




2025年9月,在芯片设计盛会Hot Chips上,一家名为d-Matrix的公司,展示了一项名为3D堆叠数字内存计算(3DIMC)的颠覆性技术,矛头直指整个AI产业最头疼的难题——"内存墙"。

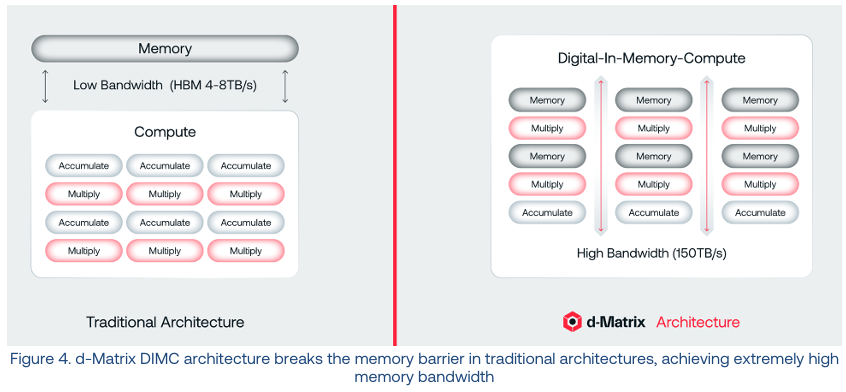
随着AI从幕后训练走向台前应用,我们的芯片越来越像一个饿着肚子的性能猛兽,而内存带宽就是那条细细的补给线,根本喂不饱它。d-Matrix的方案简单粗暴又充满想象力:直接把计算单元塞进SRAM(静态随机存取存储器)模块里。结果呢?高达150 TB/s的内存带宽,把传统HBM(高带宽内存)甩开了将近20倍。这为AI推理开辟了一条全新的赛道。
AI算力的'阿喀琉斯之踵',谁来解救?
聊到"内存墙"(Memory Wall),这可不是什么新鲜词。早在1994年,Wulf和McKee就提出了这个概念,用来形容处理器和内存之间日益扩大的速度鸿沟。你可以想象一下,CPU(中央处理器)的时钟速度跟着摩尔定律像坐了火箭一样,每18个月翻一番,可DRAM(动态随机存取存储器)的性能每年只愿意慢悠悠地提升7-10%。到了2000年代,处理器都跑到GHz级别了,内存访问时间还停留在几十纳秒,性能瓶颈就这么卡住了。
到了AI时代,这个问题被无限放大。训练一个深度神经网络,权重、激活值、梯度这些数据得在内存和计算单元之间来回倒腾。带宽跟不上,再昂贵的计算核心也只能干瞪眼,系统效率一塌糊涂。特别是现在,大型语言模型(LLM)的参数动不动就几千亿,内存带宽这点"小水管"早就扛不住了。
d-Matrix的创始人
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









