



29日晚,DeepSeek发布了DeepSeek-V3.2-Exp实验版模型。

而且是“作为迈向新一代架构的中间步骤”,难道DeepSeek-V4要来啦?

言归正传,我们一起看看Exp版本究竟如何。
V3.2-Exp在上一个版本的基础上引入DeepSeek Sparse Attention,简称DSA,是一种稀疏注意力机制。
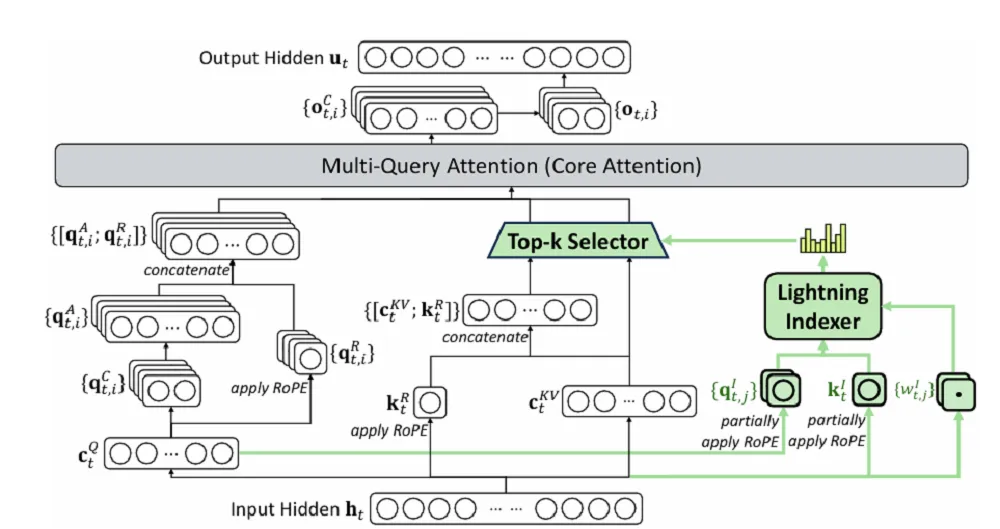
有了DSA,模型学会了抓重点。它会用一个叫“闪电索引器”(Lightning Indexer)的组件,飞快地扫一眼全文,找出和当前任务最相关的那一小撮关键信息,然后只让这些关键信息参与核心计算。
这么一来,计算的复杂度就从二次方级别,降到了近似线性水平。
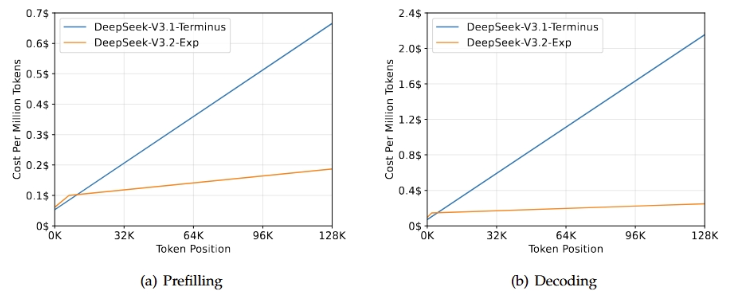
这个改进,在几乎不影响模型输出效果的前提下,实现了长文本训练和推理效率的大幅提升。
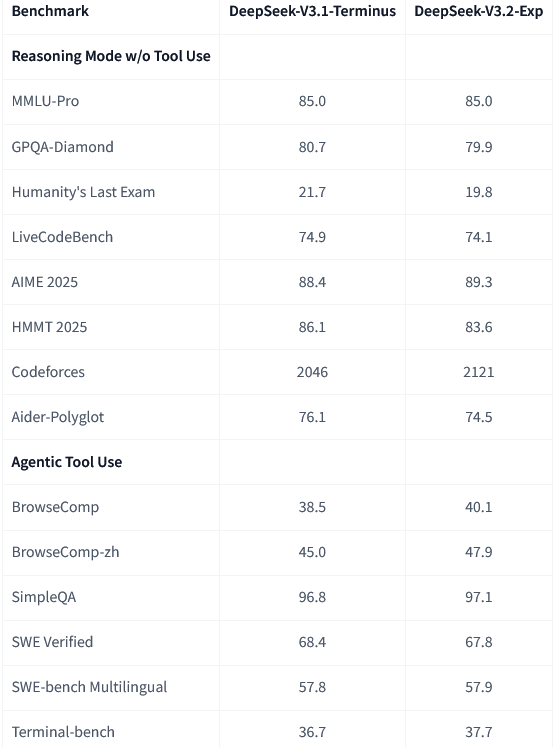
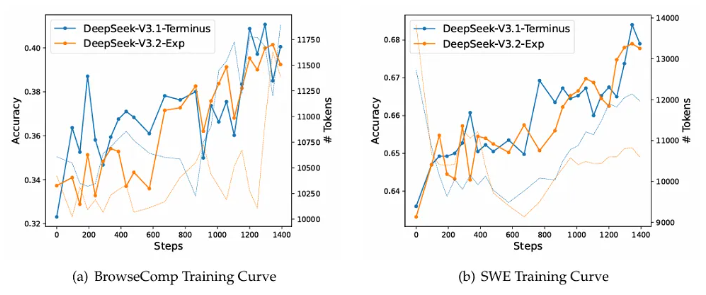
新模型V3.2-Exp和上一代V3.1-Terminus放在一起,用同样的设置跑了一遍,各领域的公开评测集结果显示,两者的表现基本持平。
开源和降价,一步到位
新模型DeepSeek-V3.2-Exp已经在Huggingface和魔搭社区开源了。
连开发过程中设计和实现的很多新的GPU算子都开源了,而且还提供了两个版本:TileLang版和CUDA版。
TileLang是一种高级语言,方便社区里的研究人员做实验、快速迭代想法。
CUDA是更底层的语言,效率更高,适合追求极致性能的开发者。
得益于新架构带来的成本降低,官方API的价格也立刻下调了。

开发者调用DeepSeek API的成本,降低了50%以上。
降价最狠的是输出token的价格。
现在,让DeepSeek-V3.2-Exp模型输出100万个token,只要3块钱。
这个价格,是上一代V3.1系列模型的四分之一。
目前,官方的App、网页端和小程序,都已经用上了最新的V3.2-Exp模型。
为了方便开发者对比验证新旧模型的差异,官方还临时保留了V3.1-Terminus的API接口,相当贴心。
国产软硬件厂商,光速跟进
新模型刚一发布,国内的硬件和云服务厂商就宣布“Day 0”适配。
所谓“Day 0”,就是发布当天就支持。

寒武纪真快。
在深度求索官宣模型开源之后,仅仅过了4分钟,寒武纪就发文,宣布同步实现对新模型的Day 0适配,并且开源了自家的推理引擎vLLM-MLU。
寒武纪表示,此前对DeepSeek系列模型进行了深入的软硬件协同性能优化,达成了业界领先的算力利用率水平。
针对本次的DeepSeek-V3.2-Exp新模型架构,他们通过Triton算子开发快速适配,再用自家的BangC融合算子进行性能优化,实现了很高的计算效率。
新模型的稀疏注意力机制,叠加上寒武纪的计算效率,可以大幅降低长序列场景下的成本。

华为旗下的昇腾芯片也快速通过vLLM和SGLang等推理框架,完成了对新模型的适配部署,并且把推理代码和算子实现都开源了。
根据他们的测试,DeepSeek-V3.2-Exp在昇腾设备上处理128K的长序列文本,首个token的输出耗时低于2秒,后续每个token的输出耗时低于30毫秒。
速度很快。
华为云更是基于CloudMatrix 384超节点,来为模型提供稳定可靠的推理服务,最大能支持160K的上下文长度。

海光信息的DCU(深度计算处理器)同样率先实现了对DeepSeek-V3.2-Exp的Day 0高效适配和优化,确保算力“零等待”部署。
除了芯片厂商,云平台也纷纷跟进。
华为云、PPIO派欧云、优刻得(UCloud)等云平台,都已经宣布上线了DeepSeek-V3.2-Exp。
整个国产AI产业链,围绕着一个新模型的发布,展现出了惊人的协同效率。
上手体验如何?
新模型发布,自然少不了各路网友和开发者的上手体验。
有位网友在社交媒体上分享,他用一个包含10万个token的代码库测试了新模型,最直观的感受就是,速度提升非常明显。
不过,这个新模型毕竟是个“实验版”,在实际使用中,也暴露出了一些问题。
它似乎为了追求效率和简洁,在某些能力上做出了妥协。
比如在编程任务上,有评测显示,新模型V3.2-Exp生成的代码,比上一代V3.1-Terminus要简短得多。
在信息检索任务上,也出现了类似的情况。新模型似乎变“懒”了。
知乎博主@toyama nao在测评后也指出了类似的问题,他认为V3.2-Exp在工作记忆、计算精度稳定性等方面有明显短板,还容易陷入死循环。

当然,深度求索官方也坦言,V3.2-Exp作为一个实验性版本,虽然在公开评测集上验证了有效性,但还需要在用户的真实场景中进行更大规模的测试,来排除某些场景下效果不佳的可能性。
架构创新,可能比眼前的性能更重要
作为一个实验性的“中间步骤”,DeepSeek-V3.2-Exp更大的价值,或许不在于它当前在某些任务上的表现,而在于它在模型架构上做出的探索。
前面提到的DSA注意力机制,目前还处在原型期,除了闪电索引器(Lightning Indexer),还有一个细粒度的token选择机制。
闪电索引器负责快速评估查询token和历史token的相关性,然后从选择机制里只挑选最相关的一部分上下文,送入注意力计算环节。
这个架构上的创新,直接带来了成本和效率的优化。
在训练方法上,深度求索也采用了“继续预训练+后训练”的组合拳。
继续预训练分两步走。
第一步,先在稠密模式下,短暂训练那个“闪电索引器”,让它的输出结果和标准的注意力机制保持一致。
第二步,再引入稀疏选择机制,让模型慢慢适应新的、更高效的计算方式,相当于让它从“地毯式搜索”学会“精准打击”。
预训练完成后,还有后训练阶段,主要用了专家蒸馏和混合强化学习两种技术。
专家蒸馏,就是针对数学、编程、推理等不同领域,分别训练出各自的“专家模型”,然后想办法把这些专家的“知识”,压缩进一个通用的模型里。
混合强化学习,则是把推理能力、智能体能力和人类对齐训练,都统一在一个强化学习阶段完成,避免了传统分阶段训练容易出现“学了新的忘了旧的”的问题。
在所有测试环境中,长序列推理的开销都明显降低,证明DSA机制在真实部署场景中很有用。
同时,新模型的训练曲线和上一代模型一样稳定,也说明这种新架构在收敛性上没有额外的风险。
这次深度求索的探索,无论从技术架构的创新,还是对整个国产AI生态的带动,都值得关注。
参考资料:
https://github.com/Cambricon/vllm-mlu
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Exp
https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
END

















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









