



AI的进化已经快摸到天花板了,Meta想出个新招,让AI从自己犯的错里学习,而且不需要一个老师在旁边打分。
几个月前,人工智能领域的两位大神,图灵奖得主Richard Sutton和谷歌DeepMind的科学家David Silver,联手抛出了一篇檄文——《欢迎来到经验时代》。

文章观点很犀利,AI想变得更聪明,不能再像个书呆子一样只埋头啃人类数据了。
它必须像个活生生的动物,被扔进一个真实的环境里,通过一连串的互动,去闻,去听,去摸,去行动,去感受这个世界给它的反馈。这个连续不断的过程,就是所谓的“经验流”。AI得在这个经验流里,通过强化学习自己给自己升级,而不是等着人类把嚼碎的知识喂到嘴里。
这听起来很酷,但做起来比登天还难。
真正的世界,哪有那么多现成的奖励信号等着你。在很多复杂的任务里,完成度很难量化成一个分数。没有分数,强化学习就成了没头苍蝇。
所有人都卡在了这里。一边是星辰大海的理论,一边是寸步难行的现实。
Meta超级智能实验室(MSL)、FAIL和俄亥俄州立大学的一帮研究员,带着他们的“早期经验”(Early Experience)范式走了过来,试图在这条鸿沟上搭起一座桥。

“早期经验”学习的来由
我们今天看到的各种语言大模型,从聊天到写代码,看起来无所不能,但它们的成长空间被限制了。
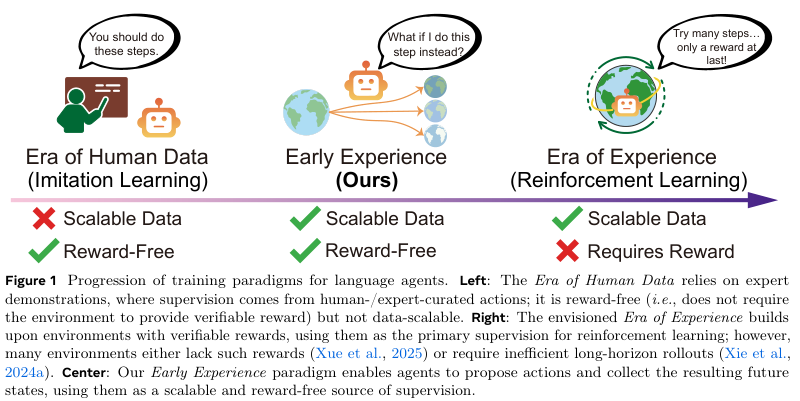
它们的成长,极度依赖一种叫作监督微调的训练方式。找一堆专家,做一遍标准答案,然后让AI照着学。比如,教AI订机票,就给它看一万遍人类专家成功订票的录屏。
这种方法见效快,训练过程稳定。
但AI在这个过程中,像个被蒙上眼睛的木偶,它只是在模仿动作,根本不知道自己每个动作会带来什么后果。它只是在机械地复现专家的行为路径。完全没有从失败中学习的能力。一旦遇到一个专家没演示过的情况,比如网站改版了,或者弹出一个验证码,它就卡壳了。
Meta的研究员们表示:“专家示范的本质,就是它只覆盖了现实世界里一小撮场景,AI被困在了这口井里。”
而另一个被寄予厚望的方法,强化学习,虽然在封闭世界里大杀四方,可一拿到真实世界的开放问题上,很难泛化。
就像前面说的,奖励信号太稀疏,太难定义。
在一个电商网站上,AI的任务是“买一件性价比最高的红色T恤”,它浏览了十个页面,对比了五个商品,最后把一件加进了购物车。这个过程里,哪一步应该给奖励?是点击了筛选按钮,还是查看了用户评论?直到最后下单成功,才能得到一个明确的“好”或“坏”的反馈。但这个反馈来得太晚了,中间几十步操作,功劳到底算谁的?这就是信用分配难题,让训练变得极其低效和不稳定。
只会死记硬背的“模仿派”,需要清晰奖惩才能进步的“强化派”,都走得磕磕绊绊。
Meta团队决定在模仿学习和强化学习之间,走出第三条路:让AI从自己的“经验”里直接学习,而且还不需要奖励。
他们是这样设计的:AI不再仅仅学习人类专家整理好的“标准答案”,它还会去亲自下场“体验”。当它在环境中执行一个动作后,会产生一个未来的状态,这个状态,就是它自己的亲身经历。这些经历,无论好坏,都可以被转化成监督信号,让AI直接从行动的后果中成长。
论文里举了一个生动的例子。
“想象一个语言智能体要学习如何在网页上预订航班。在传统的模仿学习中,它只能看到专家成功预订的示范过程。而在‘早期经验范式’中,智能体还会探索当它点击不同的按钮或错误填写表单时会发生什么,观察错误提示、页面跳转以及其他结果。这些观察会成为无需显式奖励的学习信号。”
换句话说,AI不仅要学“怎么做对”,还要看“做错了会怎么样”。
比如,AI在日期栏里填了一个“昨天”的日期,然后点击了下一步。页面刷新,弹出一个红色的错误提示:“无效的出发日期”。这个血淋淋的教训,比看一万遍“如何正确填写日期”的示范都有用。这个错误提示本身,就是最宝贵的学习资料。
Meta团队围绕这个核心思想,设计了两种具体的策略。
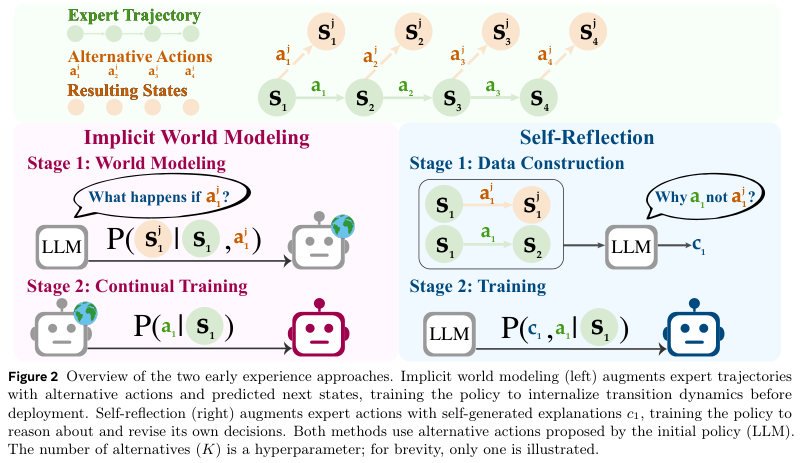
一,隐式世界建模
让AI去预测“我做了这个动作之后,世界会变成什么样子”。
在他们的设定里,世界的状态,无论是网页内容还是环境描述,都用自然语言来表示。所以,“预测下一个状态”这个任务,就变成了语言模型最擅长干的事:下一个词元预测。
具体来说,AI在某个状态下,不按专家的路子走,自己试了一个动作,比如乱点了一个按钮,然后观察到了一个新的页面状态。这个新的页面状态,就成了训练它的“答案”。模型要学习的,就是在“当前页面”和“我乱点的那个按钮”这两个条件下,预测出那个“新页面”的内容。
他们用同一套模型参数,既用来预测世界会怎么变(世界建模),也用来决定自己下一步该干嘛(策略执行)。这就相当于把对世界运行规律的理解,直接内化成了自己的行动本能。
二,自我反思
如果说“隐式世界建模”是让AI自己去碰壁,那么“自我反思”就是让AI在碰壁之后,还要写一份“检讨”。
这个策略更进一步,它让AI去比较“我的骚操作”和“专家的神操作”到底差在哪。
具体流程是这样的:在某个状态下,AI知道专家会执行动作A,然后会达到一个好的结果。但AI不这么干,它从自己的策略里采样了一个替代动作B,执行了,然后得到了一个可能不太好的结果。
研究团队会提示语言模型,让它生成一段“思维链”,用自然语言解释一下,为什么专家的动作A,从结果上看,要比我的动作B更好。
比如,专家点击了“下一步”,进入了支付页面。而AI自己点击了“返回”,回到了首页。AI就要生成这样一段反思:“专家的动作通向了任务的下一个环节,而我的动作导致了任务进程的倒退,所以我应该选择专家的动作。”
这些包含了状态、替代动作和反思的“检讨书”,会被收集起来,形成一个自我反思数据集。然后,用这些数据去训练AI,让它在做决策前,先学会像这样进行一番利弊分析。
在实际操作中,他们会把这个自我反思数据集,和原始的专家示范数据集混在一起训练。这样,AI既能学习专家的正确路径,也能从自己的错误尝试和反思中吸取教训。
八个环境的检验
Meta团队挑选了八个风格迥异、难度各异的语言智能体环境,来检验“早期经验”范式到底是不是真有两下子。
这八个环境,涵盖了具身导航、网页操作、工具使用、长线规划等各种棘手的任务。
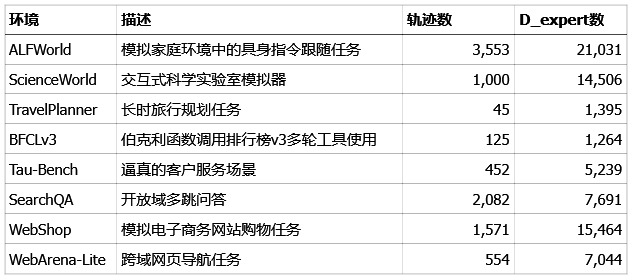
他们用了Llama-3.2-3B,Qwen-2.5-7B和Llama-3.1-8B这几个不同规模的模型,在每个环境里,都用固定的专家数据量进行训练。一组只用模仿学习,作为基准。另外两组,则分别加上“隐式世界建模”(IWM)和“自我反思”(SR)这两种早期经验的策略。
为了公平,所有方法的训练步数预算都完全一样。
结果是惊人的。
早期经验,几乎在所有的环境和模型上,都把单纯的模仿学习甩在了身后。
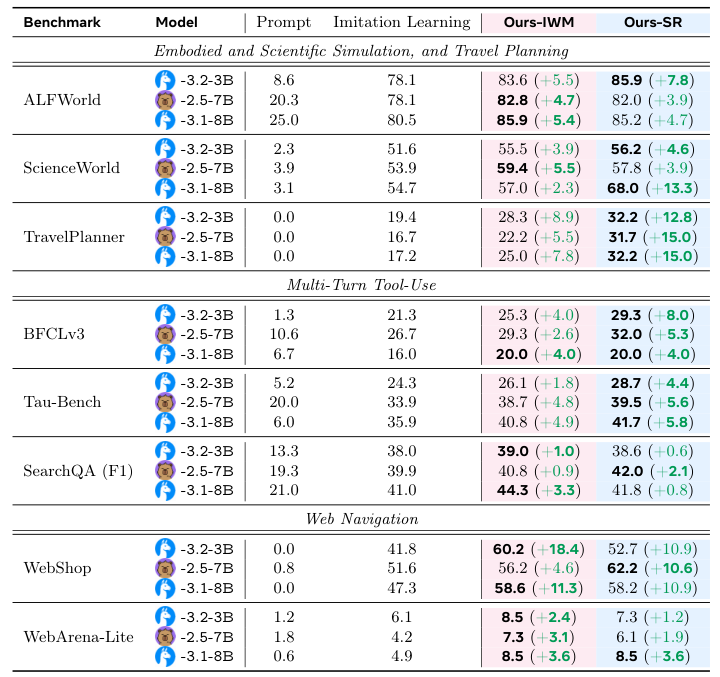
在WebShop这个模拟购物网站上,“隐式世界建模”把成功率从41.8%直接干到了60.2%,提升了18.4个百分点,效果拔群。因为购物网站的页面跳转逻辑相对固定,AI通过预测下一个页面的状态,很快就摸清了网站的脾气。
在TravelPlanner这个需要长线规划的旅行任务里,“自我反思”则大放异彩,把成功率提升了12.8个百分点。这类任务,一步错,步步错,AI通过反思自己的错误选择,学会了如何制定更合理的长期计划。
即使是在WebArena这种极其复杂的真实网页导航任务里,早期经验也能带来稳定,虽然绝对值不大,但依旧是肉眼可见的提升。
研究团队还发现,不同的环境特点,适合不同的早期经验策略。
如果一个环境的动作空间是封闭有限的,比如在ALFWorld里,动作就是“前进、左转、拿起苹果”这些,那么“隐式世界建模”就很有效,它能帮助AI快速掌握这些动作和环境状态之间的因果关系。
如果环境的动作空间结构化但非常庞大,比如调用各种复杂的API接口,那么“自我反思”就更管用。因为它能帮助AI理解为什么调用这个API是对的,而调用另一个是错的,这背后涉及更复杂的逻辑推理。
泛化能力也大大提升
一个好的学生,不仅要能考高分,还要能举一反三,解决没见过的新问题。
Meta的团队也想知道,经过早期经验训练的AI,泛化能力怎么样。他们设计了分布外(Out-of-Distribution, OOD)的测试,也就是用一些和训练数据风格迥异的任务来考验AI。

结果很清楚。虽然面对新问题同样有较大提升。在好几种情况下,它在OOD任务上的相对提升,甚至超过了在常规任务上的提升。
这说明,通过亲身犯错和反思,AI把自己的探索经历,转化成了应对未知世界的“肌肉记忆”。
更关键的是,早期经验范式,还为后续的强化学习铺平了道路。
当环境能够提供奖励信号时,研究团队在之前训练好的模型基础上,又接上了一个强化学习阶段。
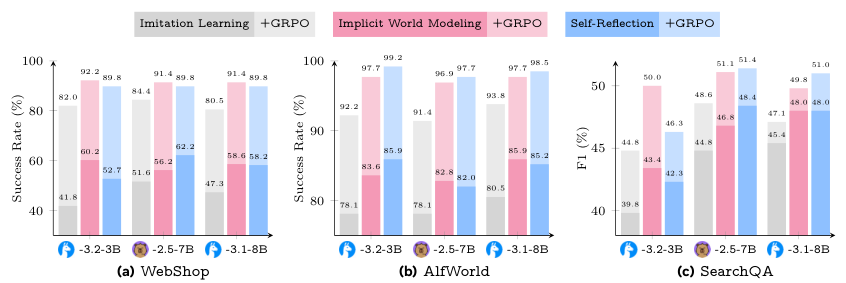
他们发现,无论是用“隐式世界建模”还是“自我反思”预训练过的模型,再去做强化学习,其最终能达到的性能上限,都稳定地高于从模仿学习开始的模型。
早期经验不仅仅是模仿学习的替代品,还是一个通往真正强化学习的、坚实而高效的跳板。
Meta的这项研究,为我们揭示了AI从“数据时代”迈向“经验时代”的一条清晰可行的路径。
参考资料:
https://storage.googleapis.com/deepmind-media/Era-of-Experience /The Era of Experience Paper.pdf
https://arxiv.org/abs/2510.08558
https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









