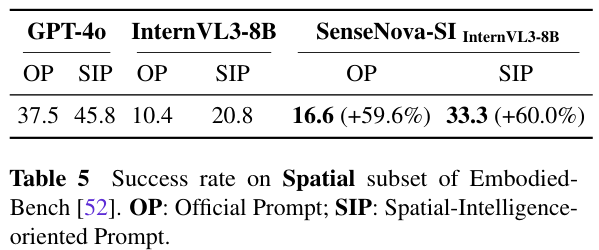
在SIP设置下,SenseNova-SI-InternVL3-8B的成功率达到33.3%,相比原始InternVL3-8B的20.8%提升了60%。
模型能够更可靠地识别关键空间线索,生成更准确的动作规划。这证明了在海量空间数据上训练出的基础模型,能够直接赋能具身智能,显著提升机器人理解和执行空间指令的能力。
SenseNova-SI是一次关于数据驱动空间智能的深度实验,向我们展示了当人工智能真正理解空间时,爆发出的潜力。
参考资料:
https://github.com/OpenSenseNova/SenseNova-SI
https://www.modelscope.cn/organization/SenseNova
https://huggingface.co/collections/sensenova/sensenova-si
https://arxiv.org/abs/2511.13719

















 1250
1250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









