



Meta发布了一个手机模型MobileLLM-Pro并开源了,端侧AI又迎来强力模型。
这是一款仅有10.8亿参数的基础语言模型,代号MobileLLM-P1,专为在手机这样的设备上高效运行而生。它的出现,完美回应了市场对隐私保护、低延迟和离线功能的强烈需求。它让强大的AI能力直接在你的手机上成为可能,不需要时时刻刻联网,数据也更安全。
通过巧妙的架构和先进的压缩技术,MobileLLM-Pro在极其有限的资源下,不仅超越了同级别的对手,还在处理长文本、推理能力方面表现得相当出色。
它的“骨架”很清奇
想要在小小的手机里塞下一个能打的模型,就得在架构上玩点高端操作。
MobileLLM-Pro的研究人员发现,对于十亿参数以下的小模型,把网络做得更“深”比做得更“宽”效果更好。所以,他们设计了一个30层深度的Transformer架构,但把其他维度控制得非常精简。
具体来看它的配置:
-
参数数量:10.84亿
-
网络层数:30层
-
注意力头:20个(其中只有4个处理键值对)
-
嵌入维度:1280
-
隐藏维度:6144
-
词汇表大小:202048个
-
上下文长度:128k字符
这种“瘦高个”身材,让模型在参数有限的情况下,依然能捕捉到复杂的语言规律和逻辑。
MobileLLM-Pro还有一个绝活,叫作“交错局部-全局注意力”(Interleaved Local-Global Attention, LGA)机制。传统的模型在处理信息时,每一层都会看一遍全部内容,这在处理长文章时非常耗费计算资源。而MobileLLM-Pro则是每三层只看局部小窗口(512个字符)的“局部注意力”之后,再来一层审视全局的“全局注意力”。
这种“张弛有道”的设计好处巨大:处理8000字符长度的文本时,预处理延迟降低了1.8倍,关键值(KV)缓存大小从117MB骤降到40MB。这意味着模型在处理长文档时,速度更快,内存占用更小,不会让手机卡顿。
“蒸馏”来的智慧
MobileLLM-Pro的强大性能,并非完全从零开始苦练而来,而是采用了“知识蒸馏”的训练方法。
用一个更强大的“老师模型”,拥有170亿参数的Llama 4-Scout,来手把手地教“学生模型”MobileLLM-Pro。
整个预训练过程被精心设计为三个阶段:
语言学习阶段:先用高质量数据,通过知识蒸馏,让模型掌握通用的语言基础能力,比如语法、语义和基本推理。
长上下文感知阶段:利用老师模型处理长文本的能力,教会学生模型如何稳健地处理长达128k字符的上下文。这就好比老师教学生读长篇小说,而不是只看短故事。
领域能力阶段:这个阶段更有趣,研究人员训练了多个在特定领域(如代码、数学、科学)表现出色的“专家模型”,然后像调鸡尾酒一样,将这些专家的能力融合进MobileLLM-Pro中,使其成为一个“通才”。
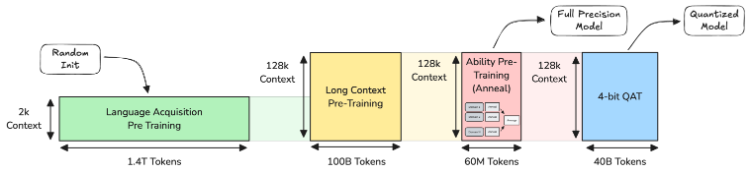
在完成这三步后,还有一个专门为模型“瘦身”准备的第四阶段:量化感知训练(Quantization-Aware Training, QAT)。
“瘦身”也要有技术
要在手机上流畅运行,模型必须变得极小。量化就是这个“瘦身”过程,它把模型中原本用高精度浮点数表示的参数,压缩成低精度的整数。
传统的做法是“训练后量化”(Post-Training Quantization, PTQ),等模型训练好了再压缩,但这往往会导致性能大幅下降。打个比方,就像把一张高清照片强行压缩成低像素图片,细节会丢失很多。在MobileLLM-Pro的测试中,PTQ直接导致基准测试分数平均掉了34%。
而MobileLLM-Pro采用的“量化感知训练”(QAT),则是在训练过程中就让模型“意识到”自己未来要被压缩,提前适应低精度的环境。这种方法效果惊人,性能损失被控制在了1.5%以内。

最终,MobileLLM-Pro提供了两种针对不同硬件的量化方案:
CPU优化版:采用4位分组权重量化,压缩后的模型大小仅为590MB,性能只比全精度版本下降0.4%。
加速器优化版:专门为苹果的神经引擎(ANE)和高通的Hexagon张量处理器(HTP)等移动AI芯片设计,性能下降也只有1.3%。
这确保了无论在哪种手机上,MobileLLM-Pro都能发挥出接近原版模型的强大性能。
量化后仍然很强
MobileLLM-Pro的基础模型在多个行业标准基准测试中,表现都非常亮眼。
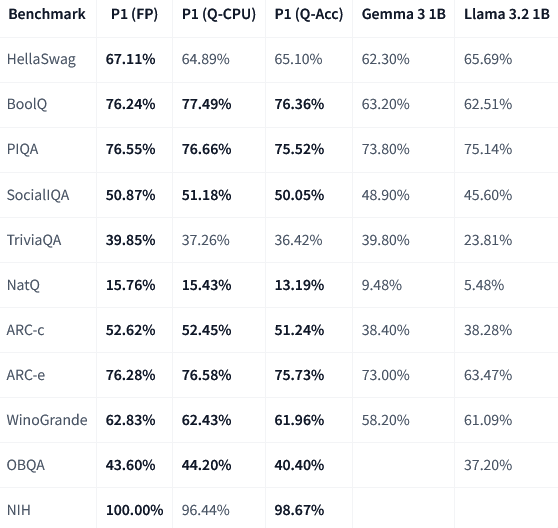
注:FP = 全精度(bf16),Q-CPU = int4分组量化(CPU),Q-Acc = int4通道量化(加速器)
MobileLLM-Pro的性能,即使是“瘦身”过的量化版本,仍然全面领先谷歌的Gemma 3 1B和Meta自家的Llama 3.2 1B模型,尤其是在BoolQ、NatQ和ARC等考验推理和知识能力的测试中。
在经过指令微调,更贴近聊天和任务处理场景后,MobileLLM-Pro在编程相关的任务上表现得尤其突出,比如在MBPP和HumanEval测试中,分数远超对手。
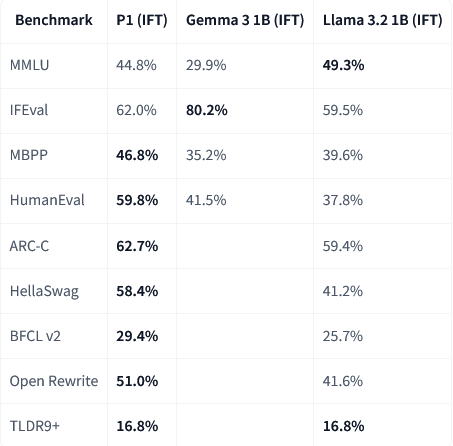
注:IFT = 指令微调
在真实手机上的表现又如何呢?Meta在三星设备上进行了延迟测试,结果显示,即使在处理长达8000字符的文本时,其响应速度也完全在可接受范围内。尤其是在使用HTP(Hexagon张量处理器)硬件加速后,延迟大幅降低。
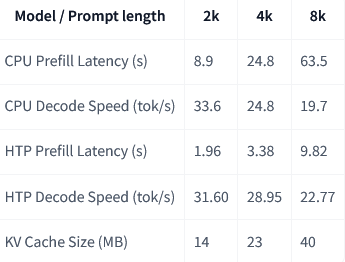
测试平台:Samsung Galaxy S25 CPU和Galaxy S24 Hexagon Tensor Processor
这一切都证明了MobileLLM-Pro不仅仅是一个实验室里的概念模型,而是一个真正可以落地到我们日常设备中的实用AI。
它为设备端聊天机器人、长文档摘要、代码辅助等应用场景打开了全新的想象空间,同时由于所有计算都在本地完成,用户的隐私也得到了最大程度的保障。
参考资料:
https://huggingface.co/facebook/MobileLLM-Pro
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









