



异构计算硬件体系
AI大模型与异构算力融合技术白皮书
主流AI芯片对比
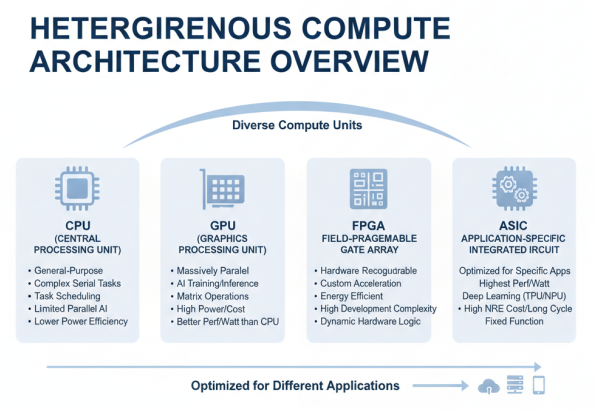
异构计算硬件体系由多种类型的计算单元组成,主要包括CPU、GPU、FPGA、ASIC等,各具特点,适用于不同的应用场景。
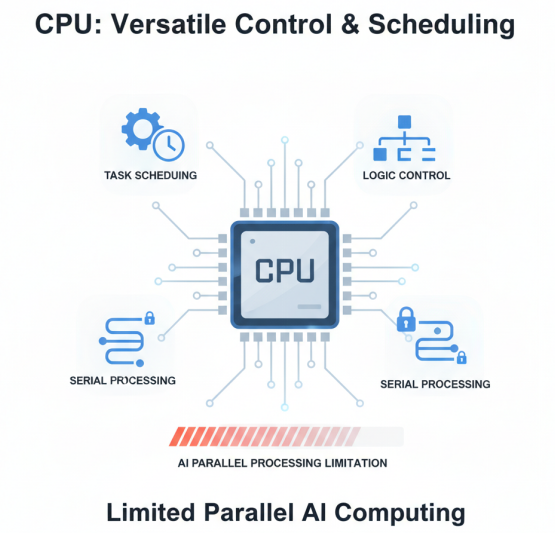
CPU(中央处理器)作为通用计算单元,具有强大的逻辑控制和任务调度能力,适合处理复杂的串行任务和多样化的工作负载。然而,在AI计算场景下,CPU的并行计算能力相对有限,能效比较低。现代CPU通常集成多个核心,支持SIMD(单指令多数据)指令集,如AVX-512等,在一定程度上提升了AI计算性能,但与专用AI加速器相比仍有差距。
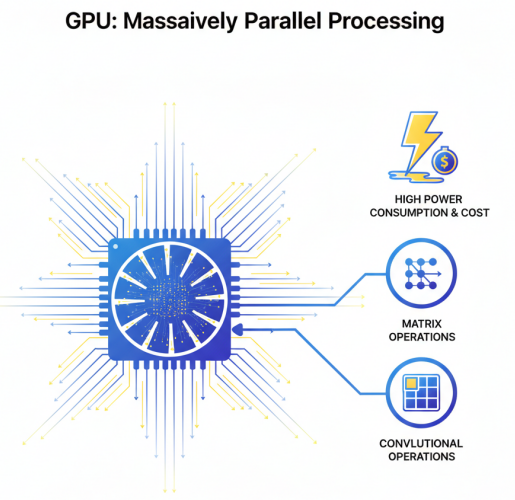
GPU(图形处理器)最初为图形渲染设计,因其强大的并行计算能力而成为AI训练和推理的主流选择。GPU拥有数千个计算核心,适合执行大规模并行计算任务,特别是在矩阵运算、卷积运算等AI核心算法上表现优异。然而,GPU功耗较高,成本昂贵,且在某些特定算法上效率不如专用芯片。在能效比方面,GPU优于CPU但不及FPGA和ASIC。
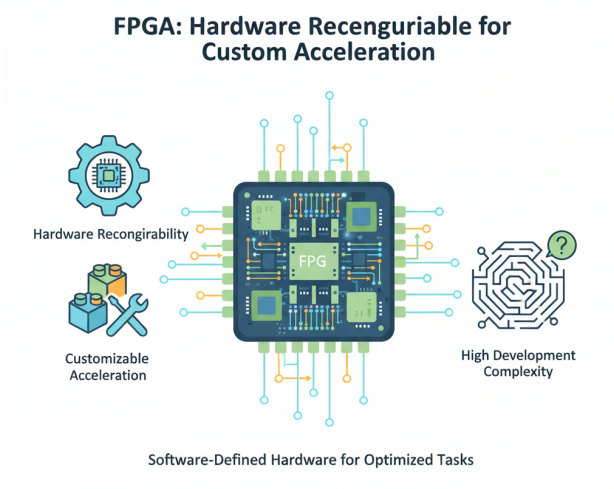
FPGA(现场可编程门阵列)具有硬件可重构的特点,用户可以根据特定应用需求定制硬件逻辑,实现高度优化的计算加速。FPGA在能效比和灵活性方面具有优势,特别适合需要定制化加速的场景。然而,FPGA开发复杂度高,需要专业的硬件设计知识,且运行频率相对较低,在大规模部署时面临挑战。与GPU/CPU相比,FPGA采用软件定义的硬件架构,硬件逻辑可根据需求动态调整,而GPU/CPU硬件固定,其并行性设计是适应固定硬件的。
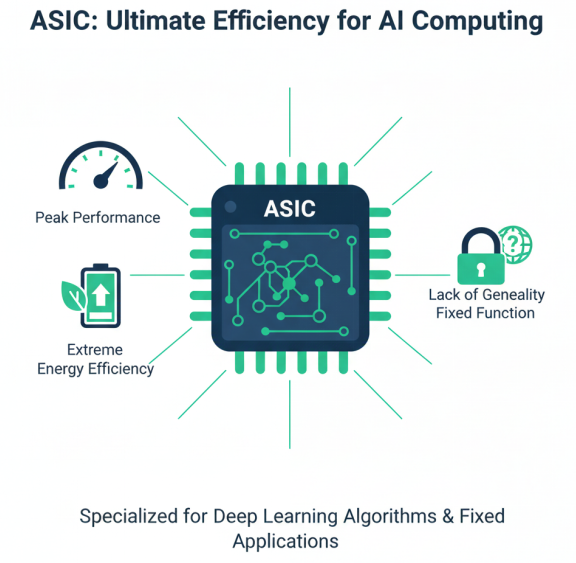
ASIC(专用集成电路)针对特定应用进行优化,在能效比和性能方面表现最佳。AI领域的ASIC如TPU、NPU等,针对深度学习算法特点进行专门优化,实现了极高的计算密度和能效比。然而,ASIC缺乏通用性,开发成本高,周期长,适合大规模、固定场景的应用。从能耗比方面来看,ASIC > FPGA > GPU > CPU,产生这样结果的根本原因是:对于计算密集型算法,数据的搬移和运算效率越高的能耗比就越高。
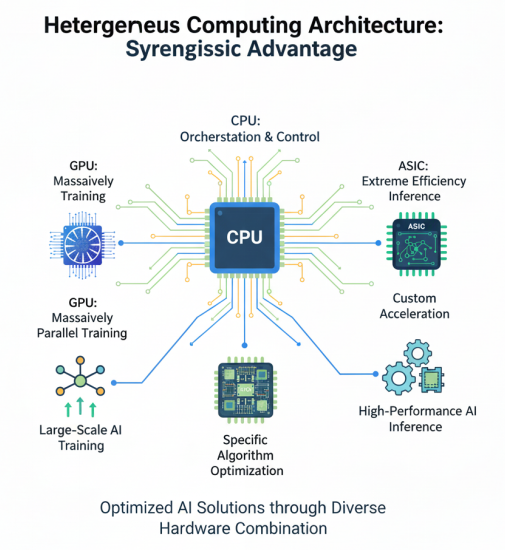
在大模型场景下,不同芯片各有所长:GPU适合大规模并行训练,ASIC适合高能效推理,FPGA适合特定算法加速,CPU适合任务调度和控制。异构计算架构通过合理组合这些不同类型的计算单元,可以充分发挥各自优势,实现整体系统性能的最优化。
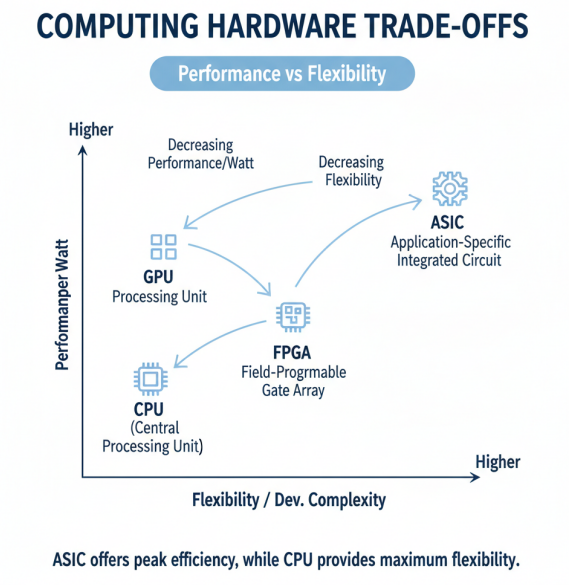
从性能功耗比来看,ASIC作为定制芯片表现最优,GPU次之,FPGA再次之,CPU最低。但从灵活性和开发难度来看,则正好相反。在实际的异构计算系统中,通常采用CPU+GPU的组合用于通用AI训练,CPU+FPGA的组合用于需要定制化加速的场景,CPU+ASIC的组合则用于大规模推理部署。这种多样化的硬件组合,为不同场景下的AI计算提供了最优解决方案。
国产AI芯片技术路线
国产AI芯片近年来取得了显著进展,形成了多元化的技术路线和产品体系。主要厂商包括寒武纪、华为昇腾、海光、壁仞、燧原、沐曦、摩尔线程等,各自推出了具有特色的AI芯片产品。
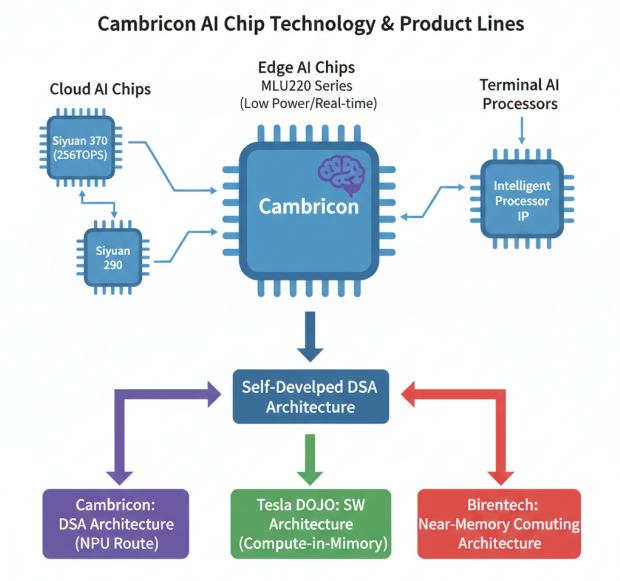
寒武纪AI芯片技术路线
寒武纪作为国内AI芯片的领军企业,专注于人工智能芯片产品的研发与技术创新,提供云边端全场景AI芯片产品。云端产品线包括思元290、思元370等,其中思元370达到256TOPS INT8算力;边缘端产品线包括MLU220系列,提供低功耗、高实时性的AI加速能力;终端产品线包括智能处理器IP,授权给终端设备厂商使用。寒武纪采用自研DSA计算架构,与特斯拉DOJO的存算一体架构和壁仞科技的近存架构形成不同的技术路线。
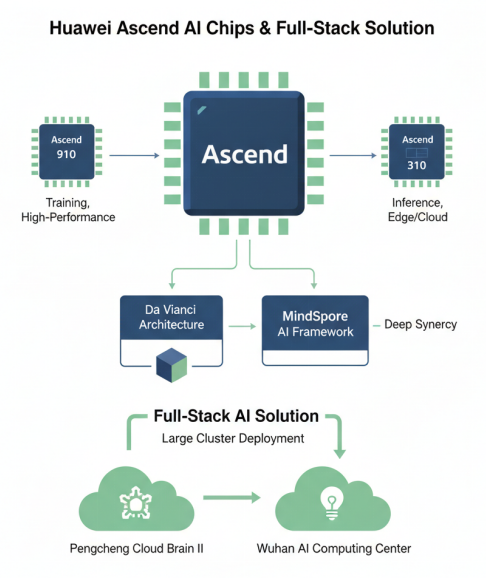
华为昇腾AI芯片与全栈解决方案
华为昇腾系列芯片包括昇腾910和昇腾310等,其中昇腾910是面向训练的高性能AI芯片,昇腾310主要面向推理场景。昇腾芯片采用达芬奇架构,支持3D Cube计算引擎,在AI计算性能方面具有竞争力。华为还推出了MindSpore AI框架,与昇腾芯片深度协同,形成了全栈AI解决方案。昇腾芯片在鹏城云脑II、武汉人工智能计算中心等大集群实践中得到广泛应用。
海光DCU系列是基于GPGPU架构的AI加速器,兼容CUDA生态,降低了用户迁移成本。海光DCU产品深算一号在通用计算和AI计算方面表现均衡,特别适合科学计算与AI融合的应用场景。壁仞BR100系列采用近存计算架构,在计算密度和能效比方面具有创新,是国内高端AI芯片的代表之一。
燧原科技、沐曦集成电路、摩尔线程等新兴AI芯片企业也各具特色。燧原科技推出邃思系列AI芯片,采用自研的GCU架构;沐曦集成电路专注于高性能GPU研发;摩尔线程则面向图形计算和AI计算融合场景。这些企业的创新推动着国产AI芯片技术的多元化发展。
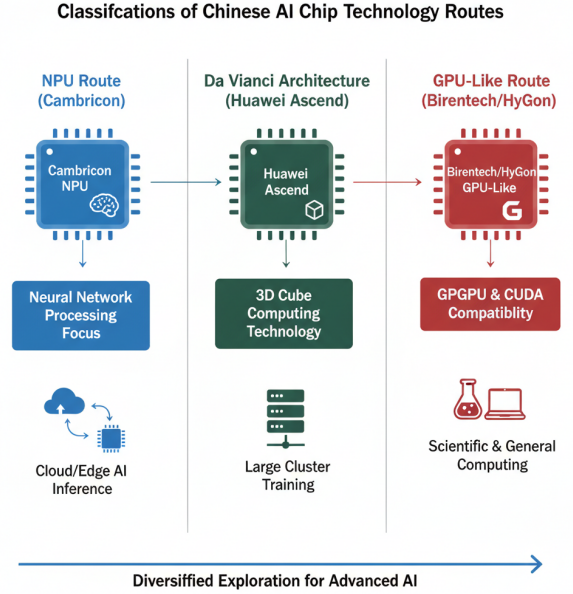
国产AI芯片技术路线分类
国产AI芯片在指令集、制程工艺、算力指标、生态兼容性等方面各有特点。在指令集方面,多数厂商采用自研指令集,以实现更好的性能优化;在制程工艺方面,普遍采用7nm、5nm等先进工艺;在算力指标方面,高端产品已接近国际领先水平;在生态兼容性方面,通过支持主流AI框架、提供迁移工具等方式,降低开发者使用门槛。
从技术路线来看,国产AI芯片主要分为三类:一是以寒武纪为代表的NPU路线,专注于神经网络处理;二是以华为昇腾为代表的达芬奇架构路线,强调3D Cube计算技术;三是以壁仞为代表的类GPU路线,兼容CUDA生态。这些不同的技术路线反映了国产AI芯片在追赶国际先进水平过程中的多元化探索。
芯片性能与能效评测
AI芯片的性能和能效评测涉及多个关键指标,包括TOPS/W(每瓦特万亿次运算)、算力利用率、内存带宽等,这些指标综合反映了芯片在实际应用中的表现。
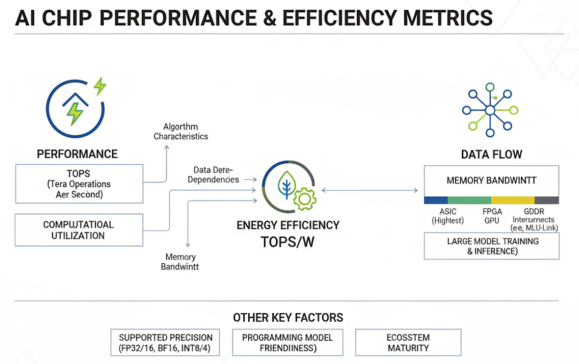
TOPS(Tera Operations Per Second)是衡量AI芯片算力的核心指标,表示芯片每秒可执行的万亿次操作数。然而,理论TOPS值并不能完全反映实际性能,还需要考虑算力利用率,即实际达到的算力与理论峰值的比例。影响算力利用率的因素包括算法特性、数据依赖性、内存带宽限制等。在实际评测中,需要通过标准基准测试套件,如MLPerf、AI Benchmark等,来衡量芯片在典型AI任务上的实际性能。
能效比(TOPS/W)是衡量AI芯片能效的关键指标,表示每瓦特功耗可提供的算力。随着数据中心能耗问题的日益突出,能效比成为芯片设计的重要目标。不同类型芯片的能效比差异显著:ASIC通常能达到最高的能效比,FPGA次之,GPU再次之,CPU最低。在实际应用中,需要综合考虑性能和能效,选择最适合的芯片类型。
内存带宽是影响AI芯片性能的另一关键因素。大模型训练和推理涉及大量数据移动,内存带宽往往成为性能瓶颈。现代AI芯片普遍采用高带宽内存(HBM、GDDR等)来提升内存带宽,如寒武纪MLU370-X8搭载MLU-Link多芯互联技术,每张加速卡可获得200GB/s的通讯吞吐性能。在实际评测中,需要关注理论内存带宽和有效内存带宽的差异,以及内存子系统对整体性能的影响。
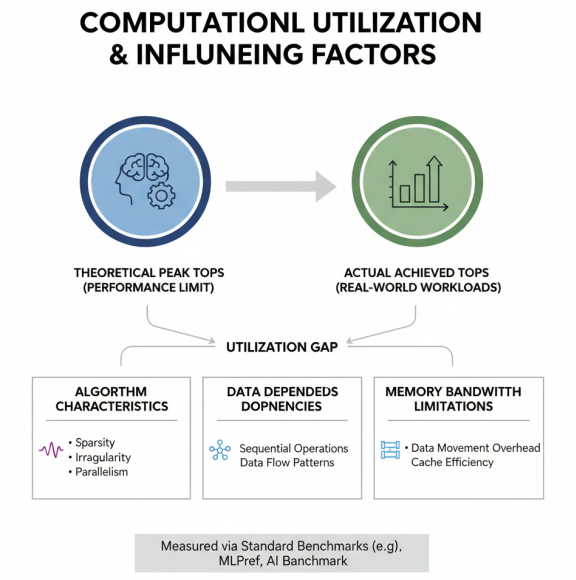
算力利用率及其影响因素
除了上述指标外,AI芯片评测还需考虑支持精度(FP32/FP16/BF16/INT8/INT4等)、编程模型友好度、生态成熟度等因素。支持精度决定了芯片在不同精度计算任务上的适用性;编程模型友好度影响开发效率;生态成熟度则关系到芯片的实际应用前景。
在国产芯片与国际标杆的对比中,寒武纪MLU370、昇腾910B等国产芯片在算力指标上已接近NVIDIA A100/H100的水平,但在软件生态、编程模型等方面仍有差距。随着技术的不断进步和生态的持续完善,国产AI芯片的性能和能效将进一步提升,为大模型训练和推理提供强有力的硬件支撑。
高速互联与网络架构
AI大模型与异构算力融合技术白皮书
高速互联技术
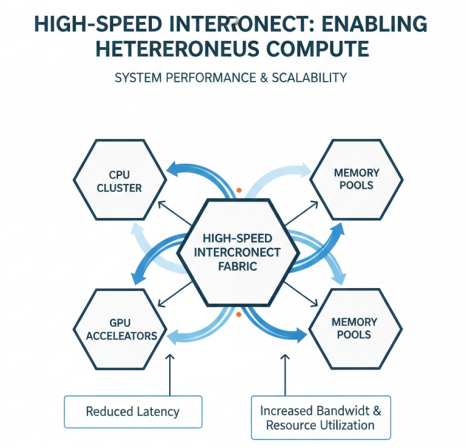
高速互联技术在异构算力系统中的关键作用
高速互联技术是异构算力系统的关键组成部分,直接影响系统的整体性能和扩展能力。在大模型训练和推理场景中,高效的高速互联技术能够显著提升系统性能,降低通信延迟,提高资源利用率。
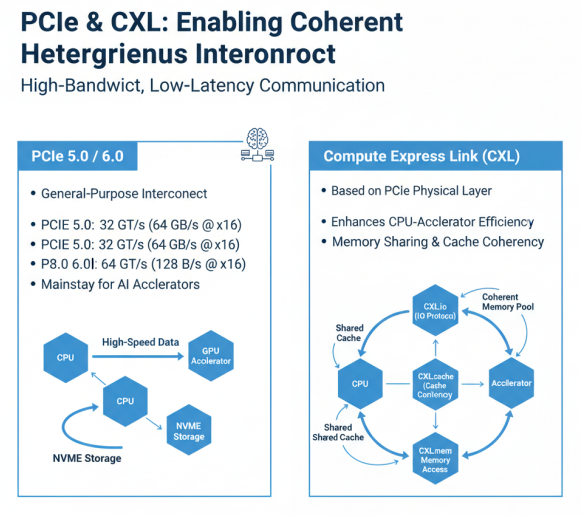
PCIe和CXL技术概览
PCIe(Peripheral Component Interconnect Express)是计算机系统中广泛使用的高速互联标准,目前主流的是PCIe 5.0,正在向PCIe 6.0发展。PCIe 5.0提供32GT/s的传输速率,x16配置下可提供约64GB/s的带宽,满足大多数AI加速卡的互联需求。PCIe 6.0进一步将传输速率提升至64GT/s,并引入PAM4调制技术,在相同物理层下实现带宽翻倍。PCIe 5.0/6.0已成为AI加速器与主机系统互联的主流选择,为AI计算提供高带宽、低延迟的数据传输通道。
CXL(Compute Express Link)是基于PCIe物理层的新型互联协议,旨在提高CPU与专用加速器之间的互联效率。CXL协议保留并拓展了PCIe的兼容性,只要使用PCIe 5.0及以上版本且支持CXL的设备均可通过CXL实现高速互联。CXL支持三种协议:CXL.io(基础I/O协议)、CXL.cache(缓存一致性协议)和CXL.mem(内存访问协议),能够实现CPU与加速器之间的高效内存共享和缓存一致性,特别适合异构计算场景。
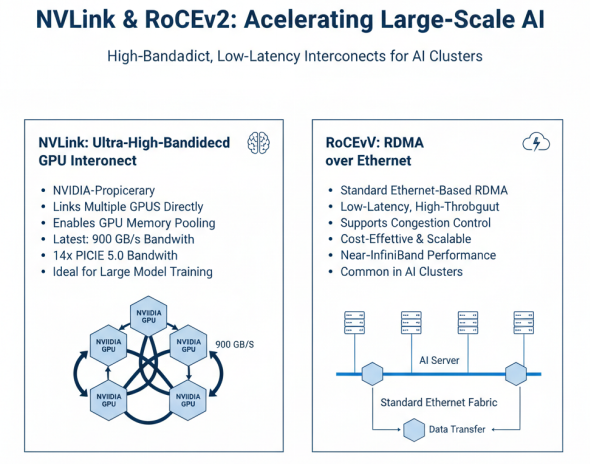
NVLink和RoCEv2技术概览
NVLink是NVIDIA专有的高速GPU互联技术,与传统的PCIe相比,能为更多GPU系统提供更快速的替代方案。NVLink技术通过连接多个NVIDIA显卡,能够实现显存池化和高速数据交换,大幅提升多GPU系统的性能。最新的NVLink技术提供高达900GB/s的带宽,是PCIe 5.0的14倍以上,特别适合大模型训练等需要大量GPU间通信的场景。
RoCEv2(RDMA over Converged Ethernet version 2)是基于以太网的RDMA(远程直接内存访问)技术,在标准以太网上实现低延迟、高吞吐的数据传输。RoCEv2支持拥塞控制和流量控制,能够在不增加专用网络设备的情况下提供接近InfiniBand的性能。在大规模AI集群中,RoCEv2因其成本优势和标准化特性,成为广泛选择的高速互联技术。
这些高速互联技术在带宽、延迟、扩展性等方面各有特点。PCIe提供通用互联,CXL增强内存一致性,NVLink提供超高带宽GPU互联,RoCEv2实现标准以太网上的RDMA。在实际系统设计中,需要根据应用场景和性能需求,选择合适的高速互联技术,构建高效的异构算力系统。
智算中心网络拓扑
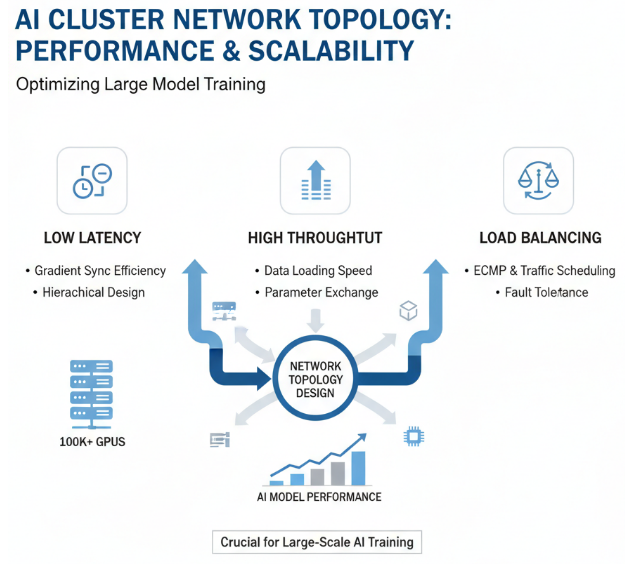
大规模AI集群网络拓扑概述
智算中心网络拓扑设计直接影响大规模AI集群的性能和扩展能力。在大模型训练场景中,特别是万卡甚至十万卡集群,合理的网络拓扑设计对于降低通信延迟、提高网络吞吐、实现负载均衡至关重要。
CLOS三层架构是目前大规模数据中心网络的主流拓扑结构,包括核心层、汇聚层和接入层。CLOS架构具有无阻塞、高可扩展性的特点,能够有效支持大规模服务器集群的互联。在AI集群中,CLOS架构通常配合ECMP(等价多路径)路由,实现负载均衡和故障容错。CLOS架构的扩展性好,可以通过增加交换机数量和端口密度来线性扩展网络容量,适合大规模AI集群的部署。
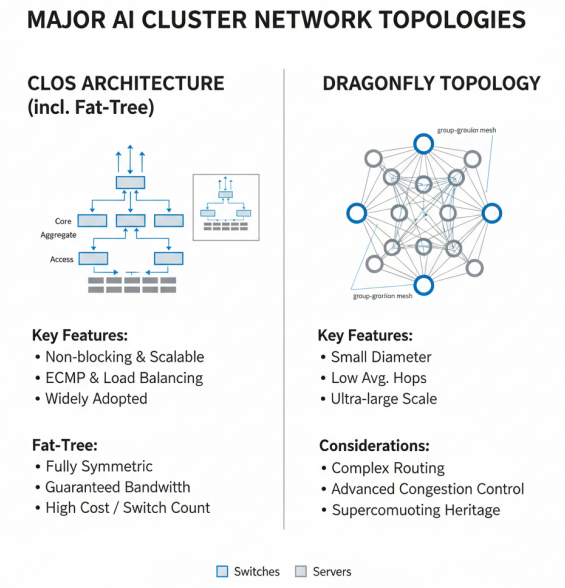
主流网络拓扑结构对比
Fat-Tree是CLOS架构的一种特例,采用完全对称的设计,所有路径具有相同的带宽和延迟。Fat-Tree拓扑在AI集群中得到广泛应用,特别是在需要高带宽、低延迟通信的大模型训练场景中。Fat-Tree网络的优点是带宽保证、无阻塞、易于管理,但缺点是成本较高,交换机数量多。在实际部署中,通常采用折叠式Fat-Tree(Folded Fat-Tree)设计,减少交换机数量,降低成本。
Dragonfly是一种高维网络拓扑,通过高维连接实现节点间的高效通信。Dragonfly拓扑在超级计算机中得到广泛应用,近年来也开始应用于大规模AI集群。Dragonfly网络的优点是直径小、平均跳数少、扩展性好,适合超大规模集群的部署。然而,Dragonfly拓扑的路由和拥塞控制较为复杂,需要专门的算法支持。
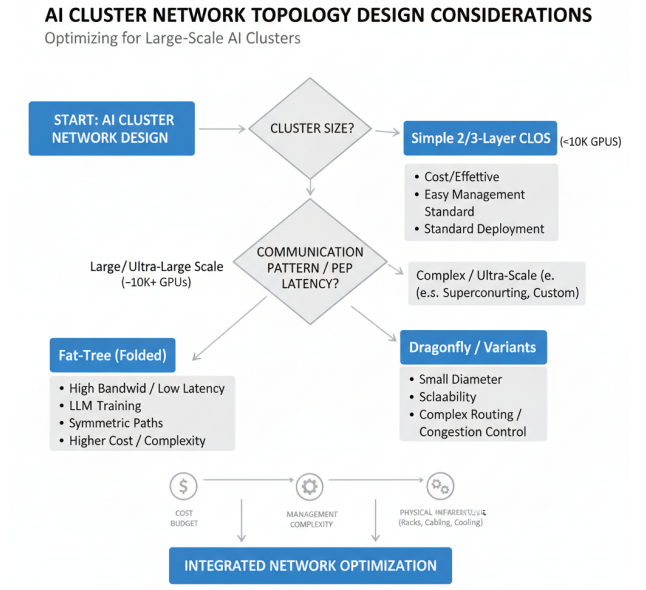
万卡集群网络设计中,如何综合考虑P2P延迟与吞吐优化,以及在实际部署中需要考虑的多种因素
在万卡集群网络设计中,需要综合考虑P2P延迟与吞吐优化。P2P延迟直接影响大模型训练中的梯度同步效率,而吞吐则影响数据加载和模型参数交换的速度。为了优化P2P延迟,通常采用层次化网络设计,将物理上临近的节点组织在同一子网中,减少跨子网通信;为了优化吞吐,通常采用多路径负载均衡、流量调度等技术,充分利用网络带宽。
在实际部署中,智算中心网络拓扑设计需要考虑多个因素:集群规模、通信模式、成本预算、管理复杂度等。对于中小规模集群,通常采用简单的二层或三层CLOS架构;对于大规模集群,可能需要更复杂的拓扑结构,如Dragonfly或其变种。此外,网络拓扑设计还需要与机柜布局、线缆管理、散热设计等物理设施相协调,实现整体系统的最优化。
集群通信优化
集群通信优化是大模型分布式训练的关键技术,直接影响训练效率和扩展性。在大规模AI集群中,节点间的通信开销往往成为性能瓶颈,因此需要通过高效的通信原语和优化技术来降低通信开销,提高训练效率。

集群通信优化概览- 分布式训练的性能瓶颈与解决方案
AllReduce是最常用的通信原语之一,用于数据并行训练中的梯度同步。AllReduce操作将所有节点的数据聚合后广播给所有节点,实现全局梯度的一致性。AllReduce可以通过先进行ReduceScatter操作,然后进行AllGather操作来实现:ReduceScatter操作首先聚合数据,然后将结果分散,这样每个成员仅持有聚合结果的一部分;AllGather操作则将各部分结果收集到所有节点,形成完整的结果。AllReduce通过组合操作,成为数据并行训练的核心通信原语。
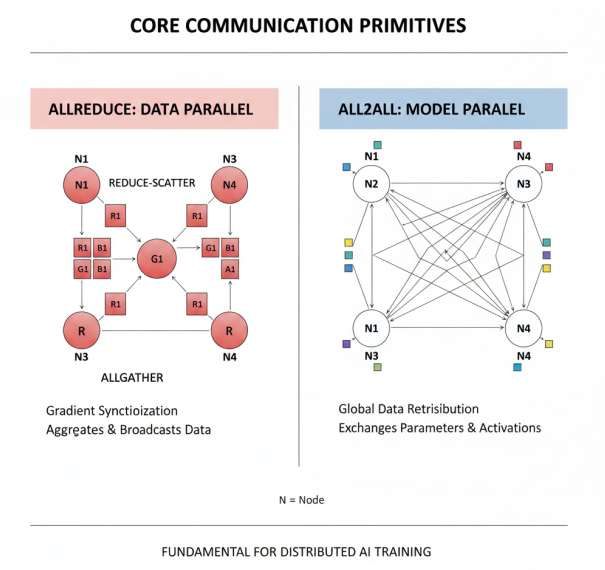
核心通信原语- AllReduce 与 All2All
All2All(All-to-All)是另一种重要的通信原语,在模型并行训练中广泛应用。All2All操作实现全局数据的重新分布,每个节点向所有其他节点发送数据,同时从所有其他节点接收数据。在张量并行和流水线并行中,All2All通信用于参数和激活值的交换,是实现模型并行的基础。
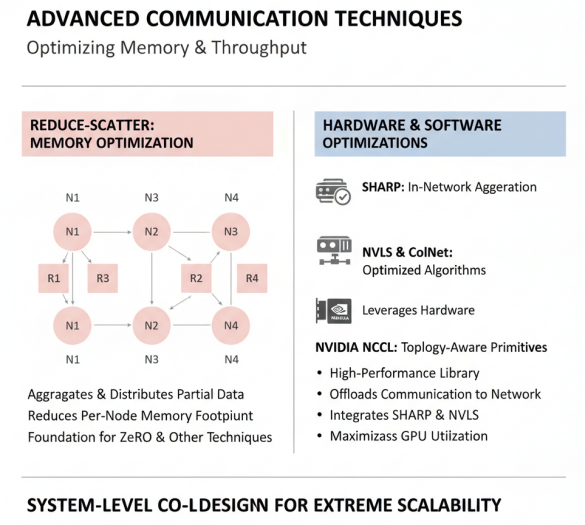
Reduce-Scatter 与通信优化技术
Reduce-Scatter是平衡显存与通信的重要原语,为ZeRO等显存优化技术奠定基础。Reduce-Scatter操作首先聚合数据,然后将结果分散到各个节点,每个节点仅持有聚合结果的一部分。这种操作可以有效减少单节点的内存占用,同时控制通信开销。
为了进一步提高通信效率,业界提出了多种优化技术。SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)技术通过在网络设备中执行聚合操作,减少数据在节点间的传输量,显著提高分布式深度学习工作负载的可扩展性和性能。NVLS与CollNet是专为优化AllReduce性能设计的特殊算法,其中NVLS还通过利用特定硬件能力支持ReduceScatter和AllGather操作。
在实际应用中,NVIDIA集合通信库(NCCL)提供了高性能、拓扑感知型集合运算:AllReduce、Broadcast、Reduce、AllGather和ReduceScatter,这些运算已针对NVIDIA硬件进行了深度优化。NCCL经过优化,可将关键的集合通信操作分流到网络,从而充分利用SHARP,显著提高分布式深度学习工作负载的可扩展性和性能。
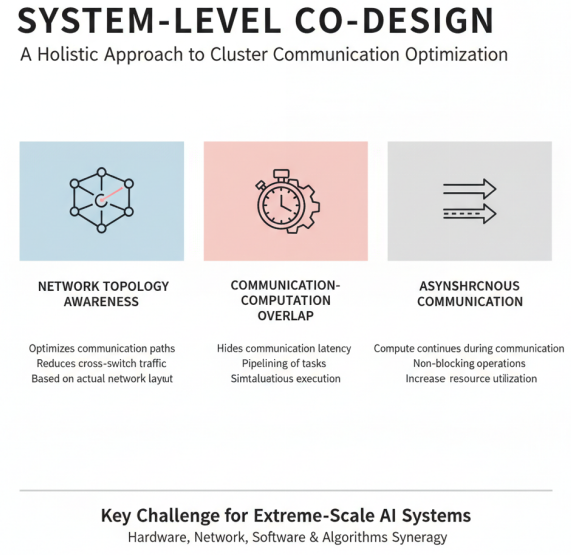
集群通信优化的系统性方法
集群通信优化还需要考虑网络拓扑感知、通信计算重叠、异步通信等技术。网络拓扑感知根据实际网络拓扑优化通信路径,减少跨交换机通信;通信计算重叠通过流水线技术,将通信与计算重叠执行,隐藏通信延迟;异步通信则允许计算任务在通信进行时继续执行,提高资源利用率。
在大规模AI集群中,集群通信优化是一个系统工程,需要硬件、网络、软件、算法等多层面的协同优化。随着集群规模的不断扩大和模型复杂度的持续增加,集群通信优化将成为异构算力系统设计的关键挑战和研究热点。
存储与数据管理
AI大模型与异构算力融合技术白皮书
大模型存储需求
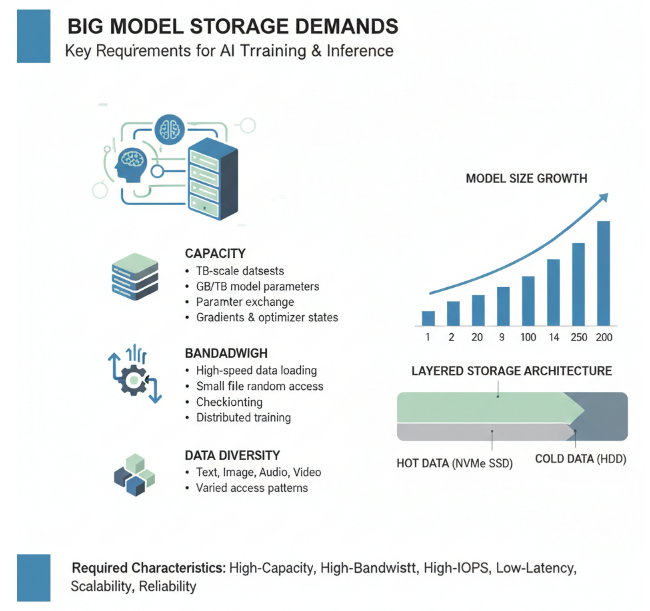
大模型训练和推理对存储系统提出了极高的要求,包括存储容量、带宽、IOPS等多个方面。随着模型参数规模的不断扩大和数据量的爆炸式增长,存储系统已成为大模型训练的重要瓶颈之一。
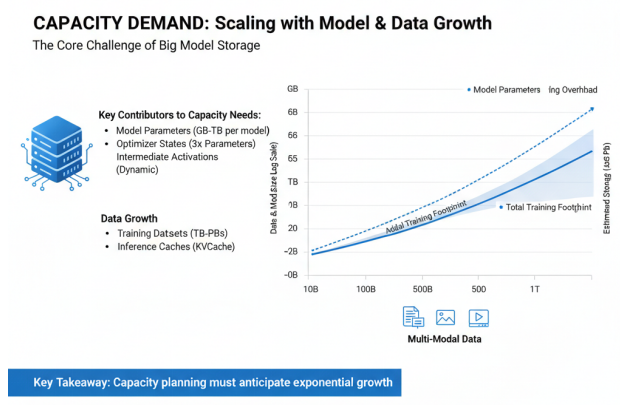
在存储容量方面,大模型训练涉及的数据集规模可达TB级,模型参数本身也需要GB级甚至TB级的存储空间。以千亿参数大模型为例,仅模型参数就需要数百GB的存储空间(假设每个参数为16位浮点数)。在训练过程中,还需要存储梯度、优化器状态、中间激活值等,进一步增加了存储需求。对于推理场景,虽然不需要存储训练相关数据,但模型参数和缓存(如KVCache)仍需要大量存储空间。
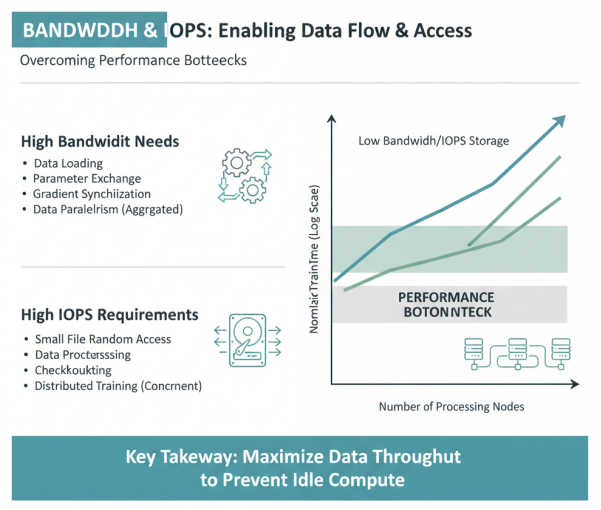
在存储带宽方面,大模型训练需要高带宽的存储系统来支持数据的高效加载。训练过程中的数据加载、参数交换、梯度同步等操作都需要高存储带宽支持。特别是在数据并行训练中,每个节点都需要独立加载数据,对存储系统的聚合带宽要求极高。存储带宽不足会导致计算资源闲置,降低训练效率。
在IOPS(每秒输入/输出操作数)方面,大模型训练通常涉及大量小文件的随机访问,如数据预处理、检查点保存/恢复等操作,需要高IOPS的存储系统支持。特别是在分布式训练中,多个节点同时访问存储系统,对IOPS的要求呈倍数增长。
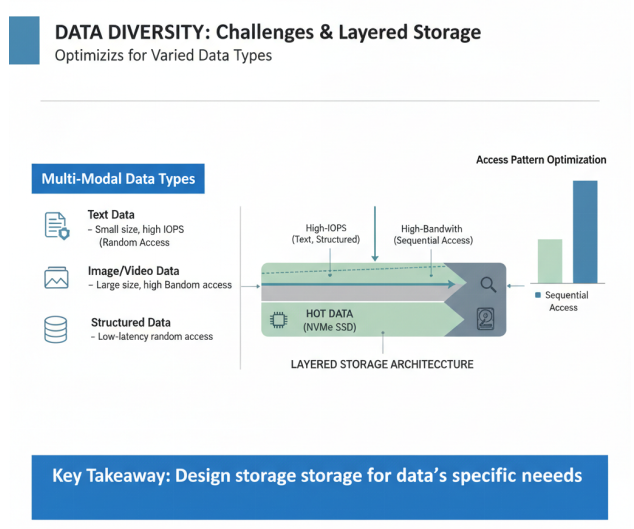
大模型存储需求还体现在数据多样性上。训练数据通常包括文本、图像、音频、视频等多种模态,每种数据类型对存储系统的要求各不相同。文本数据通常体积小但数量多,需要高IOPS;图像和视频数据体积大,需要高带宽;结构化数据则需要低延迟的随机访问能力。
为了满足大模型存储需求,存储系统需要具备以下特性:高容量、高带宽、高IOPS、低延迟、可扩展性、可靠性等。在实际系统设计中,通常采用分层存储架构,将热数据存储在高性能存储介质(如NVMe SSD)上,冷数据存储在大容量存储介质(如HDD)上,实现成本与性能的平衡。
分布式存储技术
分布式存储技术是满足大模型存储需求的关键,通过将数据分散存储在多个节点上,实现存储容量的线性扩展和性能的并行提升。在大模型训练场景中,分布式存储技术需要解决数据分片、缓存、预取等关键问题。
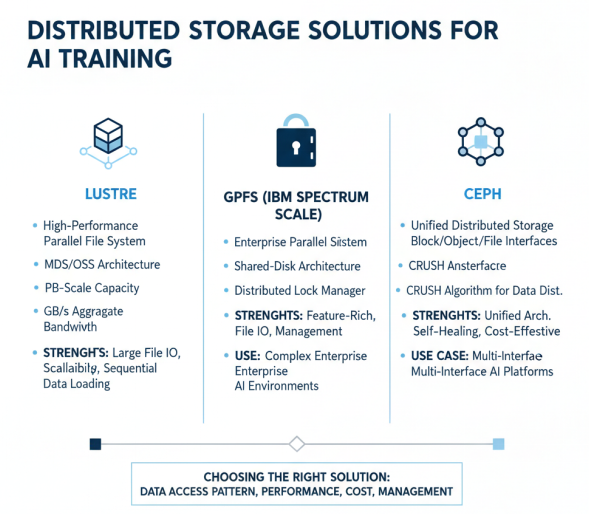
主流分布式存储技术对比,聚焦Lustre、GPFS和Ceph的特点和适用场景
Lustre是一种高性能并行文件系统,广泛应用于HPC和大规模AI训练场景。Lustre采用元数据服务器(MDS)和对象存储服务器(OSS)分离的架构,支持PB级存储容量和数百GB/s的聚合带宽。Lustre的优势在于高性能、高可扩展性,特别适合大文件顺序读写场景,如大模型训练中的数据加载。然而,Lustre在小文件处理和元数据操作方面相对较弱,需要配合其他技术使用。
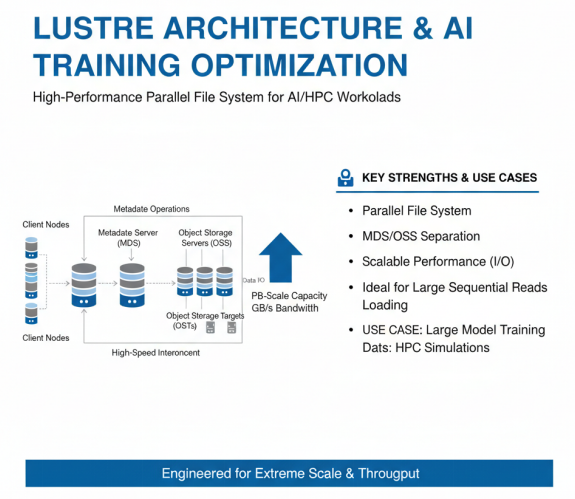
Lustre的架构和优势
GPFS(General Parallel File System,现称IBM Spectrum Scale)是IBM开发的高性能分布式文件系统,支持多种存储架构和访问协议。GPFS采用共享磁盘架构,通过分布式锁管理机制实现数据一致性,支持高并发访问。GPFS的优势在于全面的特性支持、良好的小文件性能和强大的管理功能,适合复杂的企业级AI训练环境。
Ceph是一种统一的分布式存储系统,支持块存储、对象存储和文件存储三种接口,被称为统一存储。Ceph采用CRUSH算法实现数据分布,无需中心化的元数据服务器,具有良好的可扩展性和容错性。Ceph的优势在于统一架构、自修复能力和成本效益,适合需要多种存储接口的AI平台。然而,Ceph在性能方面通常不如专用的并行文件系统,特别是在低延迟场景下。
除了上述主流分布式存储技术外,还有一些针对AI场景优化的存储解决方案。例如,Alluxio严格来说不是一个文件系统,而是构建在其他分布式文件系统之上的分布式缓存系统,在大数据领域使用非常广泛。Alluxio通过内存缓存加速数据访问,特别适合多次迭代的AI训练场景。
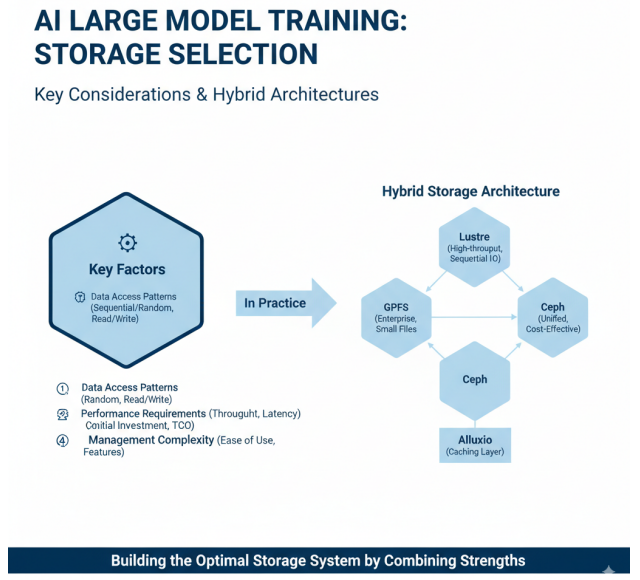
分布式存储技术选择的关键考量因素和混合存储架构的理念
在大模型训练中,分布式存储技术的选择需要考虑多个因素:数据访问模式、性能需求、成本预算、管理复杂度等。对于大规模顺序访问为主的训练场景,Lustre是理想选择;对于需要多种存储接口的复杂环境,Ceph提供统一解决方案;对于企业级关键应用,GPFS提供全面的特性支持。在实际部署中,通常采用混合存储架构,结合不同存储技术的优势,构建最适合大模型训练的存储系统。
数据预处理与加载
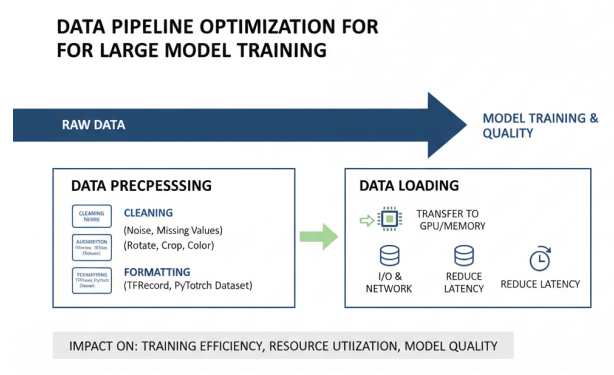
数据预处理与加载是大模型训练流程中的重要环节,直接影响训练效率和模型质量。高效的数据预处理与加载技术能够最大化计算资源利用率,减少I/O等待时间,提高整体训练吞吐量。
数据预处理包括数据清洗、增强、格式转换等多个步骤。数据清洗主要处理原始数据中的噪声、缺失值、异常值等问题,确保训练数据的质量;数据增强通过旋转、裁剪、翻转、颜色变换等技术扩充训练数据集,提高模型的泛化能力;格式转换则将不同来源、不同格式的数据统一为模型训练所需的格式,如TensorFlow的TFRecord、PyTorch的Dataset等。
数据加载是将预处理后的数据高效传输到计算设备(如GPU)内存中的过程。在大模型训练中,数据加载往往成为性能瓶颈,特别是在分布式训练场景中,多个计算节点同时加载数据,对存储系统和网络带宽提出极高要求。为了优化数据加载效率,通常采用以下技术:
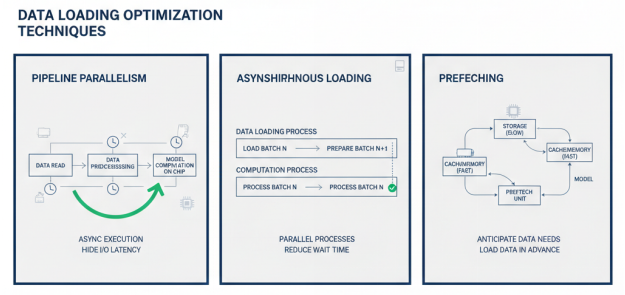
流水线并行(Pipeline Parallelism)是一种常用的数据加载优化技术,将数据读取、数据预处理计算、以及芯片上的模型计算三个步骤异步并行执行。这三步构成了典型的数据生产者和数据消费者的上下游关系,通过流水线技术可以隐藏I/O延迟,提高资源利用率。MindSpore等框架提供了灵活的数据集加载方法、丰富的数据处理操作,以及自动数据增强、动态批处理等功能,支持高效的数据流水线。
异步加载是另一种重要的优化技术,使用多个进程来并行加载和预处理数据,通过流水线处理减少数据等待时间。在异步加载模式下,数据加载进程与计算进程并行执行,计算进程在处理当前批次数据时,数据加载进程已经在准备下一批次数据,从而隐藏数据加载延迟。PyTorch的DataLoader、TensorFlow的tf.data等API都支持异步加载模式。
预取(Prefetching)技术通过预测未来需要的数据,提前将其加载到内存或缓存中,减少数据访问延迟。预取技术可以与缓存技术结合使用,将频繁访问的数据保存在高速存储介质中,进一步提高数据访问效率。在大模型训练中,常用的预取策略包括基于访问模式的预取、基于训练进度的预取等。
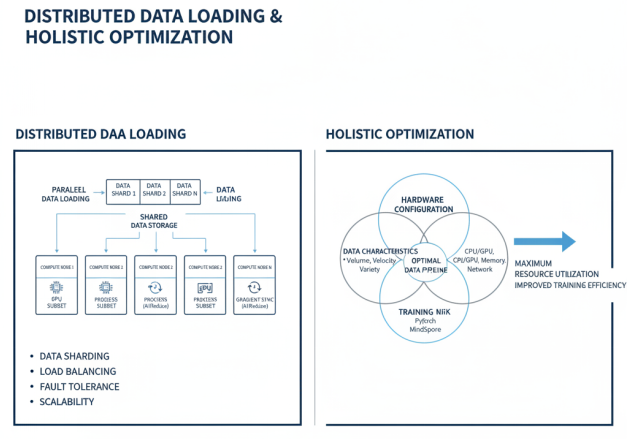
分布式数据加载是大规模分布式训练中的关键技术,通过将数据分片存储在多个节点上,实现数据加载的并行化。在数据并行训练中,每个节点负责加载和处理数据的一个子集,通过AllReduce等通信原语实现梯度同步。分布式数据加载需要解决数据分片、负载均衡、容错等问题,确保每个节点都能高效获取所需数据。
在实际应用中,数据预处理与加载的优化需要综合考虑数据特性、硬件配置、训练框架等多个因素。通过合理选择和组合上述技术,可以构建高效的数据流水线,最大化计算资源利用率,提高大模型训练的整体效率。
本报告共计分为“前言、AI大模型与算力行业现状、异构算力技术架构与核心组件、大模型与异构算力融合关键技术、国内企业实践与案例分析、行业应用与场景落地、挑战、趋势与展望”七大部分内容。上述文章仅为「异构算力技术架构与核心组件」部分的内容摘选。

















 1372
1372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









